1. Introduction
Cryptocurrencies are new financial instruments based on the technology of blockchains. A coin is defined as a chain of digital signatures. In Bitcoin, each owner transfers the coin by digitally signing a hash of the previous transaction and the public key of the next owner, adding them to the end of the coin [
1]. A cryptocurrency exchange platform is a website on which we can buy and sell coins for other digital currency or trust money. Depending on the exchange, they can operate as a stock exchange or as a currency exchange house, which is very effective and safe for users. The easy access of this market through more than 22,000 projects operating within the industry, exchanges with low fees of transactions, more than 5000 virtual coins worldwide, and a daily trade volume of nearly 174 billion dollars have done cryptocurrencies a very attractive instrument of investment for the general population [
2].
The interactions of cryptocurrencies are not always identical among all variables, in other words, the variables influence each other with different magnitude. Thus, it is necessary to study the asymmetric dependence structure to understand such interactions. The common measures to estimate dependencies, i.e., linear cross-correlation, cross-spectra, and mutual information; share the characteristic to be symmetric in nature. The usual approach to understanding asymmetric dependencies is through the parametric approach of copulas [
3]. Nevertheless, we are interested in an approach from the point of view of information theory in order to take into account the concept of causality. Even though there exist also attempts to model causality via copula-based methods [
4], the information approach works on the broadest sense of free modeling.
The most popular measures of asymmetric dependencies in information theory are related to conditional information or Transfer entropy (TE) based on the concept of Shannon entropy [
5]. This quantity was introduced originally with the purpose to quantify the statistical coherence between systems evolving in time [
6]. Since then transfer entropy has been used to solve problems of different nature. It has been effective in the study of the neuronal cortex of the brain [
7], statistical physics [
8], dynamical systems [
9], given a thermodynamic interpretation in [
10].
In applications to econometrics, transfer entropy can be regarded as a nonlinear generalization of the Granger causality test [
11]. There exists a series of results [
11,
12,
13] that state an exact equivalence between the Granger causality and TE statistics for various approaches and assumptions on the data generating processes, which make it possible to construct TE as a non-parametric test of pure Granger causality. In a previous study [
14], we compared a synthetic linear and non-linear models, and an empirical data set of cryptocurrencies, where is highlighted the advantage of the symbolic estimation of TE over traditional Granger causality test. Moreover, in [
15] the multivariate version of symbolic transfer entropy has been tested, the authors show that it can be applicable to non-stationary time series in mean and variance and is even unaffected by the existence of outliers and vector autoregressive filtering.
Despite this characteristic, the main deficiency of the general TE as a measure of causality is the possibility of spurious causalities due to indirect influences or common drivers. To explain this point consider the processes
X,
Y, and
Z; if a causal interaction is given by
, a bivariate analysis would give a significant link between
X and
Z that is detected as being only indirect in a multivariate analysis [
16]. An approach to overcome this issue is proposed in [
17] by inferring an effective network structure given multivariate interactions using a greedy algorithm. The authors of [
18] improved the methodology by adding a preliminary step to prune the set of sources and implementing a series of rigorous statistical tests to decrease the type I and II errors emerged in the multiple comparisons involved on the computations of multivariate transfer entropy. The approach of these studies employs conditional and collective forms of multivariate transfer entropy [
19,
20].
On the other hand, complex system theory has a long tradition between physicists. The emergence of regularities have been observed in different systems and theories, such as convection, turbulence, phase transition, nonlinear dynamics, renormalization theory, among other fields of physics [
21]. However, there is no strict mathematical definition of what complexity is, rather it is characterized according to the properties presented in the particular system. These properties are commonly referred as scale invariance, self-organized criticality, hierarchical structure, coexistence of collective effects and noise, variability and adaptability, and highly optimized tolerance [
22].
Network representation has become a common approach to represent interactions between elements in complex systems. This tool allows characterizing the properties of different phenomenan in a common framework. Graph theory has become an essential piece to the understanding of the structure and behavior of these systems. Based on it has been possible to discover emerging properties having fundamental implications on different areas of knowledge [
23]. The representation of the financial markets through networks and the study of their complex structure draw attention in physics since the seminal work [
24]. There, it is introduced the ultrametric distance and the Minimum Spanning Tree (MST) to characterize the correlations between the stocks used to compute the Dow Jones Industrial Average (DJIA) index, and the portfolio of stocks used to compute the Standard and Poor’s 500 (S&P 500). Also, in [
25] it is extended the methodology to study a portfolio of equities at different time horizons, as well as the MST structure of volatilities comparing the network’s topological properties of real and artificial markets.
Subsequently, a series of works have emerged that describes an analogy between the foreign exchange market (or Forex) and the cryptocurrency market, using as a framework the tools that characterize complex networks. To begin with, the work done on [
26] studied a large collection of daily time series for world currencies’ exchange rates through MST methodology. They find an autoscaling behavior in the degree distribution of the network, and demonstrate the existence of a hierarchical structure in the currency markets by developing an analytical model. In the simultaneous works [
27,
28] the authors show that the structure of the Forex network depends on the base currency. In addition, they found the network is not stable in time, noting the USD node gradually loses its centrality, while the EUR node starts turning more central during the study period. In relation to cryptocurrencies, the study [
29] analyzes the return distribution, volatility autocorrelation, Hurst exponents, and the effects of multiscaling for the Bitcoin market. There, the authors find that this market show signs of maturity during the last months of the analysis, whose characteristics resemble the complex properties of the Forex market. The analysis done in [
30], found further evidence of the shared features of Forex and Cryptocurrency markets at high-frequency rate. Besides, it is pointing out the BTC/ETH and EUR/USD exchange rates do not show any significant relationships. Thus, they hypothesize both markets start decoupling. The same authors extend their study to 100 cryptocurrencies, introducing the collective analysis of random matrices [
31]. They found that the level of collectivity depends on which cryptocurrency is used as the exchange rate. Moreover, it is detected that the USD begins to disconnect from the network and resemble a fictitious currency, which may imply the cryptocurrencies’ autonomy. Last, the work of [
32] studies the relationship between both markets from a more econometric perspective, where it is explained the importance of diversifying between them.
The previous results pave the way to carry out extensive studies on cryptocurrencies without having to link them to the forex markets, despite the fact both markets share several similarities. In this spirit we are interested to study the complexity properties that emerge in the induced network by multivariate entropy transfer when considering the price and volume of transaction. In this sense, we are seeking to characterize their asymmetric interactions by applying a series of statistical tests with the intention of considering only significant connections. To the aim of bias reduction, we are looking for multivariate rather than bivariate approach. Likewise, it is desired to describe the turbulence observed during March 2020 by interpreting the temporal behavior of the directed interactions via the complex network’s artifacts. In this regard, the turmoil of cryptocurrencies has been analyzed in [
33] from the concept of
bull and bear market. The authors study the three largest cryptocurrencies of Bitcoin, Ethereum, and Litecoin through the technique of Detrended Fluctuation Analysis (DFA) analyzing the Hurst exponent over a different time windows. They find that during the
bull period the market is efficient, whereas in
bear times it is inefficient.
Furthermore, there exist literature discussing the spillover effect and systematic risk among the cryptocurrency markets. In [
34] it is found that the structural breaks are universally present in seven of the largest cryptocurrencies, whereas it is spreads from the smallest to the largest currencies, in order of capitalization. This finding is done by implementing the Granger causality test, as well as a test for the ARCH and the Dynamic Conditional Correlation MGARCH to the selected coins. Furthermore, the work [
35] show evidence that Ethereum is likely to be the independent coin in the cryptocurrency markets, while Bitcoin tends to be the spillover effect recipient. There, the author modeled the system by variants of the Vector Autoregressive Model (VAR), and using jointly distributed Student’s-t copulas to measure the risk contagion among cryptocurrencies. Moreover, the study [
36] found a risk contagion effect between cryptocurrencies when applying a copula approach. There, it is suggested to perform portfolio diversification to avoid this phenomenon.
On the perspective of transfer entropy, the study of Sandoval [
37] uses the information measure to characterize the contagion of institutions in times of crisis. He identifies the companies most vulnerable to be contagious on countries that have suffered sovereign default. A recent study in similar direction is [
38], where transfer entropy is estimated by discretizing the return time series into positive and negative values and validated by resampling. The researchers constructed an indicator to measure the systematic risk on the stock market and real state data. They observed the networks manifest strongly connectivity around periods of high volatility around the crash of 2008. Further, the authors of [
39] apply the Rényi Transfer Entropy to investigate the interactions between the crude oil markets and the cryptocurrency markets. Their results suggest that the macroscopic economic value of the US crude oil has an contagion effect on the cryptocurrency markets.
In this study, we analyze the cryptocurrency network induced by the estimation of the multivariate transfer entropy as proposed in [
18]. We are especially interested to understand the effects of the financial turbulence of 2020 on the market of cryptocurrencies taking into account the price and volume of transactions as a variable of interest. To obtain deeper insights about the structure of the induced network we quantify the clustering coefficient and estimate the degree distributions of nodes, which are two standard tools from complex networks [
40]. Our work follows the line of thought of the literature discussed above, specifically in the sense of studying the systematic risk and contagion between the currencies through the transfer entropy when the cryptocurrency market is in a turbulent situation. Likewise, the March 2020 turmoil is explored with network theory’s tools, which have had a fundamental role in the econophysics interpretation of the complex systems that emerge in finance.
However, our work is distinguished in combining a series of elements that give rise to ask and exploring the following questions, which as far as we know have not yet been discussed in the literature: Do the directed networks associated to the multivariate transfer entropy of volume and price of cryptocurrencies present complex properties? Is it possible to characterize and in some sense to anticipate the turmoils on the cryptocurrency markets through the properties of the network induced by the multivariate transfer entropy? Can the clustering coefficients of these networks play the role of an early indicator of turbulence in these markets? Is there self-similarity in the induced networks, and if so, how do we interpret this characteristic in turbulent times?
We hypothesize the complex properties of the multivariate transfer entropy network may provide early warning signals of increasing systematic risk. This is inferring through evidence found during the turbulence of March 2020 for the induced directed networks by the multivariate information measure of the hourly volume and price of 146 coins from December 2019 to April 2020. We hope, these results may help the practitioners who venture to invest in this risky class of financial instruments to have further quantitative tools to assess systematic risk during times of turbulence.
The next
Section 2 describes the data under study.
Section 3 presents the greedy algorithm and the series of statistical tests involved in the computation of multivariate transfer entropy, as well as preliminary results. In
Section 4 the network dynamics characterized by the clustering coefficient and power law fitness are analyzed in the context of the generated network of cryptocurrencies. Finally,
Section 5 highlights the implications of the results and future work is proposed.
2. Data
We consider the price and volume in dollars of
cryptocurrencies, which are obtained using the API of CoinMarketCap [
2] for the period from 00:00 2019-12-01 to 00:00 2020-04-05, at an hourly frequency, resulting in a total of
observations (see
Supplementary Material). The data acquisition and preprocessing strategy consisted in creating a database on a remote Linux server and automatically make calls to the CoinMarketCap API (in UTC time) to request the price and volume of the first 200 coins in order of capitalization on the day the database was built, i.e., on the 9th November 2019. The frequency and number of currencies were chosen in such a way that it did not exceed the number of requests or credits allowed by the API. The intention was to fulfill the commitment to have the maximum number of coins at the highest possible frequency. The cryptocurrencies are selected under the condition of having each less of
of missing values in volume and price during the trading period. In case of no record, a spline interpolation of order three was used to fill the time series gaps. Thus, our set of variables dropped to the reduced variables stated above (
). In addition, we transformed the
time series into price-returns
, and volume-returns
by computing the logarithmic difference of consecutive observations
where
;
; and
,
stands for the price and volume of cryptocurrency
k at time
t, respectively. In this way, we deal only with the stochastic part of the time series.
Even though the general approximation of the transfer entropy is non-parametric, we are going to use a Gaussian estimator for the conditional distributions as will be explained in the next section. Then, it is necessary to ensure that the data is stationary. For this purpose, it is a usual practice to take as an input the logarithmic returns to satisfy this requirement. Another approach is not to use excessively long time series, even though it may create a compromise between the bias of the transfer entropy estimator and stationarity. In this study, in addition to using moderately long log-returns time series, we have verified stationarity using the augmented Dickey-Fuller test [
41] and the Phillips-Perron test [
42]. In both tests it has been obtained a
p-value less than 0.001 for all the
time series considered. Therefore, it is confirmed no evidence of a unit root in any variable.
Further, it is known that the distribution of financial and cryptocurrency data change according to the resolution that we observe them [
43,
44,
45]. In this sense, it is important to keep in mind the implications of our results are only valid for hourly observations. Our interest in this frequency lies in the high volume of transactions that take place intra-day on the market of cryptocurrencies. However, we did not want to go to higher frequencies (minutes) due to two situations. The first is that volatility increases and it is more difficult to justify stationarity. Second, the justification for using a Gaussian estimator to calculate the entropy transfer would be invalided because the distribution of the logarithmic returns increases its kurtosis and their distribution start resembles one of the Levy family [
45]. On the other hand, we are interested to delimit our work for the period of time just before the pandemic effects take place. Consequently, we have the limitation of having not too many days of transactions around this event, so the sample would not be large enough to obtain an unbiased estimation of multivariate transfer entropy if used daily time series.
Finally, it is important to mention that we are working with non-traded prices. Coinmarketcap is known as a
coin-ranking service because they rank both coins and exchanges by trading volume and market capitalization to weight their cryptocurrencies data. The specific strategy followed by CoinMarketCap can be found in [
46]. This type of information would represent a problem if we were interested in proposing an optimal portfolio, hedging strategies, or trading applications, as is properly warned in [
47]. Nonetheless, it is not the goal of this study, we are interested in the weighted information provided by CoinMarketCap, since it estimates the formation of prices considering important features of the cryptocurrency data and selected exchanges. The last is more in tune with the vision of complex systems. In other words, the objective of our study is in essence explanatory rather than predictive. Notwithstanding, it should be kept in mind the results are conditioned to the way in which CoinMarketCap weighted the information.
3. Multivariate Transfer Entropy
The Transfer Entropy (TE) from a process
X to a process
Y measures the amount of uncertainty reduced in future values of X by knowing the past states of Y and X itself. In other words, transfer Entropy (TE) quantifies the amount of information that the past of a source process
X provides about the current value of a target process
, considering the context of
Y’s own past. In a multivariate setting, a set of sources
is provided. The multivariate Transfer Entropy (mTE) from
to
Y can be defined as the information that the past of
provides about
, in the context of both
Y’s past and all the other relevant sources in
X. The main challenge is to define and identify the relevant sources. In principle, the mTE from
to
Y is computed by conditioning on all the other sources in the network, i.e.,
. However, in practice, the sizes of the conditioning set must be reduced in order to avoid the curse of dimensionality. The idea is to restrict the conditioning set by finding and including the sources that participate with
in reducing the uncertainty about
, in the context of
Y’s own past. The set of relevant sources will be denoted as
Z [
48].
In order to infer
Z from
X it is followed the greedy algorithm approach suggested by [
17,
18], where
Z is built iteratively by maximizing the conditional mutual information (CMI) criterion. As a first step, a set of candidate variables
is defined from the past values of
X; then,
Z is built including iteratively the candidate variables
c that provides statistically significant maximum information about the current value
, conditioned on all the variables that have already been selected. More formally, at each iteration, the algorithm selects the past variable
that maximizes the conditional mutual information
at significance level
of a maximum information test. The set of selected variables forms a multivariate,
non-uniform embedding of
X [
49] (See
Appendix A).
The implemented greedy algorithm operates in several steps. First,
Z is initialized as an empty set and is considered the candidate sets for
Y’s past
and
X’s past
. Second, variables from
are selected. To this end, for each candidate,
, it is estimated the information contribution to
as
. Next, it is found the candidate with maximum information contribution,
, and is performed a significance test; if it is found significant, must be added
to
Z and remove it from
. In addition, the
maximum statistic (see
Appendix B.1) is used to test for significance while controlling the Family-Wise Error Rate (FWER). Then, the algorithm stops if
is not significant or
is empty. Third, variables are selected from
X’s past states, i.e., iteratively candidates in
are tested following the procedure described before. Fourth, redundant variables in
Z are tested and removed using the
minimum statistic (see
Appendix B.2). The minimum statistic computes the conditional mutual information between every selected variable in
Z and the current value, conditional on all the remaining variables in
Z. This test is performed to ensure that the variables included in the early steps of the iteration still provide a significant information contribution in the context of the final parent set
Z [
17]. Fifth, the
omnibus test is performed (see
Appendix B.3) to test the collective information transfer from all the relevant source variables to the target
. The resulting omnibus
p-value is later used for the correction of the FWER at the network level. If the omnibus test is significant, a sequential maximum statistic is performed on each selected variable
to obtain the final information contribution and
p-value for each variable.
The mTE between a single source
and target
Y can be computed from the inferred non-uniform embedding
Z. To this end, it is collected from
Z all of
’s selected past variables,
, and calculated the mTE as
. Note that time lag between
’s selected past variables and the current value at time
t indicates the information-transfer delay [
50]. The delay can be estimated as the lag of the past variable which provides the maximum individual information contribution, where the maximum contribution is indicated either by the maximum raw TE estimate or by the minimum
p-value over all variables from the source. Finally, the algorithm must be repeated for every node (or variable) in the network (see [
18] for an extensive description of the mTE algorithm and hypothesis testing).
mTE Network of Cryptocurrencies
We consider each time series of price-returns and volume-returns of cryptocurrencies to be a stochastic process in order to detect the causal relations between the variables. The procedure is to fix the target variable
, the source set as
, and apply the mTE algorithm [
48] described above for each time series
, where the first
p variables represent the price-returns and the last
p variables the volume-returns, where
as described in the data section. The intention is to detect if the causal relations of price-returns and volume-returns bring clues to understand the dynamic of cryptocurrency market in times of turbulence. Hence, we design a temporal analysis of time windows of 21 days, sliding by seven days, and using an overlapping of 14 days. Under this procedure, it is obtained
time windows, the first from the 01:00 of 2019-12-01 to 00:00 of 2019-12-22, and the last from 01:00 of 2020-03-15 to 00:00 of 2020-04-05. Thus, each data frame contain
observations of hourly price-returns and volume-returns, i.e., having dimensions
.
It is of primary importance to estimate the CMI, represented above as
, in order to quantify mTE, where
. We estimate CMI under the assumption that price-returns and volume-returns follow a jointly Gaussian continuous distribution, which is equivalent to assume a linear causal dependency as proposed by Granger [
51]. The value added to the original Granger causality test is the use of a multivariate framework to test statistically significant causal relations conditioned to other variables, while the original test only measures bivariate dependencies. We chose Gaussian estimator over a more realistic distribution approach due to the dimension settings as well as the sliding windows turn the computational complexity excessively time demanding. Nevertheless, the results assuming linear dependencies are worthwhile to mention due to the capacity of mTE to detect conditional interactions.
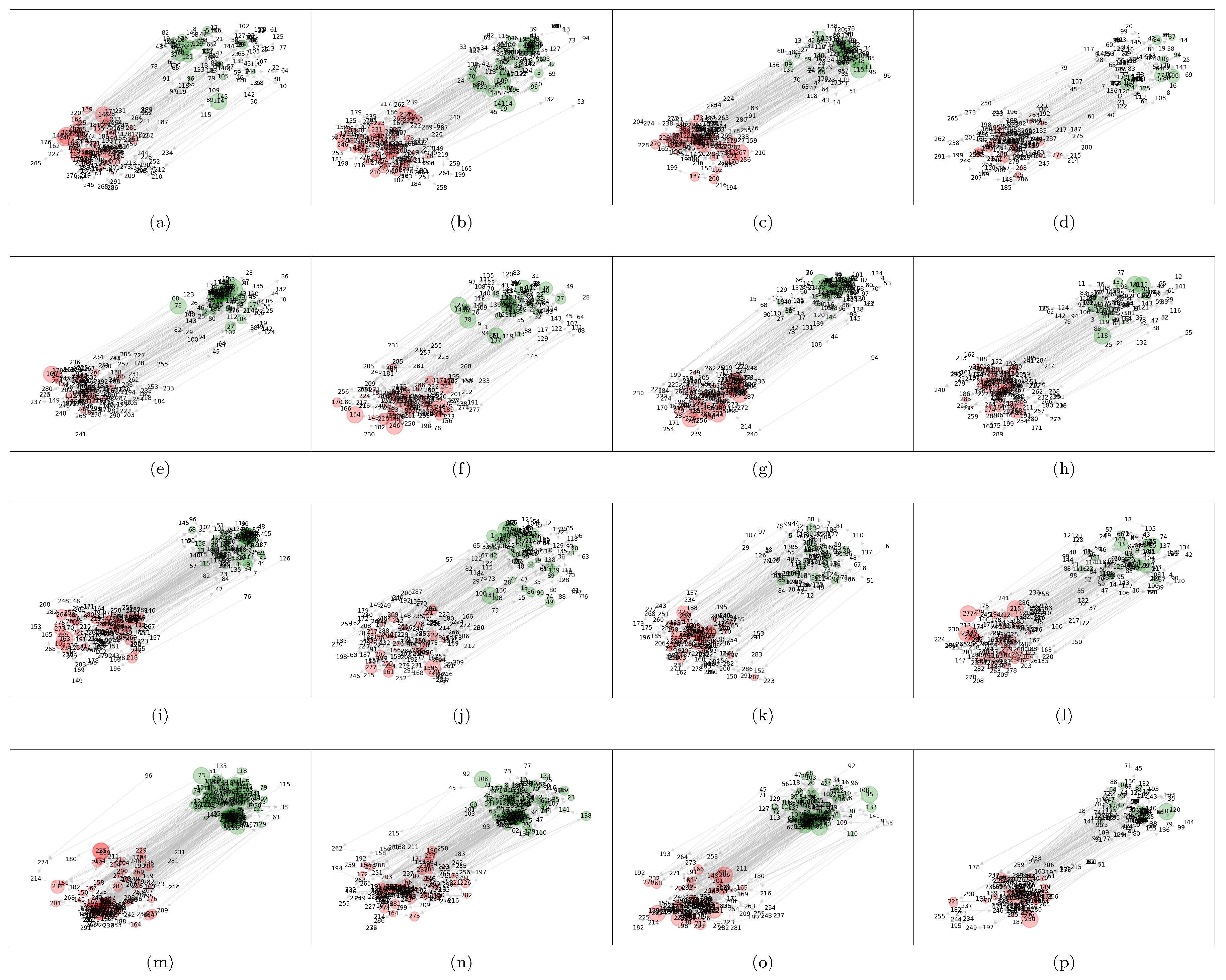
Figure 1 shows the resulting networks for the mTE analysis of cryptocurrencies described above using the Gaussian estimator. Here we set the number of permutations for the surrogate distribution used in the statistical tests (
maximum,
minimum, and
omnibus) to 500, and a significance level of
. The alphabetic order of the subfigures represents the temporal order of the time window of each experiment. Thus, for example, the subfigure (a) shows the results for the time frame 2019-12-01–2019-12-22, the subfigure (b) for 2019-12-08–2019-12-29, and so on. The graph visualization is made using the Kamada-Kawai algorithm [
52], where each variable is represented as a node. We have discriminated the price and volume variables separating their corresponding nodes by a fixed distance to the upper right if it corresponds to a price-return node, and to the lower left if it corresponds to a volume-return node. In addition, the price nodes are colored in green, while the volume ones in red. The directed edges represent true causal relations under the mTE methodology, where we have tested for one to three lags, and as a result, it is obtained a binary adjacency matrix
A. This matrix has elements
if there exit a statistically significant causal relation in this range of lags, and
on the contrary, where
. Finally, the size of each node is drawn according to its clustering coefficient, which is described in the next section. However, here it is already noting the increasing size of the green nodes for the cases (m)–(o), which correspond to the subnetwork of price-returns for the time windows ending at 2020-03-15, 2020-03-22, and 2020-03-29, respectively.
5. Discussion
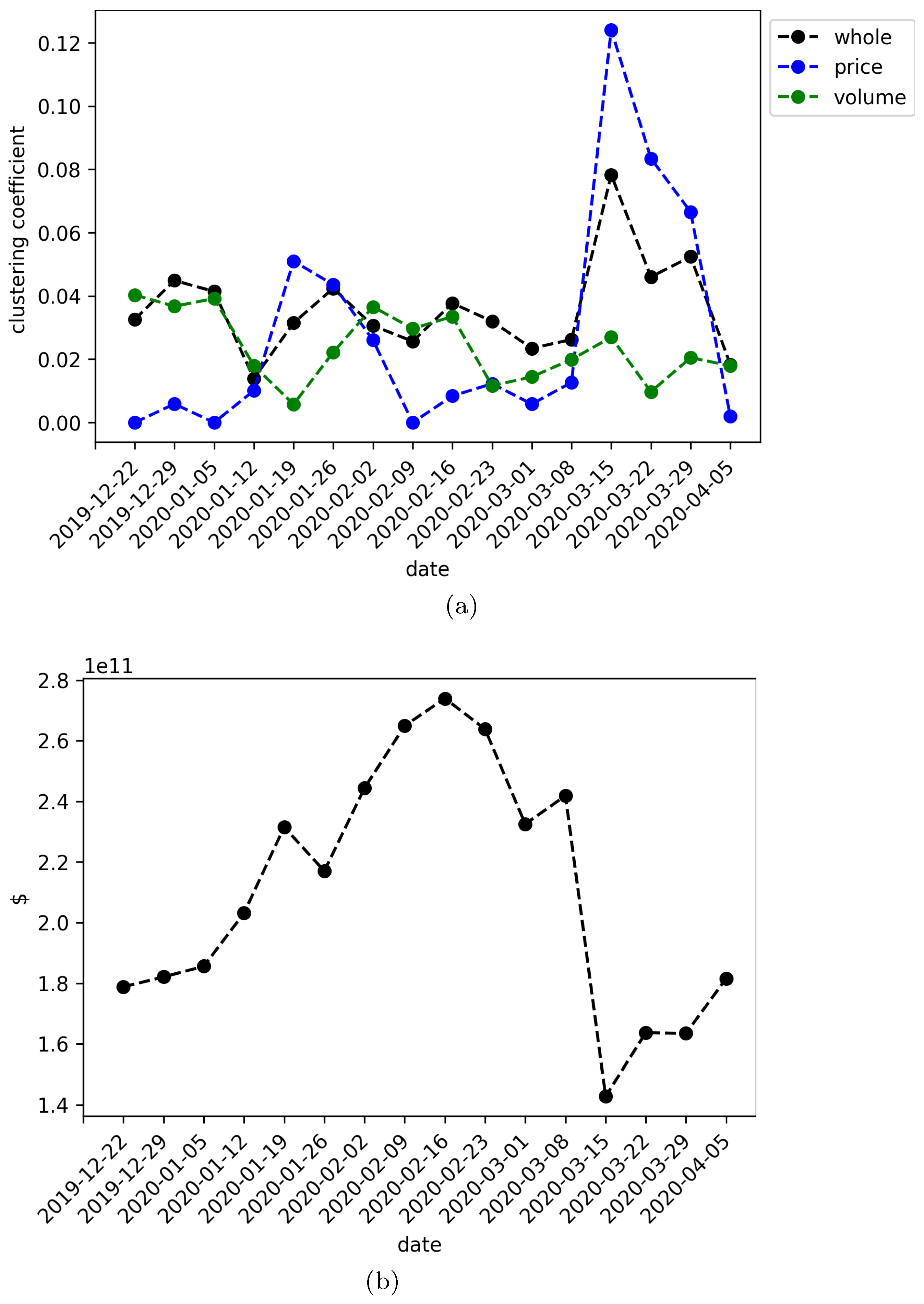
The multivariate approach of transfer entropy followed here is an efficient greedy methodology based on multiple hypothesis testing able to detect true causal interactions. Even though the Gaussian specification for the conditional distributions involved in the computations of mTE do not capture non-linear structures in the data, the induced networks of cryptocurrencies exhibit interesting characteristics. Actually, the graph visualization of the interactions of price-returns and volume-returns using the Kamada-Kawai algorithm already displays an informative picture. Under this descriptive representation has been possible to distinguish three time windows where the strength of the attractive forces between nodes stand out to be stronger than the other scenarios. Interestingly, these periods coincide with the most severe fall of the recent worldwide stock markets crash on March 2020.
The clustering coefficient version for directed graphs was also measured. In this case, we first notice that the individual coefficient also increases during the times mentioned above, which motivated us to analyze the temporal behavior of the clustering coefficient for the whole network. Here, our greatest contribution arose finding that the clustering coefficient of the whole network, as well as the price-returns subnetwork, increases dramatically during the same periods of major financial contraction, where we use as an indicator of turbulence the market capitalization of the cryptocurrencies under study.
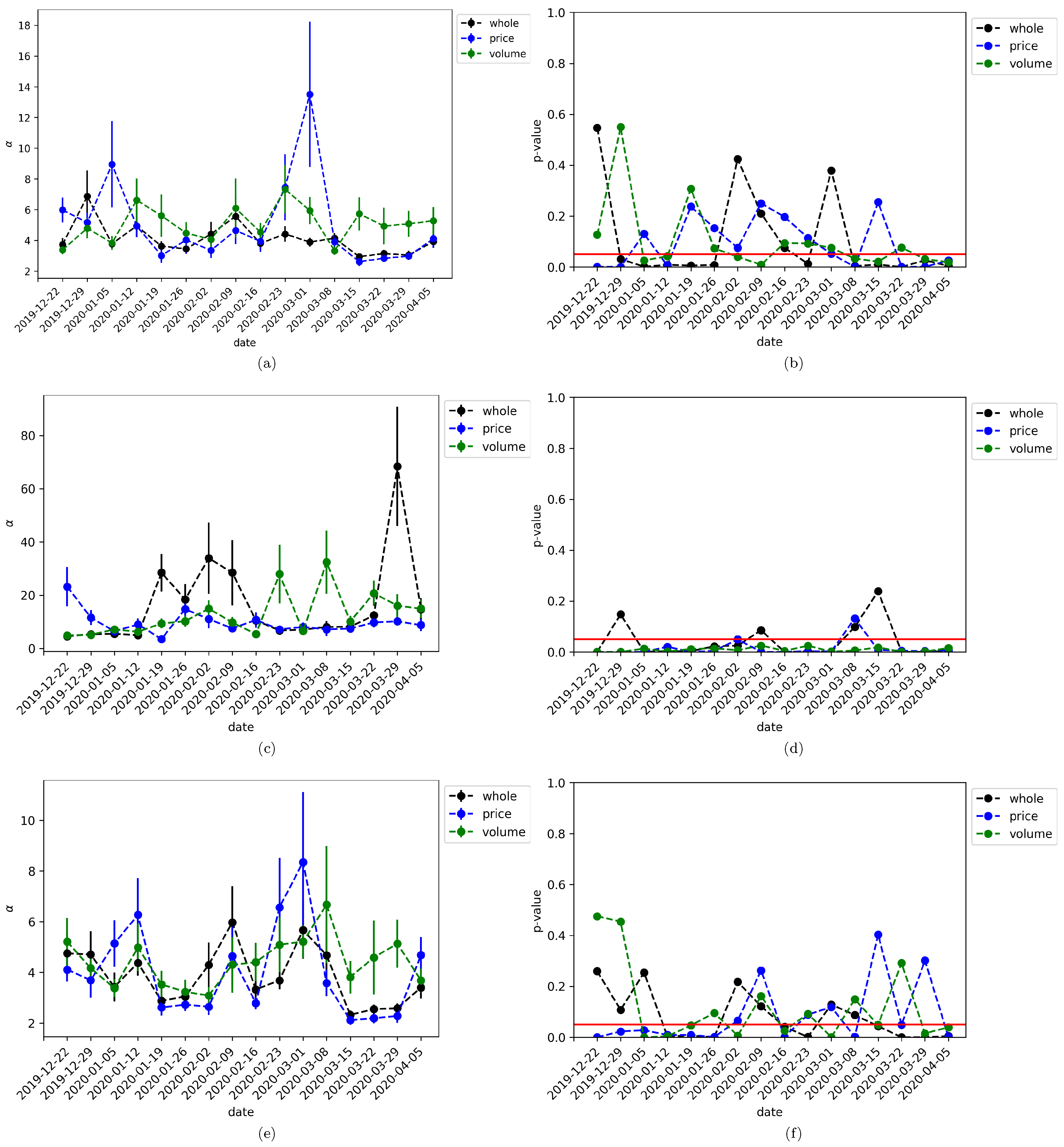
In addition, we explored deeper the structure of the network through the analysis of the degree distribution of nodes as well as in-nodes and out-nodes. Our intention was to characterize the complexity of the network estimating the power of the associated distributions. Although several of the estimations were not significant, the log-likelihood in all cases bent over a power law distribution, giving evidence of the complex nature of the network. Most importantly, it was found that the power of the distribution has higher estimated values during March 2020, which provides further support to our hypothesis: the structure of the induced cryptocurrency network by mTE changes during times of turbulence in the sense of higher clustering coefficient and complexity.
Future work involves the use of an extensive data set to include the market capitalization, financial indices, sentiment indicators of textual data, as well as volume in a cleaver way in order to verify if the same phenomena are presented in the induced graphs by a more complete data set. The last because what is found here volume does not play a role as relevant as the price is to early-warning signals for future markets turbulence. A forthcoming work is analyzing the same data set from data mining techniques as is the point of view of association rules and the apriori algorithm, where preliminary results already show a rich network structure.
Finally, it is important to clarify that despite the statistical results found here in relation to the power fitness of degree distributions, no economical theory behind power laws has been properly developed yet. At most, we can say the power law degree distributions as well as the clustering coefficient of mTE networks may serve an early warning signal of an increasing systematic risk of the cryptocurrency markets in times of crash. The econophysics community has been put a lot of effort to unravel stylized facts of the network structure of financial markets in general, but it is still necessary to build epistemologically the blocks of the theory jointly with the financial economists to have a common playground to discuss and construct new ideas. As stated in [
61]: “
the time is ripe for economists to use those power laws to investigate old and new regularities with renewed models and data”. In this sense, this work only tries to contribute with new evidence in the networks induced by mTE, hoping to soon have an interpretable theory in the same sense as phase transitions, critical points, and scale invariance of turbulent dynamics are in physical statistics.






{kind=link}
{kind=link}
{kind=link}
{kind=link}