Abstract
The design of transportation networks is generally performed on the basis of the division of a metropolitan region into communities. With the combination of the scale, population density, and travel characteristics of each community, the transportation routes and stations can be more precisely determined to meet the travel demand of residents within each of the communities as well as the transportation links among communities. To accurately divide urban communities, the original word vector sampling method is improved on the classic Deepwalk model, proposing a Random Walk (RW) algorithm in which the sampling is modified with the generalized travel cost and improved logit model. Urban spatial community detection is realized with the K-means algorithm, building the F-Deepwalk model. Using the basic road network as an example, the experimental results show that the Deepwalk model, which considers the generalized travel cost of residents, has a higher profile coefficient, and the performance of the model improves with the reduction of random walk length. At the same time, taking the Shijiazhuang urban rail transit network as an example, the accuracy of the model is further verified.
1. Introduction
In order to achieve a specific level of accessibility and coverage, the urban transportation network planning method typically starts with the central area of the city, chooses the transportation hub as the passenger flow distribution point, and connects the chosen passenger flow distribution point with various levels of lines. However, it is challenging for the transportation network created by the city as a whole to meet the travel demand of inhabitants in different parts of the city at the same time due to the disparities in the scale, population density, and travel characteristics of distinct urban communities. In the event that an urban community is divided, the planning of the transportation network within the community comes first, followed by the consideration of the network connections between the various areas. In addition to fulfilling inhabitants’ travel demands inside various communities, the created network can further enhance the transportation links between towns.
We concentrate on urban spatial community detection techniques in this setting. In the realm of complex networks, community detection algorithms were used in earlier studies on the subjective and qualitative spatial community detection of cities [1,2], including not only the traditional urban community detection of land classification [3] but also traditional networks, virtual space transaction networks such as the Bitcoin network [4], and social networks [5]. At present, novel community detection technologies, such as network refining [6], outlier detection [7], and comparative learning [8], may be applied to urban spatial division in the future, and are worthy of further exploration by scholars.
Overall, there are four primary types of community detection algorithms for complex networks: (1) labeled community detection models that combine nodes and edges; (2) edge-based community detection models; (3) overlapping community detection algorithms; and (4) node-based community detection models. Unfortunately, without taking into account the real circumstances of the city’s population distribution, traffic diversion, etc., these complex network-based community detection algorithms merely abstract the urban space as a complex network, either focusing on the weight of a single node in urban space [9,10] and taking its membership degree as the primary consideration to carry out multi-layer community detection [11,12], or considering the spatial structure of nodes [13,14] in community division, ignoring the travel characteristics of urban residents themselves.
The use of the Word2Vec model by Yao et al. [15] and others to explore the spatial relationship of points of interest (POI) in land use classification is growing as a result of the emergence of geographic data and social big data. Zhang et al. [16] combine high-resolution remote sensing image data and POI data to propose a new urban land use model based on the mutual correlation function (CC-FLU), which solves the potential shortcomings of models using single-source data and fusion methods. Li [17] et al. determined Zhengzhou’s functional zoning by screening the microblog check-in data and processing it using a multi-density spatial clustering technique. In response to arguments made by Niu [18] et al. that the Word2Vec model was unable to adequately capture the spatial heterogeneity among urban communities, the Word2Vec model and the Doc2Vec model were fused; Node2Vec [19] optimized the sequence extraction strategy for the random walking on Deepwalk architecture and various parameter selections are applicable to various types of network data. Yan [20] et al. contend that the urban spatial structure is too complex to be solely represented by natural language sequences. Consequently, they incorporate the spatial distance between points of interest (POIs) into the Word2Vec model and present the Place2Vec model. Other researchers, relying on deep learning algorithms [21,22,23], extract word vector features from various spatial points within the city to achieve urban spatial community detection.
In order to make the community detection model more consistent with the urban spatial structure, some scholars began to study multi-layer transportation networks. A multi-layer traffic network structure can capture the complex interaction between different traffic modes. In the public transportation system, there are a variety of transportation modes (such as buses, subways, taxis, shared bicycles, etc.), each of which has its own unique operating characteristics and coverage. [24,25,26] The multi-layer network model can treat these different modes of transportation as different network layers, so as to more fully reflect the complexity and diversity of the entire transportation system [27,28]. Luo [29] et al. capture latent knowledge from both network topological structure and node attributes through a two-layer representation method. A weighted co-association matrix-based fusion algorithm (WCMFA) is proposed to detect the inherent community structure in attributed networks using multi-layer fusion strategies. Yildirimoglu [30] et al. introduce a novel method to identify active areas or community structures in city networks using multi-layer graphs. Their method processes trip data through Voronoi segmentation, applies community detection per layer, and tests an algorithm to reveal a unified multi-layer community structure. However, in community detection, there are few applications of multi-layer traffic networks, mostly social networks and synthetic networks [31,32,33], which may represent a new research field in the future.
However, these studies have three major shortcomings: (1) The travel regularity and number of residents are not fully integrated into the community detection model. (2) The spatial structure characteristics of urban traffic networks are not fully integrated into the community detection model. (3) In the Deepwalk study, because the RW algorithm is biased towards large-degree nodes in sampling, the samples will not accurately reflect the network topology information, and the random walking sequences improved by Node2Vec do not represent the actual travel routes of residents.
A Deepwalk model is suggested based on the generalized trip costs of the residents in order to close the research gap. Our research is divided into three parts:
- (1)
- The generalized travel cost of residents is incorporated into the RW model.
- (2)
- The improved logit model is used to distribute passenger flow, and the word vector sequence is obtained.
- (3)
- The final sequence of word vectors is input into the Word2Vec model to learn the node embedding, which realizes the community detection of urban space.
The rest of the paper is organized as follows: Section 2 develops a Deepwalk model based on residents’ generalized travel costs; Section 3 contains the model verification; Section 4 presents a case study; and Section 5 presents the conclusions, as well as some suggestions for future research directions.
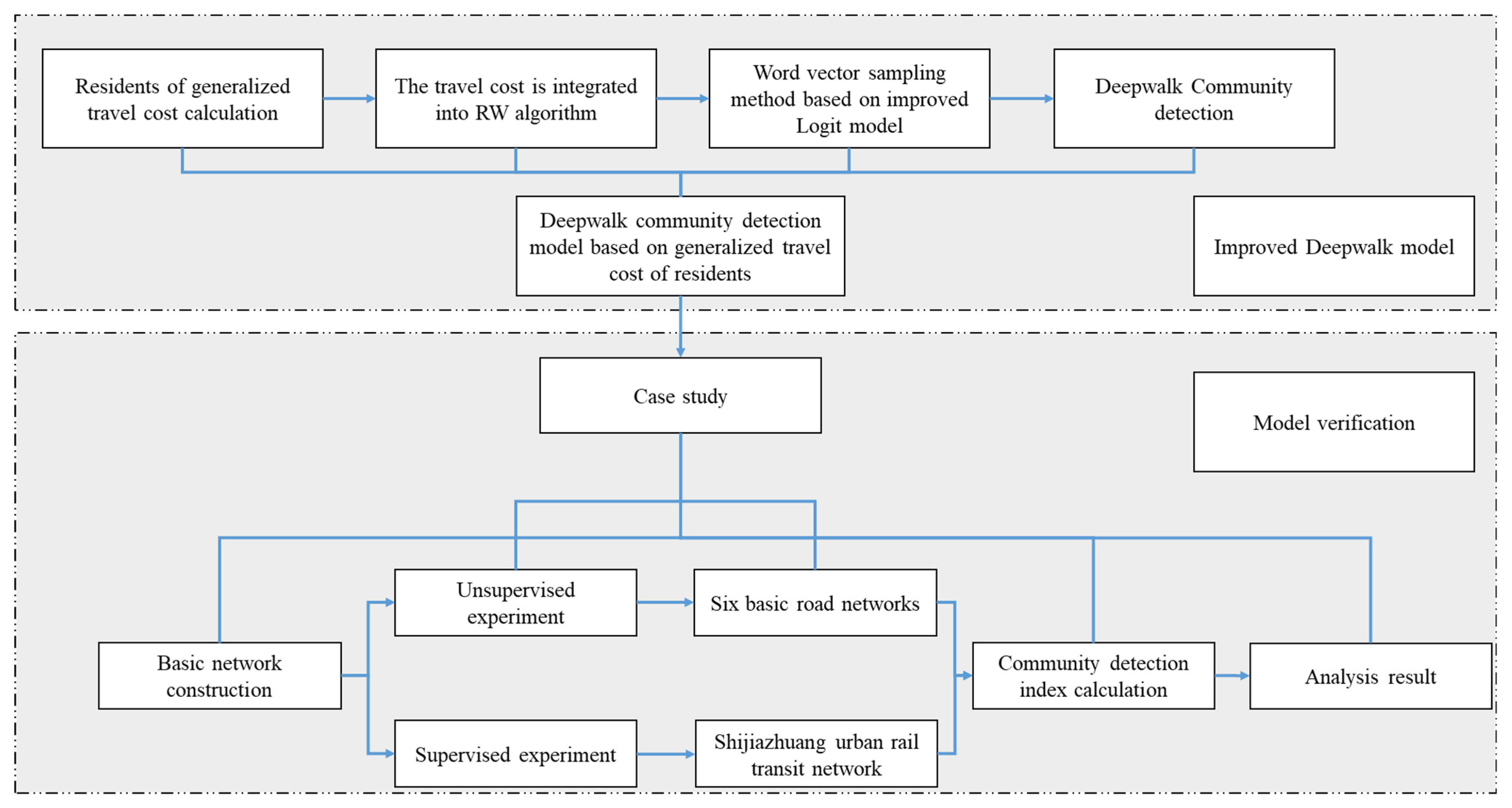
Figure 1 describes the logical framework of the research method in this paper in detail, so as to facilitate readers to gradually understand how our research progresses from theoretical conception to practical verification.
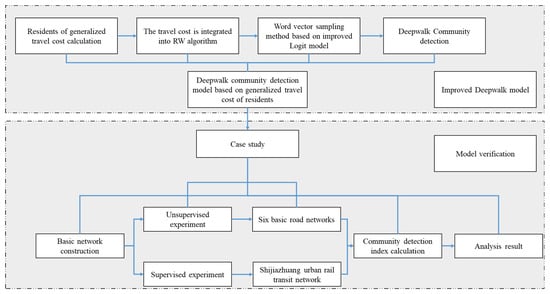
Figure 1.
Flowchart of the paper.
2. Methods
We are dedicated to building a complete model for community detection in urban space. The Word2Vec model is trained on the incoming sequences by the original Deepwalk model, which uses the RW algorithm to pass the sequence generated by random walking of each node in the network as a natural language string. The Word2Vec model then returns a low-dimensional parameter vector for representation. Consequently, in order for Deepwalk to yield a useful result, the random walk’s length, the sequence it generates, and the number of random walks are all essential.
To this end, we propose a Deepwalk model based on residents’ generalized travel costs, which is divided into three parts: (1) constructing the topology of the urban spatial road network; (2) based on residents’ generalized travel costs, amending the RW algorithm and assigning the passenger flow according to the improved logit model, determining the final sequence of word vectors; and (3) importing the sequence of word vectors into the Word2Vec model to learn node embeddings, use PCA and t-SNE algorithms for dimensionality reduction, and finally divide the community structure of the network by clustering with K-means algorithm.
2.1. Urban Transportation Network
Let be an urban transportation network, where denotes the set of large passenger distribution points in G, and denotes the set of roads in the network, , noting that is the corresponding adjacency matrix of G. If there exists a road that can go straight through between the passenger distribution points and , then , otherwise .
2.2. Broad Travel Cost for Residents
When choosing urban public transportation travel, the number of transfers and the degree of resident congestion are key factors affecting residents’ willingness to travel. The more transfers required, the longer the travel time and the more congested the flow of residents, resulting in a lower likelihood of residents choosing that travel path [34]. The time spent by residents on public transportation is divided into in-vehicle travel time and out-of-vehicle waiting time:
where is the in-vehicle time; is the stopping time at the intermediate station of the ith non-interchange station in the path; is the total number of stations in the path; is the total number of interchanges in the path; and is the travel time in the interval.
The transfer time (waiting time outside the car) for residents is as follows:
where is the transfer time, is the travel time of the kth transfer station in the path; is the departure interval. and are the passenger’s transfer sensitivity and correction coefficient of the number of interchanges. The values of parameters are explained in detail in a previous study [34]. Dr. Chai conducted relevant simulation experiments and reached relevant conclusions: a path with more transfer times tends to have more average travel time, and the greater the transfer sensitivity, the more obvious the phenomenon. When , the convenience and directness of passenger travel are relatively more reasonable
The fare calculation method of urban rail transit is divided into two cases, sectional fare and one-ticket-two-system, and the specific fare is denoted as without considering the special card and special charge cases. In order to unify the fare into the time cost , a time-cost conversion factor is introduced .
The expression for the time-cost conversion factor A is:
where is the number of people employed in the case city; is the number of hours worked in a year; and GDP is the annual national GDP of the case city.
Excessive passenger flow and interval fullness at a station will affect residents’ travel and lead to an increase in travel costs. We mimic the BPR [35] function to define the flow delay coefficient(FDC) of station i based on the intensity of passenger flow at the next stop of residents, which reflects the impact of passenger congestion on residents’ entry and transfer.
where in BPR, is the time it takes to actually cross the section, is the road-free travel time, Q is the volume of traffic passing through the section at that time, C is the actual traffic capacity of the road section, and are undetermined parameters of the model, and the recommended values are 0.15 and 4. In FDC, is the intensity of passenger flow; and are the tuning coefficients; in summary, the generalized travel cost of residents is:
where is the resident’s generalized travel cost, is the departure interval of the train when the resident is at the starting point, and its value is equal to by default, and the resident’s generalized travel cost is an important reference for the subsequent determination of the stochastic wandering path.
2.3. Random Walk Path Assignment Based on Residents’ Travel Costs
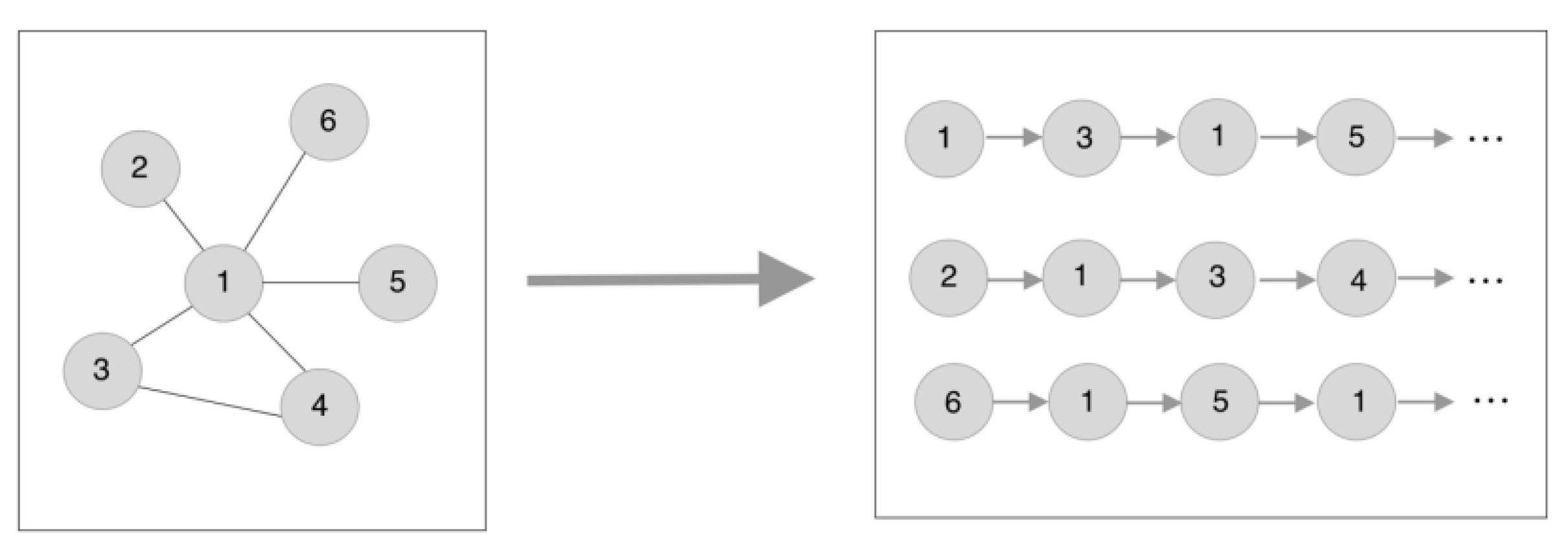
The original random walk algorithm picks network nodes by continuously walking around the network topology with the connecting edges of the nodes [36,37]. Its inputs and outputs are shown in Figure 2.
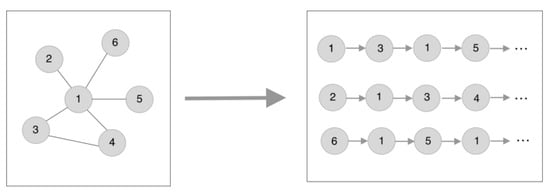
Figure 2.
Random walk schematic.
The number of residents at the node is the number of random walks in the sequence based on the generalized travel costs. Using the improved logit model for passenger flow allocation, the residents will be divided into different paths in accordance with different probabilities. The logit method commonly uses impedance as a constant multi-path passenger flow allocation method, the premise of which is the assumption that each resident is self-perceived to determine the impedance of the road section, and the perceptual impedance is expressed as follows:
where is the perceived impedance of path r between nodes i, j of the road network, is the actual traffic impedance, and is the random error term. The actual traffic impedance can be expressed by the generalized travel cost of residents:
According to the definition of utility, the greater the utility, the greater the probability that the resident will choose that path:
Assuming that the random error terms are independent of each other and follow a Gumbel distribution [38,39], the probability that a resident chooses path r is:
According to the “multiplication” invariance of the logit model, the probability that a resident chooses the path can be expressed as follows:
where is the average of the generalized travel costs of all random wandering generated sequences between nodes s and e; m is the number of different random wandering sequences generated at node j.
Taking node j as an example, the specific steps of the algorithm are as follows:
Step 1: Starting from node j, generate a randomized wandering sequence of length walk_length and number_walks, which will be denoted as .
Step 2: Calculate the generalized travel cost for each path, denoted as , according to Equation (6).
Step 3: Based on the improved logit model, Equation (11) is used to determine the probability of residents choosing each path, denoted as .
Step 4: If the number of residents at node j is n, then the number of paths A is:
Then the final sequence generated at node j is . l is the number of road network nodes, and the randomized wandering sequence of the road network G is .
2.4. Urban Community Detection Model Based on Improved RW
We use random wandering sequences based on residents’ generalized travel costs to represent the word vectors at the nodes, incorporate the Word2Vec model in the field of NLP for learning, sample the data, use PCA and t-SNE algorithms to reduce the dimensionality, and ultimately divide the community structure of the network by clustering with the K-means algorithm.
2.4.1. Word2Vec Model
There are two main Word2Vec models: the CBOW model and the Skip-Gram model. The Skip-Gram model is utilized to process the samples and update the feature vectors of the nodes to predict their context [40,41].
Each word in the Skip-Gram model is associated with two learnable D-dimensional vectors (i.e., word embeddings), i.e., denoted when it is the center word and when it is a context word. Given the center word , the probability of correctly predicting the context type is computed by the Softmax function:
where represents the total number of words in the predicted library, and represent the word vectors for the input and output of the word . The goal of the Skip-Gram model is to minimize the cross-loss entropy between the predicted probability and the true probability:
where denotes the number of context words corresponding to the size of the set sliding window, and denotes the number of words in the training set. In order to speed up the training time, we adopt the negative sampling method [42], and the corresponding objective function is as follows:
where denotes the number of negative examples and denotes the negative example word. Its corresponding probability formula is:
where denotes the probability that word is selected as a negative example word, represents the number of occurrences of word in the corpus, and denotes the total number of words in the corpus.
2.4.2. Community Detection Model
This model takes the word vectors processed by the Word2Vec model and reduces the high dimensional data to low dimensions by the PCA algorithm, and then reduces the target data to two dimensions by using the t-SNE algorithm [43,44]. The t-SNE algorithm can map each data point into two-dimensional space, which performs worse than the PCA algorithm when in high dimensions but outperforms the PCA algorithm for low dimensional space, such as three dimensions and two dimensions. The similarity of two original data points in high dimensional space is defined as follows:
where is used to measure the degree of proximity of and , can be regarded as a Gaussian distribution with variance around . P, j is the symmetric similarity of the two data points, and the similarity of the mapped points in the 3D space is defined as follows:
The purpose of the t-SNE algorithm is to minimize the Kullback–Leibler scatter between two similarity matrices computed in different spaces:
After dimensionality reduction using the t-SNE algorithm, clustering is performed using the K-Means algorithm [45], which aims to minimize the squared error E:
where is the mean vector of cluster , also known as the center of mass, defined as:
2.4.3. Indicators for Model Evaluation
After outputting the clustering results, different metrics are used for judging. For unsupervised experiments, silhouette coefficients are used to verify the accuracy; for supervised experiments, module degree values, silhouette coefficients, Davies–Bouldin coefficients, ARI, AMI, and Harmonic mean values are used to verify the accuracy.
3. Model Verification
The default parameters of the original Deepwalk model are used for node embedding of the road network dataset [20], i.e., number_walks = 20, vector_size = 256, walk_length = 8, alpha = 0.03, min_alpha = 0.0007, window_size = 4. For the improved Deepwalk model, number_walks is the number of residents at the node, and in the stochastic wandering sequence based on the generalized travel cost. Since the initialized cluster centers of the K-means algorithm will have a certain impact on the results, in the experiments, we call the K-means algorithm in ‘sklearn’ and perform the K-means algorithm 50 times for the dataset of each network K-means algorithm and then take the maximum value of the 50 measurements, and the maximum value is taken as the simulation result.
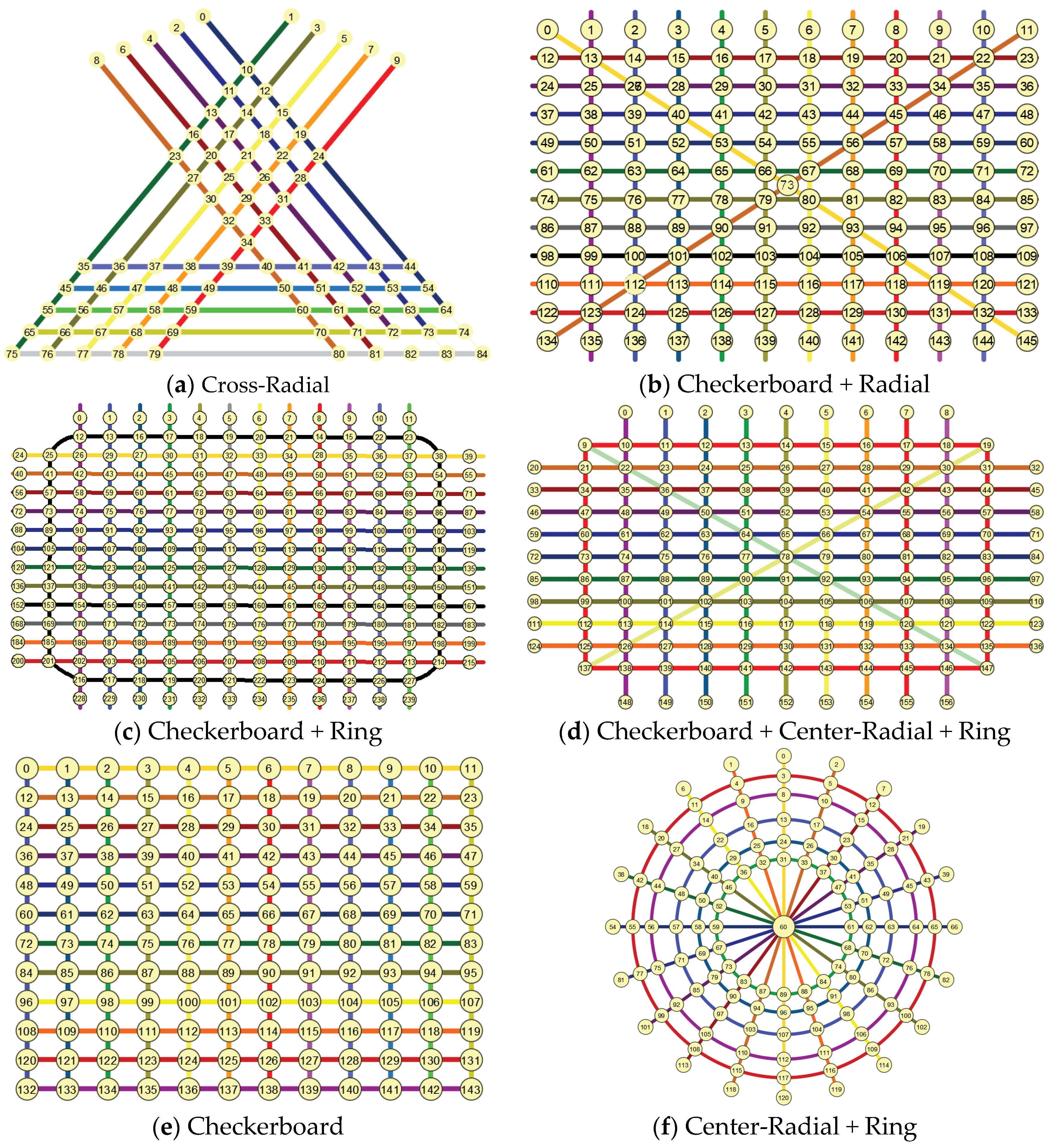
Although the urban road network structure is inextricably linked to the structural characteristics of the city itself, its form generally consists of one or more combinations of basic road network forms. Therefore, in order to take into account a variety of road network forms, the basic road network forms calculated in this section include Cross-Radial, Checkerboard + Radial, Checkerboard + Ring, Checkerboard + Center-Radial + Ring, Checkerboard and Center-Radial + Ring, as shown in Figure 3.
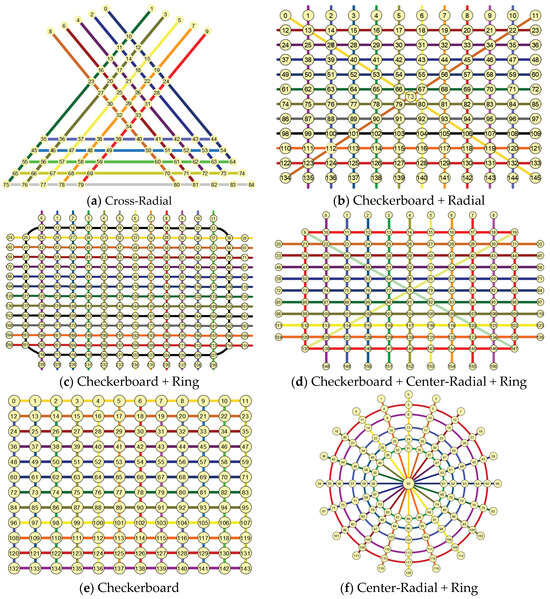
Figure 3.
Basic road network pattern.
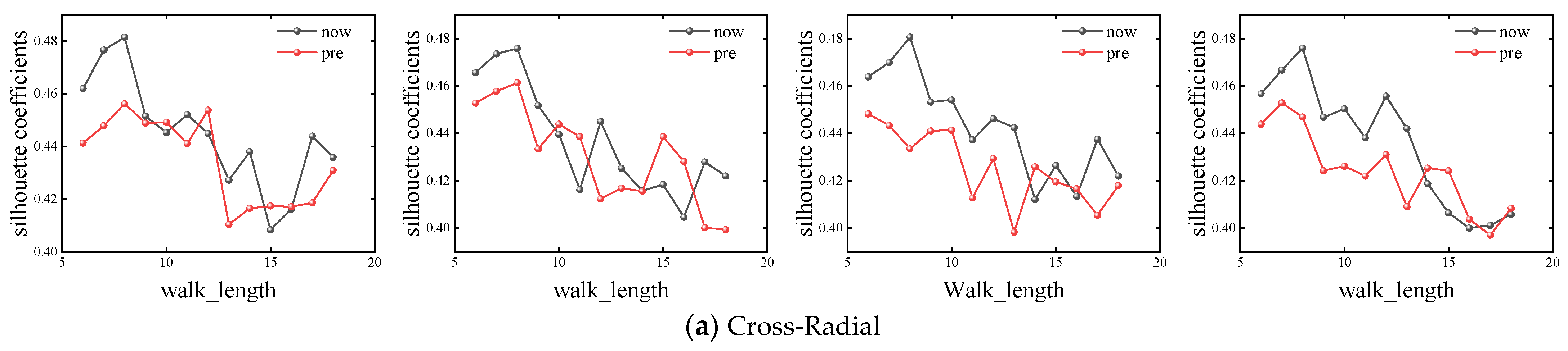
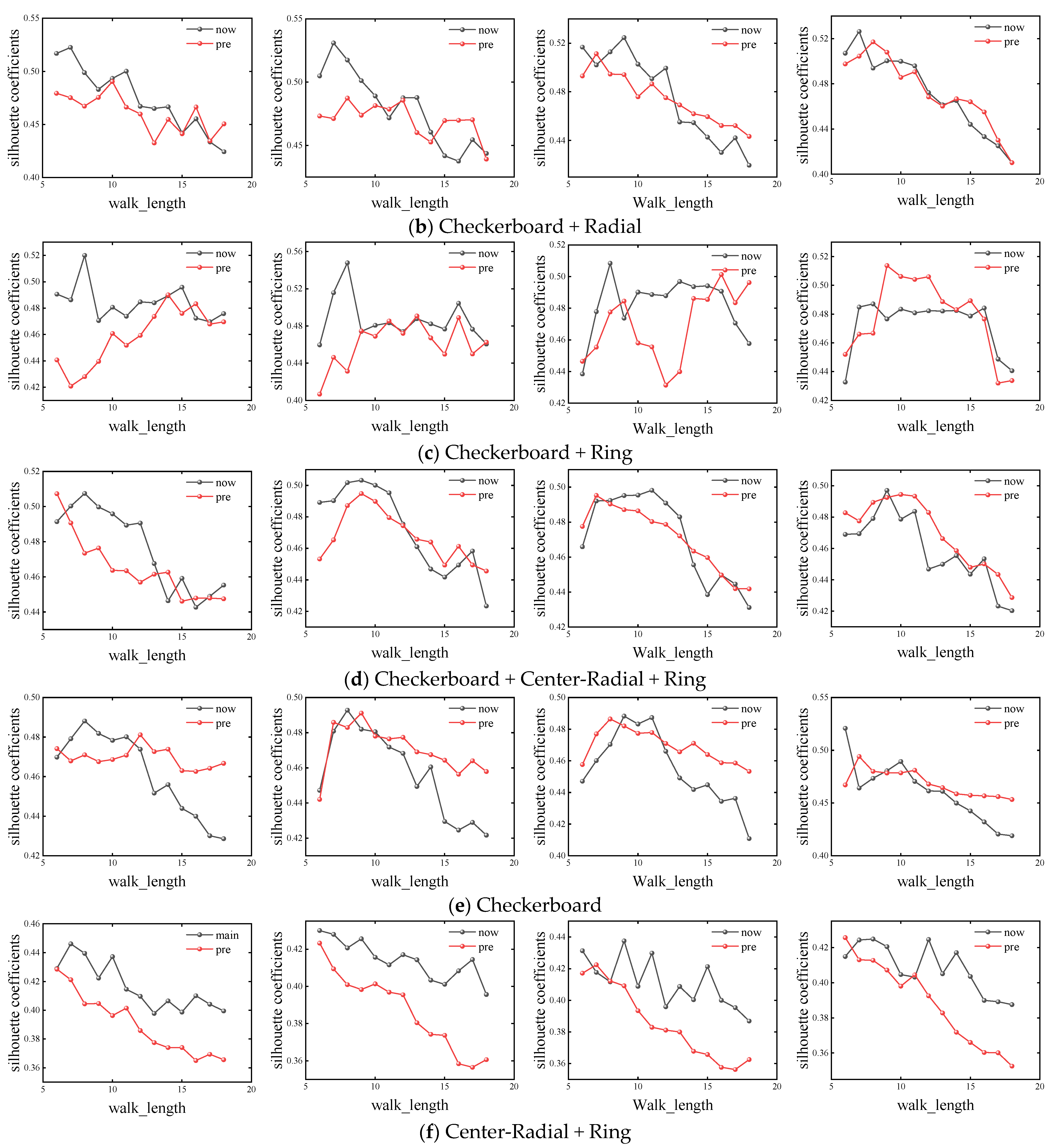
In order to ensure the accuracy of the experiment, this paper fixed the number of random walks as number_walks = 10, 15, 20 and 25, and calculated the simulation results of different basic road networks with walk_length from 6 to 18, respectively. The corresponding silhouette coefficients of different road network shapes under different parameters are shown in Figure 4.
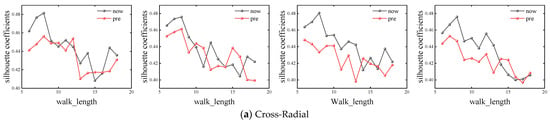
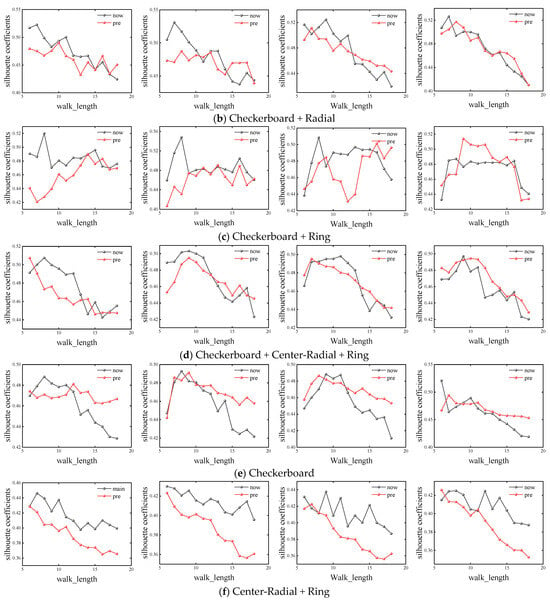
Figure 4.
Calculation results of base network silhouette coefficients with different parameters.
It can be seen that when number_walks is smaller than 20, the performance of the F-Deepwalk model is superior to that of the Deepwalk model when walk_length is smaller, except for the checkerboard road network. When walk_length ranges from 8 to 12, the F-Deepwalk model performs better, and its optimal value generally appears when walk_length ranges from 8 to 9. With the continuous increase of walk_length, the contour coefficients of the Checkerboard + Radiate network and Checkerboard network under the Deepwalk model will be reversed, but the maximum value still appears in the F-Deepwalk model. When number_walks is equal to 25, the contour coefficients of the Chessboard + Ring network and Chessboard network reach the maximum value in the Deepwalk model, and the overall performance is better than that of the F-Deepwalk model, but the overall optimal value is still smaller than that of F-Deepwalk model when number_walks is less than 20. Taking the Chessboard + Ring network as an example, the F-Deepwalk model obtains the maximum value when number_walks = 15, walk_length = 8, and its value is 0.54795. The Deepwalk model obtains the maximum value when number_walks = 25, walk_length = 9. Its value is 0.51377, an increase of 6.65%.
In order to more concretely determine the advantages of the F-Deepwalk model, we present the optimal community division results of different models, as shown in Figure 5.
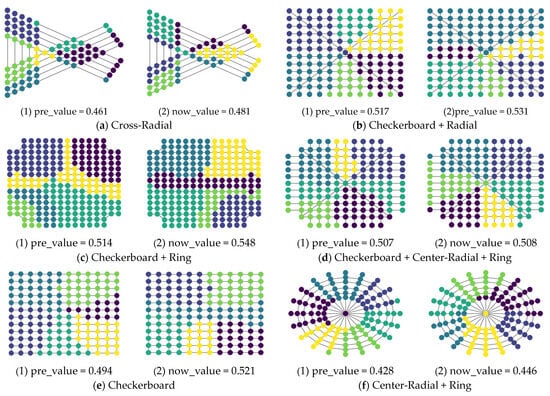
Figure 5.
Optimal result division diagram.
It can be seen that the F-Deepwalk model has no obvious enhancement effect in Checkerboard + Center-Radial + Ring, but has obvious enhancements in other wire network types.
4. Case Study
In order to further illustrate the accuracy of the model, we take the Shijiazhuang urban rail transit network as an example, conduct simulation experiments on it, and compare it with the actual urban spatial situation. With the acceleration of urbanization in recent years, Shijiazhuang, the capital city of Hebei Province, has exhibited growing traffic demand. In order to relieve urban traffic pressure and improve citizens’ travel efficiency, Shijiazhuang actively builds and constantly improves its rail transit network. Shijiazhuang rail transit network, with its efficient, convenient, and environmental protection characteristics, has become an important link to connect the city’s various regions. Through scientific and reasonable route planning, the network can effectively cover the main functional areas, commercial areas, residential areas, and transportation hubs of the city, and ensure the on-time rate and operation efficiency of the trains. Passengers can rely on accurate train schedules to arrange travel, reduce waiting time, and greatly facilitate the daily travel of citizens.
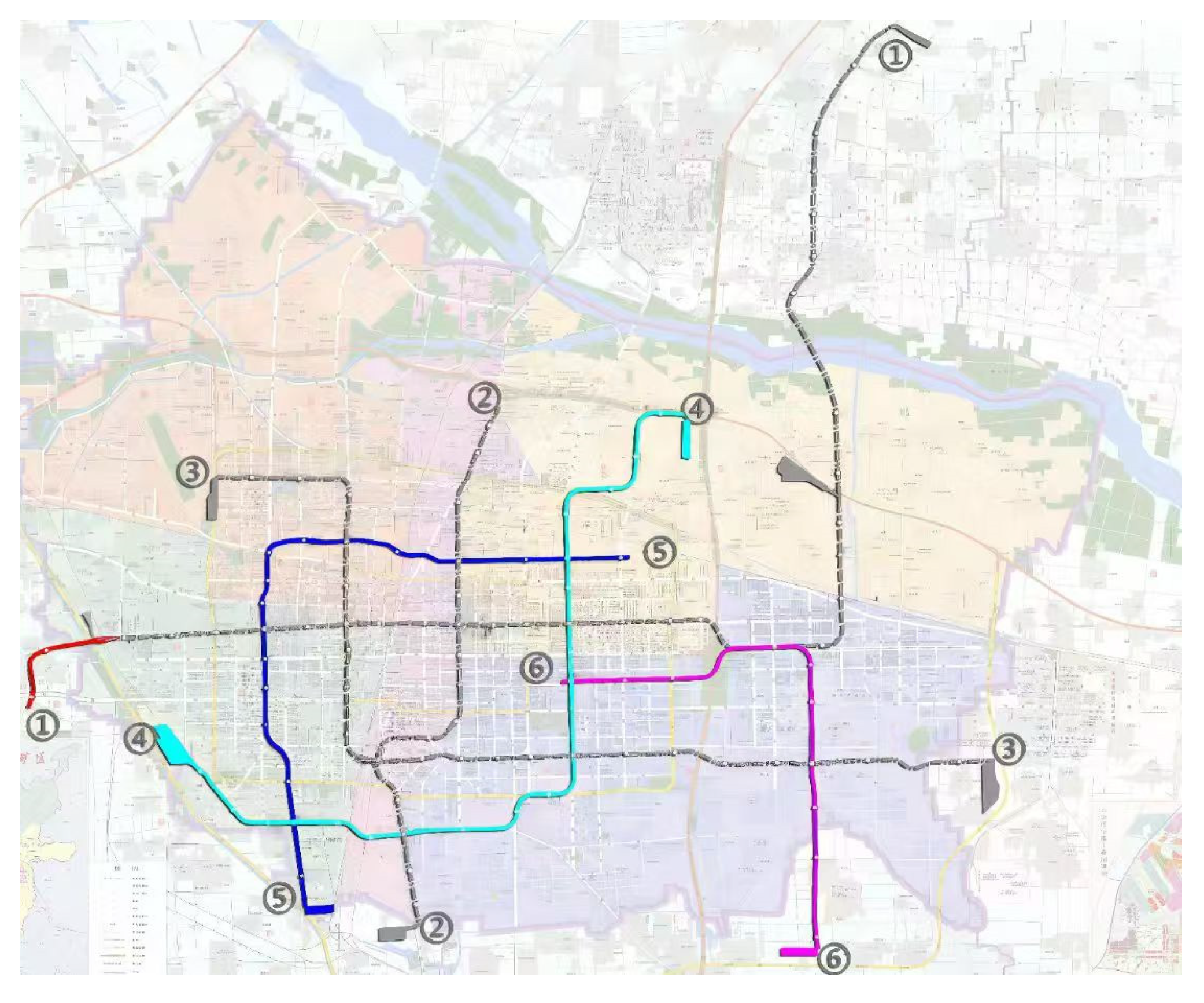
Figure 6 shows the urban space community detection situation and rail transit network topology of Shijiazhuang city, respectively, with different colors representing the different subdivisions in which the stations are located.
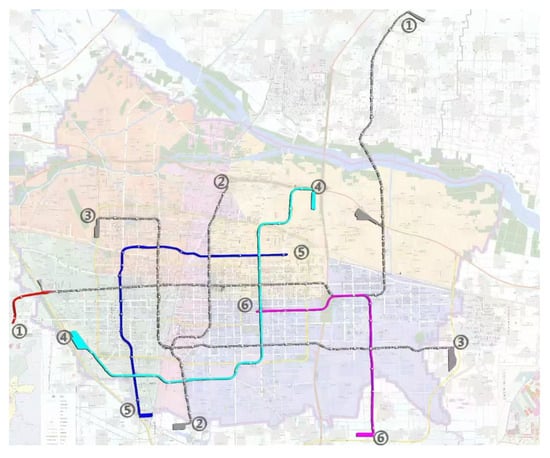
Figure 6.
Shijiazhuang urban space community (data source: https://sjz.bendibao.com/traffic/2019218/48216.shtm (accessed on Day 14 Month 7 Year 2024)).
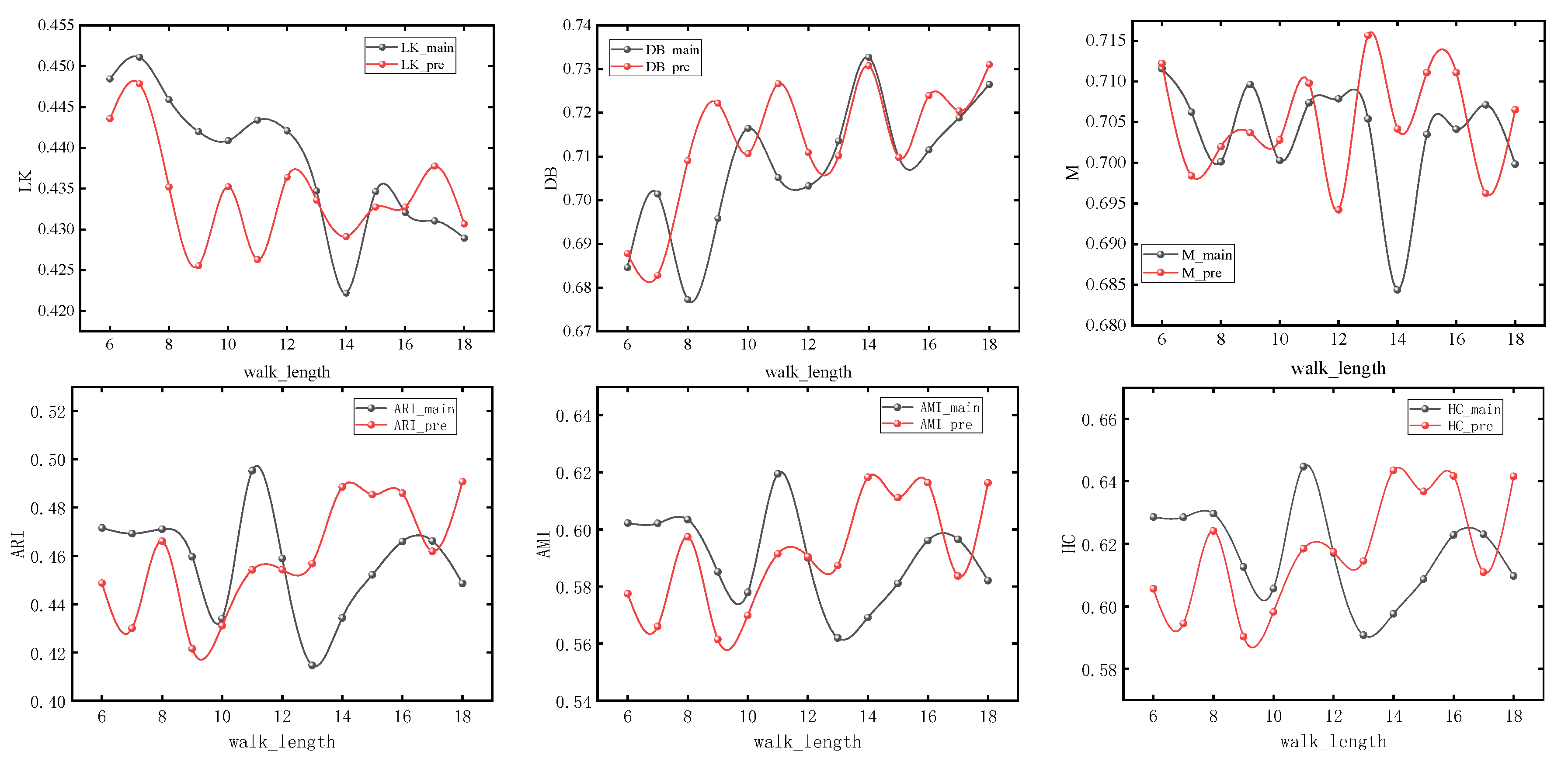
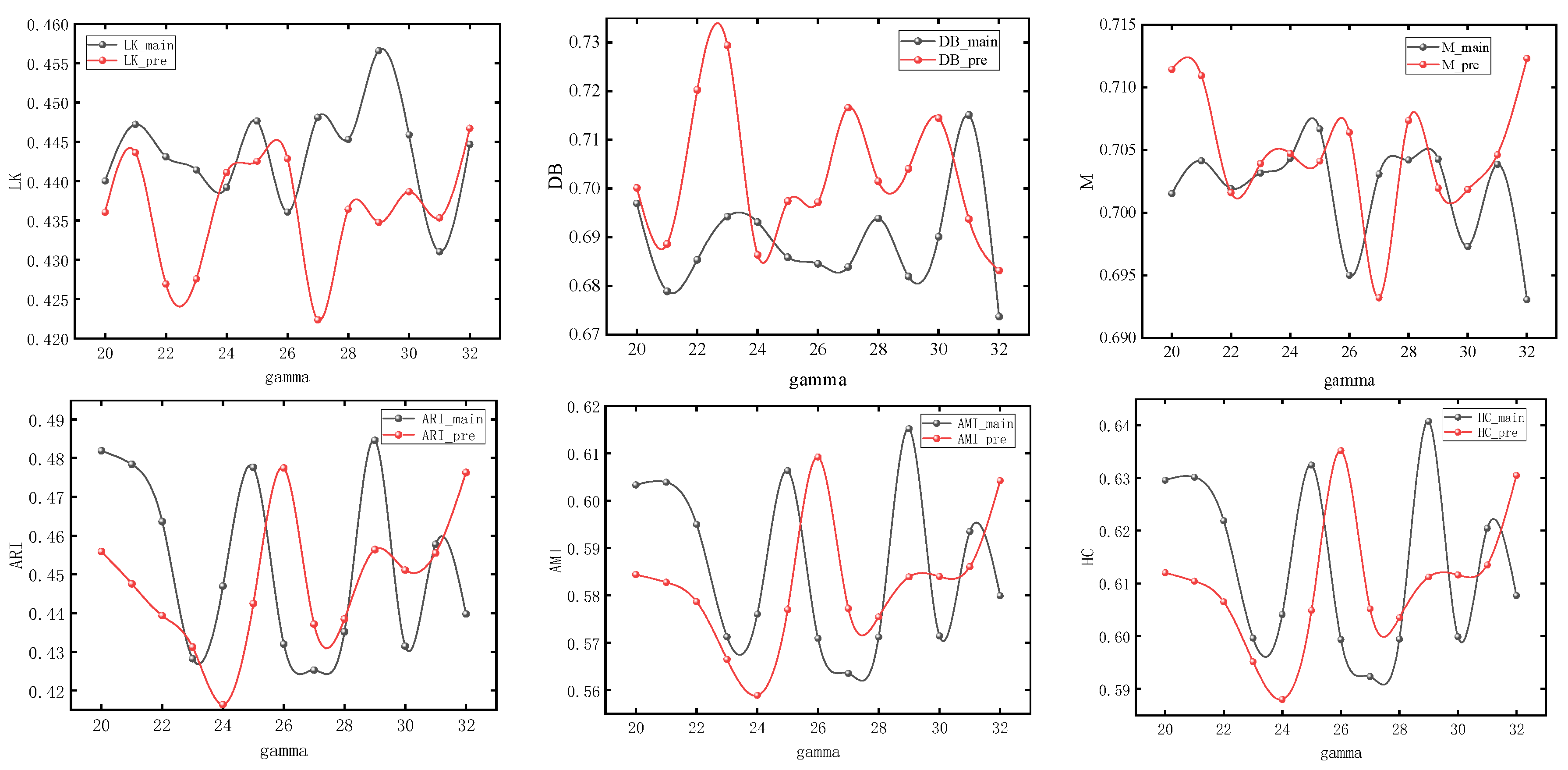
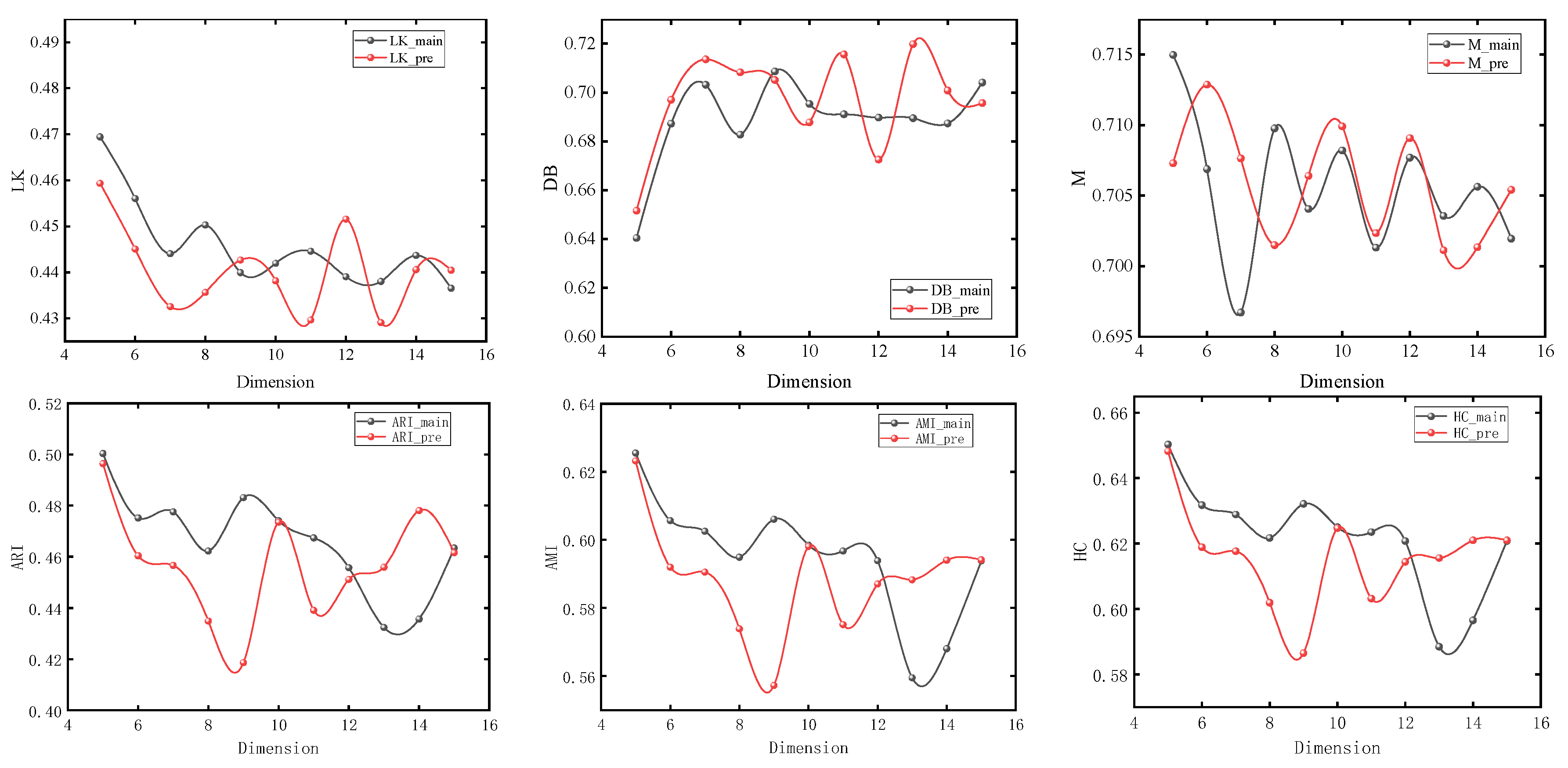
The nodes with different colors in the figure correspond to the urban spatial communities where the nodes are located in the network. It can be seen from Section 3 that the model usually obtains the maximum value when number_walks = 20. In order to simplify the experiment, we first set number_walks = 20, then adjust walk_length, then fix walk_length and readjust number_walks. In order to ensure the accuracy of the experiment, we also adjusted the dimensionality of PCA reduction. The modularity values (M), silhouette coefficients (LK), Davies–Bouldin coefficients (DB), ARI, AMI, and Harmonic mean values for different parameters are shown in Figure 7, Figure 8 and Figure 9.
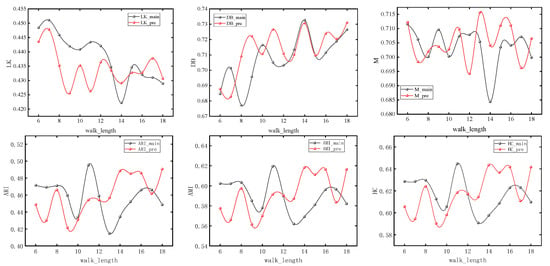
Figure 7.
Experimental results under different lengths of random walks.
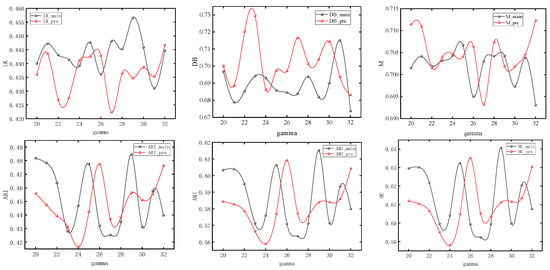
Figure 8.
Experimental results under different numbers of random walks.
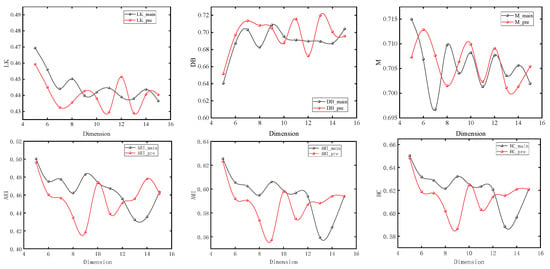
Figure 9.
Experimental results under different dimensionality reduction levels.
It can be seen that with the change of parameters, the overall trend of silhouette coefficients and Davies–Bouldin coefficients of the improved Deepwalk model are better than the original model, and the modularity values are not much different between the two. In addition, the overall trend of the improved model is better than the original model when walk_length, gamma and dimensionality are small, but the performance of the original model is gradually reversed as the parameter values continue to increase. However, the maximum values of ARI, AMI, and HC all appear in the improved model, with maximum values of 0.51283, 0.63679, and 0.66077, which are improved by 4.1%, 3.4%, and 2.1%, respectively, compared with the original model.
5. Conclusions and Future Work
5.1. Conclusions
We have developed a Deepwalk model based on residents’ generalized travel costs to ensure that the number of random walks and the length of random walks at each node are realistic, and the contributions of this model are as follows:
(1) Based on the original random walk algorithm, the generalized travel costs of residents and the improved logit model are integrated to determine the random walk path that is more in line with the actual demand. At the same time, the PCA and t-SNE algorithms can not only process high-dimensional data efficiently but also find the cluster structure and similarity in the data.
(2) The model is applied to simulate the basic road network configuration. The results show that the F-Deepwalk model is more accurate when walk_length is low, and the results are better than the Deepwalk model in any state.
(3) In order to further verify the accuracy of the model, the Shijiazhuang urban rail transit network is used for experiments. The results show that the model has high accuracy and is helpful in improving the accuracy of urban community division. This paper provides a reference for subsequent network planning.
5.2. Policy Suggestion
This model provides an innovative and refined new perspective for urban planning. By using this model to accurately divide urban communities, we can understand the characteristics and needs of different communities more scientifically, so as to guide relevant departments to develop more practical management measures and service programs.
For the transportation authority, after clarifying the boundaries and characteristics of each community, the transportation authority can formulate differentiated traffic flow restrictions according to the specific conditions of different communities. For example, stricter parking management and traffic flow diversion measures should be implemented around communities with dense residents and heavy traffic pressure. In communities with frequent commercial activities and large passenger flow, it may be necessary to optimize road layouts and increase public transportation facilities to alleviate traffic congestion. For the urban planning bureau, based on the results of community division, public resources can be more accurately allocated, such as parks, green spaces, schools, hospitals, etc. By knowing the demographics, age distribution, and income levels of each community, the planning bureau can ensure that the layout of public facilities meets the needs of residents and avoids wasting resources.
5.3. Limitations and Future Work
Due to the sampling uncertainty of the random walk algorithm, this paper adopts the method of averaging by multiple simulations to reduce the error, but this still has the problem of unstable experimental results; meanwhile, for cities, it is slightly one-sided to consider only the number of inhabitants, the travel paths of inhabitants and the structure of the urban road network. In the future, on the one hand, we will study a new sampling model to ensure sampling accuracy; on the other hand, we will consider incorporating land value and policy documents of different cities into the sampling sequence to ensure that the results of neighborhood classification are more realistic.
Author Contributions
Conceptualization, J.G. and Q.L; Methodology, J.G. and Q.L; Software, J.G.; Investigation, J.Z. and Q.L; Writing—original draft, J.G.; Writing—review & editing, Q.L.; Visualization, J.Z.; Supervision, Q.L. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Data Availability Statement
The raw data supporting the conclusions of this article will be made available by the authors on request.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Yang, X.; Bo, S.; Zhang, Z. Classifying Urban Functional Zones Based on Modeling POIs by Deepwalk. Sustainability 2023, 15, 7995. [Google Scholar] [CrossRef]
- Liu, Y.; Fan, Y.; Zeng, A. Higher-order interactions disturb community detection in complex networks. Phys. Lett. A 2024, 494, 129288. [Google Scholar] [CrossRef]
- Andrade, R.; Alves, A.; Bento, C. POI Mining for Land Use Classification: A Case Study. ISPRS Int. J. Geo-Inf. 2020, 9, 493. [Google Scholar] [CrossRef]
- Kamuhanda, D.; Cui, M.; Tessone, C.J. Illegal Community Detection in Bitcoin Transaction Networks. Entropy 2023, 25, 1069. [Google Scholar] [CrossRef]
- Zheng, X.; Xing, D.; Chen, K.; Zhao, J.; Lu, Y. Multiscale Community Detection Using a Label Propagation-Based Clustering Method in Complex Networks. IEEE Access 2023, 11, 80003–80019. [Google Scholar] [CrossRef]
- Yu, J.; Leng, J.; Sun, D.; Wu, L.-Y. Network refinement: Denoising complex networks for better community detection. Phys. A Stat. Mech. Appl. 2023, 617, 128681. [Google Scholar] [CrossRef]
- Sachpenderis, N.; Koloniari, G. Outlier Detection and Prediction in Evolving Communities. Appl. Sci. 2024, 14, 2356. [Google Scholar] [CrossRef]
- Huang, Z.; Xu, W.; Zhuo, X. Community-CL: An Enhanced Community Detection Algorithm Based on Contrastive Learning. Entropy 2023, 25, 864. [Google Scholar] [CrossRef]
- Maji, G.; Mandal, S.; Sen, S. Identification of city hotspots by analyzing telecom call detail records using complex network modeling. Expert Syst. Appl. 2023, 215, 119298. [Google Scholar] [CrossRef]
- Xu, Y.; Ren, T.; Sun, S. Community Detection Based on Node Influence and Similarity of Nodes. Mathematics 2022, 10, 970. [Google Scholar] [CrossRef]
- Gao, R.; Li, S.; Shi, X.; Liang, Y.; Xu, D. Overlapping Community Detection Based on Membership Degree Propagation. Entropy 2021, 23, 15. [Google Scholar] [CrossRef] [PubMed]
- Gao, K.; Ren, X.; Zhou, L.; Zhu, J. Automatic Detection of Multilevel Communities: Scalable, Selective and Resolution-Limit-Free. Appl. Sci. 2023, 13, 1774. [Google Scholar] [CrossRef]
- Hu, Y.F.; Han, Y.Q. Identification of Urban Functional Areas Based on POI Data: A Case Study of the Guangzhou Economic and Technological Development Zone. Sustainability 2019, 11, 1385. [Google Scholar] [CrossRef]
- Chen, Y.; Qian, H.Z.; Wang, X.; Wang, D.; Han, L.J. A GloVe Model for Urban Functional Area Identification Considering Nonlinear Spatial Relationships between Points of Interest. ISPRS Int. J. Geo-Inf. 2022, 11, 498. [Google Scholar] [CrossRef]
- Yao, Y.; Li, X.; Liu, X.; Liu, P.; Liang, Z.; Zhang, J.; Mai, K. Sensing spatial distribution of urban land use by integrating points-of-interest and Google Word2Vec model. Int. J. Geogr. Inf. Sci. 2017, 31, 825–848. [Google Scholar] [CrossRef]
- Zhang, Y.; Li, Q.; Tu, W.; Mai, K.; Yao, Y.; Chen, Y.Y. Functional urban land use recognition integrating multi-source geospatial data and cross-correlations. Comput. Environ. Urban Syst. 2019, 78, 101374. [Google Scholar] [CrossRef]
- Li, J.; Xie, X.; Zhao, B. Identification of Urban Functional Area by Using Multisource Geographic Data: A Case Study of Zhengzhou, China. Complexity 2021, 2021, 8875276. [Google Scholar] [CrossRef]
- Niu, H.F.; Elisabete, A.S. Delineating urban functional use from points of interest data with neural network embedding: A case study in Greater London. Comput. Environ. Urban Syst. 2021, 88, 101651. [Google Scholar] [CrossRef]
- Chattopadhyay, S.; Ganguly, D. Node2vec with weak supervision on community structures. Pattern Recognit. Lett. 2021, 150, 147–154. [Google Scholar] [CrossRef]
- Yan, B. From ITDL to Place2Vec–Reasoning about Place Type Similarity and Relatedness by Learning Embeddings from Augmented Spatial Contexts. In Proceedings of the 25th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Redondo Beach, CA, USA, 7–10 November 2017; Volume 35. [Google Scholar]
- Wang, Y.; Piao, C.; Liu, C.H.; Zhou, C.; Tang, J. Modeling User Interests with Online Social Network Influence by Memory Augmented Sequence Learning. IEEE Trans. Netw. Sci. Eng. 2021, 8, 541–554. [Google Scholar] [CrossRef]
- Lu, W.P.; Tao, C.; Li, H.F.; Qi, J.; Li, Y.S. A unified deep learning framework for urban functional zone extraction based on multi-source heterogeneous data. Remote Sens. Environ. 2022, 270, 112830. [Google Scholar] [CrossRef]
- Feng, Y.; Huang, Z.; Wang, Y.L.; Wan, L.; Liu, Y.; Zhang, Y.; Shan, X. An SOE-based learning framework using multisource big data for identifying urban functional zones. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2021, 14, 7336–7348. [Google Scholar] [CrossRef]
- Ma, J.; Li, M.; Li, H.J. Traffic dynamics on multilayer networks with different speeds. IEEE Trans. Circuits Syst. II Express Briefs 2021, 69, 1697–1701. [Google Scholar] [CrossRef]
- Li, M.; Ma, J.; Zhang, J. Enhancing traffic capacity for multilayer networks by link rewiring. Int. J. Mod. Phys. B 2021, 35, 2150254. [Google Scholar] [CrossRef]
- Ding, R.; Yin, J.; Dai, P.; Jiao, L.; Li, R.; Li, T.; Wu, J. Optimal topology of multilayer urban traffic networks. Complexity 2019, 2019, 4230981. [Google Scholar] [CrossRef]
- Ding, R.; Ujang, N.; Hamid, H.B.; Abd Manan, M.S.; Li, R.; Albadareen, S.S.M.; Nochian, A.; Wu, J. Application of complex networks theory in urban traffic network researches. Netw. Spat. Econ. 2019, 19, 1281–1317. [Google Scholar] [CrossRef]
- Zhang, J.; Mao, S.; Yang, L.; Ma, W.; Li, S.; Gao, Z. Physics-informed deep learning for traffic state estimation based on the traffic flow model and computational graph method. Inf. Fusion 2024, 101, 101971. [Google Scholar] [CrossRef]
- Luo, S.; Zhang, Z.; Zhang, Y.; Ma, S. Co-association matrix-based multi-layer fusion for community detection in attributed networks. Entropy 2019, 21, 95. [Google Scholar] [CrossRef]
- Yildirimoglu, M.; Kim, J. Identification of communities in urban mobility networks using multi-layer graphs of network traffic. Transp. Res. Part C Emerg. Technol. 2018, 89, 254–267. [Google Scholar] [CrossRef]
- Interdonato, R.; Tagarelli, A.; Ienco, D.; Sallaberry, A.; Poncelet, P. Local community detection in multilayer networks. Data Min. Knowl. Discov. 2017, 31, 1444–1479. [Google Scholar] [CrossRef]
- Liu, C.; Huang, F.; Li, R.; Yang, Q.; Li, Y.; Yu, S. Community detection using multitopology and attributes in social networks. Concurr. Comput. Pract. Exp. 2022, 34, e6028. [Google Scholar] [CrossRef]
- Jia, J.; Liu, P.; Du, X.; Zhang, Y. Multilayer social network overlap** community detection algorithm based on trust relationship. Wirel. Commun. Mob. Comput. 2021, 2021, 9268039. [Google Scholar] [CrossRef]
- Chai, S.; Liang, Q.; Zhong, S. Design of Urban Rail Transit Network Constrained by Urban Road Network, Trips and Land-Use Characteristics. Sustainability 2019, 11, 6128. [Google Scholar] [CrossRef]
- Zhang, X.; Song, D.; Liu, Z.; Jing, Y.; Pu, J.; Yu, H. A new method for calculating traffic delay based on modified BPR function model. In Proceedings of the International Conference on Cryptography, Network Security, and Communication Technology (CNSCT 2023), Changsha, China, 6–8 January 2023; SPIE: Bellingham, WA, USA, 2023; Volume 12641, pp. 292–297. [Google Scholar]
- Nikolentzos, G.; Vazirgiannis, M. Random walk graph neural networks. Adv. Neural Inf. Process. Syst. 2020, 33, 16211–16222. [Google Scholar]
- Jabri, A.; Owens, A.; Efros, A. Space-time correspondence as a contrastive random walk. Adv. Neural Inf. Process. Syst. 2020, 33, 19545–19560. [Google Scholar]
- Chai, S.; Liang, Q. An Improved NSGA-II Algorithm for Transit Network Design and Frequency Setting Problem. J. Adv. Transp. 2020, 2020, 2895320. [Google Scholar] [CrossRef]
- Khan, R.U.; Yin, J.; Mustafa, F.S.; Shi, W. Factor assessment of hazardous cargo ship berthing accidents using an ordered logit regression model. Ocean. Eng. 2023, 284, 115211. [Google Scholar] [CrossRef]
- Johnson, S.J.; Murty, M.R.; Navakanth, I. A detailed review on word embedding techniques with emphasis on word2vec. Multimed. Tools Appl. 2024, 83, 37979–38007. [Google Scholar] [CrossRef]
- Mallik, A.; Kumar, S. Word2Vec and LSTM based deep learning technique for context-free fake news detection. Multimed. Tools Appl. 2024, 83, 919–940. [Google Scholar] [CrossRef]
- Wu, Q. Research on Urban Functional Area Recognition Based on Semantic Mining; China University of Mining and Technology: Beijing, China, 2021. (In Chinese) [Google Scholar]
- Bharadiya, J.P. A tutorial on principal component analysis for dimensionality reduction in machine learning. Int. J. Innov. Sci. Res. Technol. 2023, 8, 2028–2032. [Google Scholar]
- Silva, R.; Melo-Pinto, P. t-SNE: A study on reducing the dimensionality of hyperspectral data for the regression problem of estimating oenological parameters. Artif. Intell. Agric. 2023, 7, 58–68. [Google Scholar] [CrossRef]
- Ikotun, A.M.; Ezugwu, A.E.; Abualigah, L.; Abuhaija, B.; Heming, J. K-means clustering algorithms: A comprehensive review, variants analysis, and advances in the era of big data. Inf. Sci. 2023, 622, 178–210. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).