Deep Assessment Methodology Using Fractional Calculus on Mathematical Modeling and Prediction of Gross Domestic Product per Capita of Countries


Abstract
1. Introduction
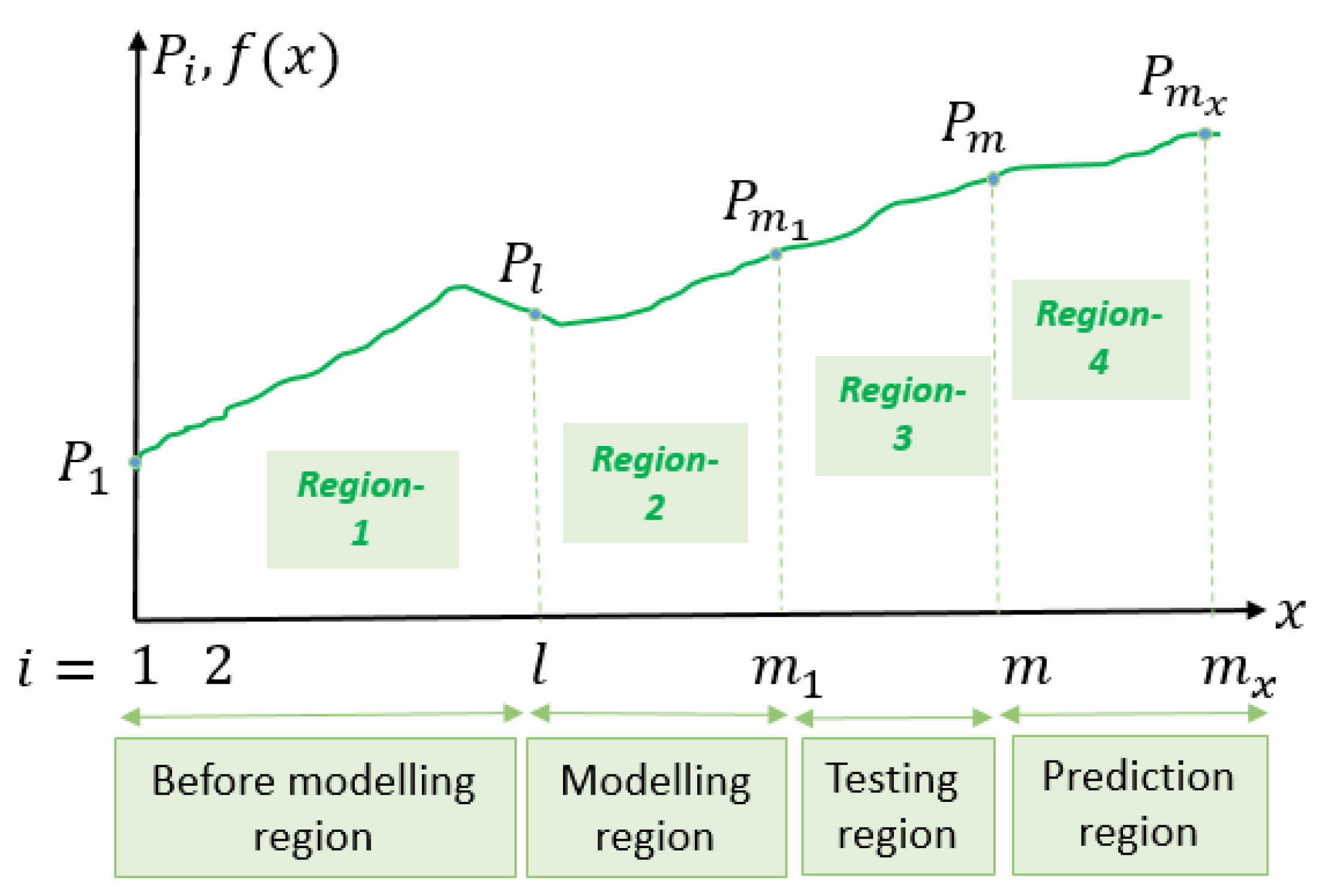
2. Formulation of the Problem
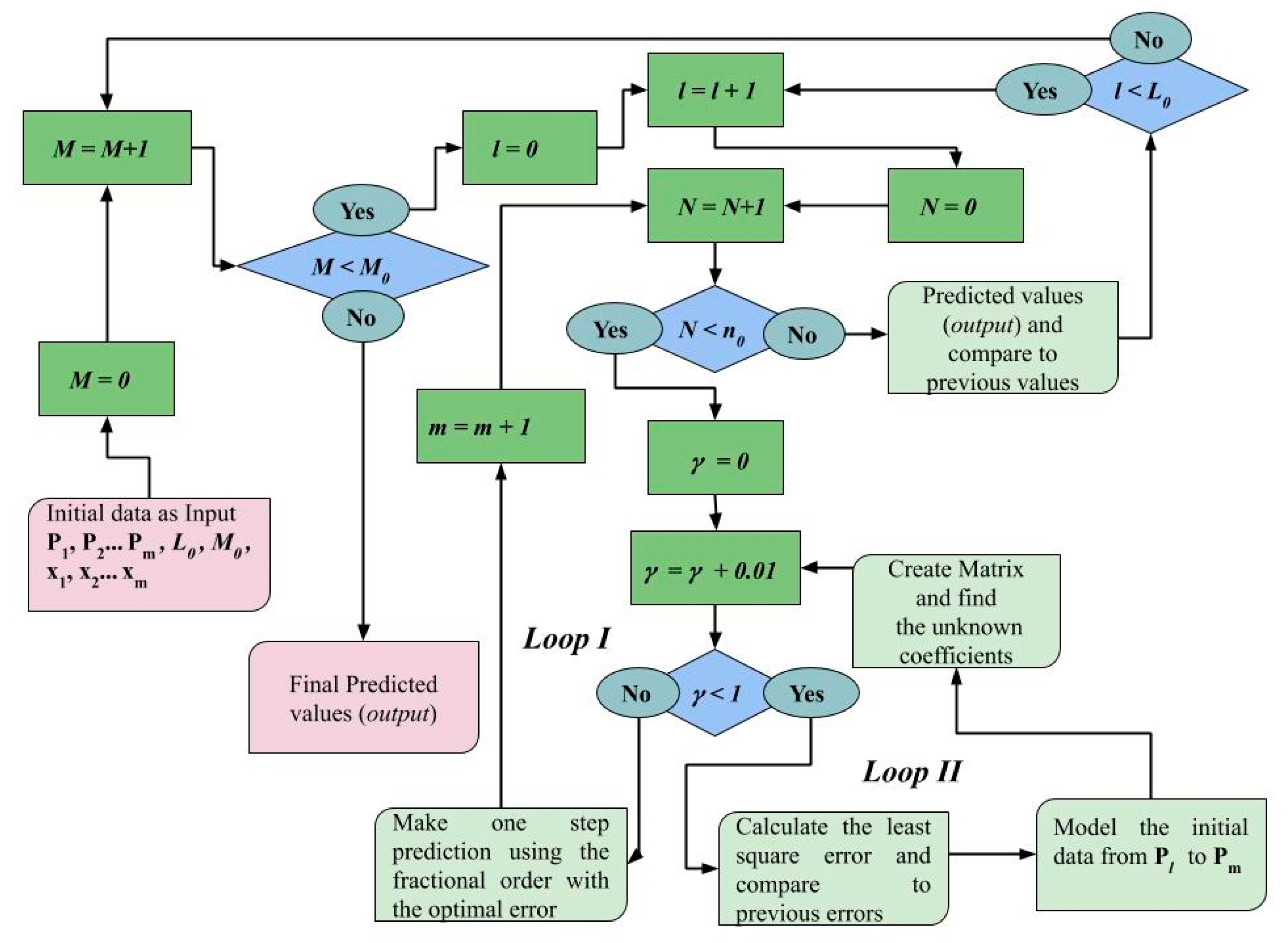
3. Our Approach
3.1. Modeling with Deep Assessment
3.2. Prediction with Deep Assessment
3.3. Long Short-Term Memory
4. Numerical Results
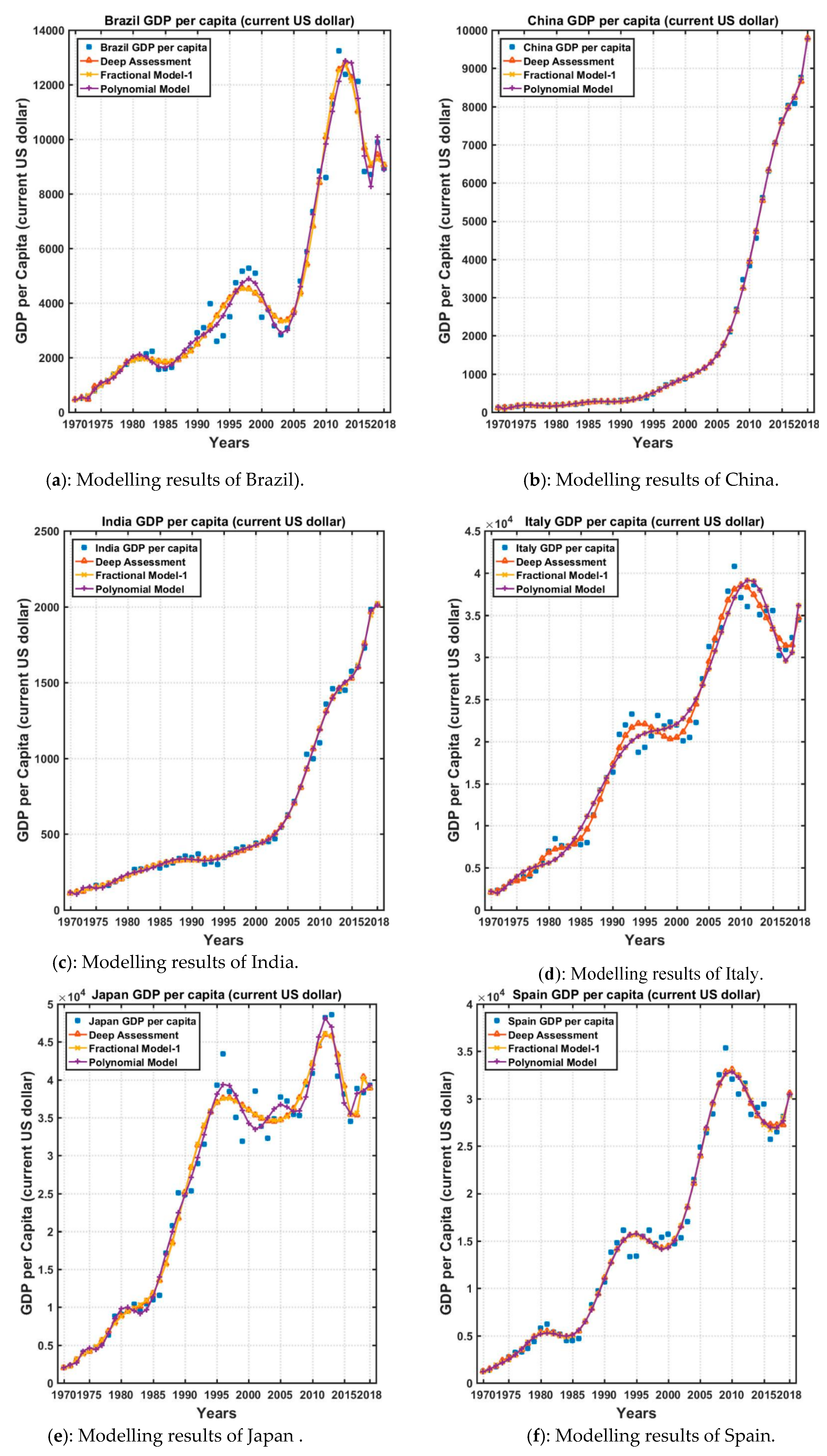
4.1. Modeling Results
4.2. Prediction Results
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Years | Brazil | China | EU | India | Italy | |
|---|---|---|---|---|---|---|
| 1 | 1960 | 210.1099 | 89.52054 | 890.4056 | 82.1886 | 804.4926 |
| 2 | 1961 | 205.0408 | 75.80584 | 959.71 | 85.3543 | 887.3367 |
| 3 | 1962 | 260.4257 | 70.90941 | 1037.326 | 89.88176 | 990.2602 |
| 4 | 1963 | 292.2521 | 74.31364 | 1135.194 | 101.1264 | 1126.019 |
| 5 | 1964 | 261.6666 | 85.49856 | 1245.499 | 115.5375 | 1222.545 |
| 6 | 1965 | 261.3544 | 98.48678 | 1346.058 | 119.3189 | 1304.454 |
| 7 | 1966 | 315.7972 | 104.3246 | 1448.551 | 89.99731 | 1402.442 |
| 8 | 1967 | 347.4931 | 96.58953 | 1546.804 | 96.33914 | 1533.693 |
| 9 | 1968 | 374.7868 | 91.47272 | 1602.06 | 99.87596 | 1651.939 |
| 10 | 1969 | 403.8843 | 100.1299 | 1762.472 | 107.6223 | 1813.388 |
| 11 | 1970 | 445.0231 | 113.163 | 1950.732 | 112.4345 | 2106.864 |
| 12 | 1971 | 504.7495 | 118.6546 | 2195.145 | 118.6032 | 2305.61 |
| 13 | 1972 | 586.2144 | 131.8836 | 2611.729 | 122.9819 | 2671.137 |
| 14 | 1973 | 775.2733 | 157.0904 | 3296.935 | 143.7787 | 3205.252 |
| 15 | 1974 | 1004.105 | 160.1401 | 3685.596 | 163.4781 | 3621.146 |
| 16 | 1975 | 1153.831 | 178.3418 | 4274.046 | 158.0362 | 4106.994 |
| 17 | 1976 | 1390.625 | 165.4055 | 4406.238 | 161.0921 | 4033.099 |
| 18 | 1977 | 1567.006 | 185.4228 | 4968.988 | 186.2135 | 4603.6 |
| 19 | 1978 | 1744.257 | 156.3964 | 6064.883 | 205.6934 | 5610.498 |
| 20 | 1979 | 1908.488 | 183.9832 | 7377.165 | 224.001 | 6990.286 |
| 21 | 1980 | 1947.276 | 194.8047 | 8384.718 | 266.5778 | 8456.919 |
| 22 | 1981 | 2132.883 | 197.0715 | 7391.077 | 270.4706 | 7622.833 |
| 23 | 1982 | 2226.767 | 203.3349 | 7093.702 | 274.1113 | 7556.523 |
| 24 | 1983 | 1570.54 | 225.4319 | 6859.966 | 291.2381 | 7832.575 |
| 25 | 1984 | 1578.926 | 250.714 | 6572.019 | 276.668 | 7739.715 |
| 26 | 1985 | 1648.082 | 294.4588 | 6775.647 | 296.4352 | 7990.687 |
| 27 | 1986 | 1941.491 | 281.9281 | 9265.924 | 310.4659 | 11,315.02 |
| 28 | 1987 | 2087.308 | 251.812 | 11,432.23 | 340.4168 | 14,234.73 |
| 29 | 1988 | 2300.377 | 283.5377 | 12,711.96 | 354.1493 | 15,744.66 |
| 30 | 1989 | 2908.496 | 310.8819 | 12,936.46 | 346.1129 | 16,386.66 |
| 31 | 1990 | 3100.28 | 317.8847 | 15,989.22 | 367.5566 | 20,825.78 |
| 32 | 1991 | 3975.39 | 333.1421 | 16,496.51 | 303.0556 | 21,956.53 |
| 33 | 1992 | 2596.92 | 366.4607 | 17,919.02 | 316.9539 | 23,243.47 |
| 34 | 1993 | 2791.209 | 377.3898 | 16,256.42 | 301.159 | 18,738.76 |
| 35 | 1994 | 3500.611 | 473.4923 | 17,194.12 | 346.103 | 19,337.63 |
| 36 | 1995 | 4748.216 | 609.6567 | 19,898.44 | 373.7665 | 20,664.55 |
| 37 | 1996 | 5166.164 | 709.4138 | 20,295.17 | 399.9501 | 23,081.6 |
| 38 | 1997 | 5282.009 | 781.7442 | 19,121.21 | 415.4938 | 21,829.35 |
| 39 | 1998 | 5087.152 | 828.5805 | 19,763.51 | 413.2989 | 22,318.14 |
| 40 | 1999 | 3478.373 | 873.2871 | 19,698.89 | 441.9988 | 21,997.62 |
| 41 | 2000 | 3749.753 | 959.3725 | 18,261.97 | 443.3142 | 20,087.59 |
| 42 | 2001 | 3156.799 | 1053.108 | 18,457.89 | 451.573 | 20,483.22 |
| 43 | 2002 | 2829.283 | 1148.508 | 20,055.33 | 470.9868 | 22,270.14 |
| 44 | 2003 | 3070.91 | 1288.643 | 24,310.25 | 546.7266 | 27,465.68 |
| 45 | 2004 | 3637.462 | 1508.668 | 27,960.05 | 627.7742 | 31,259.72 |
| 46 | 2005 | 4790.437 | 1753.418 | 29,115.63 | 714.861 | 32,043.14 |
| 47 | 2006 | 5886.464 | 2099.229 | 30,960.56 | 806.7533 | 33,501.66 |
| 48 | 2007 | 7348.031 | 2693.97 | 35,630.94 | 1028.335 | 37,822.67 |
| 49 | 2008 | 8831.023 | 3468.304 | 38,185.62 | 998.5223 | 40,778.34 |
| 50 | 2009 | 8597.915 | 3832.236 | 34,019.28 | 1101.961 | 37,079.76 |
| 51 | 2010 | 11,286.24 | 4550.454 | 33,740.65 | 1357.564 | 36,000.52 |
| 52 | 2011 | 13,245.61 | 5618.132 | 36,506.64 | 1458.104 | 38,599.06 |
| 53 | 2012 | 12,370.02 | 6316.919 | 34,328.82 | 1443.88 | 35,053.53 |
| 54 | 2013 | 12,300.32 | 7050.646 | 35,683.86 | 1449.606 | 35,549.97 |
| 55 | 2014 | 12,112.59 | 7651.366 | 36,787.23 | 1573.881 | 35,518.42 |
| 56 | 2015 | 8814.001 | 8033.388 | 32,319.45 | 1605.605 | 30,230.23 |
| 57 | 2016 | 8712.887 | 8078.79 | 32,425.13 | 1729.268 | 30,936.13 |
| 58 | 2017 | 9880.947 | 8759.042 | 33,908 | 1981.269 | 32,326.84 |
| 59 | 2018 | 8920.762 | 9770.847 | 36,569.73 | 2009.979 | 34,483.2 |
| Years | Japan | Spain | UK | US | Turkey | |
|---|---|---|---|---|---|---|
| 1 | 1960 | 478.9953 | 396.3923 | 1397.595 | 3007.123 | 509.4239 |
| 2 | 1961 | 563.5868 | 450.0533 | 1472.386 | 3066.563 | 283.8283 |
| 3 | 1962 | 633.6403 | 520.2061 | 1525.776 | 3243.843 | 309.4467 |
| 4 | 1963 | 717.8669 | 609.4874 | 1613.457 | 3374.515 | 350.6629 |
| 5 | 1964 | 835.6573 | 675.2416 | 1748.288 | 3573.941 | 369.5834 |
| 6 | 1965 | 919.7767 | 774.7616 | 1873.568 | 3827.527 | 386.3581 |
| 7 | 1966 | 1058.504 | 889.6599 | 1986.747 | 4146.317 | 444.5494 |
| 8 | 1967 | 1228.909 | 968.3068 | 2058.782 | 4336.427 | 481.6937 |
| 9 | 1968 | 1450.62 | 950.5457 | 1951.759 | 4695.923 | 526.2135 |
| 10 | 1969 | 1669.098 | 1077.679 | 2100.668 | 5032.145 | 571.6178 |
| 11 | 1970 | 2037.56 | 1212.289 | 2347.544 | 5234.297 | 489.9303 |
| 12 | 1971 | 2272.078 | 1362.166 | 2649.802 | 5609.383 | 455.1049 |
| 13 | 1972 | 2967.042 | 1708.809 | 3030.433 | 6094.018 | 558.421 |
| 14 | 1973 | 3997.841 | 2247.553 | 3426.276 | 6726.359 | 686.4899 |
| 15 | 1974 | 4353.824 | 2749.925 | 3665.863 | 7225.691 | 927.7991 |
| 16 | 1975 | 4659.12 | 3209.837 | 4299.746 | 7801.457 | 1136.375 |
| 17 | 1976 | 5197.807 | 3279.313 | 4138.168 | 8592.254 | 1275.956 |
| 18 | 1977 | 6335.788 | 3627.591 | 4681.44 | 9452.577 | 1427.372 |
| 19 | 1978 | 8821.843 | 4356.439 | 5976.938 | 10,564.95 | 1549.644 |
| 20 | 1979 | 9105.136 | 5770.215 | 7804.762 | 11,674.19 | 2079.22 |
| 21 | 1980 | 9465.38 | 6208.578 | 10,032.06 | 12,574.79 | 1564.247 |
| 22 | 1981 | 10,361.32 | 5371.166 | 9599.306 | 13,976.11 | 1579.074 |
| 23 | 1982 | 9578.114 | 5159.709 | 9146.077 | 14,433.79 | 1402.406 |
| 24 | 1983 | 10,425.41 | 4478.5 | 8691.519 | 15,543.89 | 1310.256 |
| 25 | 1984 | 10,984.87 | 4489.989 | 8179.194 | 17,121.23 | 1246.825 |
| 26 | 1985 | 11,584.65 | 4699.656 | 8652.217 | 18,236.83 | 1368.401 |
| 27 | 1986 | 17,111.85 | 6513.503 | 10,611.11 | 19,071.23 | 1510.677 |
| 28 | 1987 | 20,745.25 | 8239.614 | 13,118.59 | 20,038.94 | 1705.895 |
| 29 | 1988 | 25,051.85 | 9703.124 | 15,987.17 | 21,417.01 | 1745.365 |
| 30 | 1989 | 24,813.3 | 10,681.97 | 16,239.28 | 22,857.15 | 2021.859 |
| 31 | 1990 | 25,359.35 | 13,804.88 | 19,095.47 | 23,888.6 | 2794.35 |
| 32 | 1991 | 28,925.04 | 14,811.9 | 19,900.73 | 24,342.26 | 2735.708 |
| 33 | 1992 | 31,464.55 | 16,112.19 | 20,487.17 | 25,418.99 | 2842.37 |
| 34 | 1993 | 35,765.91 | 13,339.91 | 18,389.02 | 26,387.29 | 3180.188 |
| 35 | 1994 | 39,268.57 | 13,415.29 | 19,709.24 | 27,694.85 | 2270.338 |
| 36 | 1995 | 43,440.37 | 15,471.96 | 23,123.18 | 28,690.88 | 2897.866 |
| 37 | 1996 | 38,436.93 | 16,109.08 | 24,332.7 | 29,967.71 | 3053.947 |
| 38 | 1997 | 35,021.72 | 14,730.8 | 26,734.56 | 31,459.14 | 3144.386 |
| 39 | 1998 | 31,902.77 | 15,394.35 | 28,214.27 | 32,853.68 | 4496.497 |
| 40 | 1999 | 36,026.56 | 15,715.33 | 28,669.54 | 34,513.56 | 4108.123 |
| 41 | 2000 | 38,532.04 | 14,713.07 | 28,149.87 | 36,334.91 | 4316.549 |
| 42 | 2001 | 33,846.47 | 15,355.7 | 27,744.51 | 37,133.24 | 3119.566 |
| 43 | 2002 | 32,289.35 | 17,025.53 | 30,056.59 | 38,023.16 | 3659.94 |
| 44 | 2003 | 34,808.39 | 21,463.44 | 34,419.15 | 39,496.49 | 4718.2 |
| 45 | 2004 | 37,688.72 | 24,861.28 | 40,290.31 | 41,712.8 | 6040.608 |
| 46 | 2005 | 37,217.65 | 26,419.3 | 42,030.29 | 44,114.75 | 7384.252 |
| 47 | 2006 | 35,433.99 | 28,365.31 | 44,599.7 | 46,298.73 | 8035.377 |
| 48 | 2007 | 35,275.23 | 32,549.97 | 50,566.83 | 47,975.97 | 9711.874 |
| 49 | 2008 | 39,339.3 | 35,366.26 | 47,287 | 48,382.56 | 10,854.17 |
| 50 | 2009 | 40,855.18 | 32,042.47 | 38,713.14 | 47,099.98 | 9038.52 |
| 51 | 2010 | 44,507.68 | 30,502.72 | 39,435.84 | 48,466.82 | 10,672.39 |
| 52 | 2011 | 48,168 | 31,636.45 | 42,038.5 | 49,883.11 | 11,335.51 |
| 53 | 2012 | 48,603.48 | 28,324.43 | 42,462.71 | 51,603.5 | 11,707.26 |
| 54 | 2013 | 40,454.45 | 29,059.55 | 43,444.56 | 53,106.91 | 12,519.39 |
| 55 | 2014 | 38,109.41 | 29,461.55 | 47,417.64 | 55,032.96 | 12,095.85 |
| 56 | 2015 | 34,524.47 | 25,732.02 | 44,966.1 | 56,803.47 | 10,948.72 |
| 57 | 2016 | 38,794.33 | 26,505.62 | 41,074.17 | 57,904.2 | 10,820.63 |
| 58 | 2017 | 38,331.98 | 28,100.85 | 40,361.42 | 59,927.93 | 10,513.65 |
| 59 | 2018 | 39,289.96 | 30,370.89 | 42,943.9 | 62,794.59 | 9370.176 |
References
- Beaudry, P.; Portier, F. Stock prices, news, and economic fluctuations. Am. Econ. Rev. 2006, 96, 1293–1307. [Google Scholar] [CrossRef]
- Simpson, D.M.; Rockaway, T.D.; Weigel, T.A.; Coomes, P.A.; Holloman, C.O. Framing a new approach to critical infrastructure modelling and extreme events. Int. J. Crit. Infrastruct. 2005, 1, 125–143. [Google Scholar] [CrossRef]
- Ho, T.Q.; Strong, N.; Walker, M. Modelling analysts’ target price revisions following good and bad news? Account. Bus. Res. 2018, 48, 37–61. [Google Scholar] [CrossRef]
- Karaçuha, E.; Tabatadze, V.; Önal, N.Ö.; Karaçuha, K.; Bodur, D. Deep Assessment Methodology Using Fractional Calculus on Mathematical Modeling and Prediction of Population of Countries. Authorea 2020. [Google Scholar] [CrossRef]
- Forestier, E.; Grace, J.; Kenny, C. Can information and communication technologies be pro-poor? Telecommun. Policy 2002, 26, 623–646. [Google Scholar] [CrossRef]
- Kretschmer, T. Information and Communication Technologies and Productivity Growth: A Survey of the Literature; OECD Digital Economy Papers; OECD Publishing:: Paris, France, 2012; Volume 195. [Google Scholar] [CrossRef]
- Han, E.J.; Sohn, S.Y. Technological convergence in standards for information and communication technologies. Technol. Forecast. Soc. Chang. 2016, 106, 1–10. [Google Scholar] [CrossRef]
- Grover, V.; Purvis, R.L.; Segars, A.H. Exploring ambidextrous innovation tendencies in the adoption of telecommunications technologies. IEEE Trans. Eng. Manag. 2007, 54, 268–285. [Google Scholar] [CrossRef]
- Torero, M.; Von Braun, J. (Eds.) Information and Communication Technologies for Development and Poverty Reduction: The Potential of Telecommunications; International Food Policy Research Institute: Washington, DC, USA, 2006. [Google Scholar]
- Pradhan, R.P.; Arvin, M.B.; Norman, N.R. The dynamics of information and communications technologies infrastructure, economic growth, and financial development: Evidence from Asian countries. Technol. Soc. 2015, 42, 135–149. [Google Scholar] [CrossRef]
- Podlubny, I. Fractional differential equations. Math. Sci. Eng. 1999, 198, 79. [Google Scholar]
- Machado, J.T.; Kiryakova, V.; Mainardi, F. Recent history of fractional calculus. Commun. Nonlinear Sci. Numer. Simul. 2019, 16, 1140–1153. [Google Scholar] [CrossRef]
- Tarasov, V.E. On history of mathematical economics: Application of fractional calculus. Mathematics 2019, 7, 509. [Google Scholar] [CrossRef]
- Baleanu, D.; Güvenç, Z.B.; Machado, J.T. (Eds.) New Trends in Nanotechnology and Fractional Calculus Applications; Springer: New York, NY, USA, 2010. [Google Scholar]
- Gómez, F.; Bernal, J.; Rosales, J.; Cordova, T. Modeling and simulation of equivalent circuits in description of biological systems-a fractional calculus approach. J. Electr. Bioimpedance 2019, 3, 2–11. [Google Scholar] [CrossRef]
- Machado, J.T.; Mata, M.E. Pseudo phase plane and fractional calculus modeling of western global economic downturn. Commun. Nonlinear Sci. Numer. Simul. 2015, 22, 396–406. [Google Scholar] [CrossRef]
- Moreles, M.A.; Lainez, R. Mathematical modelling of fractional order circuit elements and bioimpedance applications. Commun. Nonlinear Sci. Numer. Simul. 2017, 46, 81–88. [Google Scholar] [CrossRef]
- Tabatadze, V.; Karaçuha, K.; Veliev, E.I. The Fractional Derivative Approach for the Diffraction Problems: Plane Wave Diffraction by Two Strips with the Fractional Boundary Conditions. Prog. Electromagn. Res. 2019, 95, 251–264. [Google Scholar] [CrossRef]
- Sierociuk, D.; Dzieliński, A.; Sarwas, G.; Petras, I.; Podlubny, I.; Skovranek, T. Modelling heat transfer in heterogeneous media using fractional calculus. Philosophical Trans. R. Soc. A 2013, 371, 20120146. [Google Scholar] [CrossRef]
- Bogdan, P.; Jain, S.; Goyal, K.; Marculescu, R. Implantable pacemakers control and optimization via fractional calculus approaches: A cyber-physical systems perspective. In Proceedings of the Third International Conference on Cyber-Physical Systems, Beijing, China, 17–19 April 2012. [Google Scholar]
- Magin, R.L. Fractional calculus models of complex dynamics in biological tissues. Comput. Math. Appl. 2010, 59, 1586–1593. [Google Scholar] [CrossRef]
- Chen, Y.; Xue, D.; Dou, H. Fractional calculus and biomimetic control. In Proceedings of the 2004 IEEE International Conference on Robotics and Biomimetics, Shenyang, China, 22–26 August 2004; pp. 901–906. [Google Scholar]
- Dimeas, I.; Petras, I.; Psychalinos, C. New analog implementation technique for fractional-order controller: A DC motor control. Aeu-Int. J. Electron. Commun. 2004, 78, 192–200. [Google Scholar] [CrossRef]
- Sierociuk, D.; Skovranek, T.; Macias, M.; Podlubny, I.; Petras, I.; Dzielinski, A.; Ziubinski, P. Diffusion process modeling by using fractional-order models. Appl. Math. Comput. 2015, 257, 2–11. [Google Scholar] [CrossRef]
- Tarasova, V.; Tarasov, V. Elasticity for economic processes with memory: Fractional differential calculus approach. Fract. Differ. Calc. 2016, 6, 219–232. [Google Scholar] [CrossRef]
- Tarasov, V.; Tarasova, V. Macroeconomic models with long dynamic memory: Fractional calculus approach. Appl. Math. Comput. 2018, 338, 466–486. [Google Scholar] [CrossRef]
- Tejado, I.; Pérez, E.; Valério, D. Fractional calculus in economic growth modelling of the group of seven. Fract. Calc. Appl. Anal. 2019, 22, 139–157. [Google Scholar] [CrossRef]
- Škovránek, T.; Podlubny, I.; Petráš, I. Modeling of the national economies in state-space: A fractional calculus approach. Econ. Model. 2012, 29, 1322–1327. [Google Scholar] [CrossRef]
- Inés, T.; Valério, D.; Pérez, E.; Valério, N. Fractional calculus in economic growth modelling: The Spanish and Portuguese cases. Int. J. Dyn. Control 2017, 5, 208–222. [Google Scholar]
- Ming, H.; Wang, J.; Fečkan, M. The application of fractional calculus in Chinese economic growth models. Mathematics 2019, 7, 665. [Google Scholar] [CrossRef]
- Blackledge, J.; Kearney, D.; Lamphiere, M.; Rani, R.; Walsh, P. Econophysics and Fractional Calculus: Einstein’s Evolution Equation, the Fractal Market Hypothesis, Trend Analysis and Future Price Prediction. Mathematics 2019, 7, 1057. [Google Scholar] [CrossRef]
- Despotovic, V.; Skovranek, T.; Peric, Z. One-parameter fractional linear prediction. Comput. Electr. Eng. 2018, 69, 158–170. [Google Scholar] [CrossRef]
- Skovranek, T.; Despotovic, V.; Peric, Z. Optimal fractional linear prediction with restricted memory. Ieee Signal Process. Lett. 2019, 26, 760–764. [Google Scholar] [CrossRef]
- Önal, N.Ö.; Karaçuha, K.; Erdinç, G.H.; Karaçuha, B.B.; Karaçuha, E. A Mathematical Approach with Fractional Calculus for the Modelling of Children’s Physical Development. Comput. Math. Methods Med. 2019, 2019, 3081264. [Google Scholar] [CrossRef]
- Önal, N.Ö.; Karaçuha, K.; Erdinç, G.H.; Karaçuha, B.B.; Karaçuha, E. A mathematical model approach regarding the children’s height development with fractional calculus. Int. J. Biomed. Biol. Eng. 2019, 13, 252–260. [Google Scholar]
- Önal, N.Ö.; Karaçuha, K.; Karaçuha, E. A Comparison of Fractional and Polynomial Models: Modelling on Number of Subscribers in the Turkish Mobile Telecommunications Market. Int. J. Appl. Phys. Math. 2019, 10, 41. [Google Scholar] [CrossRef]
- Maddison, A. A comparison of levels of GDP per capita in developed and developing countries, 1700–1980. J. Econ. Hist. 1983, 43, 27–41. [Google Scholar] [CrossRef]
- World Bank Databank World Development Indicators. Available online: https://databank.worldbank.org/source/world-development-indicators# (accessed on 10 December 2019).
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Kingma, D.P.; Ba, J. Adam. A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]




| Country | Deep Assessment | Fractional Model-1 | Deep Assessment * | Polynomial Model * | Fractional Model-1 * | M |
|---|---|---|---|---|---|---|
| US | 0.44 | 0.54 | 0.81% | 1.01% | 1.06% | 15 |
| UK | 0.14 | 0.85 | 5.38% | 7.03% | 6.61% | 15 |
| Brazil | 0.06 | 0.58 | 7.26% | 7.13% | 9.00% | 17 |
| China | 0.03 | 0.95 | 2.84% | 5.62% | 5.67% | 11 |
| India | 0.15 | 0.02 | 3.09% | 2.51% | 4.10% | 16 |
| Japan | 0.26 | 0.69 | 4.45% | 4.64% | 5.82% | 20 |
| EU | 0.06 | 0.89 | 4.02% | 3.41% | 5.71% | 20 |
| Italy | 0.39 | 1 | 4.70% | 8.81% | 8.81% | 9 |
| Spain | 0.22 | 0.58 | 4.44% | 6.49% | 6.36% | 13 |
| Turkey | 0.71 | 0.01 | 6.09% | 11.81% | 8.93% | 10 |
| Country | Interpolation | Deep Assessment * | Deep Learning * | |||
|---|---|---|---|---|---|---|
| Brazil | 0.18 | 24 | 3 | 0.32 | 0.1303% | 0.4728% |
| China | 0.97 | 11 | 3 | 0.5 | 0.7147% | 1.6365% |
| India | 0.96 | 3 | 2 | 0.99 | 0.3379% 5 | 0.7203% |
| Italy | 0.43 | 20 | 4 | 0.43 | 0.1048% | 3.0796% |
| Japan | 0.57 | 4 | 3 | 1 | 0.3499% | 1.1091% |
| Spain | 0.99 | 2 | 3 | 0.99 | 0.0560% | 1.5683% |
| Turkey | 0.39 | 17 | 4 | 0.39 | 0.1167% | 2.3691% |
| EU | 0.32 | 20 | 5 | 0.22 | 0.1044% | 0.2522% |
| US | 0.39 | 25 | 2 | 0.18 | 0.1081% | 0.8424% |
| UK | 0.18 | 18 | 7 | 0.05 | 0.9129% | 3.0508% |
| Country | Deep Assessment | Deep Learning |
|---|---|---|
| Brazil | 7932 | 8013 |
| China | 10,312 | 10,273 |
| India | 2154 | 1967 |
| Italy | 39,028 | 35,141 |
| Japan | 34,421 | 37,994 |
| Spain | 30,385 | 35,372 |
| Turkey | 8260 | 8920 |
| US | 65,767 | 63,844 |
| UK | 44,897 | 44,702 |
| EU | 40,487 | 36,487 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Karaçuha, E.; Tabatadze, V.; Karaçuha, K.; Önal, N.Ö.; Ergün, E. Deep Assessment Methodology Using Fractional Calculus on Mathematical Modeling and Prediction of Gross Domestic Product per Capita of Countries. Mathematics 2020, 8, 633. https://doi.org/10.3390/math8040633
Karaçuha E, Tabatadze V, Karaçuha K, Önal NÖ, Ergün E. Deep Assessment Methodology Using Fractional Calculus on Mathematical Modeling and Prediction of Gross Domestic Product per Capita of Countries. Mathematics. 2020; 8(4):633. https://doi.org/10.3390/math8040633
Chicago/Turabian StyleKaraçuha, Ertuğrul, Vasil Tabatadze, Kamil Karaçuha, Nisa Özge Önal, and Esra Ergün. 2020. "Deep Assessment Methodology Using Fractional Calculus on Mathematical Modeling and Prediction of Gross Domestic Product per Capita of Countries" Mathematics 8, no. 4: 633. https://doi.org/10.3390/math8040633
APA StyleKaraçuha, E., Tabatadze, V., Karaçuha, K., Önal, N. Ö., & Ergün, E. (2020). Deep Assessment Methodology Using Fractional Calculus on Mathematical Modeling and Prediction of Gross Domestic Product per Capita of Countries. Mathematics, 8(4), 633. https://doi.org/10.3390/math8040633