
CGAN-Based Forest Scene 3D Reconstruction from a Single Image


Abstract
1. Introduction
- We propose a new method of forest scene 3D reconstruction based on CGANs from a single image and perform a more detailed reconstruction of the trees in the scene, which differs from the reconstruction accuracy of the scene.
- We propose an outdoor scene depth estimation network based on the CGAN structure that exhibits outstanding performance in reconstructing complex outdoor scenes.
- We achieve detailed 3D reconstruction of trees within the forest scene with a tree silhouette depth map. The maximum absolute error for single-image reconstruction is reduced to 1.76 cm.
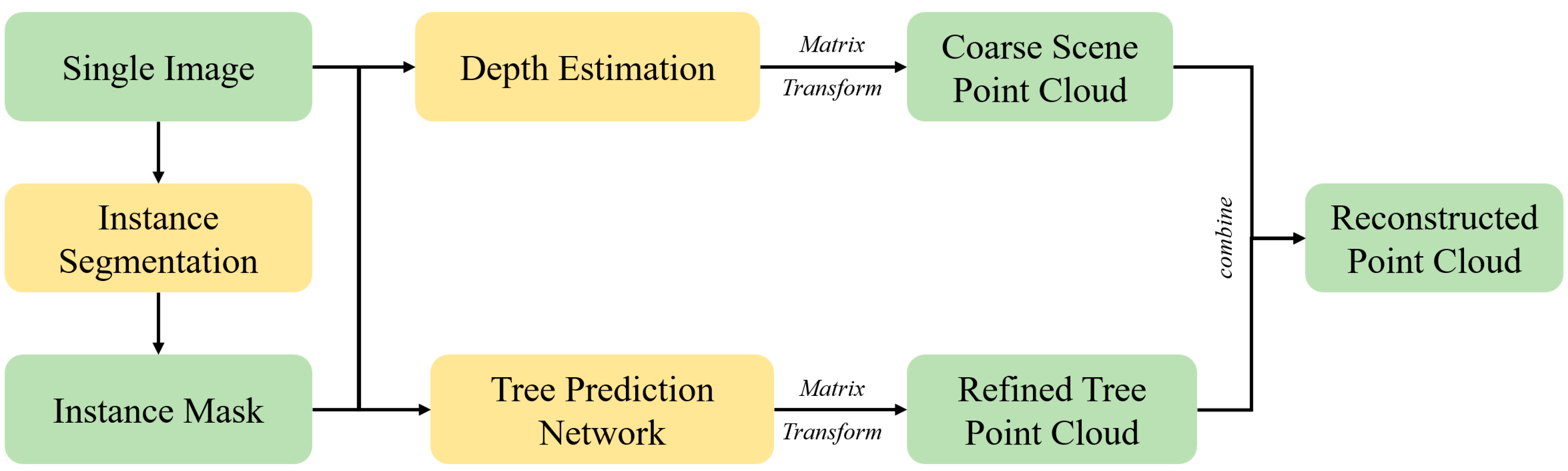
2. Methods
2.1. Instance Segmentation
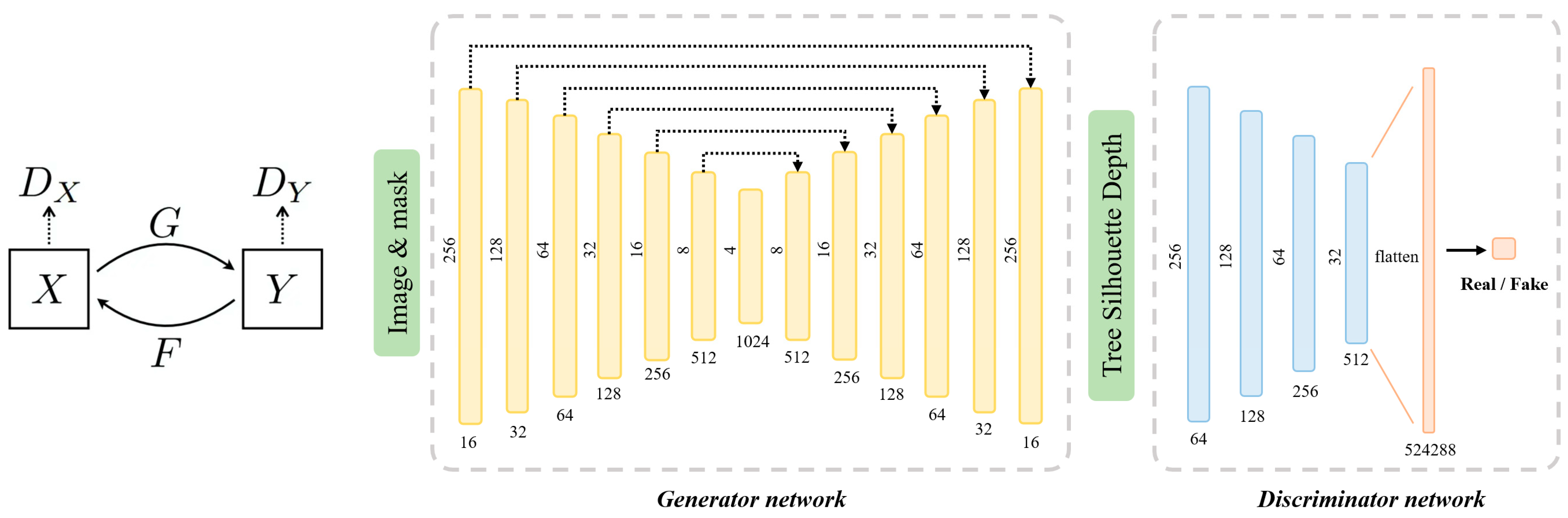
2.2. Depth Estimation (CDEN)
2.2.1. Generation Network
2.2.2. Discriminative Network
2.2.3. Loss Function
2.3. Tree Prediction Network
2.3.1. Tree Silhouette Depth Map
2.3.2. Network
2.3.3. Loss Function
3. Experiment and Results
3.1. Implementation
3.1.1. Dataset
3.1.2. Training Details
3.2. Evaluation Metrics
3.2.1. Depth Estimation Metrics
3.2.2. Forest Scene Reconstruction Metric
3.3. Reconstruction Results
3.4. Comparison Study
3.4.1. Depth Estimation Comparison
3.4.2. Forest Scene Reconstruction Comparison
3.5. Ablation Study
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Dugesar, V.; Satish, K.V.; Pandey, M.K.; Srivastava, P.K.; Petropoulos, G.P.; Anand, A.; Behera, M.D. Impact of Environmental Gradients on Phenometrics of Major Forest Types of Kumaon Region of the Western Himalaya. Forests 2022, 13, 1973. [Google Scholar] [CrossRef]
- Gollob, C.; Ritter, T.; Nothdurft, A. Forest inventory with long range and high-speed personal laser scanning (PLS) and simultaneous localization and mapping (SLAM) technology. Remote Sens. 2020, 12, 1509. [Google Scholar] [CrossRef]
- Cárdenas-Donoso, J.L.; Ogayar, C.J.; Feito, F.R.; Jurado, J.M. Modeling of the 3D tree skeleton using real-world data: A survey. IEEE Trans. Vis. Comput. Graph. 2022, 29, 4920–4935. [Google Scholar] [CrossRef] [PubMed]
- Hernandez-Santin, L.; Rudge, M.L.; Bartolo, R.E.; Erskine, P.D. Identifying species and monitoring understorey from UAS-derived data: A literature review and future directions. Drones 2019, 3, 9. [Google Scholar] [CrossRef]
- Raumonen, P.; Kaasalainen, M.; Åkerblom, M.; Kaasalainen, S.; Kaartinen, H.; Vastaranta, M.; Holopainen, M.; Disney, M.; Lewis, P. Fast automatic precision tree models from terrestrial laser scanner data. Remote Sens. 2013, 5, 491–520. [Google Scholar] [CrossRef]
- Tickle, P.K.; Lee, A.; Lucas, R.M.; Austin, J.; Witte, C. Quantifying Australian forest floristics and structure using small footprint LiDAR and large scale aerial photography. For. Ecol. Manag. 2006, 223, 379–394. [Google Scholar] [CrossRef]
- Wallace, L.; Lucieer, A.; Malenovský, Z.; Turner, D.; Vopěnka, P. Assessment of forest structure using two UAV techniques: A comparison of airborne laser scanning and structure from motion (SfM) point clouds. Forests 2016, 7, 62. [Google Scholar] [CrossRef]
- Davies, A.B.; Asner, G.P. Advances in animal ecology from 3D-LiDAR ecosystem mapping. Trends Ecol. Evol. 2014, 29, 681–691. [Google Scholar] [PubMed]
- Guerra-Hernández, J.; Cosenza, D.N.; Rodriguez, L.C.E.; Silva, M.; Tomé, M.; Díaz-Varela, R.A.; González-Ferreiro, E. Comparison of ALS-and UAV (SfM)-derived high-density point clouds for individual tree detection in Eucalyptus plantations. Int. J. Remote Sens. 2018, 39, 5211–5235. [Google Scholar] [CrossRef]
- Morgenroth, J.; Gómez, C. Assessment of tree structure using a 3D image analysis technique—A proof of concept. Urban For. Urban Green. 2014, 13, 198–203. [Google Scholar]
- Oveland, I.; Hauglin, M.; Gobakken, T.; Næsset, E.; Maalen-Johansen, I. Automatic estimation of tree position and stem diameter using a moving terrestrial laser scanner. Remote Sens. 2017, 9, 350. [Google Scholar]
- Karel, W.; Piermattei, L.; Wieser, M.; Wang, D.; Hollaus, M.; Pfeifer, N.; Surový, P.; Koreň, M.; Tomaštík, J.; Mokroš, M. Terrestrial photogrammetry for forest 3D modelling at the plot level. In Proceedings of the EGU General Assembly, Vienna, Austria, 8–13 April 2018; p. 12749. [Google Scholar]
- Iglhaut, J.; Cabo, C.; Puliti, S.; Piermattei, L.; O’Connor, J.; Rosette, J. Structure from motion photogrammetry in forestry: A review. Curr. For. Rep. 2019, 5, 155–168. [Google Scholar] [CrossRef]
- Tan, P.; Zeng, G.; Wang, J.; Kang, S.B.; Quan, L. Image-based tree modeling. In Proceedings of the ACM SIGGRAPH 2007 Papers, San Diego, CA, USA, 5–9 August 2007; p. 87-es. [Google Scholar]
- Guo, J.; Xu, S.; Yan, D.M.; Cheng, Z.; Jaeger, M.; Zhang, X. Realistic procedural plant modeling from multiple view images. IEEE Trans. Vis. Comput. Graph. 2018, 26, 1372–1384.16. [Google Scholar] [PubMed]
- Okura, F. 3D modeling and reconstruction of plants and trees: A cross-cutting review across computer graphics, vision, and plant phenotyping. Breed. Sci. 2022, 72, 31–47. [Google Scholar] [CrossRef] [PubMed]
- Tan, P.; Fang, T.; Xiao, J.; Zhao, P.; Quan, L. Single image tree modeling. ACM Trans. Graph. (TOG) 2008, 27, 1–7. [Google Scholar] [CrossRef]
- Guénard, J.; Morin, G.; Boudon, F.; Charvillat, V. Reconstructing plants in 3D from a single image using analysis-by-synthesis. In Advances in Visual Computing, Proceedings of the 9th International Symposium, ISVC 2013, Rethymnon, Crete, Greece, 29–31 July 2013; Springer: Berlin/Heidelberg, Germany, 2013; Proceedings, Part I 9; pp. 322–332. [Google Scholar]
- Eigen, D.; Puhrsch, C.; Fergus, R. Depth map prediction from a single image using a multi-scale deep network. Adv. Neural Inf. Process. Syst. 2014, 27, 2366–2374. [Google Scholar]
- Hoiem, D.; Efros, A.A.; Hebert, M. Automatic photo pop-up. In Proceedings of the ACM SIGGRAPH 2005 Papers, Los Angeles, CA, USA, 31 July 4 August 2005; pp. 577–584. [Google Scholar]
- Karsch, K.; Liu, C.; Kang, S.B. Depth extraction from video using non-parametric sampling. In Computer Vision–ECCV 2012, Proceedings of the 12th European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; Springer: Berlin/Heidelberg, Germany, 2012; Proceedings, Part V 12; pp. 775–788. [Google Scholar]
- Yang, Z.; Wang, P.; Wang, Y.; Xu, W.; Nevatia, R. Lego: Learning edge with geometry all at once by watching videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 225–234. [Google Scholar]
- Godard, C.; Mac Aodha, O.; Brostow, G. Unsupervised monocular depth estimation with left-right consistency. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 270–279. [Google Scholar]
- Liu, L.; Song, X.; Wang, M.; Liu, Y.; Zhang, L. Self-supervised monocular depth estimation for all day images using domain separation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 12737–12746. [Google Scholar]
- Ramamonjisoa, M.; Firman, M.; Watson, J.; Lepetit, V.; Turmukhambetov, D. Single image depth prediction with wavelet decomposition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 11089–11098. [Google Scholar]
- Chen, S.; Tang, M.; Dong, R.; Kan, J. Encoder–Decoder Structure Fusing Depth Information for Outdoor Semantic Segmentation. Appl. Sci. 2023, 13, 9924. [Google Scholar] [CrossRef]
- Cheng, B.; Misra, I.; Schwing, A.G.; Kirillov, A.; Girdhar, R. Masked-attention mask transformer for universal image segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 July 2022; pp. 1290–1299. [Google Scholar]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015, Proceedings of the 18th International Conference, Munich, Germany, 5–9 October 2015; Springer International Publishing: Berlin/Heidelberg, Germany, 2015; Proceedings, Part III 18; pp. 234–241. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The cityscapes dataset for semantic urban scene understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3213–3223. [Google Scholar]
- Saxena, A.; Sun, M.; Ng, A.Y. Make3d: Learning 3d scene structure from a single still image. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 31, 824–840. [Google Scholar] [CrossRef] [PubMed]
- Masoumian, A.; Rashwan, H.A.; Abdulwahab, S.; Cristiano, J.; Asif, M.S.; Puig, D. Gcndepth: Self-supervised monocular depth estimation based on graph convolutional network. Neurocomputing 2023, 517, 81–92. [Google Scholar] [CrossRef]
- Pnvr, K.; Zhou, H.; Jacobs, D. Sharingan: Combining synthetic and real data for unsupervised geometry estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 13974–13983. [Google Scholar]
- Godard, C.; Mac Aodha, O.; Firman, M.; Brostow, G.J. Digging into Self-Supervised Monocular Depth Estimation. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 3827–3837. [Google Scholar]
- Laina, I.; Rupprecht, C.; Belagiannis, V.; Tombari, F.; Navab, N. Deeper depth prediction with fully convolutional residual networks. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; pp. 239–248. [Google Scholar]
- Xu, D.; Ouyang, W.; Wang, X.; Sebe, N. Pad-net: Multi-tasks guided prediction-and-distillation network for simultaneous depth estimation and scene parsing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 675–684. [Google Scholar]
- Zhang, Z.; Cui, Z.; Xu, C.; Jie, Z.; Li, X.; Yang, J. Joint task-recursive learning for semantic segmentation and depth estimation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 235–251. [Google Scholar]
- Chen, S. Monocular Image Depth Estimation and Application in 3D Reconstruction of Forest Scene. Ph.D. Thesis, Beijing Forestry University, Beijing, China, 2021. [Google Scholar]
- Gao, Q.; Kan, J. Automatic forest DBH measurement based on structure from motion photogrammetr. Remote Sens. 2022, 14, 2064. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Metric | Formula |
|---|---|
| AbsRel | |
| RMSE | |
| SqRel | |
| RMSE-Log |
| Method | AbsRel | RMSE | SqRel | log10 |
|---|---|---|---|---|
| GCNDepth [34] | 0.424 | 6.757 | 3.075 | 0.107 |
| SharinGAN [35] | 0.377 | 8.388 | 4.901 | 0.225 |
| Monodepth2 [36] | 0.322 | 7.417 | 3.589 | 0.201 |
| Chen et al. [26] | 0.257 | 6.74 | 4.129 | 0.083 |
| Ours | 0.246 | 6.152 | 3.015 | 0.056 |
| Method | AbsRel | RMSE | SqRel | log10 |
|---|---|---|---|---|
| Laina et al. [37] | 0.257 | 7.273 | 4.238 | 0.448 |
| Xu et al. [38] | 0.246 | 7.117 | 4.06 | 0.428 |
| Zhang et al. [39] | 0.234 | 7.104 | 3.776 | 0.416 |
| Ours | 0.221 | 6.918 | 3.451 | 0.403 |
| Location | Mean DBH | Method | Min MAE (cm) | Max MAE (cm) | Mean MAE (cm) | Relative MAE |
|---|---|---|---|---|---|---|
| Beijing | 20.1 cm | Chen et al. [40] | 0.61 | 4.89 | 2.65 | 13.18% |
| Gao et al. [41] | 0.36 | 4.95 | 1.84 | 9.15% | ||
| Ours | 0.42 | 4.05 | 1.76 | 8.75% | ||
| Shandong | 16.7 cm | Chen et al. [40] | 0.49 | 3.75 | 2.36 | 14.12% |
| Gao et al. [41] | 0.29 | 3.64 | 1.48 | 8.86% | ||
| Ours | 0.33 | 3.56 | 1.25 | 7.49% |
| Network | Mean MAE (cm) | Relative MAE |
|---|---|---|
| Depth Estimation | 2.17 | 10.72% |
| Depth Estimation + Tree Prediction Network | 1.76 | 8.75% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Y.; Kan, J. CGAN-Based Forest Scene 3D Reconstruction from a Single Image. Forests 2024, 15, 194. https://doi.org/10.3390/f15010194
Li Y, Kan J. CGAN-Based Forest Scene 3D Reconstruction from a Single Image. Forests. 2024; 15(1):194. https://doi.org/10.3390/f15010194
Chicago/Turabian StyleLi, Yuan, and Jiangming Kan. 2024. "CGAN-Based Forest Scene 3D Reconstruction from a Single Image" Forests 15, no. 1: 194. https://doi.org/10.3390/f15010194
APA StyleLi, Y., & Kan, J. (2024). CGAN-Based Forest Scene 3D Reconstruction from a Single Image. Forests, 15(1), 194. https://doi.org/10.3390/f15010194