



Toxics 2025, 13(11), 903; https://doi.org/10.3390/toxics13110903 - 22 Oct 2025
Viewed by 609
Abstract
►
Show Figures
Per- and polyfluoroalkyl substances (PFAS) are environmentally persistent organofluorines linked to cancer, organ dysfunction, and other health problems. This study used quantitative structure–property relationship (QSPR) and quantitative structure–activity relationship (QSAR) modeling to examine the binding of PFAS to estrogen receptor alpha (ERα) and
[...] Read more.
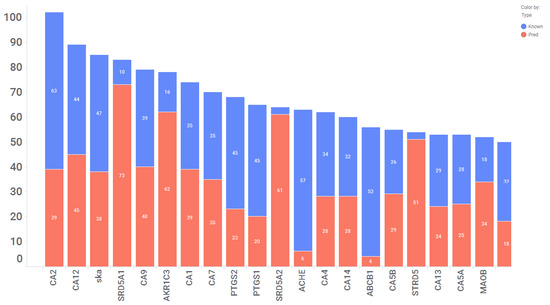
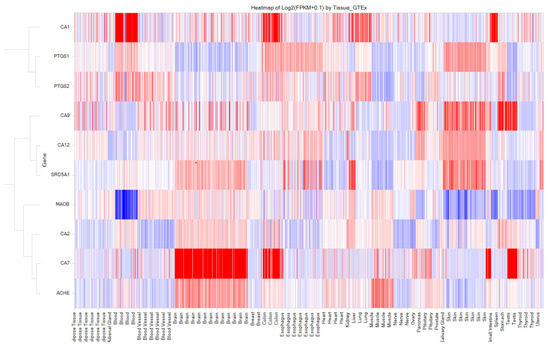
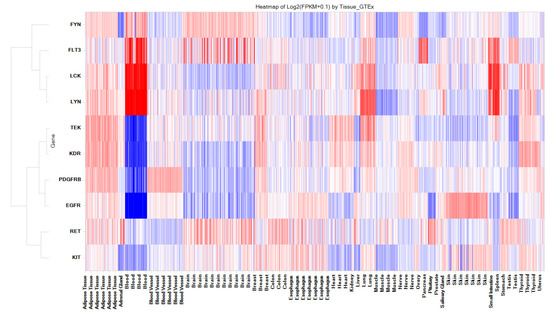
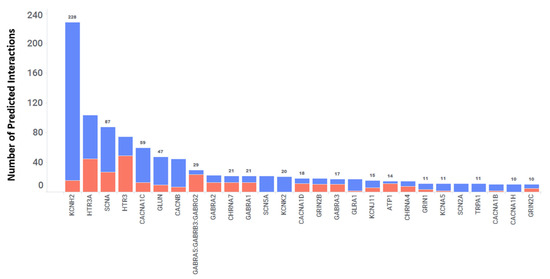
Per- and polyfluoroalkyl substances (PFAS) are environmentally persistent organofluorines linked to cancer, organ dysfunction, and other health problems. This study used quantitative structure–property relationship (QSPR) and quantitative structure–activity relationship (QSAR) modeling to examine the binding of PFAS to estrogen receptor alpha (ERα) and beta (ERβ). Molecular docking of 14,591 PFAS compounds was performed, and docking scores were used as a measure of receptor affinity. QSPR models were built for two datasets: the ERα and ERβ top binders (TBs), and a set of commonly exposed (CE) PFAS. These models quantified how chemical descriptors influence binding affinity. Across the models, higher density and electrophilicity indicated positive correlations with affinity, while surface tension indicated negative correlations. Electrostatic descriptors, including HOMO energy and positive Fukui index (F+ max), were part of the models but showed inconsistent trends. The CE QSPR models displayed correlations that conflicted with those of the TB models. Following QSPR analysis, 66 QSAR models were developed using a mix of top binders and experimental data. These models achieved strong performance, with R2 values averaging 0.95 for training sets and 0.78 for test sets, that indicated reliable predictive ability. To improve generalizability, large-set QSAR models were created for each receptor. After outlier removal, these models reached R2 values of 0.68–0.71, which supports their use in screening structurally diverse PFAS. Overall, QSPR and QSAR analyses reveal key chemical features that influence PFAS–ER binding. This predictive approach provides a scalable framework to assess the binding interactions of structurally diverse PFAS to ERs and other nuclear receptors. All the codes, data, and the GUI visualization of the results are freely available at sivaGU/QSPR-QSAR-Molecular-Visualization-Tool.
Full article

Graphical abstract



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}