
Design and Prototyping Flow of Flexible and Efficient NISC-Based Architectures for MIMO Turbo Equalization and Demapping
†


Abstract
:1. Introduction
- The ability to support various MIMO schemes reaching to a 4 × 4 antenna dimension
- The capability of using efficiently the implemented hardware resources for different time diversity channel types (block fading, quasi-static and fast fading)
- The possibility to execute in both iterative and no-iterative modes
2. Designed NISC-Based Architectures
2.1. Equalizer Architecture
2.1.1. Control Unit
2.1.2. EquaNISC Module
- Storage unit (SU)
- Multiplexing unit (MU)
- Computational unit (CU)
Storage unit (SU):
Multiplexing unit (MU):
Computational unit (CU):
2.2. Demapper Architecture
2.2.1. Control Unit
2.2.2. DemaNisc Module
- Euclidean distance unit (EDU)
- A priori LLR summation unit (ASU)
- Inter-subtraction unit (ISU)
- Minimum finders unit (MFU)
- Output unit (OU)
Euclidean distance unit (EDU):
A priori LLRs summation unit (ASU):
Inter-subtraction unit (ISU):
Minimum finders unit (MFU):
Output unit (OU):
3. Typical NISC Design Methodology
4. Adopted Design Flow
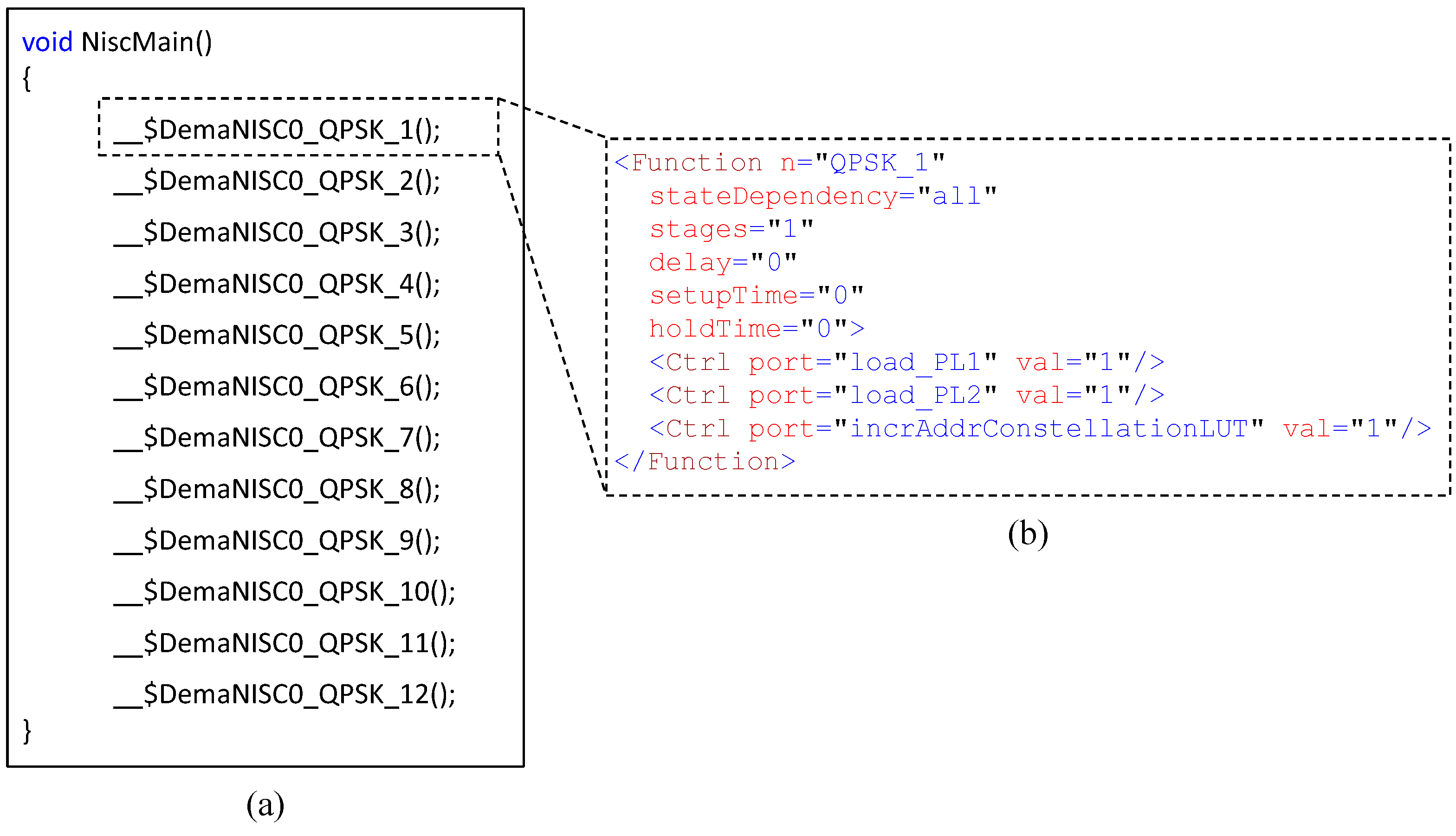
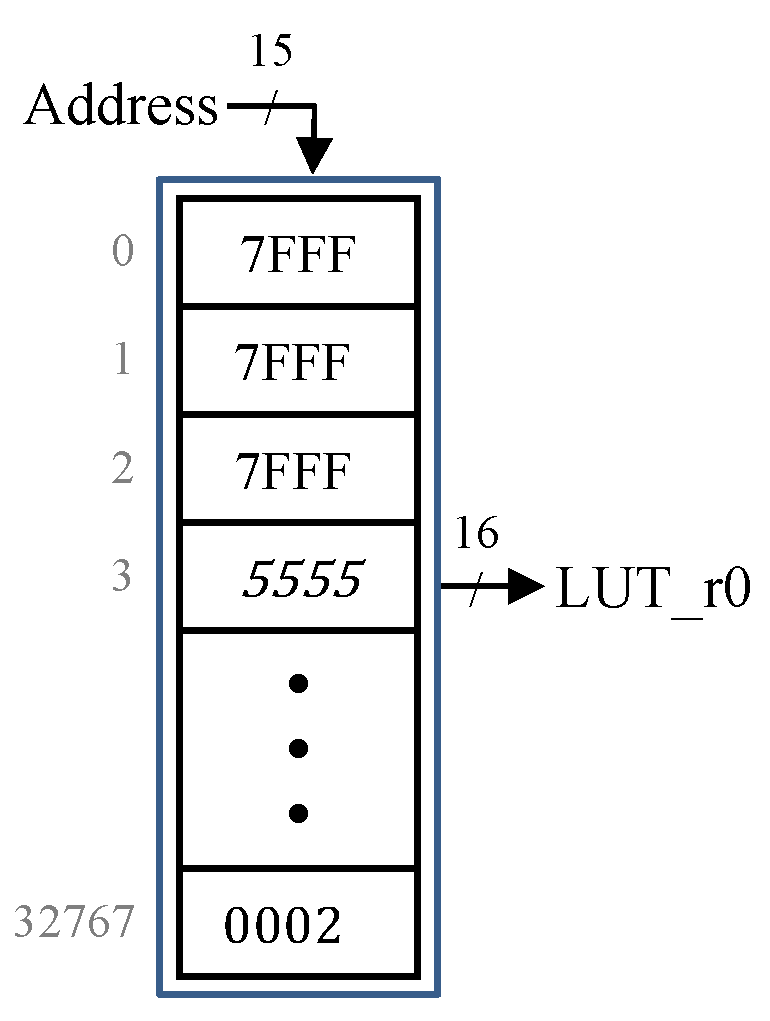
4.1. NISC Abstraction Level
4.2. FPGA Implementation Level
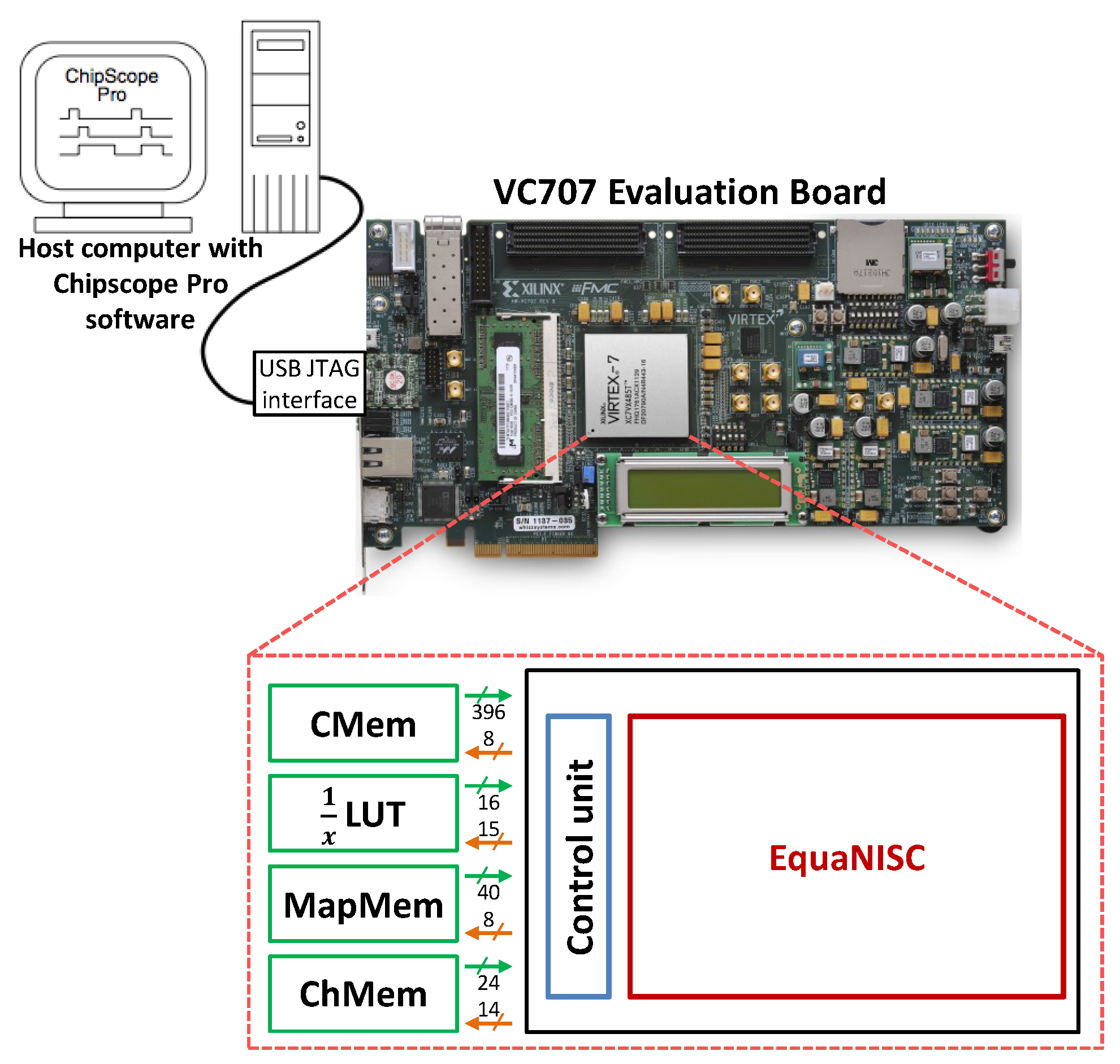
5. FPGA Prototyping
5.1. System Description
5.2. On-Chip Validation
5.3. Equalizer FPGA Prototype and Validation
5.4. Demapper FPGA Prototype and Validation
6. Results and Comparison
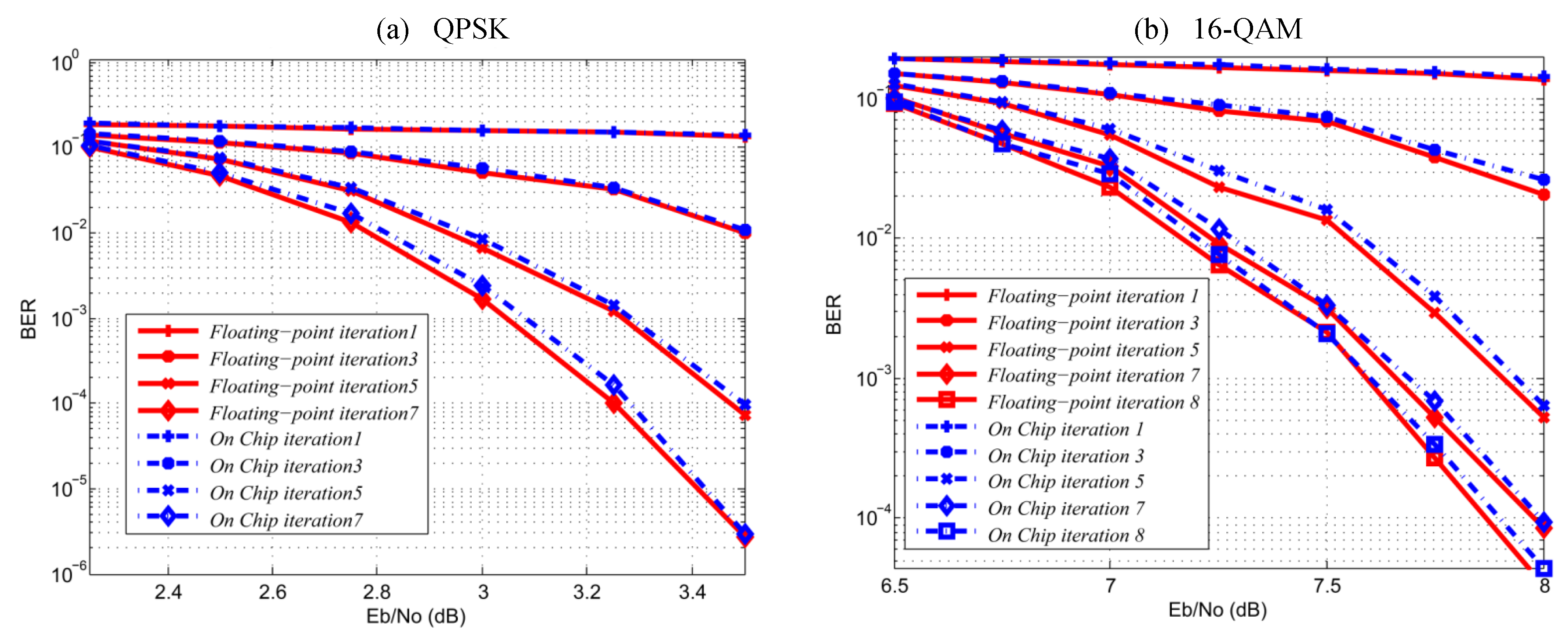
6.1. Performance Results
6.2. Synthesis Results
6.3. Throughput Results
6.4. Results Comparison
6.4.1. Equalizer Module
6.4.2. Demapper Module
7. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Digital Video Broadcasting (DVB); Interaction Channel for Satellite Distribution Systems. ETSI EN 301 790 V1.5.1. 2009. Available online: http://www.etsi.org/deliver/etsi_en/301700_301799/301790/01.05.01_60/en_301790v010501p.pdf (accessed on 23 August 2016).
- IEEE Draft Standard; Part 11: Wireless LAN Medium Access Control (MAC) and Physical Layer (PHY) Specifications; Amendment 4: Enhancements for Higher Throughput; IEEE Std 802.11; March 2012; Available online: http://standards.ieee.org/getieee802/download/802.11-2012.pdf (accessed on 23 August 2016).
- 802.16 IEEE Standard for Local and Metropolitan Area Networks, Part 16: Air Interface for Fixed Broadband Wireless Access Systems. 802.16-2004. 2004. Available online: http://ieeexplore.ieee.org/document/1350465 (accessed on 23 August 2016).
- 3GPP Technical Specifications 36.212, Multiplexing and Channel Coding (Release 11). ETSI TS 136 212 V12.2.0. 2014. Available online: http://www.etsi.org/deliver/etsi_ts/136200_136299/136212/12.02.00_60/ts_136212v120200p.pdf (accessed on 23 August 2016).
- Douillard, C.; Jézéquel, M.; Berrou, C.; Picart, A.; Didier, P.; Glavieux, A. Iterative correction of inter symbol interference: Turbo equalization. Eur. Trans. Telecommun. ETT 1995, 6, 507–511. [Google Scholar] [CrossRef]
- Laot, C.; Le Bidan, R.; Leroux, D. Low-complexity MMSE turbo equalization: A possible solution for EDGE. IEEE Trans. Wirel. Commun. 2005, 4, 965–974. [Google Scholar] [CrossRef]
- Berrou, C. Codes and Turbo Codes; Springer: Paris, France, 2010. [Google Scholar]
- Gamba, M.T.; Masera, G.; Baghdadi, A. Iterative MIMO detection: Flexibility and convergence analysis of SISO list sphere decoding and linear MMSE detection. In Proceedings of the International Conference on Software, Telecommunications and Computer Networks (SoftCOM), Dalmatia, Croatia, 23–25 September 2010; pp. 175–179.
- Reynolds, D.; Wang, X. Low-complexity turbo-equalization for diversity channels. Signal Process. 2001, 81, 989–995. [Google Scholar] [CrossRef]
- Li, X.; Ritcey, J. Bit-interleaved coded modulation with iterative decoding. IEEE Commun. Lett. 1997, 1, 169–171. [Google Scholar]
- Abdel Nour, C.; Douillard, C. Improving BICM performance of QAM constellations for broadcasting applications. In Proceedings of the International Symposium on Turbo Codes and Related Topics (ISTC), Lausanne, Switzerland, 1–5 September 2008; pp. 55–60.
- Robertson, P.; Hoeher, P.; Villebrun, E. Optimal and sub-optimal Maximum A Posteriori algorithms suitable for turbo decoding. Eur. Trans. Telecommun. ETT 1997, 8, 119–125. [Google Scholar] [CrossRef]
- Rizk, M.; Baghdadi, A.; Jezequel, M.; Mohanna, Y.; Atat, Y. Flexible and efficient architecture design for MIMO MMSE-IC linear turbo-equalization. In Proceedings of the IEEE International Conference on Communications and Information Technology (ICCIT), Porto, Portugal, 19–21 June 2013; pp. 340–344.
- Rizk, M.; Baghdadi, A.; Jezequel, M.; Mohanna, Y.; Atat, Y. Nisc-based soft-input soft-output demapper. IEEE Trans. Circuits Syst. II 2015, 62, 1098–1102. [Google Scholar] [CrossRef]
- Osseiran, A.; Boccardi, F.; Braun, V.; Kusume, K.; Marsch, P.; Maternia, M.; Queseth, O.; Schellmann, M.; Schotten, H.; Taoka, H.; et al. Scenarios for 5G mobile and wireless communications: The vision of the METIS project. IEEE Commun. Mag. 2014, 52, 26–35. [Google Scholar] [CrossRef]
- Menard, D.; Serizel, R.; Rocher, R.; Sentieys, O. Accuracy Constraint Determination in Fixed-Point System Design. EURASIP J. Embed. Syst. 2008. [Google Scholar] [CrossRef]
- Rizk, M.; Baghdadi, A.; Jézéquel, M.; Mohanna, Y.; Atat, Y. Quantization and fixed-point arithmetic for MIMO MMSE-IC linear turbo-equalization. In Proceedings of the IEEE International Conference on Microelectronics, (ICM), Beirut, Lebanon, 15–18 December 2013; pp. 1–4.
- Bigdeli, A.; Biglari-Abhari, M.; Salcic, Z.; Tin Lai, Y. A new pipelined systolic array-based architecture for matrix inversion in FPGAs with Kalman filter case study. EURASIP J. Appl. Signal Process. 2006. [Google Scholar] [CrossRef] [PubMed]
- NISC Toolset Website. Available online: http://www.ics.uci.edu/nisc/ (accessed on 15 November 2014).
- Gorjiara, B.; Gajski, D.; Reshadi, M. Gnr: A formal language for specification, compilation, and synthesis of custom embedded processors. In Processor Description Languages: Applications and Methodologies; Mishra, P., Dutt, N., Eds.; Morgan Kaufmann Publishers: Boston, MA, USA, 2008; Charpter 13. [Google Scholar]
- Gorjiara, B.; Reshadi, M.; Gajski, D. Generic architecture description for retargetable compilation and synthesis of application-specific pipelined IPs. In Proceedings of the IEEE International Conference on Computer Design (ICCD), San Jose, CA, USA, 1–4 October 2006; pp. 356–361.
- Reshadi, M.; Gajski, D. Interrupt and low-level programming support for expanding the application domain of statically-scheduled horizontal-microcoded architectures in embedded systems. In Proceedings of the IEEE Design, Automation and Test in Europe Conference and Exhibition (DATE), Nice, France, 16–20 April 2007; pp. 1–6.
- Xilinx. ChipScope Pro 10.1 Software and Cores User Guide. Available online: http://www.xilinx.com/ise/verification/chipscope_pro_sw_cores_10_1_ug029.pdf (accessed on 23 August 2016).
- Karakolah, D. Conception et Prototypage d’un Récepteur Itératif Pour des Systèmes de Transmision MIMO Avec Précodage Linéaire. Ph.D. Dissertation, Department of Electronics, Telecom Bretagne, Brest, France, 2009. [Google Scholar]
- Kim, H.; Zhu, W.; Bhatia, J.; Mohammad, K.; Shah, A.; Danesrad, B. A Practical Hardware Friendly MMSE Detector for MIMO-ODFM-Based Systems. EURASIP J. Adv. Signal Process. 2008. [Google Scholar] [CrossRef]
- Jafri, A.R. Architectures Multi-ASIP Pour Turbo Récepteur Flexible. Ph.D. Dissertation, Department of Electronics, Telecom Bretagne, Brest, France, 2011. [Google Scholar]
- Li, M. Design, Imlementation, and Prototyping of an Iterative Receiver for Bit-Interleaved Coded Modulation System Dedicated to DVB-T2. Ph.D. Dissertation, Department of Electronics, Telecom Bretagne, Brest, France, 2012. [Google Scholar]
- Park, J.W.; Sunwoo, M.H.; Kim, P.S.; Chang, D.-I. Low complexity soft-decision demapper for high order modulation of DVB-S2 system. In Proceedings of the IEEE International SoC Design Conference (ISOCC), Busan, Korea, 24–25 November 2008; Volume 02, pp. II-37–II-40.
- Digital Video Broadcasting (DVB); User Guidelines for the Second Generation System for Broadcasting, Interactive Services, News Gathering and Other Broad-Band Satellite Applications (DVB-S2). ETSI TR 102 376 V1.1.1. 2005. Available online: http://www.etsi.org/deliver/etsi_tr/102300_102399/102376/01.01.01_60/tr_102376v010101p.pdf (accessed on 23 August 2016).


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Logic Utilization and Timing | Equalizer | Demapper |
|---|---|---|
| Slice Registers | 2029 out of 607,200 | 1290 out of 607,200 |
| Slice LUTs | 5942 out of 303,600 | 1517 out of 303,600 |
| DSP48Es | 12 out of 2800 | 6 out of 2800 |
| Max Clock Frequency | 202.67 MHz | 293 MHz |
| Logic Utilization and Timing | Equalizer | Demapper |
|---|---|---|
| Operating conditions | nominal case (1 V; 25 °C) | |
| Area | 0.126 mm2 | 0.048 mm2 |
| Maximum operating frequency | 529 MHz | 520 MHz |
| Implementation | Fading Type | Throughput (Mega Symbols per Second) | |
|---|---|---|---|
| 2 × 2 MIMO SM | 4 × 4 MIMO SM | ||
| FPGA @202.67 MHz | Block fading | 115.8 | 62.4 |
| Fast fading | 6.4 | 4.7 | |
| ASIC @ 529 MHz | Block fading | 302.3 | 162.8 |
| Fast fading | 16.8 | 12.2 | |
| Modulation Type | Throughput (Mega LLRsper Second) | |
|---|---|---|
| FPGA @ 293 MHz | ASIC @ 520 MHz | |
| QPSK | 195.5 | 347 |
| 16-QAM | 234.6 | 416 |
| 64-QAM | 195.5 | 347 |
| 256-QAM | 138 | 244.7 |
| System Configuration | Reference | Target Device | Operating Frequency (MHz) | FPGA Resources | Clock Cycles | Throughput (mega Operations per Second) | ||
|---|---|---|---|---|---|---|---|---|
| Registers | LUT | Dedicated Multipliers | ||||||
| 2 × 2 SM | [25] | Virtex-II | 140 | 14166 | 103 | 388 | 17.31 | |
| Block Fading | This work | 91 | 4604 | 12 | 784 | 5.57 | ||
| 4 × 4 SM | [26] | Virtex-V | 130 | 3174 | 11299 | 14 | 13 | 10 |
| Block Fading | This work | 146 | 2029 | 6536 | 12 | 13 | 11.23 | |
| 4 × 4 SM | [26] | Virtex-V | 130 | 3174 | 11299 | 14 | 234 | 0.56 |
| Fast Fading | This work | 146 | 2029 | 6536 | 12 | 173 | 0.84 | |
| 2 × 2 | [24] | Virtex-V | 60 | 817 | 2715 | 60 | 1 | 120 |
| Precodin Quasi-Staticg | This work | 146 | 2029 | 6536 | 12 | 3.25 | 45 | |
| 2 × 2 SM | [26] | Virtex-V | 130 | 3174 | 11299 | 14 | 89 | 1.46 |
| Fast Fading | This work | 146 | 2029 | 6536 | 12 | 63 | 2.32 | |
| 2 × 2 SM | [26] | Virtex-V | 130 | 3174 | 11299 | 14 | 8 | 16.25 |
| Block Fading | This work | 146 | 2029 | 6536 | 12 | 7 | 20.86 | |
| Mapping Style and SSD | Reference | Iterative/Non-Iterative Demapping | Target Device | Operating Frequency (MHz) | FPGA Resources | Modulation Type | Clock Cycles | Throughput (mega LLR per Second) | ||
|---|---|---|---|---|---|---|---|---|---|---|
| Registers | LUT | Dedicated Multipliers | ||||||||
| non-Gray with SSD | [27] | non-iterative | Virtex II Pro XC2VP3 | 62 | 791 | 4667 | 20 | QPSK | 10 | 12.4 |
| 16-QAM | 24.8 | |||||||||
| 64-QAM | 37.2 | |||||||||
| 256-QAM | 49.6 | |||||||||
| This work | iterative and non-iterative | 194 | 1740 | 1523 | 6 | QPSK | 5 | 77.45 | ||
| 16-QAM | 10 | 77.45 | ||||||||
| 64-QAM | 26 | 44.68 | ||||||||
| 256-QAM | 82 | 18.89 | ||||||||
| [26] | iterative and non-iterative | Virtex5 XC5VLX330 | 186 | 1918 | 3201 | 6 | 64-QAM | 27 | 41.33 | |
| 256-QAM | 83 | 17.93 | ||||||||
| This work | 240 | 1328 | 1524 | 6 | 64-QAM | 26 | 55.27 | |||
| 256-QAM | 82 | 23.37 | ||||||||
| Gray without SSD | [28] | non-iterative | Virtex II XC2-V6000 | - | 1826 | 16 | QPSK, 8-PSK | - | - | |
| 16-APSK, 32-APSK | - | - | ||||||||
| This work | iterative and non-iterative | 160 | 1005 | 6 | QPSK | 4 | 80.13 | |||
| 8-PSK | 9 | 53.42 | ||||||||
| 16-APSK | 17 | 37.71 | ||||||||
| 32-APSK | 33 | 24.28 | ||||||||
| [26] | iterative and non-iterative | Virtex-V XC5VLX330 | 186 | 1918 | 3201 | 6 | QPSK | 4 | 93 | |
| 16-QAM | 6 | 124 | ||||||||
| 64-QAM | 10 | 111.6 | ||||||||
| 256-QAM | 18 | 82.67 | ||||||||
| This work | 240 | 1328 | 1524 | 6 | QPSK | 3 | 159.67 | |||
| 16-QAM | 5 | 191.6 | ||||||||
| 64-QAM | 9 | 159.67 | ||||||||
| 256-QAM | 17 | 112.71 | ||||||||
| non-Gray without SSD | [26] | non-iterative | Virtex-V XC5VLX330 | 186 | 1918 | 3201 | 6 | QPSK | 6 | 62 |
| 8-PSK | 10 | 55.8 | ||||||||
| 16-QAM,16-APSK | 18 | 41.33 | ||||||||
| 32-APSK | 34 | 27.35 | ||||||||
| 64-QAM | 66 | 16.91 | ||||||||
| 256-QAM | 258 | 5.77 | ||||||||
| This work | 240 | 1328 | 1524 | 6 | QPSK | 5 | 95.8 | |||
| 8-PSK | 9 | 79.83 | ||||||||
| 16-QAM,16-APSK | 17 | 56.35 | ||||||||
| 32-APSK | 33 | 36.29 | ||||||||
| 64-QAM | 65 | 22.1 | ||||||||
| 256-QAM | 257 | 7.46 | ||||||||
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rizk, M.; Baghdadi, A.; Jézéquel, M.; Mohanna, Y.; Atat, Y.
Design and Prototyping Flow of Flexible and Efficient NISC-Based Architectures for MIMO Turbo Equalization and Demapping
. Electronics 2016, 5, 50.
https://doi.org/10.3390/electronics5030050
Rizk M, Baghdadi A, Jézéquel M, Mohanna Y, Atat Y.
Design and Prototyping Flow of Flexible and Efficient NISC-Based Architectures for MIMO Turbo Equalization and Demapping
. Electronics. 2016; 5(3):50.
https://doi.org/10.3390/electronics5030050
Rizk, Mostafa, Amer Baghdadi, Michel Jézéquel, Yasser Mohanna, and Youssef Atat.
2016. "Design and Prototyping Flow of Flexible and Efficient NISC-Based Architectures for MIMO Turbo Equalization and Demapping
" Electronics 5, no. 3: 50.
https://doi.org/10.3390/electronics5030050