
EDAR 4.0: Machine Learning and Visual Analytics for Wastewater Management

 , ,
, ,  , , , , and
, , , , and
Abstract
:1. Introduction
2. State of the Art
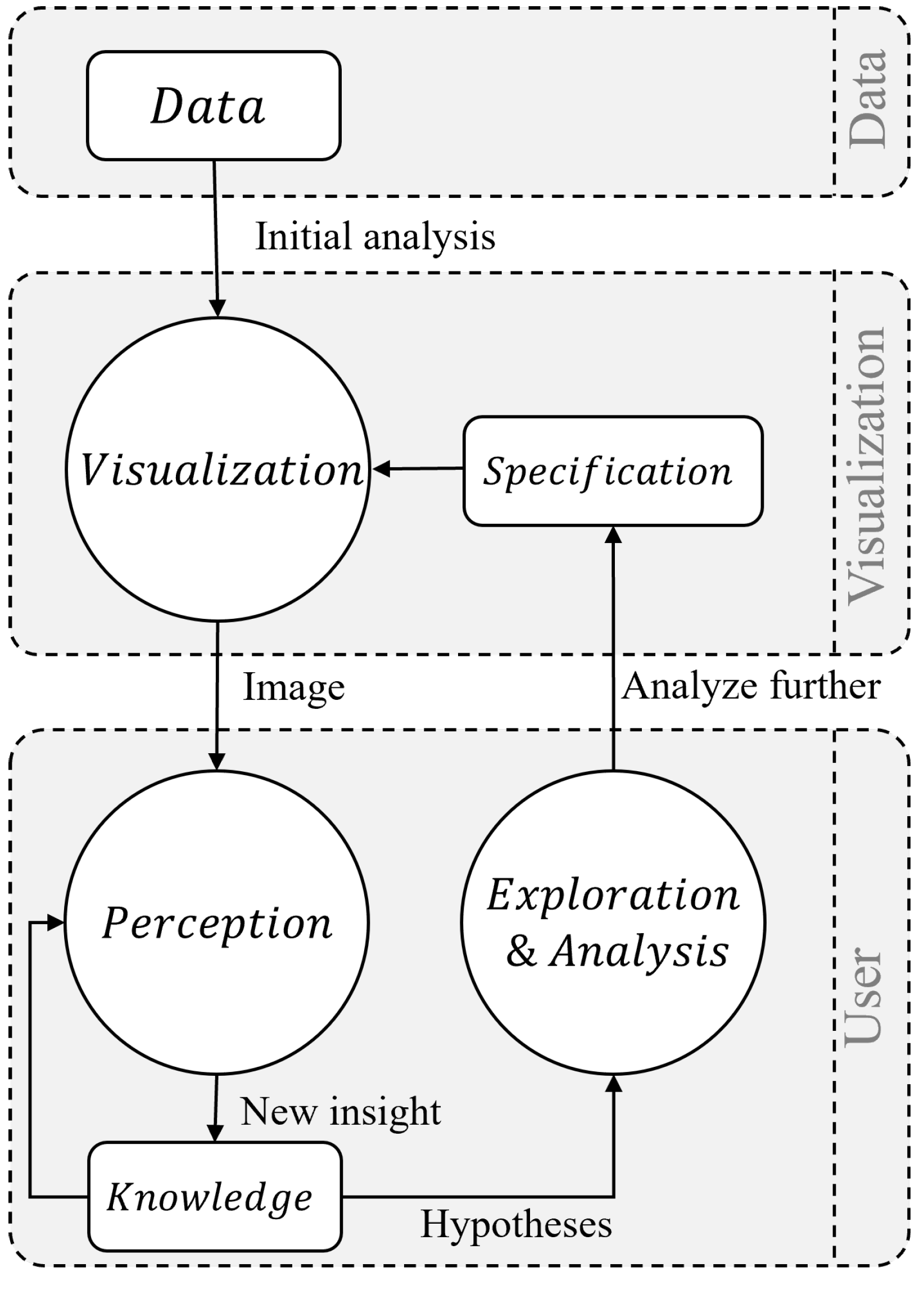
2.1. Visual Analytics
2.2. Model-Based Wastewater Management
2.3. Data-Based Wastewater Management
3. Methodology
- Data collection and acquisition. It is the process of gathering and measuring information on targeted variables; it is divided into the following activities:
- (a)
- Analysis of data origin and frequency.
- (b)
- Quantification of data uncertainty.
- (c)
- Compilation of data from various sources.
- Data management and data validation. It checks source data’s accuracy and quality before using, importing, or otherwise processing them. It is composed of the following activities:
- (a)
- Identification of the data distribution.
- (b)
- Detection of missing values.
- (c)
- Definition of erroneous data.
- (d)
- Detection and removal of outliers based on the variable analysis.
- (e)
- Detection of outliers based on physical processes.
- Data visualization. It is the graphical representation of information and data; its main activities are:
- (a)
- Exploration and visualization of data.
- (b)
- Development of intuitive, powerful visualizations.
- (c)
- Development of algorithms for the prediction of future conditions.
4. Proposed EDAR 4.0 Tool
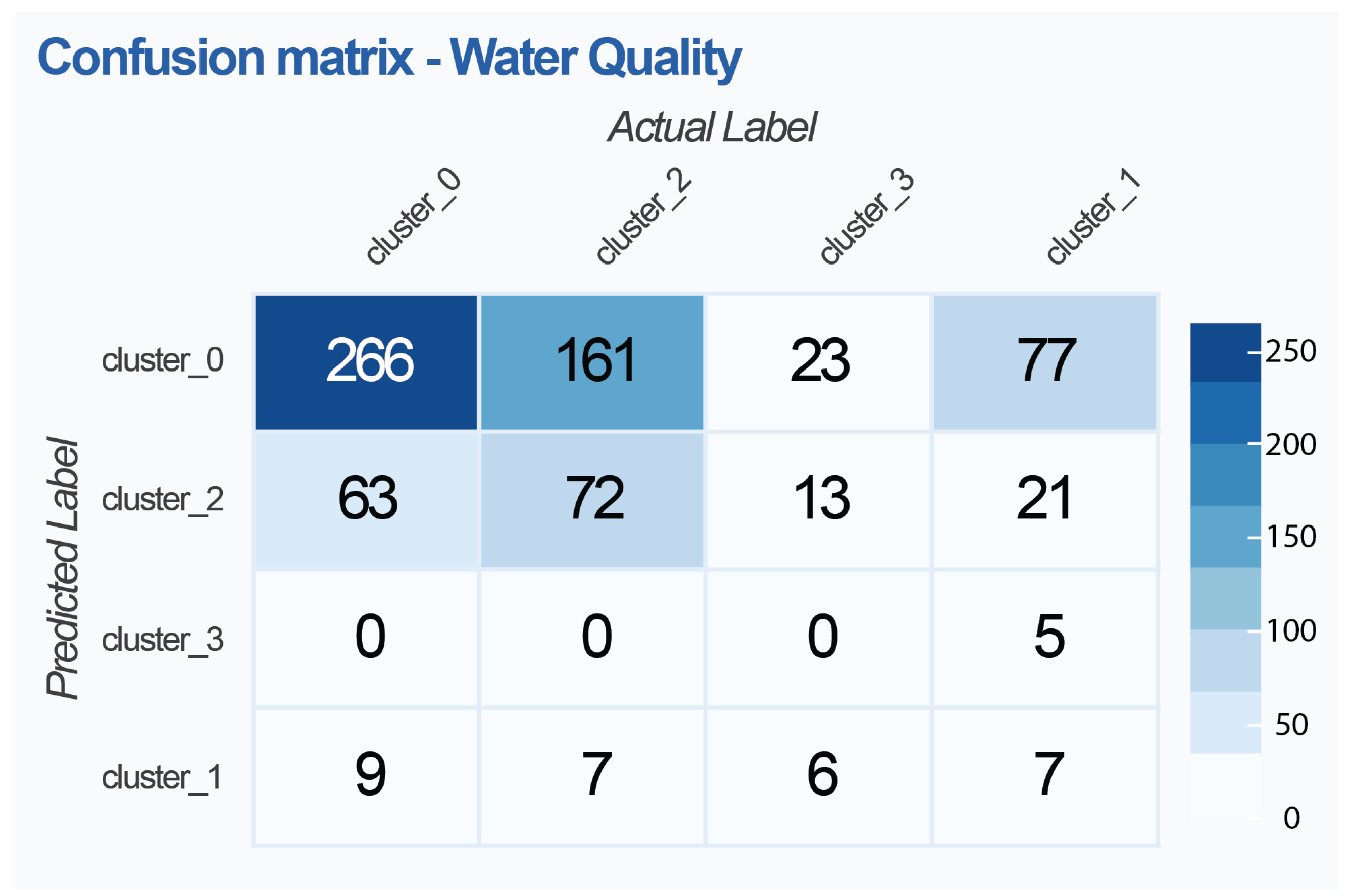
4.1. Water-Quality Monitoring
4.2. Water Quality Prediction
4.3. WWTP Model Creation & Simulation
4.4. WWTP Model Optimization
5. Discussion
- Observability: it allows monitoring of water quality through a visualization based on clustering.
- Predictability: operators can forecast how their WWTP will go.
- Risk-free evaluation: operators can validate how their system will perform if specific parameters change through simulation and optimization. it represents an essential advantage because, currently, operators are required to test their actual WWTP, which could lead to damage if their operating variables are not correctly manipulated.
- Interpretability: The decision trees and variable importance graphs help the operators better understand their WWTP behavior.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| 4IR | Fourth Industrial Revolution |
| DAE | Differential algebraic equation |
| EDA | Exploratory data analysis |
| HMI | Human–machine interface |
| ICT | Information and communication technology |
| IWA | International Water Association |
| IoT | Internet of Things |
| LAN | Local area network |
| ML | Machine learning |
| ODE | Ordinary differential equation |
| PCA | Principal component analysis |
| PLC | Programmable logic controller |
| PVA | Progressive visual analytics |
| SCADA | Supervisory control and data acquisition |
| VA | Visual analytics |
| WWTP | Wastewater treatment plant |
References
- Keim, D.; Andrienko, G.; Fekete, J.D.; Görg, C.; Kohlhammer, J.; Melançon, G. Visual Analytics: Definition, Process, and Challenges. In Information Visualization: Human-Centered Issues and Perspectives; Springer: Berlin/Heidelberg, Germany, 2008; pp. 154–175. [Google Scholar]
- Diez-Olivan, A.; Del Ser, J.; Galar, D.; Sierra, B. Data fusion and machine learning for industrial prognosis: Trends and perspectives towards Industry 4.0. Inf. Fusion 2019, 50, 92–111. [Google Scholar] [CrossRef]
- Newhart, K.B.; Holloway, R.W.; Hering, A.S.; Cath, T.Y. Data-driven performance analyses of wastewater treatment plants: A review. Water Res. 2019, 157, 498–513. [Google Scholar] [CrossRef] [PubMed]
- Luo, L.; Duan, N.; Wang, X.C.; Guo, W.; Ngo, H.H. New thermodynamic entropy calculation based approach towards quantifying the impact of eutrophication on water environment. Sci. Total Environ. 2017, 603, 86–93. [Google Scholar] [CrossRef] [PubMed]
- Maiza, M.; Odriozola, J.; Gil, A.; Naveran, G.; Basagoiti, R.; Lecuona, I.; Zurutuza, U.; Urchegi, G.; Mañas, A. Visual Analytics for supporting the Management of WWTPs. In Proceedings of the Young Water Professionals (YWP) Conference, 2017, Bilbao, Spain, 16–18 November 2017. [Google Scholar]
- European Directive 91/271/EEC; Council Directive 91/271/EEC of 21 May 1991 Concerning Urban Waste-Water Treatment. European Union Law: Brussels, Belgium, 1991.
- Cook, K.A.; Thomas, J.J. Illuminating the Path: The Research and Development Agenda for Visual Analytics; Technical Report; Pacific Northwest National Lab. (PNNL): Richland, WA, USA, 2005. [Google Scholar]
- Van Wijk, J. The value of visualization. In Proceedings of the VIS 05. IEEE Visualization, 2005, Minneapolis, MN, USA, 23–28 October 2005; pp. 79–86. [Google Scholar]
- Li, J.K.; Ma, K.L. P6: A declarative language for integrating machine learning in visual analytics. IEEE Trans. Vis. Comput. Graph. 2020, 27, 380–389. [Google Scholar] [CrossRef] [PubMed]
- Kalinin, A.A.; Palanimalai, S.; Zhu, J.; Wu, W.; Devraj, N.; Ye, C.; Ponarul, N.; Husain, S.S.; Dinov, I.D. SOCRAT: A Dynamic Web Toolbox for Interactive Data Processing, Analysis and Visualization. Information 2022, 13, 547. [Google Scholar] [CrossRef] [PubMed]
- Nawaz, A.; Arora, A.S.; Ali, W.; Saxena, N.; Khan, M.S.; Yun, C.M.; Lee, M. Intelligent Human–Machine Interface: An Agile Operation and Decision Support for an ANAMMOX SBR System at a Pilot-Scale Wastewater Treatment Plant. IEEE Trans. Ind. Inform. 2022, 18, 6224–6232. [Google Scholar] [CrossRef]
- Endert, A.; Ribarsky, W.; Turkay, C.; Wong, B.W.; Nabney, I.; Blanco, I.D.; Rossi, F. The state of the art in integrating machine learning into visual analytics. In Proceedings of the Computer Graphics Forum; Wiley Online Library: Hoboken, NJ, USA, 2017; Volume 36, pp. 458–486. [Google Scholar]
- Keim, D.A.; Munzner, T.; Rossi, F.; Verleysen, M. Bridging information visualization with machine learning (Dagstuhl Seminar 15101). In Dagstuhl Reports; Schloss Dagstuhl-Leibniz-Zentrum fuer Informatik: Wadern, Germany, 2015; Volume 5. [Google Scholar]
- Liu, S.; Wang, X.; Liu, M.; Zhu, J. Towards better analysis of machine learning models: A visual analytics perspective. Vis. Inform. 2017, 1, 48–56. [Google Scholar] [CrossRef]
- Stolper, C.D.; Perer, A.; Gotz, D. Progressive visual analytics: User-driven visual exploration of in-progress analytics. IEEE Trans. Vis. Comput. Graph. 2014, 20, 1653–1662. [Google Scholar] [CrossRef] [PubMed]
- Sun, D.; Huang, R.; Chen, Y.; Wang, Y.; Zeng, J.; Yuan, M.; Pong, T.C.; Qu, H. PlanningVis: A visual analytics approach to production planning in smart factories. IEEE Trans. Vis. Comput. Graph. 2019, 26, 579–589. [Google Scholar] [CrossRef] [PubMed]
- Wu, W.; Zheng, Y.; Chen, K.; Wang, X.; Cao, N. A visual analytics approach for equipment condition monitoring in smart factories of process industry. In Proceedings of the 2018 IEEE Pacific Visualization Symposium (PacificVis), Kobe, Japan, 10–13 April 2018; pp. 140–149. [Google Scholar]
- Jongrack, K.; Kwangtae, Y.; Wenhua, P.; Yejin, K. Modified Newton-Raphson Method to Minimize Calculation Time for Wastewater Treatment Plant Simulation. J. Korean Soc. Hazard Mitig. 2018, 18, 319–326. [Google Scholar]
- Flores-Alsina, X.; Kazadi Mbamba, C.; Solon, K.; Vrecko, D.; Tait, S.; Batstone, D.J.; Jeppsson, U.; Gernaey, K.V. A plant-wide aqueous phase chemistry module describing pH variations and ion speciation/pairing in wastewater treatment process models. Water Res. 2015, 85, 255–265. [Google Scholar] [CrossRef] [PubMed]
- Jeppsson, U.; Rosen, C.; Alex, J.; Copp, J.; Gernaey, K.V.; Pons, M.N.; Vanrolleghem, P.A. Towards a benchmark simulation model for plant-wide control strategy performance evaluation of WWTPs. Water Sci. Technol. 2006, 53, 287–295. [Google Scholar] [CrossRef] [PubMed]
- Li, Z.; Kovachki, N.; Azizzadenesheli, K.; Liu, B.; Bhattacharya, K.; Stuart, A.; Anandkumar, A. Fourier Neural Operator for Parametric Partial Differential Equations. arXiv 2020, arXiv:2010.08895. [Google Scholar]
- Matrosov, E.S.; Huskova, I.; Kasprzyk, J.R.; Harou, J.J.; Lambert, C.; Reed, P.M. Many-objective optimization and visual analytics reveal key trade-offs for London’s water supply. J. Hydrol. 2015, 531, 1040–1053. [Google Scholar] [CrossRef]
- Kim, M.; Kim, Y.; Kim, H.; Piao, W.; Kim, C. Operator decision support system for integrated wastewater management including wastewater treatment plants and receiving water bodies. Environ. Sci. Pollut. Res. Int. 2016, 23, 10785–10798. [Google Scholar] [CrossRef] [PubMed]
- Heo, S.; Nam, K.; Loy-Benitez, J.; Yoo, C. Data-Driven Hybrid Model for Forecasting Wastewater Influent Loads Based on Multimodal and Ensemble Deep Learning. IEEE Trans. Ind. Inform. 2021, 17, 6925–6934. [Google Scholar] [CrossRef]
- Jafar, R.; Awad, A.; Jafar, K.; Shahrour, I. Predicting Effluent Quality in Full-Scale Wastewater Treatment Plants Using Shallow and Deep Artificial Neural Networks. Sustainability 2022, 14, 15598. [Google Scholar] [CrossRef]
- Shao, S.; Fu, D.; Yang, T.; Mu, H.; Gao, Q.; Zhang, Y. Analysis of Machine Learning Models for Wastewater Treatment Plant Sludge Output Prediction. Sustainability 2023, 15, 13380. [Google Scholar] [CrossRef]
- Piao, W.; Kim, C.; Cho, S.; Kim, H.; Kim, M.; Kim, Y. Development of a protocol to optimize electric power consumption and life cycle environmental impacts for operation of wastewater treatment plant. Environ. Sci. Pollut. Res. Int. 2016, 23, 25451–25466. [Google Scholar] [CrossRef] [PubMed]
- AvRuskin, G.A.; Jacquez, G.M.; Meliker, J.R.; Slotnick, M.J.; Kaufmann, A.M.; Nriagu, J.O. Visualization and exploratory analysis of epidemiologic data using a novel space time information system. Int. J. Health Geogr. 2004, 3, 26. [Google Scholar] [CrossRef] [PubMed]
- Ghosh, A.; Nashaat, M.; Miller, J.; Quader, S.; Marston, C. A comprehensive review of tools for exploratory analysis of tabular industrial datasets. Vis. Inform. 2018, 2, 235–253. [Google Scholar] [CrossRef]
- Anderberg, M. Cluster Analysis for Applications: Probability and Mathematical Statistics: A Series of Monographs and Textbooks; Probability and Mathematical Statistics; Elsevier Science: Amsterdam, The Netherlands, 2014. [Google Scholar]
- Haggarty, R.; Miller, C.; Scott, E.; Wyllie, F.; Smith, M. Functional clustering of water quality data in Scotland. Environmetrics 2012, 23, 685–695. [Google Scholar] [CrossRef]
- Wong, H.; Hu, B. Application of interval clustering approach to water quality evaluation. J. Hydrol. 2013, 491, 1–12. [Google Scholar] [CrossRef]
- Vo-Van, T.; Nguyen-Hai, A.; Tat-Hong, M.V.; Nguyen-Trang, T. A New Clustering Algorithm and Its Application in Assessing the Quality of Underground Water. Sci. Program. 2020, 2020, 6458576. [Google Scholar] [CrossRef]
- Saary, M.J. Radar plots: A useful way for presenting multivariate health care data. J. Clin. Epidemiol. 2008, 61, 311–317. [Google Scholar] [CrossRef]
- Velasquez, D.; Toro, M.; Bruse, J.L.; Oregui, X.; Maiza, M.; Sierra, B. A Novel Architecture Definition for AI-Driven Industry 4.0 Applications. In Proceedings of the 2023 International Conference on Intelligent Computing and Control (IC&C), Wuhan, China, 24–26 February 2023; pp. 25–31. [Google Scholar]
- Fortuna, L.; Rizzotto, G.; Lavorgna, M.; Nunnari, G.; Xibilia, M.G.; Caponetto, R. Evolutionary Optimization Algorithms. In Soft Computing: New Trends and Applications; Springer: London, UK, 2001; pp. 97–116. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Absolute Values | Performances |
|---|---|---|
| 25 mg/L | 70% | |
| 125 mg/L | 75% | |
| 10 mg/L | 90% | |
| 1 mg/L | 80% | |
| 35 mg/L | 70% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Velásquez, D.; Vallejo, P.; Toro, M.; Odriozola, J.; Moreno, A.; Naveran, G.; Giraldo, M.; Maiza, M.; Sierra, B. EDAR 4.0: Machine Learning and Visual Analytics for Wastewater Management. Sustainability 2024, 16, 3578. https://doi.org/10.3390/su16093578
Velásquez D, Vallejo P, Toro M, Odriozola J, Moreno A, Naveran G, Giraldo M, Maiza M, Sierra B. EDAR 4.0: Machine Learning and Visual Analytics for Wastewater Management. Sustainability. 2024; 16(9):3578. https://doi.org/10.3390/su16093578
Chicago/Turabian StyleVelásquez, David, Paola Vallejo, Mauricio Toro, Juan Odriozola, Aitor Moreno, Gorka Naveran, Michael Giraldo, Mikel Maiza, and Basilio Sierra. 2024. "EDAR 4.0: Machine Learning and Visual Analytics for Wastewater Management" Sustainability 16, no. 9: 3578. https://doi.org/10.3390/su16093578