



Toxics 2024, 12(8), 541; https://doi.org/10.3390/toxics12080541 - 26 Jul 2024
Viewed by 2012
Abstract
►
Show Figures
Endocrine-disrupting chemicals (EDCs) are chemicals that can interfere with homeostatic processes. They are a major concern for public health, and they can cause adverse long-term effects such as cancer, intellectual impairment, obesity, diabetes, and male infertility. The endocrine system is a complex machinery,
[...] Read more.
Endocrine-disrupting chemicals (EDCs) are chemicals that can interfere with homeostatic processes. They are a major concern for public health, and they can cause adverse long-term effects such as cancer, intellectual impairment, obesity, diabetes, and male infertility. The endocrine system is a complex machinery, with the estrogen (E), androgen (A), and thyroid hormone (T) modes of action being of major importance. In this context, the availability of in silico models for the rapid detection of hazardous chemicals is an effective contribution to toxicological assessments. We developed Qualitative Gene expression Activity Relationship (QGexAR) models to predict the propensities of chemically induced disruption of EAT modalities. We gathered gene expression profiles from the LINCS database tested on two cell lines, i.e., MCF7 (breast cancer) and A549 (adenocarcinomic human alveolar basal epithelial). We optimized our prediction protocol by testing different feature selection methods and classification algorithms, including CATBoost, XGBoost, Random Forest, SVM, Logistic regression, AutoKeras, TPOT, and deep learning models. For each EAT endpoint, the final prediction was made according to a consensus prediction as a function of the best model obtained for each cell line. With the available data, we were able to develop a predictive model for estrogen receptor and androgen receptor binding and thyroid hormone receptor antagonistic effects with a consensus balanced accuracy on a validation set ranging from 0.725 to 0.840. The importance of each predictive feature was further assessed to identify known genes and suggest new genes potentially involved in the mechanisms of action of EAT perturbation.
Full article

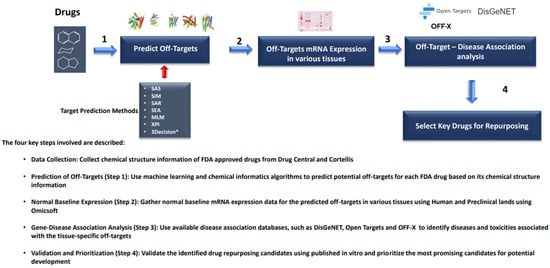
Figure 1

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}