1. Introduction
Wind power is one of the fastest-growing forms of green energy production worldwide. According to the Global Wind Report (2023) [
1], global wind power capacity grew by 9% in 2022 compared to 2021, adding 77.6 GW of fresh production while bringing the total installed capacity to 906 GW for the entire renewable energy industry. Unlike other conventional resources such as fossil fuel and even hydroelectric generation, the kinetic energy continually induced by circulating air is considered an inexhaustible source of power, which is abundant and widely distributed, making it a scalable source that can meet a variety of demands. Moreover, the adverse effects caused by wind plants do not drastically impact local fauna and flora, resulting in a clean and sustainable energy generation [
2,
3]. Another plus is that wind energy is economically competitive with other forms of generation, especially for countries and businesses seeking to reduce their carbon footprint and dependence on fossil fuels [
4,
5].
Despite the benefits and advances promoted by wind-driven generation, electricity produced in wind farms may undergo high volatility. For example, wind speed does not always follow a regular behavior over time. As a consequence, assessing and forecasting energy generation amid the incessant demand of consumption centers is not a straightforward task. In addition, the diversity of technologies and conversion systems used in wind turbines that coexist in large-scale power complexes contribute to generation volatility, thus imposing the necessity of using data-driven tools to keep power production constant, predictable, and reliable for dispatch and consumption. Another issue is that the weather conditions such as the airspeed, relative humidity, air temperature, atmospheric pressure, and precipitation can influence the trend and seasonality of the day-to-day-generated power, especially in large wind farms, resulting in irregular and highly non-linear data, which need to be handled when fitting machine learning models [
6,
7,
8]. Lastly, the electricity load from wind power plants can affect the law of supply and demand in the energy wholesale market [
9], rendering data-driven learning approaches crucial for gaining more-assertive insights for decision-making in this business sector.
In general, the problem of assessing and forecasting the power generation in large wind farms involves investigating the trend and seasonality of combined time series data. According to Quian and Sui [
10], renewable energy prediction planning horizons can be categorized into three groups: (i) short-term (one hour to seven days), (ii) medium-term (one week to one month), and (iii) long-term (one month to one year). Long-term forecasting is crucial for achieving grid balance, infrastructure construction and maintenance, as well as strategic energy planning [
10]. Since the prediction is usually computed by assuming a specific forecast horizon, the long-term case is more challenging due to the high variability of wind power over an extended period, making the forecast task by machine learning models difficult in real-world scenarios [
11,
12,
13].
In the specialized literature, various machine-learning-based approaches have been proposed to estimate energy generation in wind farms. For example, Zheng et al. [
7] employed a Feature Selection Engineering (FSE) step using k-means clustering to build a learning methodology based on the XGBoosting (XGB) algorithm for short-term power forecasting. To train their model, the authors took weather-type features such as temperature, air humidity, and precipitation data. Paula et al. [
12] also applied FSE to improve the discriminative performance of machine learning methods, including Artificial Neural Networks (ANNs), Random Forest (RF), and Gradient Boosting (GB), to estimate wind-related features, while Demolli et al. [
8] utilized XGB, RF, Support Vector Machine (SVM), and Lasso Regression (LG) to compute daily power predictions by inputting wind speed data. Along the same line, Singh et al. [
14] employed a GB-based regression approach to explore the problem of power generation forecasting in Turkish wind farms, delivering short-term predictions. Wind power forecasting was also the goal of Optis and Perr-Sauer [
15], where the stability of the machine learning algorithms Multilayer Perceptron (MLP), Extremely Randomized Trees (ERT), GB, and SVM was assessed by considering the effect of atmospheric turbulence during the problem modeling. Similarly, Li et al. [
16] took the SVM algorithm together with a recent swarm-based optimization method called dragonfly to predict wind power over a short-term period.
The combination of machine learning and statistical analysis is another effective approach that offers an in-depth examination of wind farm data, including forecasts. In this domain, Malska and Damian [
17] conducted an immersive statistical analysis of energy production in a wind farm located in the Subcarpathian region, Poland. Adopting a similar methodology, Shabbir et al. [
18] implemented a recurrent neural network architecture combined with advanced statistical methods to estimate energy generation in an Estonian wind farm. Najeebullah et al. [
19] also applied a statistical framework for wind power prediction, obtaining short-term forecasts through a hybrid modeling based on ANN models. Puri and Nikhil [
20] investigated the availability of wind energy in highly mountainous regions, specifically in the Himalayan Range. Their study employed data on wind speed, temperature, and air density to predict wind energy using ANN-based algorithms, with the goal of enhancing future planning for wind electricity production. Solari et al. [
21] covered forecast horizons restricted to a few days by taking geostrophic wind data to infer wind speed for port safety purposes. In a similar way, Cheng et al. [
22] aimed at achieving short-term outputs by predicting wind-related features based on anemometer data.
Finally, Long Short-Term Memory (LSTM) networks have recently been used to tackle time series prediction applications. In this context, Vaitheeswaran and Ventrapragada [
23] employed a hybrid approach integrating LSTM and Genetic Algorithms (GAs) for wind power prediction, aiming to achieve both short-term and medium-term forecasts. Jaseena and Kovoor [
24] demonstrated that their LSTM-based method outperforms the classic ARIMA technique in short-term wind speed forecasting. Sowmya et al. [
25] also addressed the wind forecasting problem, by applying stacked LSTM architectures instead. Papazek and Schicker [
26] explored different application scenarios by integrating time series data from diverse sources using LSTM, underscoring the importance of customized pre- and post-processing methods in renewable energy prediction. Ziaei and Goudarzi [
27] developed LSTM-driven models specifically for short-term wind estimation, showcasing their effectiveness in capturing wind characteristics with satisfactory accuracy. In a similar fashion, Kumar et al. [
28] applied LSTM and Recurrent Neural Networks (RNNs) for predicting wind speed and solar irradiance. The forecasted renewable energy data were then utilized to analyze the load frequency behavior in an isolated microgrid.
As pointed out by Wilczak et al. [
29] and Mesa et al. [
30], wind power estimation has always been of interest to the energy community; however, the main focus has been on improving short-term wind forecasts instead. Moreover, according to Wang et al. [
31], most regular- and long-term wind power forecasts are primarily designed for individual sites and suffer from certain shortcomings, such as ignoring regional characteristics. Another concern related to extended-range forecasts is that obtaining a computationally robust solution for large-scale wind farms in practice may require the unification of customized tuning approaches, sophisticated optimization models, and accurate machine learning models, as well as the availability of extensive, restricted-access datasets locally acquired from the power plants [
13,
32]. These datasets include not only energy-related data collected from the wind farms, but also the systematic assessment of local meteorological variables.
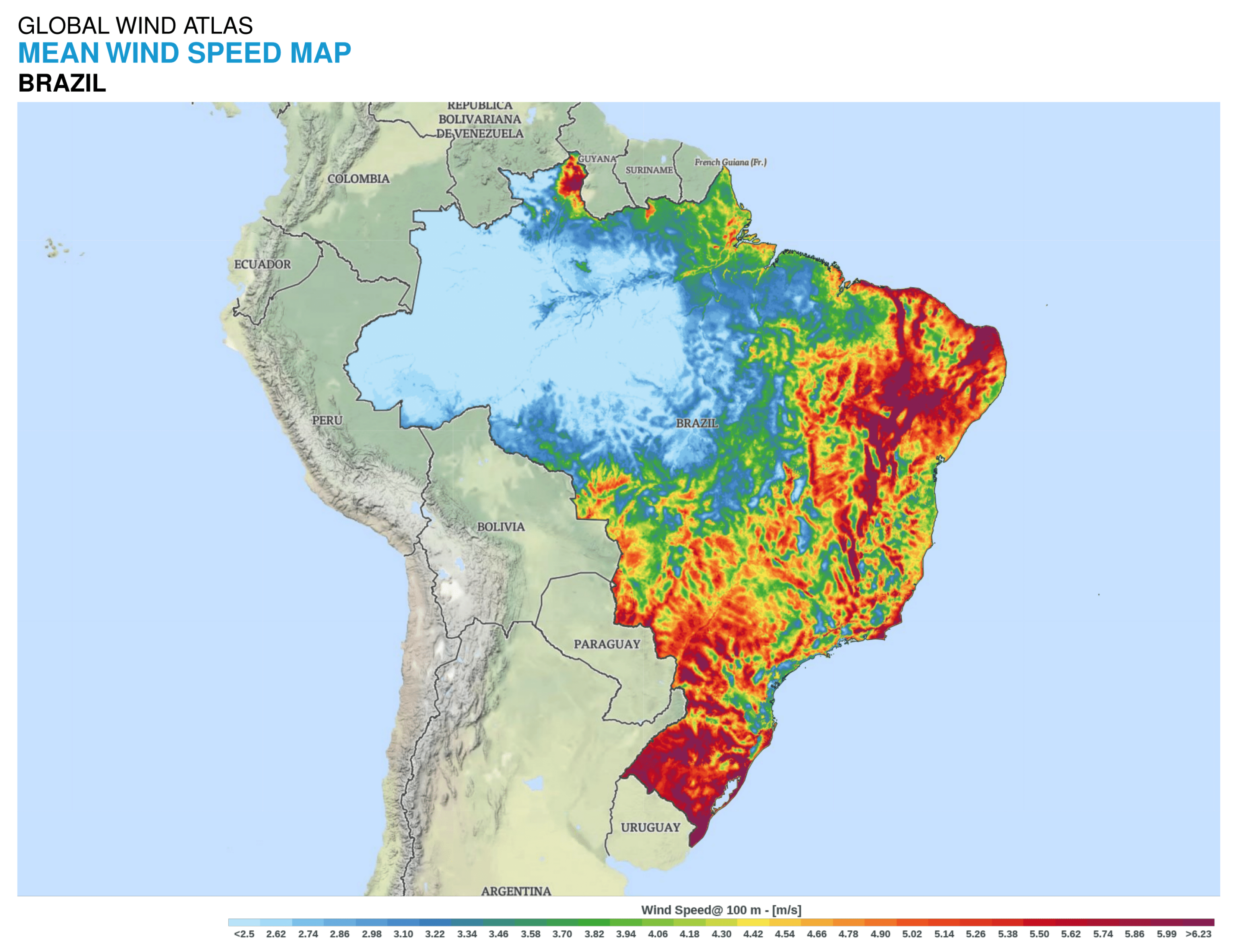
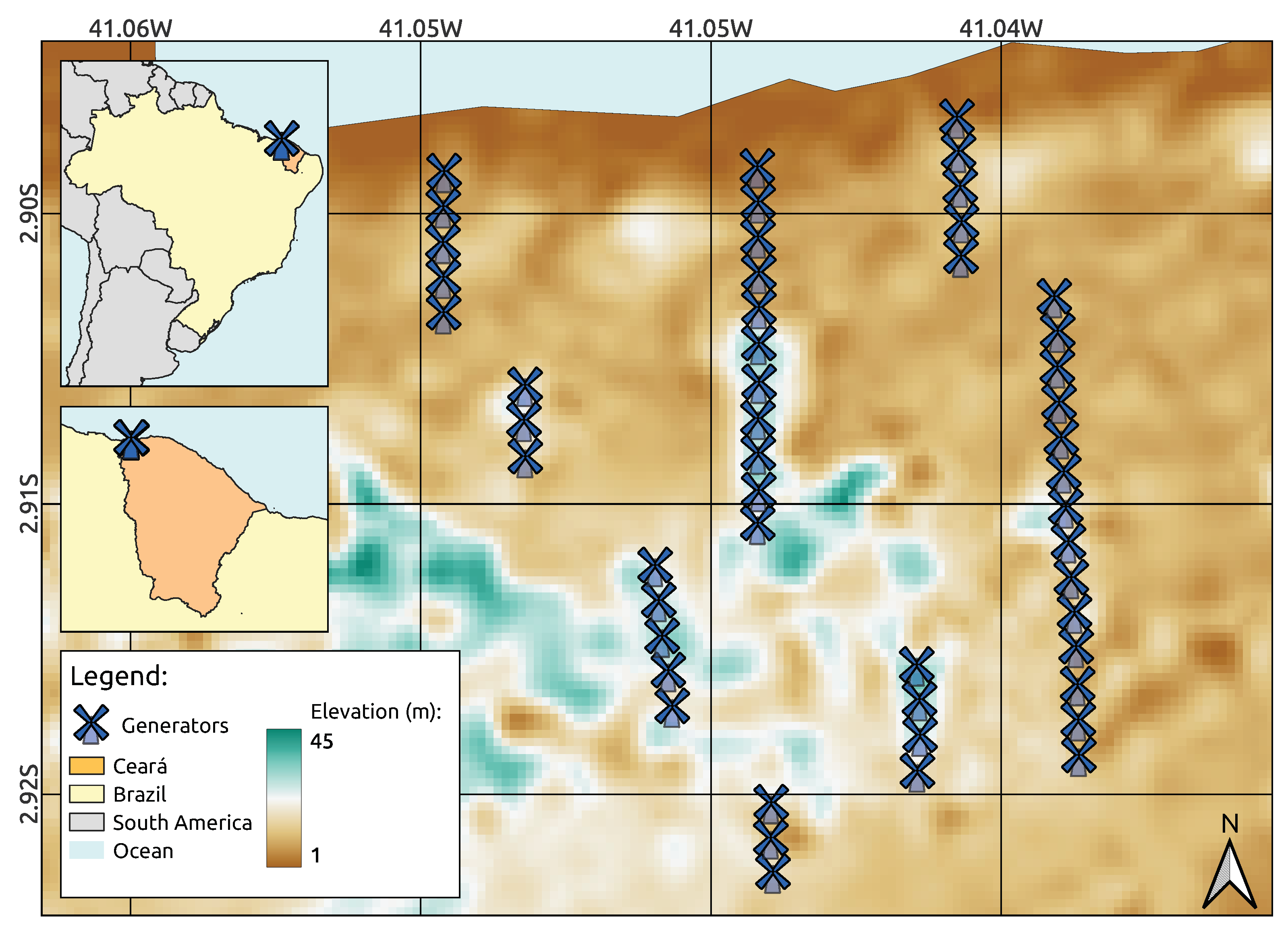
Therefore, in this paper, the focus was on providing an effective data-driven methodology for assessing and predicting the electricity generated at one of the largest renewable energy farms in South America: the Praia Formosa wind complex, located in the municipality of Camocin, in the state of Ceará, Brazil, with an installed capacity of 104.4 MW. To tackle most of the issues raised above, an integrated database was built using open data repositories to train three machine intelligence models: Random Forest, Extreme Gradient Boosting, and Long Short-Term Memory Network, enabling accurate and consistent long-term forecasts. Specifically, public data from both regional weather stations and the National Electric Systems Operator were collected in an effort to improve the model’s predictability by exploiting external factors that may influence wind power generation in this region. As a result, the formulated holistic framework not only enhanced the forecasting accuracy, but also provided valuable insights into the interplay between regional weather conditions and local energy production throughout different periods of the year. Additionally, data-driven strategies, including the use of feature engineering tools, were employed to optimize the accuracy of the machine intelligence models while evaluating the influence of meteorological variables on wind farm power generation.
In summary, the key contributions of this paper are:
The design of three accurate, well-behaved machine learning approaches for long-term forecasting: the RF-, XGB-, and LSTM-based models. Unlike most predictive proposals in the wind energy context, which focus on short-term results, the designed models excel in delivering precise long-range wind power outputs.
The creation of a comprehensive database sourced from multiple open platforms, enabling a thorough analysis of the regional characteristics of the wind farm.
The implementation of customized tuning strategies to optimize the machine intelligence models, leading to significant improvements in long-range predictions.
An in-depth data-driven study of key meteorological variables that most influence wind power generation throughout different seasons and months, providing detailed insights and contextualization for local grid operators and power plant owners.
5. Conclusions
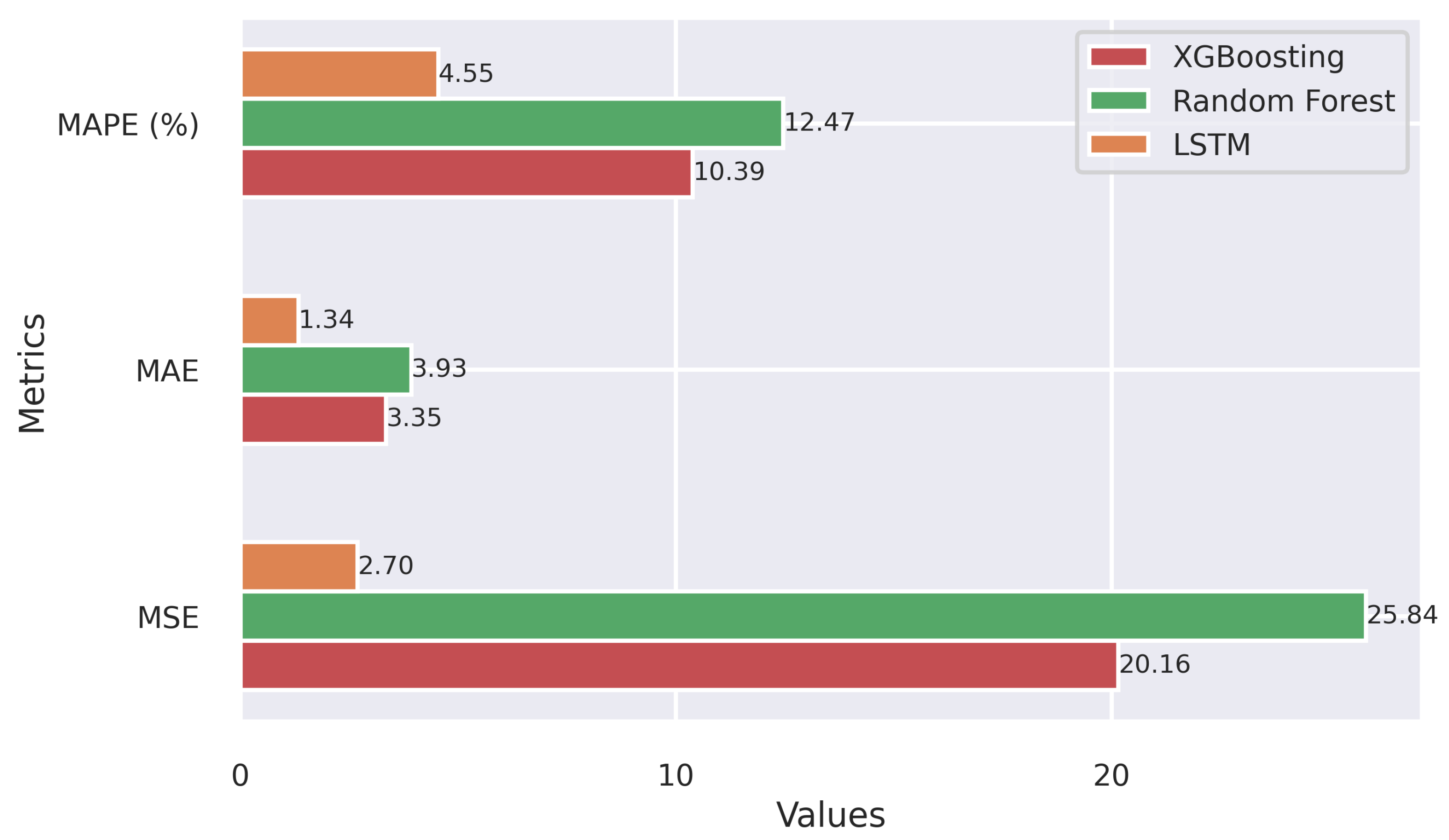
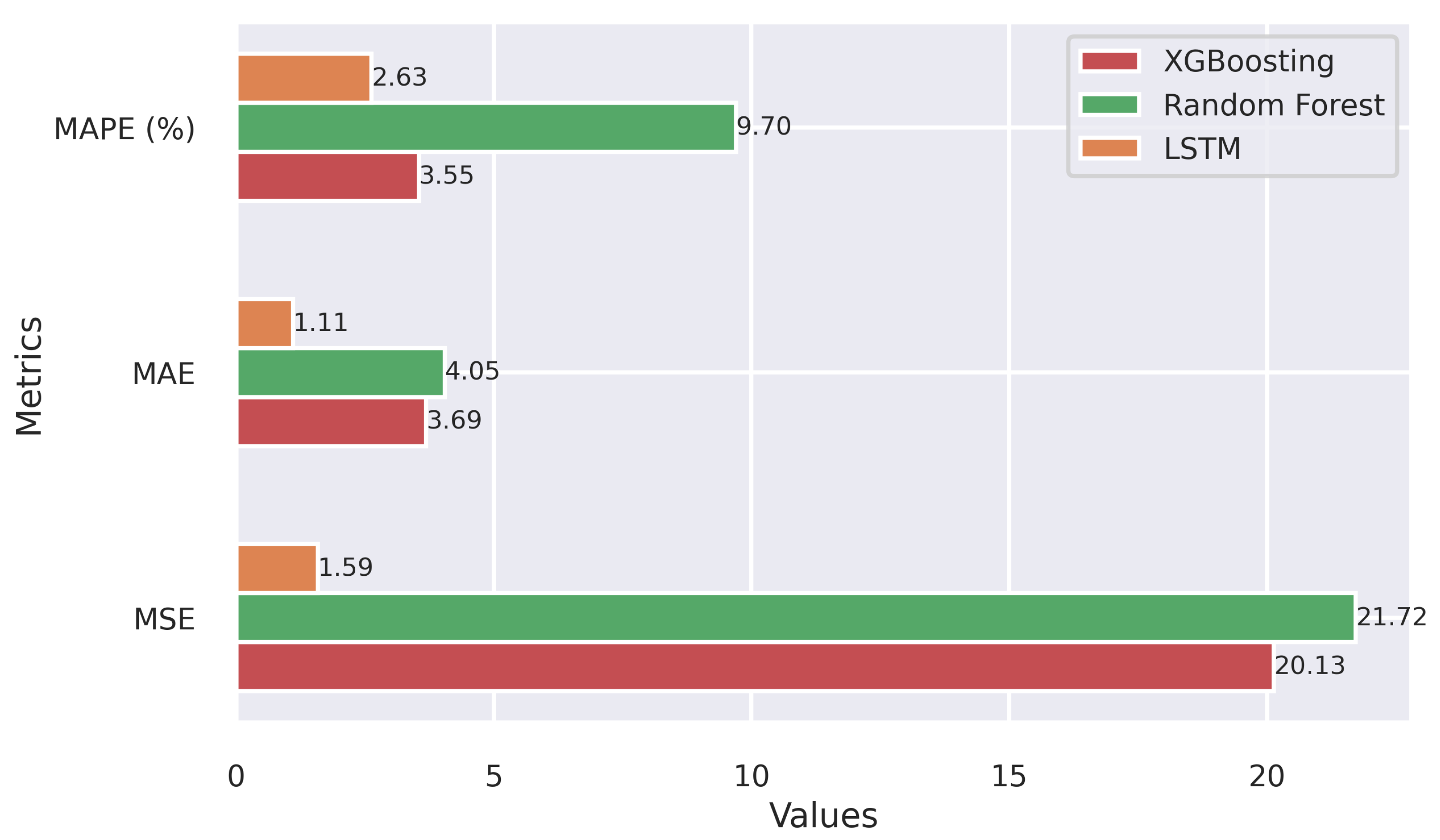
In this paper, a comprehensive and effective data-driven framework for assessing and predicting the wind energy generation at the Praia Formosa park, a large-scale wind complex located in the northeastern region of Brazil, was presented. By integrating data from multiple open sources, including regional weather stations and the National Electric Systems Operator, three machine intelligence models capable of delivering accurate and stable long-term forecasts were implemented and tuned. The implemented machine learning-based models, Random Forest, Extreme Gradient Boosting and Long Short-Term Memory Network, combined with new features, as well as the selection of the best features (K-Best) and hyperparameters (Random Search), resulted in highly accurate predictions, as shown by the validation analysis.
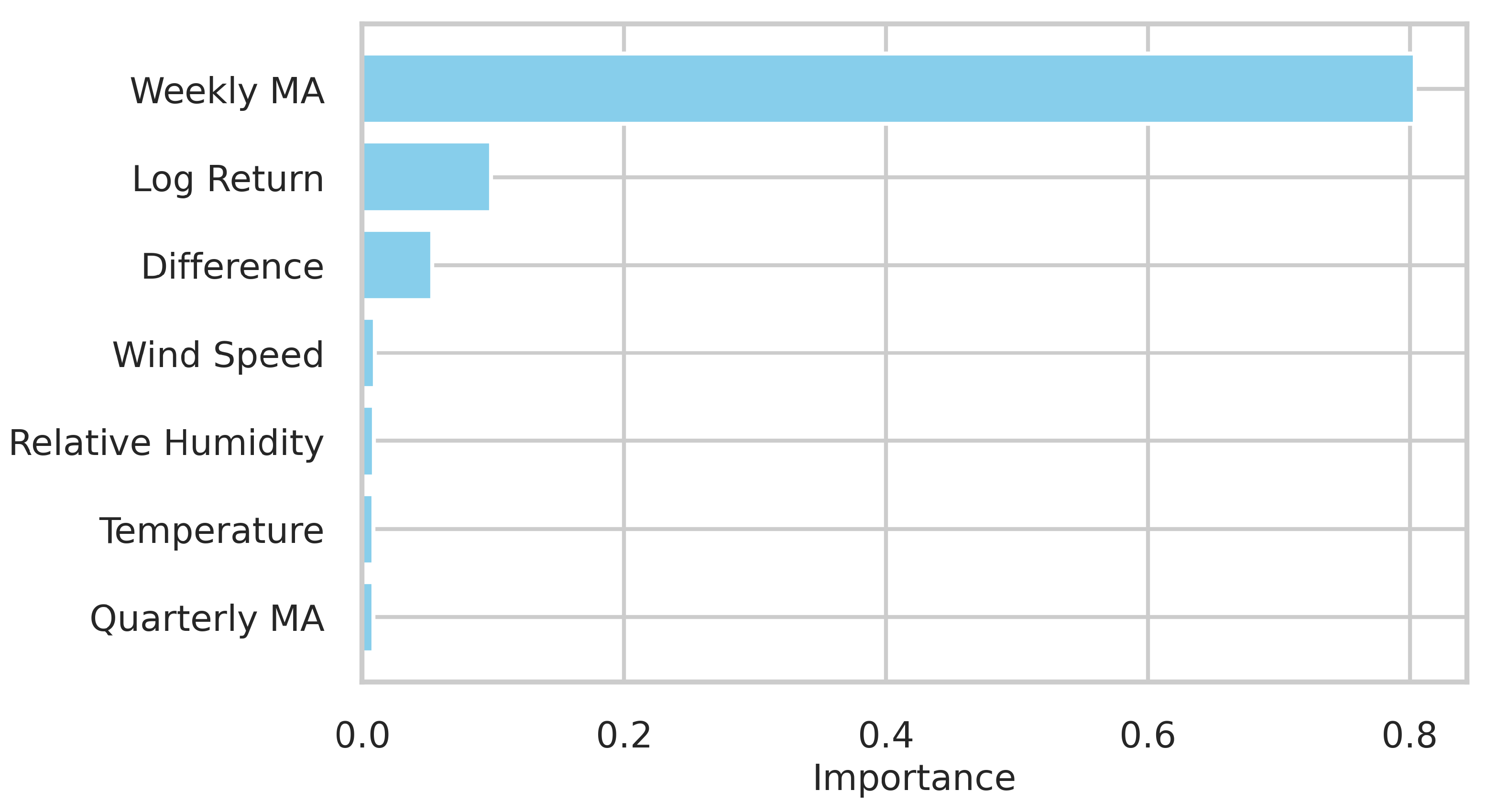
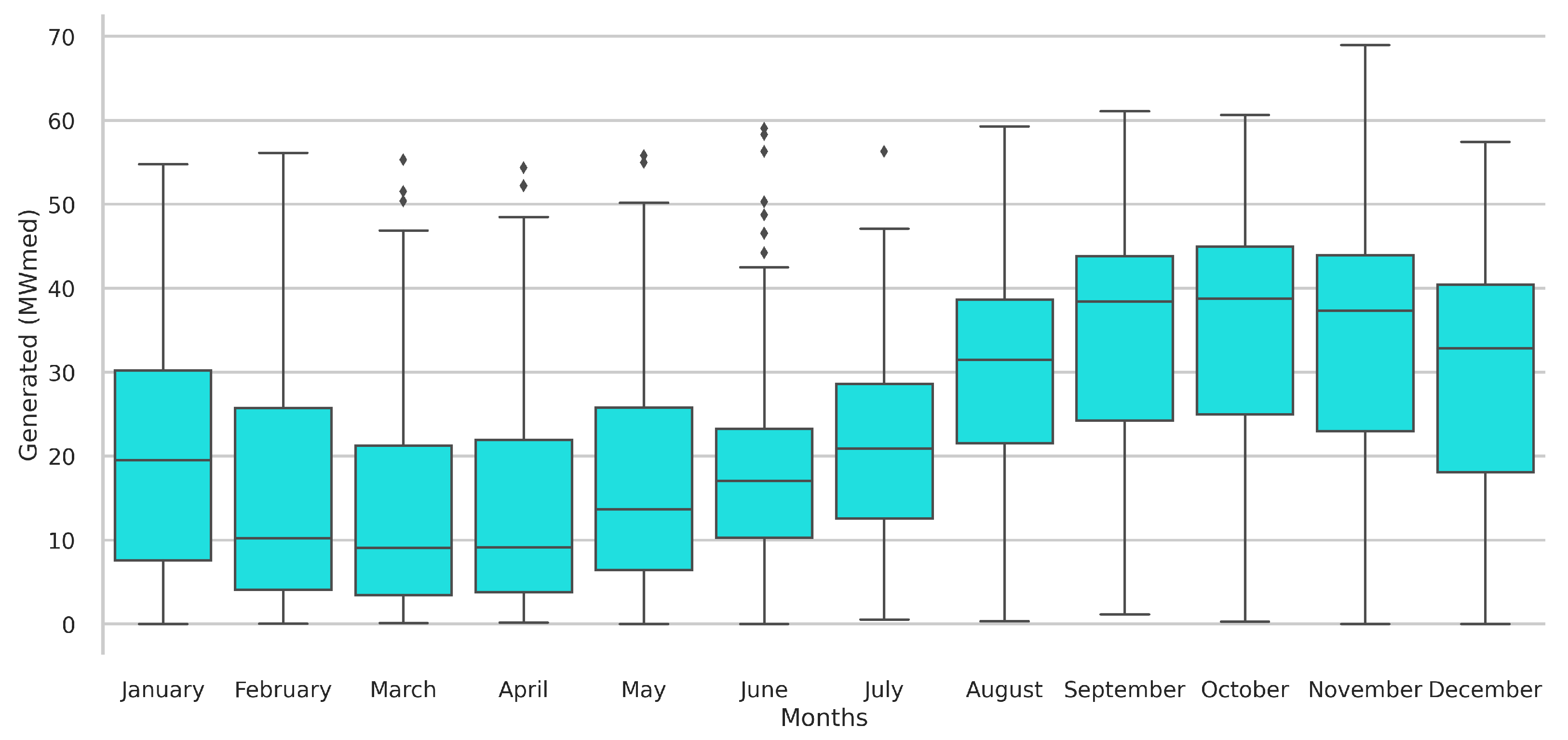
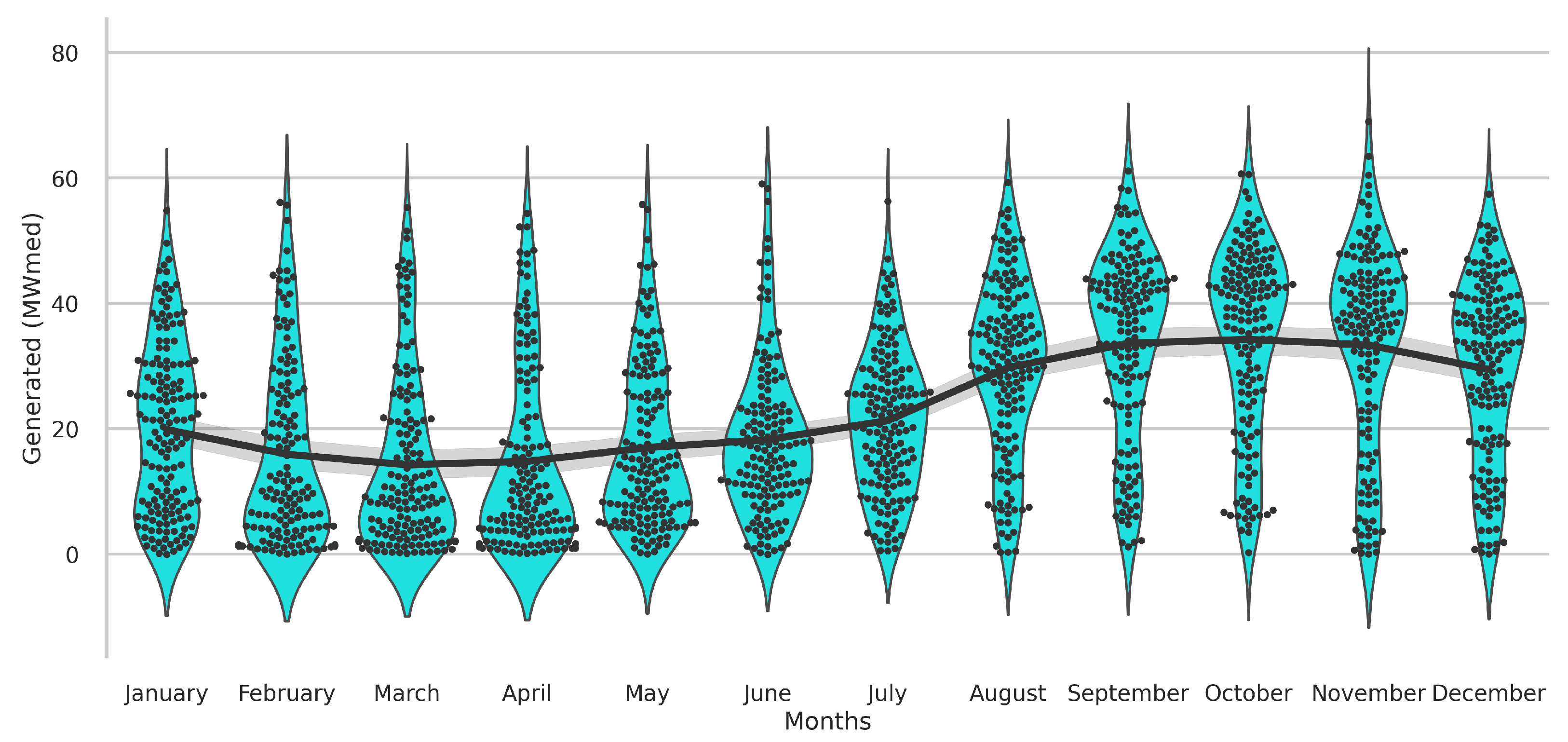
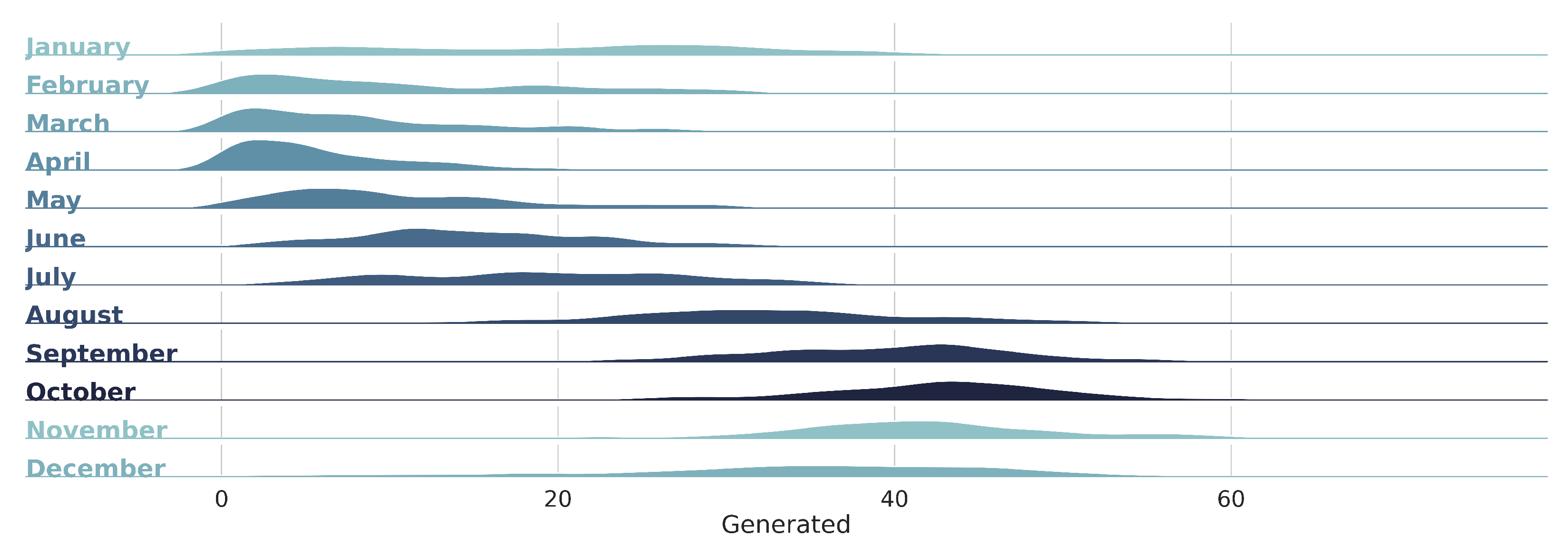
The knowledge data discovery study unlocked valuable insights into the relationship between regional weather conditions and local energy generation. By exploiting the correlation of weather-type features with wind energy, the convergence of the machine intelligence models was enhanced, while still comprehending the role of each variable in power generation. In particular, it was found that temperature, relative humidity and wind speed are the features that have the most significant impact on electricity production at the Praia Formosa wind complex. Another finding is that the generation at the investigated wind park is higher from August to November.
Wind power forecasting conducted over long-term windows, as explored in this paper, can assist power dispatch control not only in the northeastern region, but also throughout the whole country, such as through the National Interconnected System [
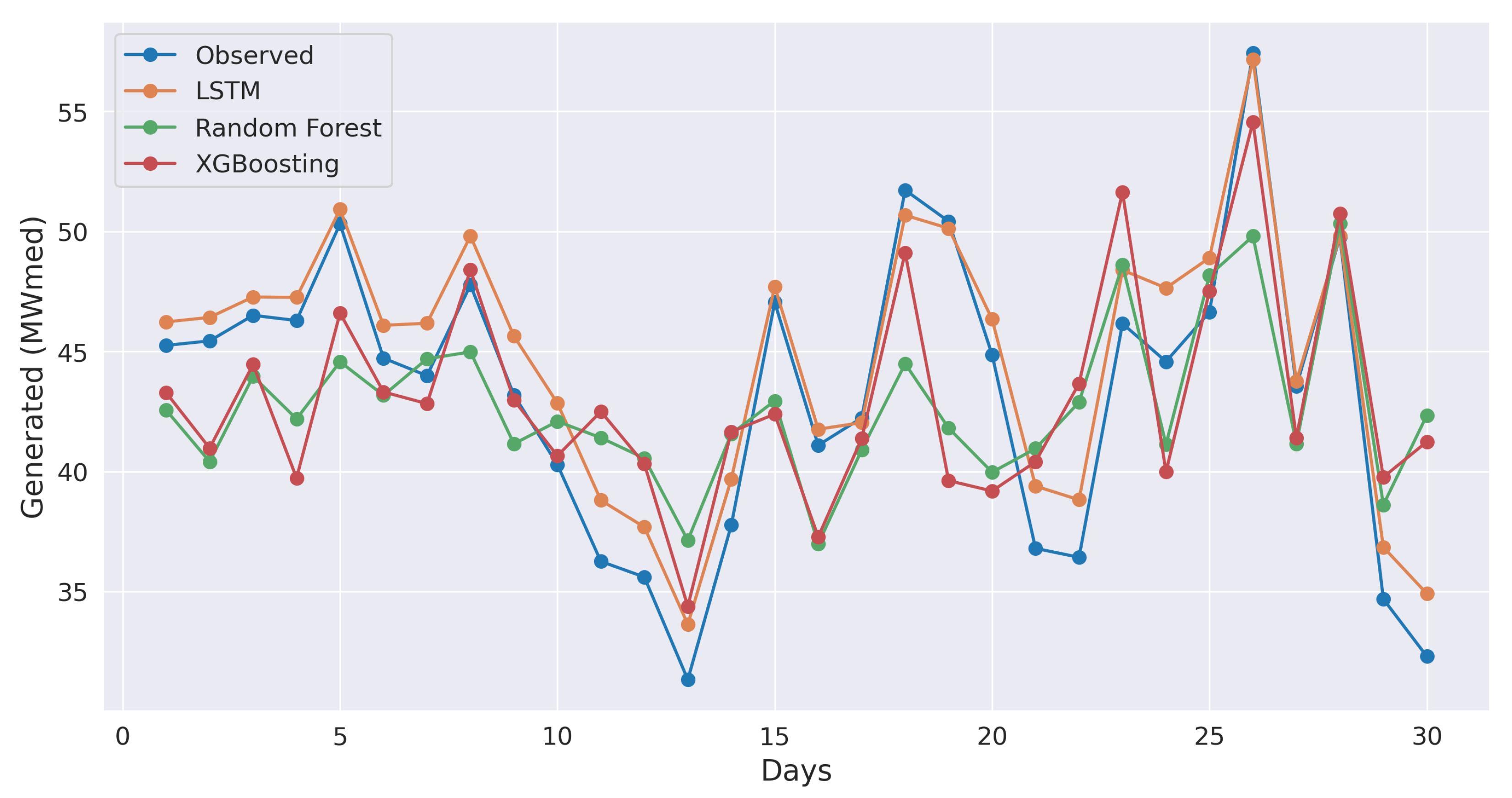
64], as the machine intelligence models demonstrated a good accuracy rate over a full year. While both ensemble-type models, XGB and RF, delivered satisfactory results in terms of the MAPE and MSE metrics, LSTM stands out as the superior choice. The LSTM-based framework exhibited high accuracy, achieving a MAPE score of 4.55%. The forecasting plots for the last month of 2022 attested to the models’ capability to closely mirror actual energy generation, with LSTM excelling in capturing complex patterns.
Concerning the computational efficiency of the implemented models, it was observed that XGB reached the fastest processing time among the evaluated methods during the training phase. However, in the testing stage, the computational demand was notably reduced for all methods, with the LSTM-based model displaying the fastest inference time, completing the task in only 0.95 s. These results highlighted the potential use of the implemented machine intelligence methods for further applications in wind energy forecasting, contingent upon the availability of relevant data and tailored adjustments for different wind farm scenarios.
Apart from introducing a new methodological framework for forecasting energy generation in large-scale wind farms and conducting in-depth analyses of the gathered data, this study offers a comprehensive database sourced from multiple official Brazilian agencies. It caters to the needs of both the industry and researchers interested in investigating wind generation in large-scale parks, with a particular focus on the Brazilian context.


 ,
, 














{kind=link}
{kind=link}
{kind=link}
{kind=link}
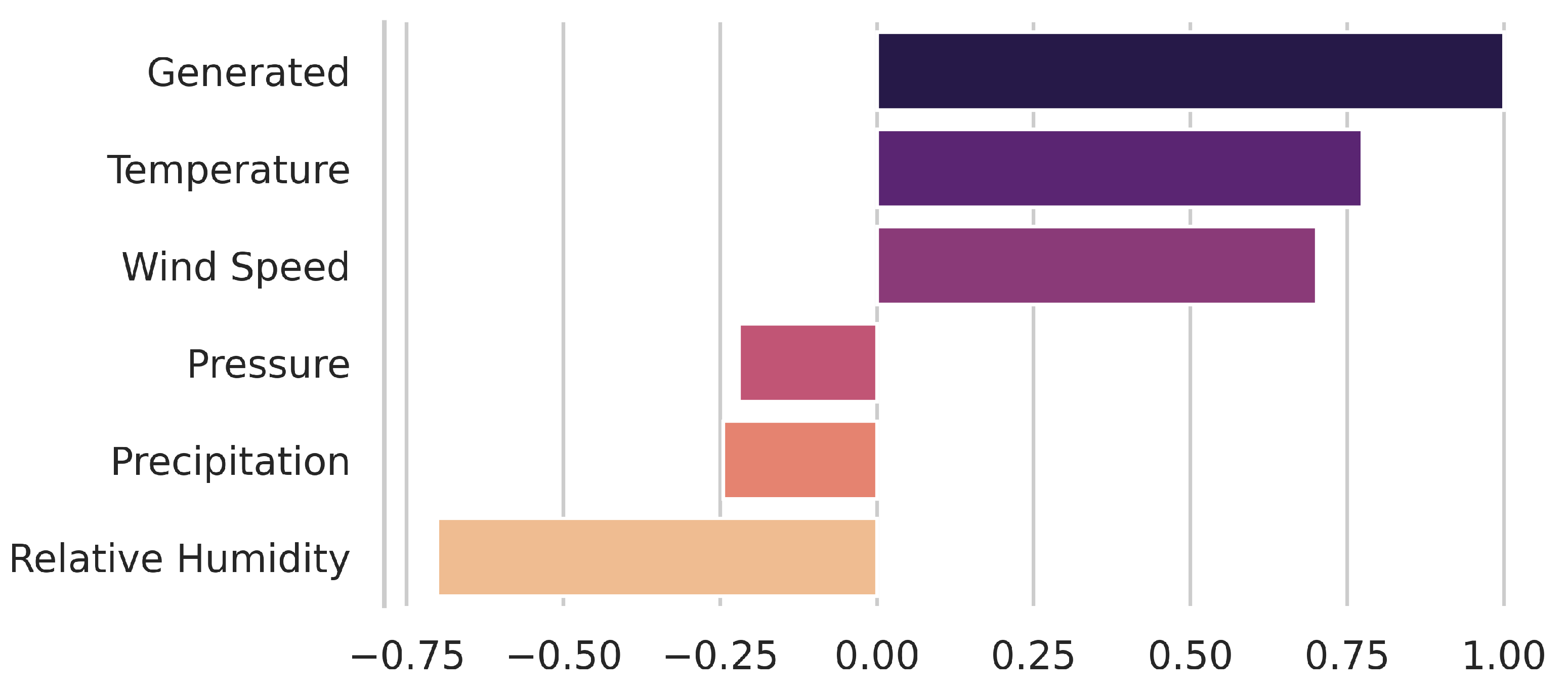{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}