
The Use of a Large Language Model for Cyberbullying Detection



Abstract
:1. Introduction
2. Related Work
3. Methodology
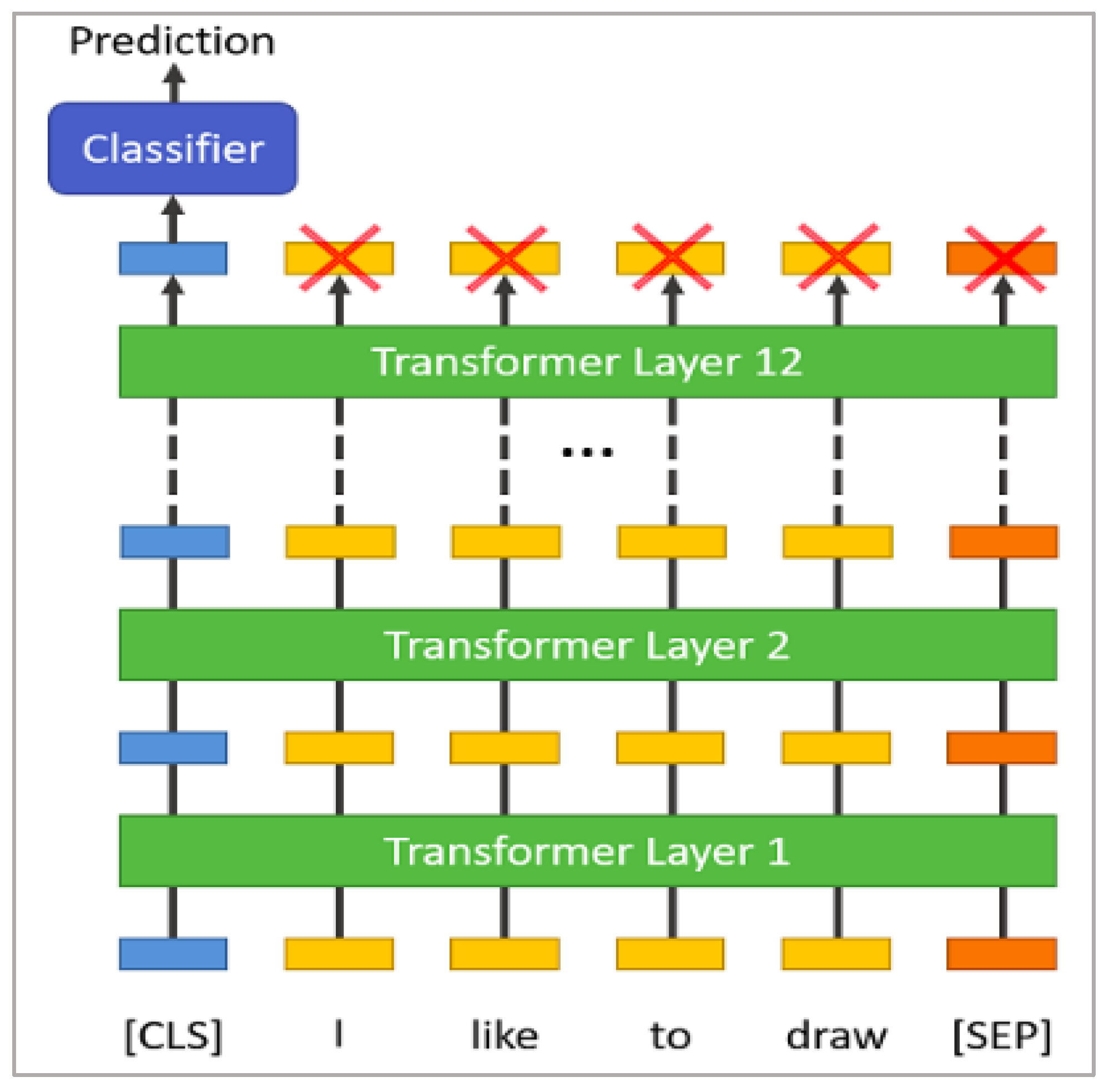
3.1. Bidirectional Encoder Representations from Transformers (BERT)
3.2. RoBERTa
3.3. XLNet
3.4. XLM-RoBERTa
3.5. Support Vector Machine
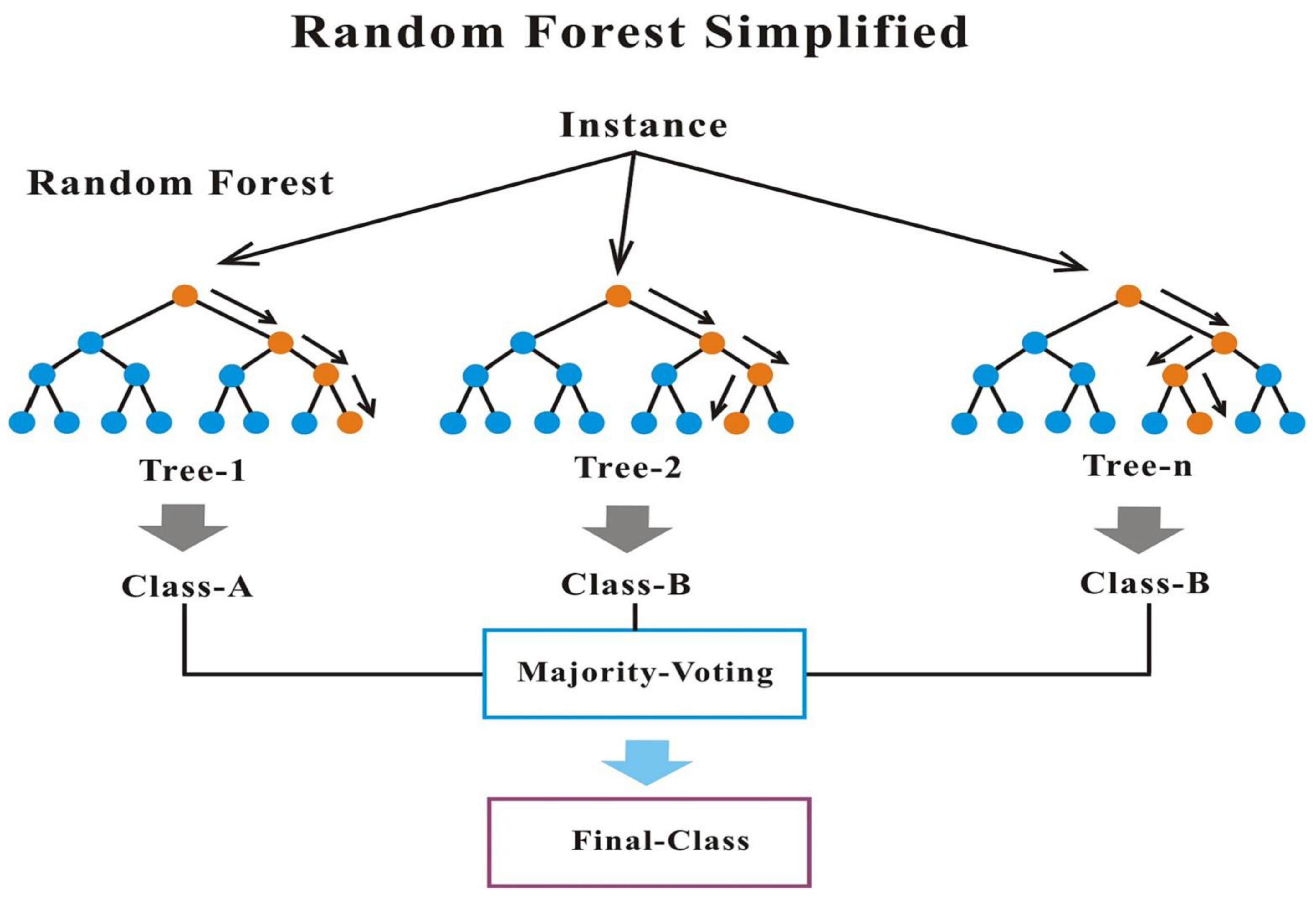
3.6. Random Forest
- Select k data points randomly;
- Build decision trees with the k data points;
- Predict y value based on aggregate of class (outcome);
- Voting or average.
3.7. Evaluation Metrics
3.8. Dataset
3.9. Experimental Setup
4. Experimental Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Pew Research Center. A Majority of Teens Have Experienced Some Form of Cyberbullying. 2018. Available online: https://www.pewresearch.org/internet/2018/09/27/a-majority-of-teens-have-experienced-some-form-ofcyberbullying/ (accessed on 16 March 2023).
- Statista. Share of Adult Internet Users in the United States Who Have Personally Experienced Online Harassment as of January 2021. 2021. Available online: https://www.statista.com/statistics/333942/us-internet-online-harassment-severity/ (accessed on 16 March 2023).
- Pew Research Center. Teens and Cyberbullying. 2022. Available online: https://www.pewresearch.org/internet/2022/12/15/teens-and-cyberbullying-2022/ (accessed on 16 March 2023).
- Office for National Statistics. Online Bullying in England and Wales; Year Ending March 2020. 2020. Available online: https://www.ons.gov.uk/peoplepopulationandcommunity/crimeandjustice/bulletins/onlinebullyinginenglandandwales/yearendingmarch2020 (accessed on 16 March 2023).
- Patchin, J.W.; Hinduja, P.D.S. Tween Cyberbullying; Cyberbullying Research Center: Jupiter, FL, USA, 2020. [Google Scholar]
- Emmery, C.; Verhoeven, B.; De Pauw, G.; Jacobs, G.; Van Hee, C.; Lefever, E.; Daelemans, W. Current limitations in cyberbullying detection: On evaluation criteria, reproducibility, and data scarcity. Lang. Resour. Eval. 2021, 55, 597–633. [Google Scholar] [CrossRef]
- Dinakar, K.; Reichart, R.; Lieberman, H. Modeling the detection of textual cyberbullying. In Proceedings of the International AAAI Conference on Web and Social Media, Barcelona, Spain, 21 July 2011; Volume 5, pp. 11–17. [Google Scholar]
- Reynolds, K.; Kontostathis, A.; Edwards, L. Using machine learning to detect cyberbullying. In Proceedings of the 10th International Conference on Machine Learning and Applications and Workshops, Honolulu, HI, USA, 18–21 December 2011; IEEE: Piscataway, NJ, USA, 2011; Volume 2, pp. 241–244. [Google Scholar]
- Aboujaoude, E.; Savage, M.W.; Starcevic, V.; Salame, W.O. Cyberbullying: Review of an old problem gone viral. J. Adolesc. Health 2015, 57, 10–18. [Google Scholar] [CrossRef]
- Xu, J.M.; Jun, K.S.; Zhu, X.; Bellmore, A. Learning from bullying traces in social media. In Proceedings of the 2012 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Montreal, QC, Canada, 3–8 June 2012; pp. 656–666. [Google Scholar]
- Huang, J.; Zhong, Z.; Zhang, H.; Li, L. Cyberbullying in social media and online games among Chinese college students and its associated factors. Int. J. Environ. Res. Public Health 2021, 18, 4819. [Google Scholar] [CrossRef]
- Hellfeldt, K.; López-Romero, L.; Andershed, H. Cyberbullying and psychological well-being in young adolescence: The potential protective mediation effects of social support from family, friends, and teachers. Int. J. Environ. Res. Public Health 2020, 17, 45. [Google Scholar] [CrossRef] [PubMed]
- Nixon, C.L. Current perspectives: The impact of cyberbullying on adolescent health. Adolesc. Health Med. Ther. 2014, 5, 143–158. [Google Scholar] [CrossRef] [PubMed]
- Jin, X.; Zhang, K.; Twayigira, M.; Gao, X.; Xu, H.; Huang, C.; Luo, X.; Shen, Y. Cyberbullying among college students in a Chinese population: Prevalence and associated clinical correlates. Front. Public Health 2023, 11, 1100069. [Google Scholar] [CrossRef]
- Karki, A.; Thapa, B.; Pradhan, P.M.S.; Basel, P. Depression, anxiety, and stress among high school students: A cross-sectional study in an urban municipality of Kathmandu, Nepal. PLoS Glob. Public Health 2022, 2, e0000516. [Google Scholar] [CrossRef]
- Piccoli, V.; Carnaghi, A.; Bianchi, M.; Grassi, M. Perceived-Social Isolation and Cyberbullying Involvement: The Role of Online Social Interaction. Int. J. Cyber Behav. Psychol. Learn. (IJCBPL) 2022, 12, 1–14. [Google Scholar] [CrossRef]
- Peng, Z.; Klomek, A.B.; Li, L.; Su, X.; Sillanmäki, L.; Chudal, R.; Sourander, A. Associations between Chinese adolescents subjected to traditional and cyber bullying and suicidal ideation, self-harm and suicide attempts. BMC Psychiatry 2019, 19, 324. [Google Scholar] [CrossRef]
- Kim, S.; Kimber, M.; Boyle, M.H.; Georgiades, K. Sex differences in the association between cyberbullying victimization and mental health, substance use, and suicidal ideation in adolescents. Can. J. Psychiatry 2019, 64, 126–135. [Google Scholar] [CrossRef]
- Zaborskis, A.; Ilionsky, G.; Tesler, R.; Heinz, A. The association between cyberbullying, school bullying, and suicidality among adolescents. Crisis 2018, 40, 100–114. [Google Scholar] [CrossRef] [PubMed]
- Islam, M.I.; Yunus, F.M.; Kabir, E.; Khanam, R. Evaluating risk and protective factors for suicidality and self-harm in Australian adolescents with traditional bullying and cyberbullying victimizations. Am. J. Health Promot. 2022, 36, 73–83. [Google Scholar] [CrossRef] [PubMed]
- Eyuboglu, M.; Eyuboglu, D.; Pala, S.C.; Oktar, D.; Demirtas, Z.; Arslantas, D.; Unsal, A. Traditional school bullying and cyberbullying: Prevalence, the effect on mental health problems and self-harm behavior. Psychiatry Res. 2021, 297, 113730. [Google Scholar] [CrossRef] [PubMed]
- Messias, E.; Kindrick, K.; Castro, J. School bullying, cyberbullying, or both: Correlates of teen suicidality in the 2011 CDC youth risk behavior survey. Compr. Psychiatry 2014, 55, 1063–1068. [Google Scholar] [CrossRef] [PubMed]
- Elsafoury, F.; Katsigiannis, S.; Pervez, Z.; Ramzan, N. When the timeline meets the pipeline: A survey on automated cyberbullying detection. IEEE Access 2021, 9, 103541–103563. [Google Scholar] [CrossRef]
- Rosa, H.; Matos, D.; Ribeiro, R.; Coheur, L.; Carvalho, J.P. A “deeper” look at detecting cyberbullying in social networks. In Proceedings of the 2018 International Joint Conference on Neural Networks (IJCNN), Rio de Janeiro, Brazil, 8–13 July 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–8. [Google Scholar]
- Rosa, H.; Pereira, N.; Ribeiro, R.; Ferreira, P.; Carvalho, J.; Oliveira, S.; Coheur, L.; Paulino, P.; Simão, A.V.; Trancoso, I. Automatic cyberbullying detection: A systematic review. Comput. Hum. Behav. 2019, 93, 333–345. [Google Scholar] [CrossRef]
- Ogunleye, B.O. Statistical Learning Approaches to Sentiment Analysis in the Nigerian Banking Context. Ph.D. Thesis, Sheffield Hallam University, Sheffield, UK, October 2021. [Google Scholar]
- Yi, P.; Zubiaga, A. Cyberbullying detection across social media platforms via platform-aware adversarial encoding. In Proceedings of the International AAAI Conference on Web and Social Media, Atlanta, GA, USA, 6–9 June 2022; Volume 16, pp. 1430–1434. [Google Scholar]
- Agrawal, S.; Awekar, A. Deep learning for detecting cyberbullying across multiple social media platforms. In Advances in Information Retrieval, Proceedings of the 40th European Conference on IR Research, ECIR 2018, Grenoble, France, 26–29 March 2018; Springer International Publishing: Cham, Switzerland, 2018; pp. 141–153. [Google Scholar]
- Di Capua, M.; Di Nardo, E.; Petrosino, A. Unsupervised cyber bullying detection in social networks. In Proceedings of the 23rd International Conference on Pattern Recognition (ICPR), Cancun, Mexico, 4–8 December 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 432–437. [Google Scholar]
- Kontostathis, A.; Reynolds, K.; Garron, A.; Edwards, L. Detecting cyberbullying: Query terms and techniques. In Proceedings of the 5th Annual ACM Web Science Conference, Paris, France, 2–4 May 2013; pp. 195–204. [Google Scholar]
- Centers for Disease Control and Prevention. Technology and Youth: Protecting Your Child from Electronic Aggression; Centers for Disease Control and Prevention: Atlanta, GA, USA, 2014. Available online: http://www.cdc.gov/violenceprevention/pdf/ea-tipsheet-a.pdf (accessed on 16 March 2023).
- Waseem, Z.; Hovy, D. Hateful symbols or hateful people? Predictive features for hate speech detection on twitter. In Proceedings of the NAACL Student Research Workshop, San Diego, CA, USA, 13–15 June 2016; pp. 88–93. [Google Scholar]
- Wulczyn, E.; Thain, N.; Dixon, L. Ex machina: Personal attacks seen at scale. In Proceedings of the 26th International Conference on World Wide Web, Perth, Australia, 3–7 April 2017; pp. 1391–1399. [Google Scholar]
- Huang, H.; Qi, D. Cyberbullying detection on social media. High. Educ. Orient. Stud. 2023, 3, 74–86. [Google Scholar]
- Alduailaj, A.M.; Belghith, A. Detecting Arabic Cyberbullying Tweets Using Machine Learning. Mach. Learn. Knowl. Extr. 2023, 5, 29–42. [Google Scholar] [CrossRef]
- Lepe-Faúndez, M.; Segura-Navarrete, A.; Vidal-Castro, C.; Martínez-Araneda, C.; Rubio-Manzano, C. Detecting Aggressiveness in Tweets: A Hybrid Model for Detecting Cyberbullying in the Spanish Language. Appl. Sci. 2021, 11, 10706. [Google Scholar] [CrossRef]
- Dewani, A.; Memon, M.A.; Bhatti, S.; Sulaiman, A.; Hamdi, M.; Alshahrani, H.; Shaikh, A. Detection of Cyberbullying Patterns in Low Resource Colloquial Roman Urdu Microtext Using Natural Language Processing, Machine Learning, and Ensemble Techniques. Appl. Sci. 2023, 13, 2062. [Google Scholar] [CrossRef]
- Suhas-Bharadwaj, R.; Kuzhalvaimozhi, S.; Vedavathi, N. A Novel Multimodal Hybrid Classifier Based Cyberbullying Detection for Social Media Platform. In Data Science and Algorithms in Systems, Proceedings of 6th Computational Methods in Systems and Software, Online, 12–15 October 2022; Springer International Publishing: Cham, Switzerland, 2022; Volume 2, pp. 689–699. [Google Scholar]
- Woo, W.H.; Chua, H.N.; Gan, M.F. Cyberbullying Conceptualization, Characterization and Detection in social media—A Systematic Literature Review. Int. J. Perceptive Cogn. Comput. 2023, 9, 101–121. [Google Scholar]
- Ogunleye, B.; Maswera, T.; Hirsch, L.; Gaudoin, J.; Brunsdon, T. Comparison of Topic Modelling Approaches in the Banking Context. Appl. Sci. 2023, 13, 797. [Google Scholar] [CrossRef]
- Zhao, A.; Yu, Y. Knowledge-enabled BERT for aspect-based sentiment analysis. Knowl.-Based Syst. 2021, 227, 107220. [Google Scholar] [CrossRef]
- Yang, N.; Jo, J.; Jeon, M.; Kim, W.; Kang, J. Semantic and explainable research-related recommendation system based on semi-supervised methodology using BERT and LDA models. Expert Syst. Appl. 2022, 190, 116209. [Google Scholar] [CrossRef]
- Lin, S.Y.; Kung, Y.C.; Leu, F.Y. Predictive intelligence in harmful news identification by BERT-based ensemble learning model with text sentiment analysis. Inf. Process. Manag. 2022, 59, 102872. [Google Scholar] [CrossRef]
- Paul, S.; Saha, S. CyberBERT: BERT for cyberbullying identification: BERT for cyberbullying identification. Multimed. Syst. 2022, 28, 1897–1904. [Google Scholar] [CrossRef]
- Yadav, J.; Kumar, D.; Chauhan, D. Cyberbullying detection using pre-trained bert model. In Proceedings of the 2020 International Conference on Electronics and Sustainable Communication Systems (ICESC), Coimbatore, India, 2–4 July 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1096–1100. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Stoyanov, V. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Yang, Z.; Dai, Z.; Yang, Y.; Carbonell, J.; Salakhutdinov, R.R.; Le, Q.V. Xlnet: Generalized autoregressive pretraining for language understanding. Adv. Neural Inf. Process. Syst. 2019, 32. [Google Scholar] [CrossRef]
- Conneau, A.; Khandelwal, K.; Goyal, N.; Chaudhary, V.; Wenzek, G.; Guzmán, F.; Stoyanov, V. Unsupervised cross-lingual representation learning at scale. arXiv 2019, arXiv:1911.02116. [Google Scholar]
- Vapnik, V. The Nature of Statistical Learning Theory; Springer Science & Business Media: Berlin/Heidelberg, Germany, 1999. [Google Scholar]
- Menon, R.V.; Chakrabarti, I. Low complexity VLSI architecture for improved primal–dual support vector machine learning core. Microprocess. Microsyst. 2023, 98, 104806. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Cao, M.; Yin, D.; Zhong, Y.; Lv, Y.; Lu, L. Detection of geochemical anomalies related to mineralization using the Random Forest model optimized by the Competitive Mechanism and Beetle Antennae Search. J. Geochem. Explor. 2023, 249, 107195. [Google Scholar] [CrossRef]
- Dinh, T.P.; Pham-Quoc, C.; Thinh, T.N.; Do Nguyen, B.K.; Kha, P.C. A flexible and efficient FPGA-based random forest architecture for IoT applications. Internet Things 2023, 22, 100813. [Google Scholar] [CrossRef]
- Koohmishi, M.; Azarhoosh, A.; Naderpour, H. Assessing the key factors affecting the substructure of ballast-less railway track under moving load using a double-beam model and random forest method. In Structures; Elsevier: Amsterdam, The Netherlands, 2023; Volume 55, pp. 1388–1405. [Google Scholar]
- Wang, J.; Fu, K.; Lu, C.T. Sosnet: A graph convolutional network approach to fine-grained cyberbullying detection. In Proceedings of the 2020 IEEE International Conference on Big Data (Big Data), Atlanta, GA, USA, 10–13 December 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1699–1708. [Google Scholar]
- Bretschneider, U.; Wöhner, T.; Peters, R. Detecting online harassment in social networks. In Proceedings of the Thirty Fifth International Conference on Information Systems, Auckland, New Zealand, 14–17 December 2014. [Google Scholar]
- Chatzakou, D.; Leontiadis, I.; Blackburn, J.; Cristofaro, E.D.; Stringhini, G.; Vakali, A.; Kourtellis, N. Detecting cyberbullying and cyberaggression in social media. ACM Trans. Web (TWEB) 2019, 13, 17. [Google Scholar] [CrossRef]
- Davidson, T.; Warmsley, D.; Macy, M.; Weber, I. Automated hate speech detection and the problem of offensive language. In Proceedings of the International AAAI Conference on Web and Social Media, Montreal, QC, Canada, 11 March 2017; Volume 11, pp. 512–515. [Google Scholar]
- Reimers, N.; Gurevych, I. Sentence-bert: Sentence embeddings using siamese bert-networks. arXiv 2019, arXiv:1908.10084. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Label | Count |
|---|---|
| Not Cyberbullying (CB) | 11,997 |
| Cyberbullying | 776 |
| Label | Count |
|---|---|
| Age | 7992 |
| Ethnicity | 7961 |
| Gender | 7973 |
| Religion | 7998 |
| Other CB | 7823 |
| Not CB | 7945 |
| Label | Count | Source | Annotation |
|---|---|---|---|
| Bullying | 19,553 | FormSpring + Twitter | Manual |
| Non-Bullying | 19,526 | FormSpring + Twitter | Manual |
| Algorithms | Class | Training Size | Accuracy (%) | Precision (%) | Recall (%) | Macro F1-Score (%) |
|---|---|---|---|---|---|---|
| TF-IDF + RF | 0 | 10,792 | 0.80 | 0.89 | 0.75 | 0.82 |
| 1 | 703 | 0.41 | 0.27 | 0.34 | ||
| TF-IDF + SVM | 0 | 10,792 | 0.84 | 0.87 | 0.85 | 0.86 |
| 1 | 703 | 0.49 | 0.43 | 0.46 | ||
| BERT | 0 | 10,792 | 0.96 | 0.98 | 0.98 | 0.98 |
| 1 | 703 | 0.66 | 0.63 | 0.64 | ||
| XLNet | 0 | 10,792 | 0.95 | 0.97 | 0.99 | 0.98 |
| 1 | 703 | 0.70 | 0.41 | 0.52 | ||
| RoBERTa | 0 | 10,792 | 0.95 | 0.98 | 0.98 | 0.98 |
| 1 | 703 | 0.63 | 0.68 | 0.66 | ||
| XLM - | 0 | 10,792 | 0.94 | 0.98 | 0.96 | 0.97 |
| RoBERTa | 1 | 703 | 0.53 | 0.68 | 0.60 |
| Algorithms | Class | Training Size | Accuracy (%) | Precision (%) | Recall (%) | Macro F1-Score (%) |
|---|---|---|---|---|---|---|
| BERT | 0 | 17,573 | 0.85 | 0.85 | 0.86 | 0.86 |
| 1 | 17,598 | 0.86 | 0.85 | 0.86 | ||
| XLNet | 0 | 17,573 | 0.86 | 0.88 | 0.84 | 0.86 |
| 1 | 17,598 | 0.84 | 0.88 | 0.86 | ||
| RoBERTa | 0 | 17,573 | 0.87 | 0.87 | 0.86 | 0.86 |
| 1 | 17,598 | 0.86 | 0.87 | 0.87 | ||
| XLM-RoBERTa | 0 | 17,573 | 0.86 | 0.86 | 0.86 | 0.86 |
| 1 | 17,598 | 0.86 | 0.86 | 0.86 | ||
| SBERT + SVM | 0 | 17,573 | 0.85 | 0.84 | 0.87 | 0.86 |
| 1 | 17,598 | 0.87 | 0.83 | 0.85 | ||
| SBERT +RF | 0 | 17,573 | 0.81 | 0.79 | 0.86 | 0.82 |
| 1 | 17,598 | 0.84 | 0.77 | 0.81 | ||
| TF-IDF + SVM | 0 | 17,573 | 0.84 | 0.84 | 0.86 | 0.85 |
| 1 | 17,598 | 0.86 | 0.83 | 0.85 | ||
| TF-IDF + RF | 0 | 17,573 | 0.84 | 0.80 | 0.90 | 0.85 |
| 1 | 17,598 | 0.88 | 0.78 | 0.83 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ogunleye, B.; Dharmaraj, B. The Use of a Large Language Model for Cyberbullying Detection. Analytics 2023, 2, 694-707. https://doi.org/10.3390/analytics2030038
Ogunleye B, Dharmaraj B. The Use of a Large Language Model for Cyberbullying Detection. Analytics. 2023; 2(3):694-707. https://doi.org/10.3390/analytics2030038
Chicago/Turabian StyleOgunleye, Bayode, and Babitha Dharmaraj. 2023. "The Use of a Large Language Model for Cyberbullying Detection" Analytics 2, no. 3: 694-707. https://doi.org/10.3390/analytics2030038
APA StyleOgunleye, B., & Dharmaraj, B. (2023). The Use of a Large Language Model for Cyberbullying Detection. Analytics, 2(3), 694-707. https://doi.org/10.3390/analytics2030038