Estimation of Suspended Sediment Loads Using Copula Functions





Abstract
1. Introduction
2. Materials and Methods
2.1. Study Area
2.2. Data
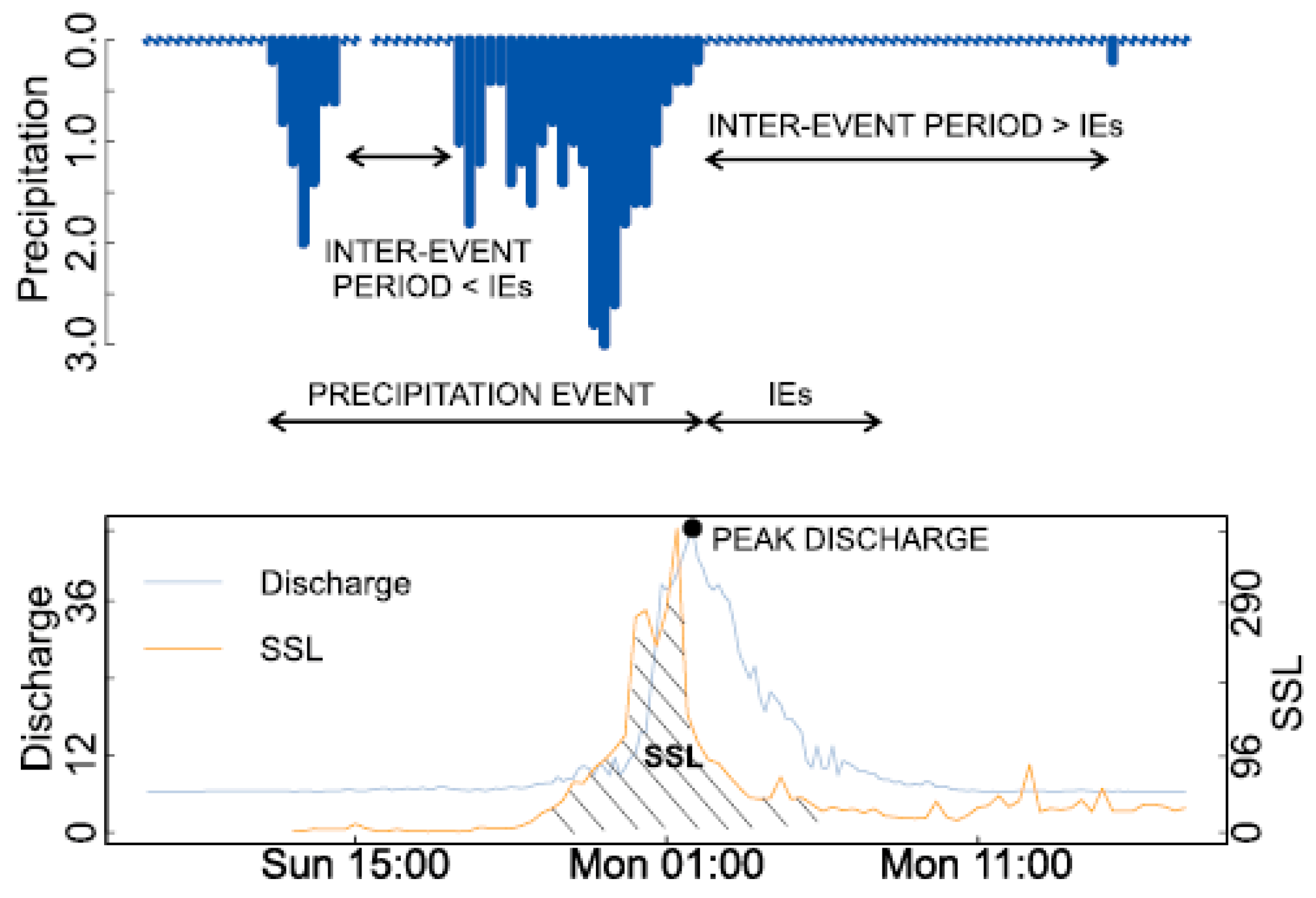
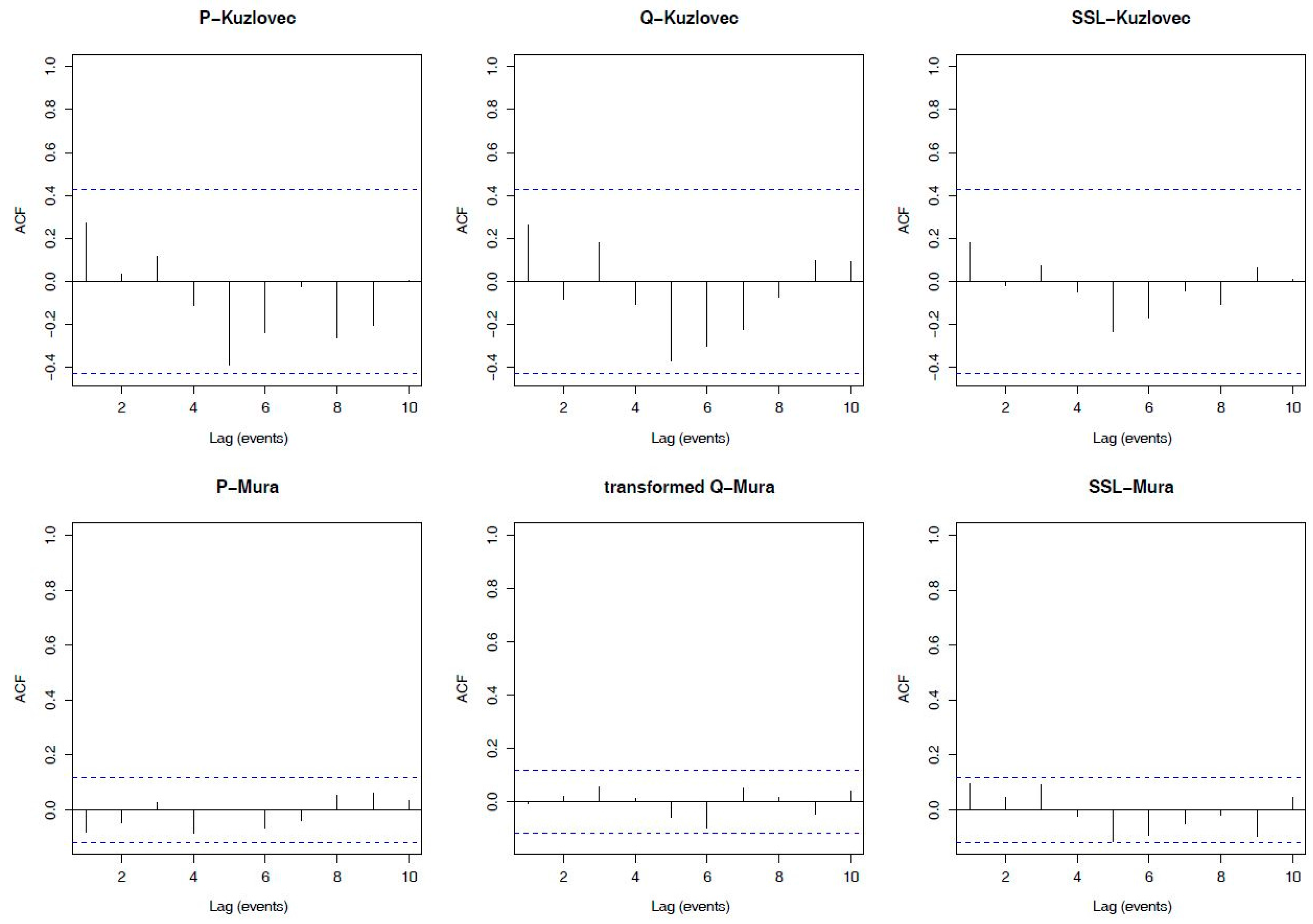
2.3. An Event-Based Sample Selection Methodology
2.4. Copula Function
- For each measured (known) pair of variables Q and P 10,000 uniform random variables [0, 1] were generated;
- For each of the 10,000 uniform randomly generated variables, Equation (7) was solved numerically using the Newton’s method for solving nonlinear equations [72];
- For each of the solutions of Equation (7), the inverse Probability Integral Transform (PIT) () was used to transform the solution from the copula space [0, 1] to the real space and consequently estimate the SSL value.
- For each known pair of variables Q and P, which corresponds to the specific event, a sample of 10,000 possible SSL values was obtained.
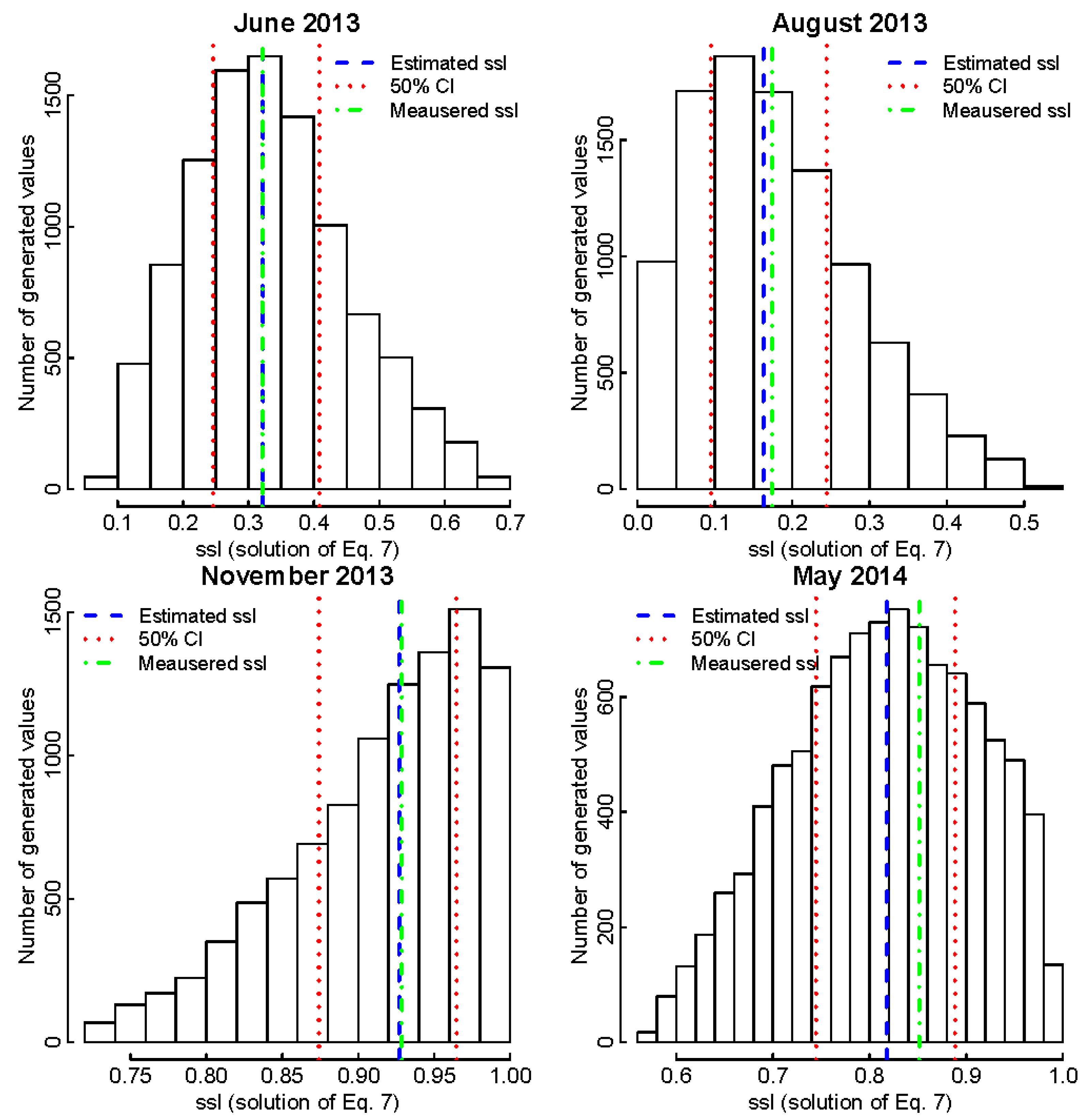
- The median value of all 10,000 possible SSL values was selected as the estimated SSL value and 50% confidence intervals for each event were also determined. Alternatively, the mode could be selected as the most likely value in some other cases.
2.5. Regression Models and Performance Criteria
3. Results and Discussion
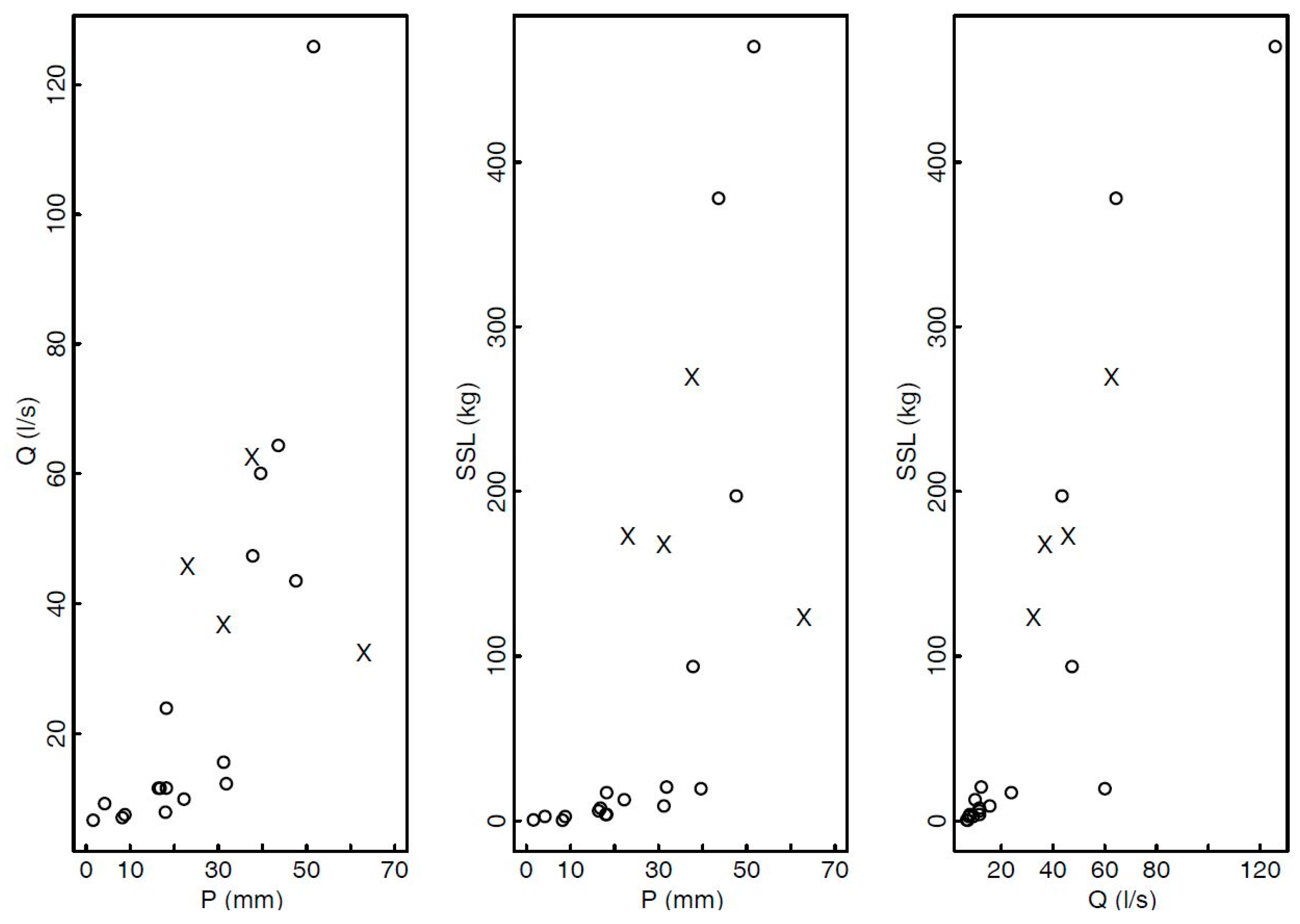
3.1. Kuzlovec Torrent
3.1.1. Estimation of Copula Model Parameters for the Kuzlovec Torrent
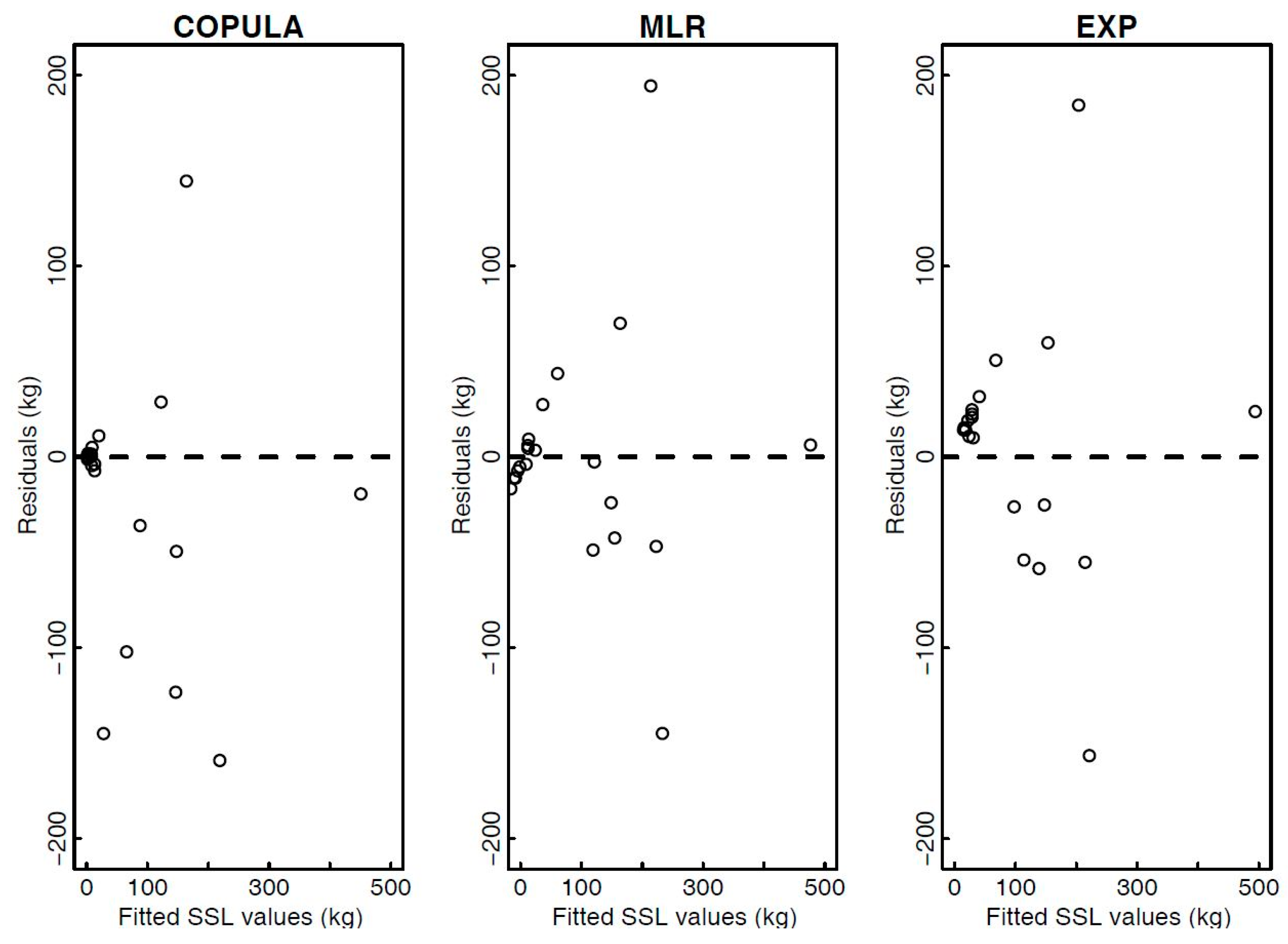
3.1.2. Comparison with Other SSL Estimation Techniques and Estimation of SSL Values Based on Measured Q and P
3.2. Gornja Radgona Station on the Mura River
3.2.1. Estimation of Copula Model Parameters for the Gornja Radgona Station
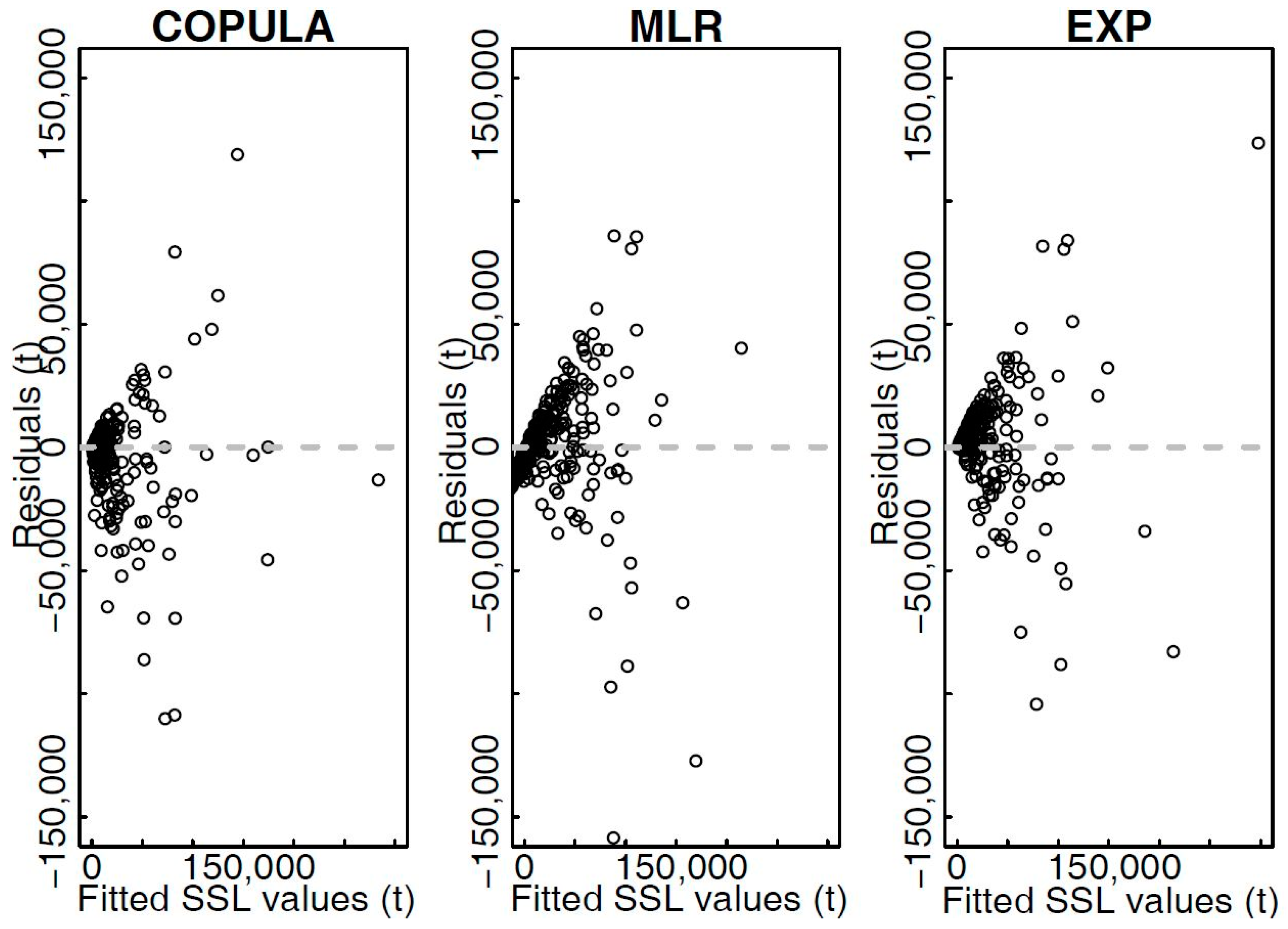
3.2.2. Comparison with Other SSL Estimation Techniques
4. Conclusions
- The proposed copula model for estimating the SSL values based on the measured Q and P values yielded meaningful results. According to some performance criteria and graphical presentation of the results the copula model gives comparable results to those obtained using other tested models (MLR and EXP). For the Gornja Radgona station the copula model yielded better fit to the actual measured SSL values than other tested methods. In this case study 281 events were available to estimate the copula model parameters and nonparametric distributions were selected as marginal distributions. However, for the Kuzlovec torrent much smaller number of events was analyzed and parametric distribution functions were used. The differences in the estimation results could also be a consequence of different copulas that were selected (symmetric and Khoudraji-Liebscher copulas). Using the copula model the probabilistic estimation of the SSL values can be obtained, which is not possible using other tested methods. Moreover, the smallest residual values were characteristic of the estimation procedure that was carried out using copula function, which indicates an important advantage of the proposed copula method compared to other tested methods. However, there were some differences between the low-medium and medium-high magnitude SSL events.
- The proposed copula based model is flexible. Both symmetric and Khoudraji-Liebscher copula functions were used to construct the copula model based on the dependence characteristics of the analyzed variables. Furthermore, other copula functions with more parameters and different properties such as Gaussian copula or Vine copulas could be used in this model to estimate the SSL values based on the Q and P. Similarly, also different marginal distribution functions can be selected, even nonparametric. The proposed copula model where nonparametric marginal distribution functions were used is more robust tool that is not significantly affected by transformations of the marginal data.
- An event-based copula model used in this study could easily be upgraded with additional variables (e.g., bedload, water electrical conductivity measurements, antecedent sediment transport conditions or antecedent soil moisture), because copula functions of higher dimensions can be constructed relatively easily. Moreover, similar model could also be used for the estimation of different environmental variables (e.g., biogeochemical model-water chemistry).
- Unlike some other techniques, the presented event-based model also captures the sediment lag effect. In the future it would be reasonable to consider also the sediment depletion (exhaustion) effect (e.g., antecedent sediment transport), which can have a considerable impact on the SSL values during consecutive events.
- The proposed event-based copula model can be a useful tool for estimating sediment budgets. The methodology was successfully applied to two different case studies, a small forested torrent and a larger river catchment and comparable results were obtained in both cases (in first case 20-min data was used while in the second case daily data was used).
Acknowledgments
Author Contributions
Conflicts of Interest
Appendix A
References
- Lenzi, M.A.; Mao, L.; Comiti, F. Interannual variation of suspended sediment load and sediment yield in an alpine catchment. Hydrol. Sci. J. 2003, 48, 899–915. [Google Scholar] [CrossRef]
- Tena, A.; Batalla, R.J.; Vericat, D.; Lopez-Tarazon, J.A. Suspended sediment dynamics in a large regulated river over a 10-year period (the lower Ebro, NE Iberian Peninsula). Geomorphology 2011, 125, 73–84. [Google Scholar] [CrossRef]
- Gorgoglione, A.; Gioia, A.; Iacobellis, V.; Ferruccio Piccinni, A.; Ranieri, E. A Rationale for Pollutograph Evaluation in Ungauged Areas, Using Daily Rainfall Patterns: Case Studies of the Apulian Region in Southern Italy. Appl. Environ. Soil Sci. 2016. [Google Scholar] [CrossRef]
- Bezak, N.; Šraj, M.; Mikoš, M. Analyses of suspended sediment loads in Slovenian rivers. Hydrol. Sci. J. 2016, 61, 1094–1108. [Google Scholar] [CrossRef]
- Ulaga, F. Monitoring suspendiranega materiala v slovenskih rekah monitoring of suspended matter in Slovenian rivers. Acta Hydrotech. 2005, 23, 117–127. (In Slovene) [Google Scholar]
- Gray, J.R.; Gartner, J.W. Technological advances in suspended-sediment surrogate monitoring. Water Resour. Res. 2009, 45, 20. [Google Scholar] [CrossRef]
- Wren, D.G.; Barkdoll, B.D.; Kuhnle, R.A.; Derrow, R.W. Field techniques for suspended-sediment measurement. J. Hydraul. Eng. 2000, 126, 97–104. [Google Scholar] [CrossRef]
- Lenzi, M.A.; D’Agostino, V.; Billi, P. Bedload transport in the instrumented catchment of the Rio Cordon Part I: Analysis of bedload records, conditions and threshold of bedload entrainment. Catena 1999, 36, 171–190. [Google Scholar] [CrossRef]
- Lenzi, M.A.; Marchi, L. Suspended sediment load during floods in a small stream of the Dolomites (northeastern Italy). Catena 2000, 39, 267–282. [Google Scholar] [CrossRef]
- Rickenmann, D. Sediment transport in Swiss torrents. Earth Surf. Process. Landf. 1997, 22, 937–951. [Google Scholar] [CrossRef]
- Soler, M.; Latron, J.; Gallart, F. Relationships between suspended sediment concentrations and discharge in two small research basins in a mountainous Mediterranean area (Vallcebre, Eastern Pyrenees). Geomorphology 2008, 98, 143–152. [Google Scholar] [CrossRef]
- Habersack, H.M.; Laronne, J.B. Bed load texture in an alpine gravel bed river. Water Resour. Res. 2001, 37, 3359–3370. [Google Scholar] [CrossRef]
- Bonacci, O.; Oskorus, D. The changes in the lower Drava River water level, discharge and suspended sediment regime. Environ. Earth Sci. 2010, 59, 1661–1670. [Google Scholar] [CrossRef]
- Harrington, S.T.; Harrington, J.R. An assessment of the suspended sediment rating curve approach for load estimation on the Rivers Bandon and Owenabue, Ireland. Geomorphology 2013, 185, 27–38. [Google Scholar] [CrossRef]
- Horowitz, A. An evaluation of sediment rating curves for estimating suspended sediment concentrations for subsequent flux calculations. Hydrol. Process. 2003, 17, 3387–3409. [Google Scholar] [CrossRef]
- Horowitz, A. Determining annual suspended sediment and sediment-associated trace element and nutrient fluxes. Sci. Total Environ. 2008, 400, 315–343. [Google Scholar] [CrossRef] [PubMed]
- Araujo, H.A.; Cooper, A.B.; Hassan, M.A.; Venditti, J. Estimating suspended sediment concentrations in areas with limited hydrological data using a mixed-effects model. Hydrol. Process. 2012, 26, 3678–3688. [Google Scholar] [CrossRef]
- Khanchoul, K.; El Abidine Boukhrissa, Z.; Acidi, A.; Altschul, R. Estimation of suspended sediment transport in the Kebir drainage basin, Algeria. Quat. Int. 2012, 262, 25–31. [Google Scholar] [CrossRef]
- Holtschlag, D.J. Optimal estimation of suspended-sediment concentrations in streams. Hydrol. Process. 2001, 15, 1133–1155. [Google Scholar] [CrossRef]
- Moliere, D.R.; Evans, K.G.; Saynor, M.J.; Erskine, W.D. Estimation of suspended sediment loads in a seasonal stream in the wet-dry tropics, Northern Territory, Australia. Hydrol. Process. 2004, 18, 531–544. [Google Scholar] [CrossRef]
- Nourani, V. Using artificial neural networks (ANNs) for sediment load forecasting of Talkherood River mouth. J. Urban Environ. Eng. 2009, 3, 1–6. [Google Scholar] [CrossRef]
- Rajaee, R.; Mirbagheri, S.A.; Zounemar-Kermani, M.; Nourani, V. Daily suspended sediment concentration simulation using ANN and neuro-fuzzy models. Sci. Total Environ. 2009, 12, 4916–4927. [Google Scholar] [CrossRef] [PubMed]
- Senthil Kumar, A.R.; Ojha, C.S.P.; Goyal, M.K.; Singh, R.D.; Swamee, P.K. Modeling of Suspended Sediment Concentration at Kasol in India Using ANN, Fuzzy Logic, and Decision Tree Algorithms. J. Hydrol. Eng. 2012, 17, 394–404. [Google Scholar] [CrossRef]
- Lafdani, E.K.; Nia, A.M.; Ahmadi, A. Daily suspended sediment load prediction using artificial neural networks and support vector machines. J. Hydrol. 2013, 478, 50–62. [Google Scholar] [CrossRef]
- McBean, E.A.; Al-Nassri, S. Uncertainty in Suspended Sediment Transport Curves. J. Hydrol. Eng. 1988, 114, 63–74. [Google Scholar] [CrossRef]
- Isik, S. Regional rating curve models of suspended sediment transport for Turkey. Earth Sci. Inform. 2013, 6, 87–98. [Google Scholar] [CrossRef]
- Tramblay, Y.; Ouarda, T.B.M.J.; St-Hilaire, A.; Poulin, J. Regional estimation of extreme suspended sediment concentrations using watershed characteristics. J. Hydrol. 2010, 380, 305–317. [Google Scholar] [CrossRef]
- Roman, D.C.; Vogel, R.M.; Schwarz, G.E. Regional regression models of watershed suspended-sediment discharge for the eastern United States. J. Hydrol. 2012, 472–473, 53–62. [Google Scholar] [CrossRef]
- Grimaldi, S.; Serinaldi, F. Asymmetric copula in multivariate flood frequency analysis. Adv. Water Resour. 2006, 29, 1155–1167. [Google Scholar] [CrossRef]
- Durante, F.; Salvadori, G. On the construction of multivariate extreme value models via copulas. Environmetrics 2010, 21, 143–161. [Google Scholar] [CrossRef]
- Chebana, F.; Ouarda, T.B.M.J. Multivariate quantiles in hydrological frequency analysis. Environmetrics 2011, 22, 63–78. [Google Scholar] [CrossRef]
- Bezak, N.; Mikoš, M.; Šraj, M. Trivariate Frequency Analyses of Peak Discharge, Hydrograph Volume and Suspended Sediment Concentration Data Using Copulas. Water Resour. Manag. 2014, 28, 2195–2212. [Google Scholar] [CrossRef]
- Šraj, M.; Bezak, N.; Brilly, M. Bivariate flood frequency analysis using the copula function: A case study of the Litija station on the Sava River. Hydrol. Process. 2015, 29, 225–238. [Google Scholar] [CrossRef]
- Grimaldi, S.; Serinaldi, F. Design hyetograph analysis with 3-copula function. Hydrol. Sci. J. 2006, 51, 223–238. [Google Scholar] [CrossRef]
- Singh, V.P.; Zhang, L. IDF curves using the Frank Archimedean copula. J. Hydrol. Eng. 2007, 12, 651–662. [Google Scholar] [CrossRef]
- Bardossy, A.; Li, J. Geostatistical interpolation using copulas. Water Resour. Res. 2008, 44. [Google Scholar] [CrossRef]
- Corbella, S.; Stretch, D.D. Simulating a multivariate sea storm using Archimedean copulas. Coast. Eng. 2013, 76, 68–78. [Google Scholar] [CrossRef]
- Salvadori, G.; De Michele, C. Frequency analysis via copulas: Theoretical aspects and applications to hydrological events. Water Resour. Res. 2004, 40. [Google Scholar] [CrossRef]
- Salvadori, G.; De Michele, C.; Kottegoda, N.T.; Rosso, R. Extremes in Nature: An Approach Using Copulas; Springer: Dordrecht, The Netherlands, 2007. [Google Scholar]
- Wong, G.; Lambert, M.F.; Leonard, M.; Metcalfe, A.V. Drought Analysis Using Trivariate Copulas Conditional on Climatic States. J. Hydrol. Eng. 2010, 15, 129–141. [Google Scholar] [CrossRef]
- Callau Poduje, A.C.; Belli, A.; Haberlandt, U. A Dam risk assessment based on univariate versus bivariate statistical approaches: A case study for Argentina. Hydrol. Sci. J. 2014, 59, 2216–2232. [Google Scholar] [CrossRef]
- STAHY. Available online: http://www.stahy.org/Activities/STAHYReferences/ReferencesonCopulaFunctiontopic/tabid/78/Default.aspx (accessed on 15 July 2017).
- Shiau, J.T.; Chen, T.J. Quantile Regression-Based Probabilistic Estimation Scheme for Daily and Annual Suspended Sediment Loads. Water Resour. Manag. 2015, 29, 2805–2818. [Google Scholar] [CrossRef]
- Šraj, M.; Rusjan, S.; Petan, S.; Vidmar, A.; Mikoš, M.; Globevnik, L.; Brilly, M. The experimental watersheds in Slovenia. IOP Conf. Ser. 2008, 4, 1–13. [Google Scholar] [CrossRef]
- Agencija Republike Slovenije za Okolje (ARSO). Available online: http://www.arso.gov.si/ (accessed on 10 January 2017).
- Bezak, N.; Šraj, M.; Rusjan, S.; Kogoj, M.; Vidmar, A.; Sečnik, M.; Brilly, M.; Mikoš, M. Comparison between two adjacent experimental torrential watersheds: Kuzlovec and Mačkov graben. Acta Hydrotech. 2013, 26, 85–97. (In Slovene) [Google Scholar]
- American Institute of Hydrology. Coastal Hydrology and Processes: Proceedings of the AIH 25th Anniversary Meeting & International Conference “Challenges in Coastal Hydrology and Water Quality”; Singh, V.P., Xu, Y.J., Eds.; Water Resources Publications: Highland Ranch, CO, USA, 2006; 509p. [Google Scholar]
- R Development Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2015. [Google Scholar]
- Miao, C.; Ni, J. Implement of filter to remove the autocorrelation’s influence on the Mann-Kendall test: A case in hydrological series. J. Food Agric. Environ. 2010, 8, 1241–1246. [Google Scholar]
- Hyndman, R.J.; Athanasopoulos, G. Forecasting: Principles and Practice; Otexts: Melbourne, Australia, 2013. [Google Scholar]
- Hipel, K.W.; McLeod, A.T. Time Series Modelling of Water Resources and Environmental Systems; Elsevier Science: Amsterdam, The Netherlands, 1994. [Google Scholar]
- Sklar, A. Fonction de répartition à n dimensions et leurs marges. Publications de L’Institute de Statistique 1959, 8, 229–231. [Google Scholar]
- Joe, H. Multivariate Models and Dependence Concepts; Chapman & Hall: London, UK; New York, NY, USA, 1997. [Google Scholar]
- Nelsen, R.B. An Introduction to Copulas; Springer: New York, NY, USA, 2006. [Google Scholar]
- Durante, F.; Sempi, C. Principles of Copula Theory; CRC/Chapman & Hall: Boca Raton, FL, USA, 2015. [Google Scholar]
- Genest, C.; Favre, A. Everything You Always Wanted to Know about Copula Modeling but Were Afraid to Ask. J. Hydrol. Eng. 2007, 12, 347–368. [Google Scholar] [CrossRef]
- Salvadori, G.; Durante, F.; Tomasicchio, G.R.; D’Alessandro, F. Practical guidelines for the multivariate assessment of the structural risk in coastal and off-shore engineering. Coast. Eng. 2015, 95, 77–83. [Google Scholar] [CrossRef]
- Pappada, R.; Durante, F.; Salvadori, G. Quantification of the environmental structural risk with spoiling ties: Is randomization worthwhile? Stoch. Environ. Res. Risk Assess. 2016. [Google Scholar] [CrossRef]
- Khoudraji, A. Contributions à L’étude des Copules et àla Modélisation des Valeurs Extremes Bivariées. Ph.D. Thesis, Université Laval, Quebec City, QC, Canada, 1995. [Google Scholar]
- Liebscher, E. Construction of asymmetric multivariate copulas. J. Multivar. Anal. 2008, 99, 2234–2250. [Google Scholar] [CrossRef]
- Salvadori, G.; De Michele, C. Multivariate multiparameter extreme value models and return periods: A copula approach. Water Resour. Res. 2010, 46. [Google Scholar] [CrossRef]
- Genest, C.; Ghoudi, K.; Rivest, L.P. A semiparametric estimation procedure of dependence parameters in multivariate families of distributions. Biometrika 1995, 82, 543–552. [Google Scholar] [CrossRef]
- Genest, C.; Remillard, B.; Beaudoin, D. Goodness-of-fit tests for copulas: A review and a power study. Insur. Math. Econ. 2009, 44, 199–213. [Google Scholar] [CrossRef]
- Kojadinovic, I.; Yan, J. Modeling Multivariate Distributions with Continuous Margins Using the copula R Package. J. Stat. Softw. 2010, 34. [Google Scholar] [CrossRef]
- Grønneberg, S.; Hjort, N.L. The copula information criteria. Scand. J. Stat. 2014, 41, 436–459. [Google Scholar] [CrossRef]
- Hosking, J.R.M.; Wallis, J.R. Regional Frequency Analysis: An Approach Based on L-Moments; Cambridge University Press: Cambridge, UK, 1997. [Google Scholar]
- Lmomco Package: Program R. Available online: https://cran.r-project.org/web/packages/lmomco/lmomco.pdf (accessed on 15 July 2017).
- Serinaldi, F. Analytical confidence intervals for index flow duration curves. Water Resour. Res. 2011, 47. [Google Scholar] [CrossRef]
- Serinaldi, F.; Grimaldi, S.; Abdolhosseini, M.; Corona, P.; Cimini, D. Testing copula regression against benchmark models for point and interval estimation of tree wood volume in beech stands. Eur. J. For. Res. 2012, 131, 1313–1326. [Google Scholar] [CrossRef]
- Serinaldi, F. Assessing the applicability of fractional order statistics for computing confidence intervals for extreme quantiles. J. Hydrol. 2009, 376, 528–541. [Google Scholar] [CrossRef]
- Hutson, A.D. A semi-parametric quantile function estimator for use in bootstrap estimation procedures. Stat. Comput. 2002, 12, 331–338. [Google Scholar] [CrossRef]
- Wolfram Research, Inc. Mathematica, Version 8.0; Wolfram Research, Inc.: Champaign, IL, USA, 2010. [Google Scholar]
- Palynchuk, B.; Guo, Y. Threshold analysis of rainstorm depth and duration statistics at Toronto, Canada. J. Hydrol. 2008, 348, 535–545. [Google Scholar] [CrossRef]
- Segoni, S.; Rosi, A.; Rossi, G.; Catani, F.; Casagli, N. Analysing the relationship between rainfalls and landslides to define a mosaic of triggering thresholds for regional-scale warning systems. Nat. Hazards Earth Syst. Sci. 2014, 14, 2637–2648. [Google Scholar] [CrossRef]
- Bezak, N.; Grigillo, D.; Urbančič, T.; Mikoš, M.; Petrovič, D.; Rusjan, S. Geomorphic response detection and quantification in a steep forested torrent. Geomorphology 2017, 291, 33–44. [Google Scholar] [CrossRef]
- SAGA GIS. Available online: http://www.saga-gis.org/en/index.html (accessed on 10 February 2017).









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Kuzlovec | Gornja Radgona |
|---|---|---|
| Basin area (km2) | 0.71 | 10,197 |
| Basin elevation (minimum; maximum; mean) (m a.s.l.) | 394; 847; 631 | 203; 3075; ~1015 |
| Mean basin slope (%) | 52 | ~25 |
| Mean channel slope (%) | 22 | ~0.7 |
| Main channel length (km) | 1.3 | ~300 |
| Mean annual precipitation (mm) | 1600–1800 | 950 |
| Statistic/Variable | P (mm) | Q (L/s) | SSL (kg) |
|---|---|---|---|
| Min | 1.6 | 6.7 | 0.4 |
| 1st quartile | 16.8 | 9.9 | 3.9 |
| Median | 23.0 | 15.6 | 17.2 |
| Mean | 27.2 | 31.1 | 94.3 |
| 3rd quartile | 37.8 | 45.8 | 167.9 |
| Max | 63.0 | 125.9 | 470.3 |
| Statistic/Model | Copula | MLR | EXP |
|---|---|---|---|
| MAE (kg) | 40.3 | 34.76 | 42.5 |
| RMSE (kg) | 68.3 | 59.42 | 61.7 |
| NSE | 0.74 | 0.80 | 0.79 |
| R2 | 0.77 | 0.80 | 0.79 |
| Min SSL (kg) | 1 | −16.1 | 14.7 |
| Median SSL (kg) | 13.3 | 36.47 | 40.6 |
| Max SSL (kg) | 451 | 476.5 | 494.0 |
| Season | Mean P (mm) | Max Q (L/s) | SSL (kg) | SSL0.25 (kg) | SSL0.75 (kg) |
|---|---|---|---|---|---|
| Summer 2013 | 11.4 | 36.0 | 99 | 58 | 172 |
| Autumn 2013 | 17.8 | 125.9 | 1429 | 805 | 2787 |
| Winter 2013–2014 | 26.8 | 138.6 | 1724 | 989 | 3293 |
| Spring 2014 | 12.1 | 43.5 | 360 | 217 | 645 |
| Statistic/Variable | P (mm) | Q (m3/s) | SSL (t) |
|---|---|---|---|
| Min | 30.1 | 62.7 | 357.7 |
| 1st quartile | 37.7 | 169 | 3453 |
| Median | 49.3 | 244.3 | 9317 |
| Mean | 58.3 | 295.1 | 26,410 |
| 3rd quartile | 68.4 | 374 | 26,500 |
| Max | 186.9 | 1237 | 303,000 |
| Statistic/Model | Copula | MLR | EXP |
|---|---|---|---|
| MAE (t) | 12,403 | 15,500 | 13,637 |
| RMSE (t) | 26,261 | 26,230 | 25,400 |
| NSE | 0.65 | 0.65 | 0.67 |
| R2 | 0.66 | 0.65 | 0.67 |
| Min SSL (t) | 900 | −20,020 | 1410 |
| Median SSL (t) | 8768 | 16,280 | 16,210 |
| Max SSL (t) | 283,500 | 214,500 | 297,900 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bezak, N.; Rusjan, S.; Kramar Fijavž, M.; Mikoš, M.; Šraj, M. Estimation of Suspended Sediment Loads Using Copula Functions. Water 2017, 9, 628. https://doi.org/10.3390/w9080628
Bezak N, Rusjan S, Kramar Fijavž M, Mikoš M, Šraj M. Estimation of Suspended Sediment Loads Using Copula Functions. Water. 2017; 9(8):628. https://doi.org/10.3390/w9080628
Chicago/Turabian StyleBezak, Nejc, Simon Rusjan, Marjeta Kramar Fijavž, Matjaž Mikoš, and Mojca Šraj. 2017. "Estimation of Suspended Sediment Loads Using Copula Functions" Water 9, no. 8: 628. https://doi.org/10.3390/w9080628
APA StyleBezak, N., Rusjan, S., Kramar Fijavž, M., Mikoš, M., & Šraj, M. (2017). Estimation of Suspended Sediment Loads Using Copula Functions. Water, 9(8), 628. https://doi.org/10.3390/w9080628