Abstract
A full-rank lattice in the Euclidean space is a discrete set formed by all integer linear combinations of a basis. Given a probability distribution on , two operations can be induced by considering the quotient of the space by such a lattice: wrapping and quantization. For a lattice , and a fundamental domain , which tiles through , the wrapped distribution over the quotient is obtained by summing the density over each coset, while the quantized distribution over the lattice is defined by integrating over each fundamental domain translation. These operations define wrapped and quantized random variables over and , respectively, which sum up to the original random variable. We investigate information-theoretic properties of this decomposition, such as entropy, mutual information and the Fisher information matrix, and show that it naturally generalizes to the more abstract context of locally compact topological groups.
1. Introduction
Lattices are discrete sets in formed by all integer linear combinations of a set of independent vectors, and have found different applications, such as in information theory and communications [1,2,3]. Given a probability distribution in , two operations can be induced by considering the quotient of the space by a lattice: wrapping and quantization.
The wrapped distribution over the quotient is obtained by summing the probability density over each coset. It is used to define parameters for lattice coset coding, particularly for AWGN and wiretap channels, such as the flatness factor, which is, up to a constant, the distance from a wrapped probability distribution to a uniform one [4,5]. This factor is equivalent to the smoothing parameter, used in post-quantum lattice-based cryptography [6]. In the context of directional statistics, wrapping has been used as a standard way to construct distributions on a circle and on a torus [7].
The quantized distribution over the lattice can be defined by integrating over each fundamental domain translation, thus corresponding to the distribution of the fundamental domains after lattice-based quantization is applied. Lattice quantization has different uses in signal processing and coding: for instance, it can achieve the optimal rate-distortion trade-off and can be used for shaping in channel coding [2]. A special case of interest is when the distribution on the fundamental region is uniform, which amounts to high-resolution quantization or dithered quantization [8,9].
In this work, we relate these two operations by remarking that the random variables induced by wrapping and quantization sum up to the original one. We study information properties of this decomposition, both from classical information theory [10] and from information geometry [11], and provide some examples for the exponential and Gaussian distributions. We also propose a generalization of these ideas to locally compact groups. Probability distributions on these groups have been studied in [12], and some information-theoretic properties have been investigated in [13,14,15]. In addition to probability measures, one can also define the notions of lattice and fundamental domains on them, thereby generalizing the Euclidean case. We show that wrapping and quantization are also well defined, and provide some illustrative examples.
2. Lattices, Wrapping and Quantization
2.1. Lattices and Fundamental Domains
A lattice in is a discrete additive subgroup of , or, equivalently, the set formed by all integer linear combinations of a set of linearly independent vector , called a basis of . A matrix B whose column vectors form a basis is called a generator matrix of , and we have . The lattice dimension is k, and, if , the lattice is said to be full-rank; we henceforth consider full-rank lattices. A lattice defines an equivalence relation in : . The associated equivalence classes are denoted by or . The set of all equivalence classes is the lattice quotient , and we denote the standard projection .
Let be a Lebesgue-measurable set of and a lattice. We say that is a fundamental domain or a fundamental region of , or that tiles by , if (1) , and (2) , for all in (it is often only asked that this intersection has Lebesgue measure zero, but we require it to be empty). Given a fundamental domain , each coset has a unique representative in , i.e., the measurable map is a bijection. This fact suggests using a fundamental domain to represent the quotient. Each fundamental domain contains exactly one lattice point, which may be chosen as the origin. An example of a fundamental domain is the fundamental parallelotope with respect to a basis , namely . Another one is the Voronoi region of the origin, given by the points that are closer to the origin than to any other lattice point, with an appropriate choice for ties. It is a well-known fact that every fundamental domain has the same volume, denoted by , for any generator matrix B of .
2.2. Wrapping and Quantization
Consider with the Lebesgue measure , and P a probability measure such that . Then the probability density function (pdf) of P is , the Radon–Nikodym derivative. For fixed full-rank lattice and fundamental domain , the wrapping of P by is the distribution on , given by . For simplicity, we identify with to regard as a distribution over , and then we have given by , for all . Using this identification, the wrapping has density given by
A construction that is, in some sense, dual to wrapping is quantization. Note that each fundamental domain partitions the space as . The quantization function is the measurable map , given by , for and . The quantized probability distribution of P on the discrete set is , given by . The probability mass function of the quantized distribution is then
Letting X be a vector random variable in with distribution p, we define and the wrapped and quantized random variables, respectively. By definition, they are distributed according to and . Interestingly, they sum up to the original one:
since . Note also that has the same distribution as , by the bimeasurable bijection . These factors, however, are not independent, since, in general, . The difference between and shall be illustrated in the following examples. Note that the expression for the quantized distribution depends on the choice of fundamental domain, while the wrapped distribution does not, up to a lattice translation.
We say a random variable X over is memoryless if for all , where is the tail distribution function. In particular, a memoryless distribution satisfies for all , , which implies . The converse, however, is not true; for example, independence holds whenever p is constant on each region , for .
Example 1.
The exponential distribution, parametrized by , is defined as
where takes value 1 if , and 0 otherwise. Choosing the lattice , , and the fundamental domain , one can write closed-form expressions for the wrapped and quantized distributions:
Note that, in this special case, , as a consequence of memorylessness. The wrapped distribution with , which amounts to a distribution on the unitary circle, is well studied in [16].
Example 2.
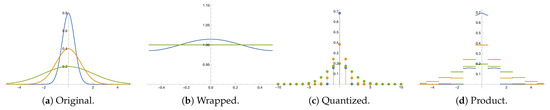
Consider the univariate Gaussian distribution
and the lattice , with fundamental domain , . The wrapped and quantized distributions are given respectively by
The value for the wrapped distribution on a unitary circle is usually considered in directional statistics [7]. Figure 1 illustrates the original, wrapped, quantized and product distributions for different zero-mean Gaussian distributions. As can be seen in the figure, in this case, .
Figure 1.
Example of zero-mean Gaussian distributions and their corresponding wrapped, quantized and product distributions, with and for different variances: (blue), (orange), (green).
A straightforward consequence of the decomposition (3) is
- ;
- ,
where , and denote, respectively, the expectation, the variance and the cross-covariance operators.
We note that different types of discretization have also been studied, other then integrating over a fundamental domain [17]. For instance, in [4,18,19], the discretized distribution is defined by restricting the original pdf to the lattice , and then normalizing:
for a fixed . This discretization is nothing other than the conditional distribution of given that , expressed as . Moreover, when , such as in the exponential distribution, cf. example 1, then .
3. Information Properties
3.1. Information-Theoretic Measures
Let us consider a random variable X with distribution p and the induced wrapped and quantized ones, respectively, and . The mutual information between and is defined as the Kullback–Leibler divergence , and is a measure of how non-independent the marginal distributions and are [10]. Using the theorem of change of variables, we have
Note that, from this decomposition, we have .
Proposition 1.
Let X be a real random variable, and and the respective wrapped and quantized random variables, using the lattice . Denote and . If X has support , then the mutual information between and is upper-bounded by
If X has support , then is upper-bounded by
Proof.
First, , since the uniform distribution maximizes entropy on a bounded support. Then, note that the mean and variance of the integer-valued random variable are and , respectively. For (7), use that, for positive integer random variables, , as in [20] (Theorem 8); for (8), the upper-bound for integer-valued random variables from [20] (Theorem 10) gives us . Replacing the corresponding inequalities in (6) yields the desired results. □
The following lemma can be found in [2] (Appendix 3).
Lemma 1.
.
Proof.
, and , since it is a discrete entropy. □
Proposition 2.
Let , , be a family of lattices, with fundamental domains .
- 1.
- If is connected, and p is continuous and Riemann-integrable, then .
- 2.
- If 0 is an interior point of , then .
Proof.
For , the proof is an adaptation of [10] (Theorem 8.3.1). Since is connected and p is continuous, we can use the mean value theorem: for every there exists an such that . Therefore, we can write , using that . The first term is an n-dimensional Riemann sum, and converges to when , while the second term becomes arbitrarily small. Therefore, , so .
For , note that, from Lemma 1, . However, by choosing sufficiently large, we can make arbitrarily close to 1, since 0 is in the interior of . Therefore, can be made arbitrarily small. □
Example 3.
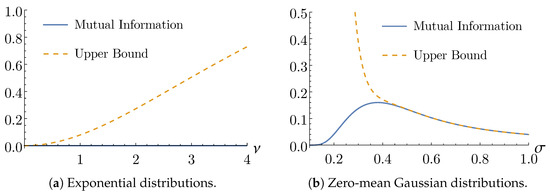
In the case of the exponential distributions, as in Example 1, the distributions of and are independent, i.e., , therefore . The mutual information and the corresponding upper bound (7) are plotted in Figure 2a, as function of the parameter ν.
Figure 2.
Mutual information and its upper bound.
Example 4.
In the case of the univariate zero-mean Gaussian distributions, as in Example 2, one can use (6) to numerically compute the mutual information , as a function of the standard deviation σ, and compare it with the upper bound (8) (Figure 2b). Interestingly, vanishes as or , which is equivalent to choosing a lattice with or , cf. Proposition 2. The mutual information attains a maximum in , showing this is the value for which and are the least independent.
3.2. Fisher Information
Let be a family of probability densities smoothly parametrized by in an open set . The Fisher information matrix is defined as the positive semi-definite matrix with coefficients , where . When M is a manifold satisfying certain regularity conditions [11], and G is positive definite, it becomes a Riemannian manifold with the metric given by , called a statistical manifold. Let ⪯ denote the Loewner partial order for matrices, given by if, and only if, is positive semi-definite. The following results justify the name information matrix given to this quantity.
Proposition 3
([11,21]). Let X be a random variable distributed according to a distribution parametrized by θ, and its information matrix. The following hold.
- 1.
- Monotonicity:if is a measurable function (i.e., a statistic) and is the information matrix of , then , with equality if, and only if, F is a sufficient statistic for θ.
- 2.
- Additivity:if are independent random variables, then the joint information matrix satisfies .
Let X be a random variable on , and and its wrapped and quantized factors, respectively. We denote their respective Fisher information matrices by , and . By additivity, the Fisher information of is , and, by monotonicity, we have both and . It follows immediately that
Example 5.
In the family of exponential distributions, as in Example 1, the independence of and implies that the Fisher information matrix is additive. Indeed, for :
4. A Generalization to Topological Groups
A topological group is a topological space that is also a group with respect to some operation · called product, and such that the inverse and product are continuous. As additional requisites, we ask G to be locally compact, Hausdorff and second-countable (i.e., has a countable basis) [22]. Let be the the Borel -algebra of G. Haar’s theorem says there is a unique (up to a constant) Radon measure on G that is invariant by left translations—we will suppose a fixed normalization, and denote both the measure and integration with respect to it by dg. The group G is said to be unimodular if dg is also invariant by right translations. Since G is -compact, the Haar measure is -finite [12].
Let be a discrete subgroup of G, which is necessarily closed, since G is Hausdorff, and countable, since G is second-countable. Let us also consider the quotient space of left cosets which has a natural projection , given by . We call a lattice if the induced Haar measure on is finite and bi-invariant. A particular case is when the quotient is compact; then is said to be a uniform lattice. A cross-section is defined as a set of representatives of such that all cosets are uniquely represented. A fundamental domain is a measurable cross-section. It can be shown that is a lattice if, and only if, it admits a fundamental domain. Furthermore, every fundamental domain has the same measure [23,24].
Let P be a probability measure on the space that is absolutely continuous with respect to the Haar measure dg. By the Radon–Nikodym theorem, we can define a density function , such that and , for all . The original measure can be represented as , and we consider the family of all such densities
Probability distributions on locally compact groups have been studied in [12], and some information-theoretic properties have been investigated in [13,14,15]. The result that allows us to consider wrapped distributions in this context is the Weil formula, taken as a particular case of [24] (Theorem 3.4.6):
Theorem 1.
For any , the wrapping , is well defined -almost everywhere, belongs to , and
As a consequence, for every probability density , we can consider its wrapping , which is , non-negative and is also a probability density: . The associated probability measure over is . This notation, suggesting as the push-forward measure by , is not a coincidence, since, from Theorem 1,
Analogously, given a fundamental domain , it is possible to define a quantization map by , for every , which is unique since . The quantized probability distribution is the discrete probability measure over , defined by the mass function , or as the push-forward measure .
If X is distributed according to p, and , , then , again, as a consequence of being a measurable bijection whose inverse is the product . Despite being an abstract definition, this framework expands the scope of the previous approach, cf. examples below. In the following, let be a full-rank lattice, and be a full-rank sublattice, as defined in Section 2.
Example 6.
Let and . This recovers the approach from Section 2 as a particular case.
Example 7.
Let and . A fundamental domain is a choice of points, where each point corresponds to a coset . Of particular interest are Voronoi constellations [25,26] where the coset leaders are selected, with some choice made for ties. Since Λ is discrete, the Haar measure is the counting measure , and . The wrapped and quantized distributions are , and .
Example 8.
Let (a torus) and (the projection of Λ to G). Then consists of a finite family of cosets , for , and a choice of fundamental domain is the projection of a fundamental domain of Λ. There are some standard choices for the distribution on G, such as a wrapping from the Euclidean space and the bivariate von Mises distribution [7] (Section 11.4). Then, and , and, in the particular case where is a -wrapped distribution, they become and .
Example 9.
Let (a finite field) or , and (any linear block code). A fundamental domain can be a finite set of points that tiles the space by . The distributions then become finite sums, such as in Example 7.
Example 10.
Let , the Lie group of square matrices with determinant 1, and (the subgroup of integer matrices). This is, in fact, a lattice, since for , where ζ is the Riemann zeta function, and for the finite covolume is calculated in [27], where descriptions of fundamental domains are also given.
5. Conclusions
In this work, we have studied the decomposition of a random variable through lattices into its wrapping and quantization terms. Generalization of examples and of Proposition 1 to higher dimensions constitutes a work in progress. We have also proposed a generalization of this decomposition to topological groups; in particular, this allows one to study information theory on such abstract spaces, which is another perspective for future work.
Author Contributions
Conceptualization, all authors; investigation, F.C.C.M. and H.K.M.; writing—original draft preparation, F.C.C.M. and H.K.M.; writing—review and editing, all authors; supervision, S.I.R.C. All authors have read and agreed to the published version of the manuscript.
Funding
This work was partly supported by Brazilian National Council for Scientific and Technological Development (CNPq) grants 141407/2020-4 and 314441/2021-2, and by São Paulo Research Foundation (FAPESP) grant 2021/04516-8.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Acknowledgments
The authors are grateful to Max Costa for fruitful discussions, and to the reviewer for the relevant suggestions.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Conway, J.H.; Sloane, N.J.A. Sphere Packings, Lattices and Groups; Springer: New York, NY, USA, 1999. [Google Scholar]
- Zamir, R. Lattice Coding for Signals and Networks: A Structured Coding Approach to Quantization, Modulation and Multiuser Information Theory; Cambridge University Press: Cambridge, UK, 2014. [Google Scholar]
- Costa, S.I.R.; Oggier, F.; Campello, A.; Belfiore, J.C.; Viterbo, E. Lattices Applied to Coding for Reliable and Secure Communications; Springer: Cham, Switzerland, 2017. [Google Scholar]
- Ling, C.; Belfiore, J.C. Achieving AWGN channel capacity with lattice Gaussian coding. IEEE Trans. Inf. Theory 2014, 60, 5918–5929. [Google Scholar] [CrossRef][Green Version]
- Damir, M.T.; Karrila, A.; Amorós, L.; Gnilke, O.W.; Karpuk, D.; Hollanti, C. Well-rounded lattices: Towards optimal coset codes for Gaussian and fading wiretap channels. IEEE Trans. Inf. Theory 2021, 67, 3645–3663. [Google Scholar] [CrossRef]
- Chung, K.M.; Dadush, D.; Liu, F.H.; Peikert, C. On the lattice smoothing parameter problem. In Proceedings of the 2013 IEEE Conference on Computational Complexity, Stanford, CA, USA, 5–7 June 2013; pp. 230–241. [Google Scholar]
- Mardia, K.V.; Jupp, P.E. Directional Statistics; Wiley: New York, NY, USA, 2000. [Google Scholar]
- Zamir, R.; Feder, M. On lattice quantization noise. IEEE Trans. Inf. Theory 1996, 42, 1152–1159. [Google Scholar] [CrossRef]
- Ling, C.; Gan, L. Lattice quantization noise revisited. In Proceedings of the 2013 IEEE Information Theory Workshop (ITW), Sevilla, Spain, 9–13 September 2013; pp. 1–5. [Google Scholar]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory, 2nd ed.; Wiley: Hoboken, NJ, USA, 2006. [Google Scholar]
- Amari, S.; Nagaoka, H. Methods of Information Geometry; American Mathematical Society: Providence, RI, USA, 2000. [Google Scholar]
- Heyer, H. Probability Measures on Locally Compact Groups; Springer: Berlin/Heidelberg, Germany, 1977. [Google Scholar]
- Chirikjian, G.S. Stochastic Models, Information Theory, and Lie Groups; Birkhäuser: Boston, MA, USA, 2009. [Google Scholar]
- Johnson, O.; Suhov, Y. Entropy and convergence on compact groups. J. Theor. Probab. 2000, 13, 843–857. [Google Scholar] [CrossRef]
- Chirikjian, G.S. Information-theoretic inequalities on unimodular Lie groups. J. Geom. Mech. 2010, 2, 119–158. [Google Scholar] [CrossRef] [PubMed]
- Jammalamadaka, S.R.; Kozubowski, T.J. New families of wrapped distributions for modeling skew circular data. Commun. Stat.–Theory Methods 2004, 33, 2059–2074. [Google Scholar] [CrossRef]
- Chakraborty, S. Generating discrete analogues of continuous probability distributions-A survey of methods and constructions. J. Stat. Distrib. Appl. 2015, 2, 6. [Google Scholar] [CrossRef]
- Nielsen, F. The Kullback–Leibler divergence between lattice Gaussian distributions. J. Indian Inst. Sci. 2022. [Google Scholar] [CrossRef]
- Luzzi, L.; Vehkalahti, R.; Ling, C. Almost universal codes for MIMO wiretap channels. IEEE Trans. Inf. Theory 2018, 64, 7218–7241. [Google Scholar] [CrossRef]
- Rioul, O. Variations on a Theme by Massey. IEEE Trans. Inf. Theory 2022, 68, 2813–2828. [Google Scholar] [CrossRef]
- Kagan, A.; Smith, P.J. Multivariate normal distributions, Fisher information and matrix inequalities. Int. J. Math. Educ. Sci. Technol. 2001, 32, 91–96. [Google Scholar] [CrossRef]
- Pontryagin, L.S. Topological Groups, 3rd ed.; Gordon and Breach Science Publishers: Montreux, Switzerland, 1986. [Google Scholar]
- Raghunathan, M.S. Discrete Subgroups of Lie Groups; Springer: New York, NY, USA, 1972. [Google Scholar]
- Reiter, H.; Stegeman, J.D. Classical Harmonic Analysis and Locally Compact Groups, 2nd ed.; Clarendon Press: Oxford, UK, 2000. [Google Scholar]
- Forney, G.D. Multidimensional constellations. II. Voronoi constellations. IEEE J. Sel. Areas Commun. 1989, 7, 941–958. [Google Scholar] [CrossRef]
- Boutros, J.J.; Jardel, F.; Méasson, C. Probabilistic shaping and non-binary codes. In Proceedings of the 2017 IEEE International Symposium on Information Theory (ISIT), Aachen, Germany, 25–30 June 2017; pp. 2308–2312. [Google Scholar]
- Paula, G.T. Comparison of volumes of Siegel sets and fundamental domains for SLn(ℤ). Geom. Dedicata 2019, 199, 291–306. [Google Scholar] [CrossRef]


Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).