
Self-Adaptive Colour Calibration of Deep Underwater Images Using FNN and SfM-MVS-Generated Depth Maps



Abstract
1. Introduction
1.1. Optical Properties of Water
1.2. Artificial Intelligence
1.2.1. Machine Learning
1.2.2. Deep Learning
1.3. The Aim of This Paper
2. Related Work
2.1. Image Enhancement
2.2. Image Restoration
2.3. Artificial Intelligence Methods
3. Materials and Methods
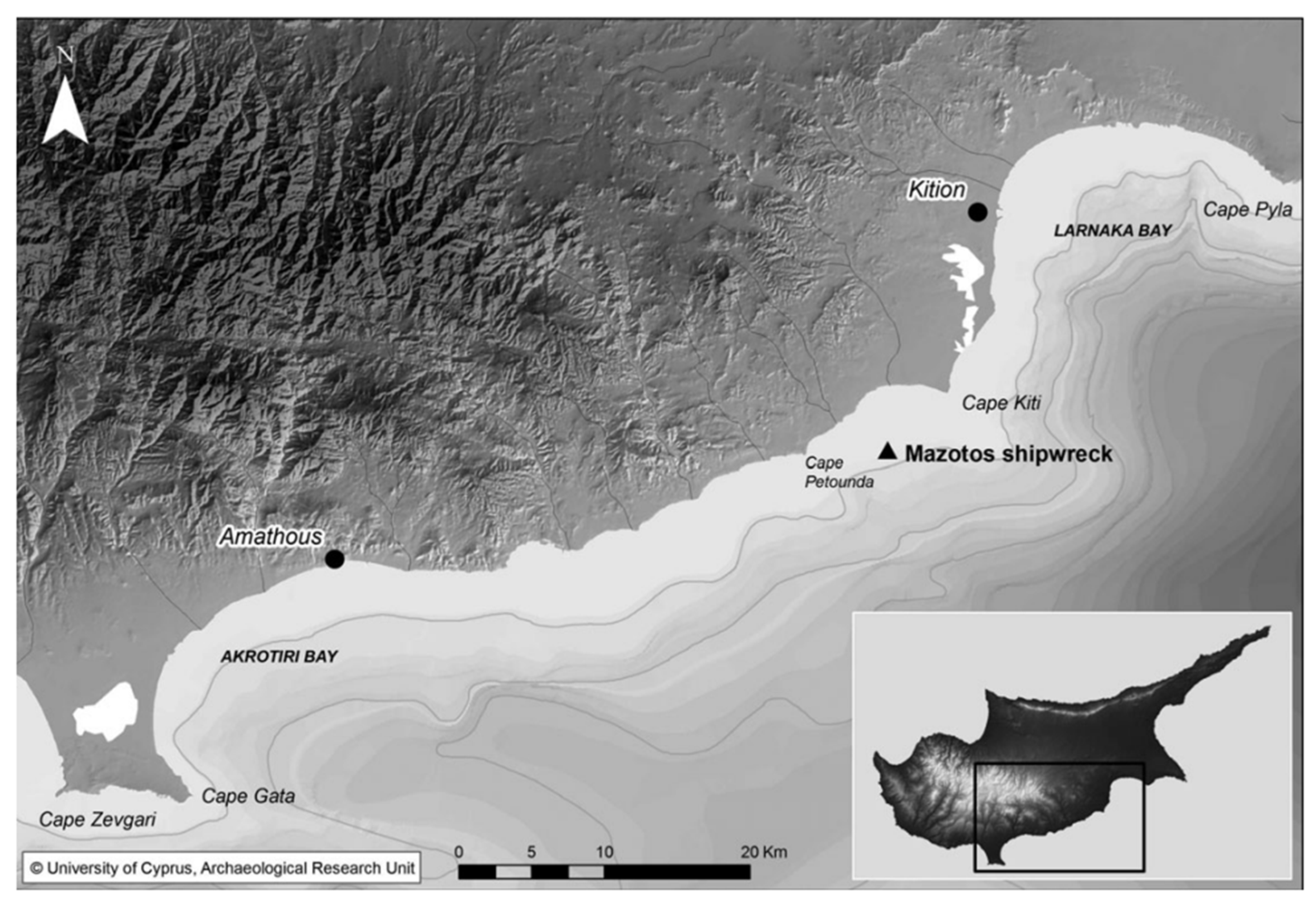
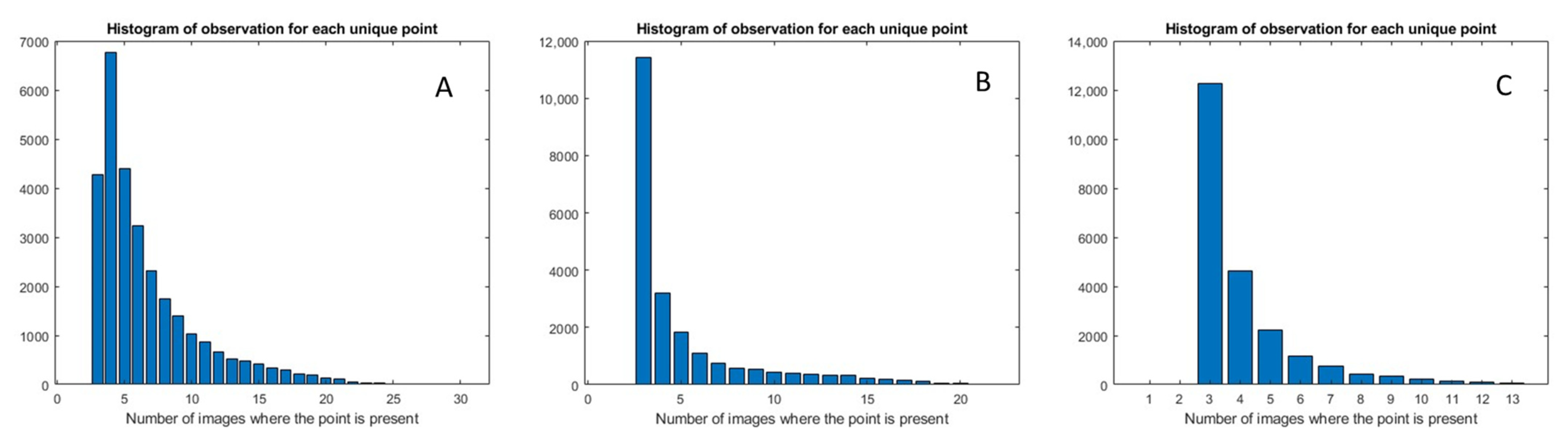
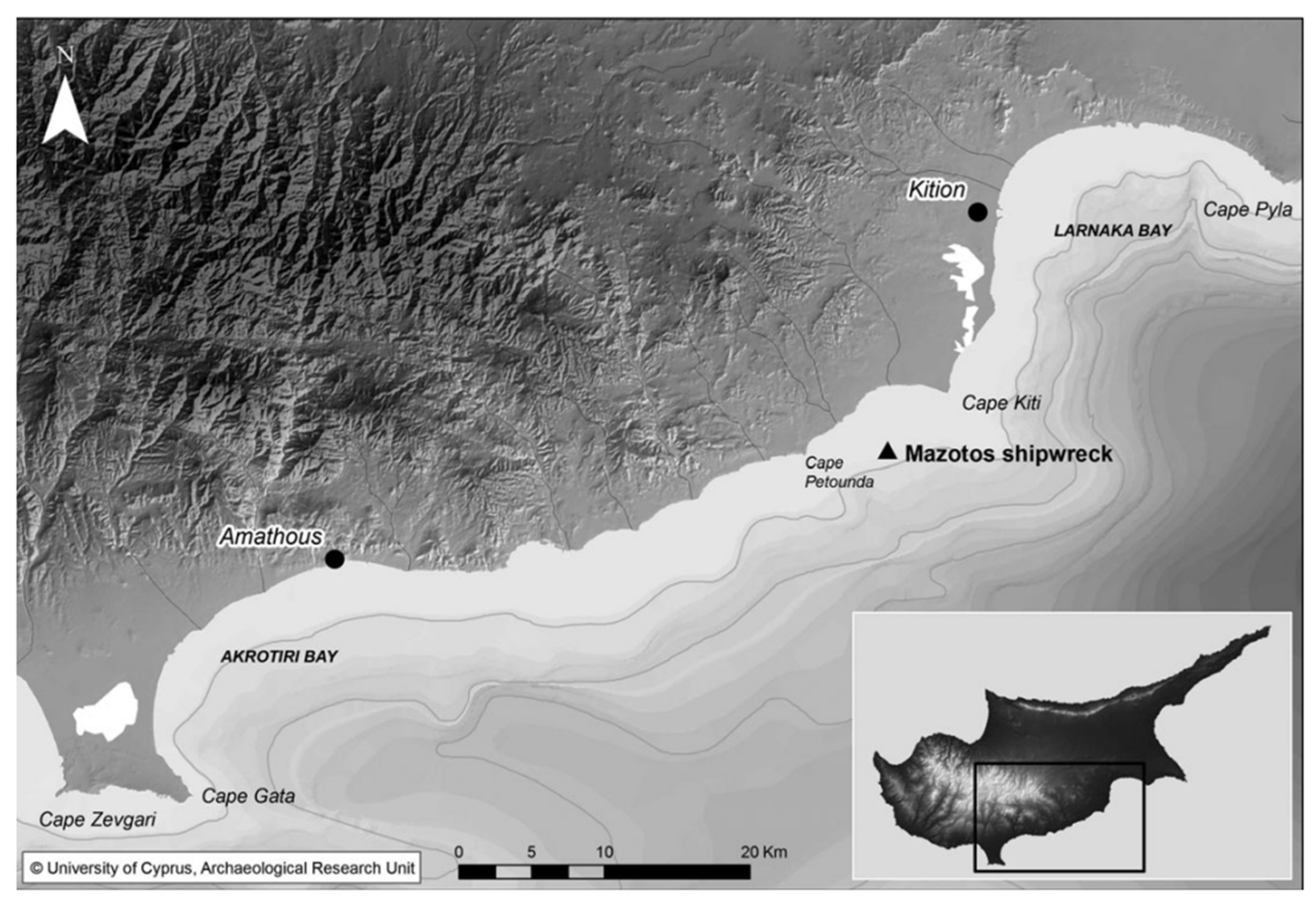
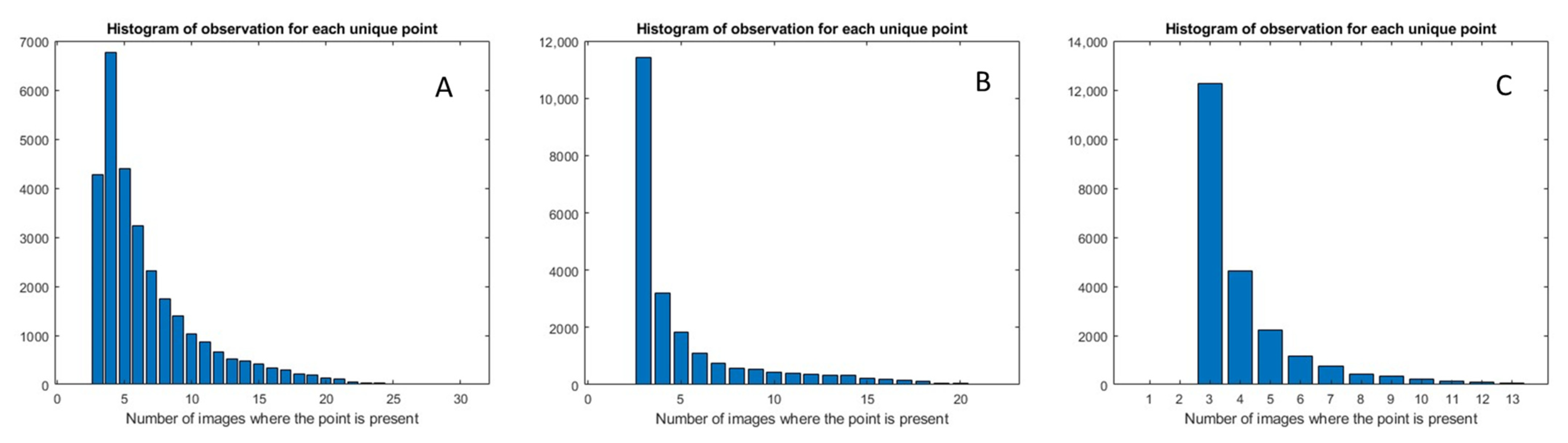
3.1. Dataset Formation
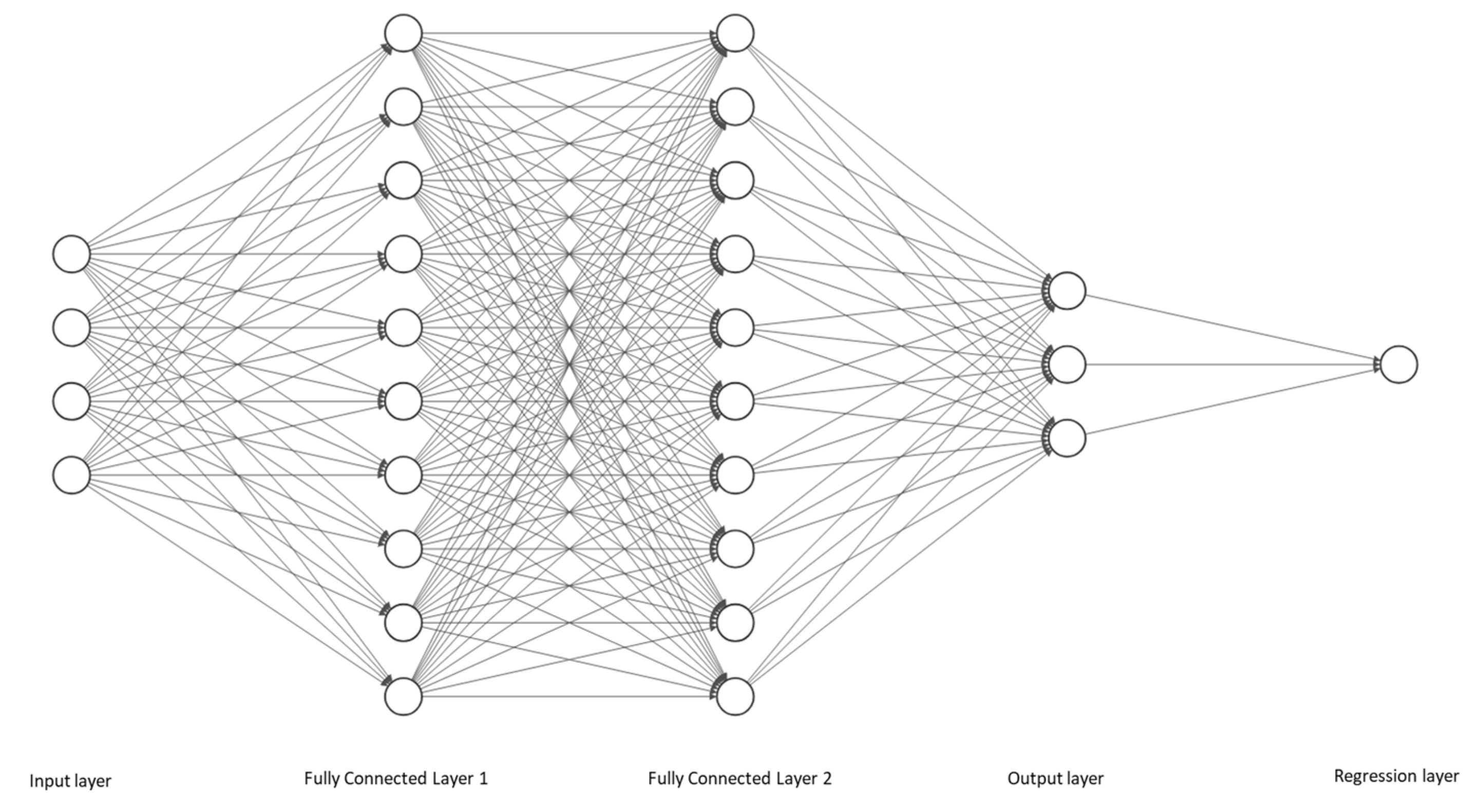
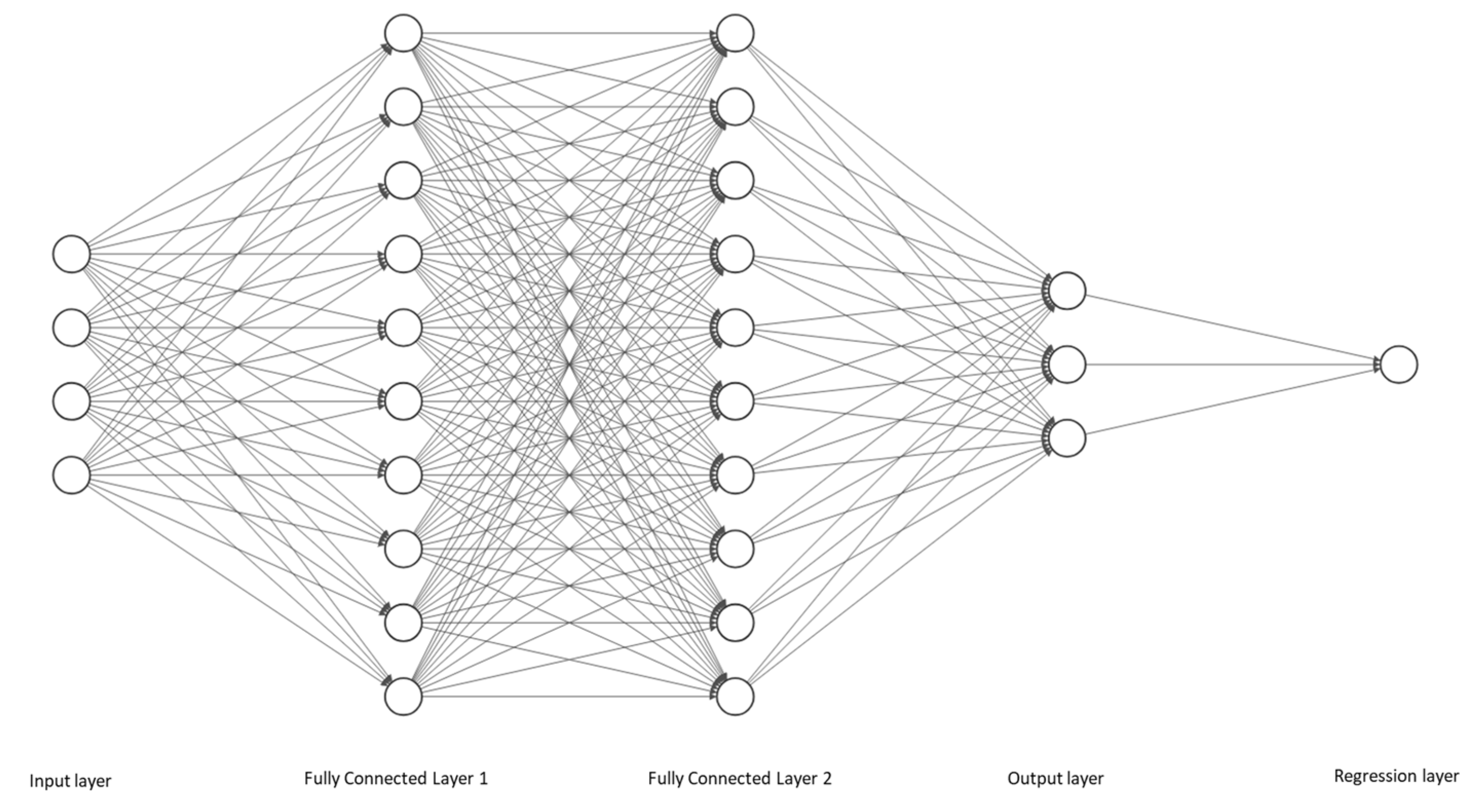
3.2. Network Architecture
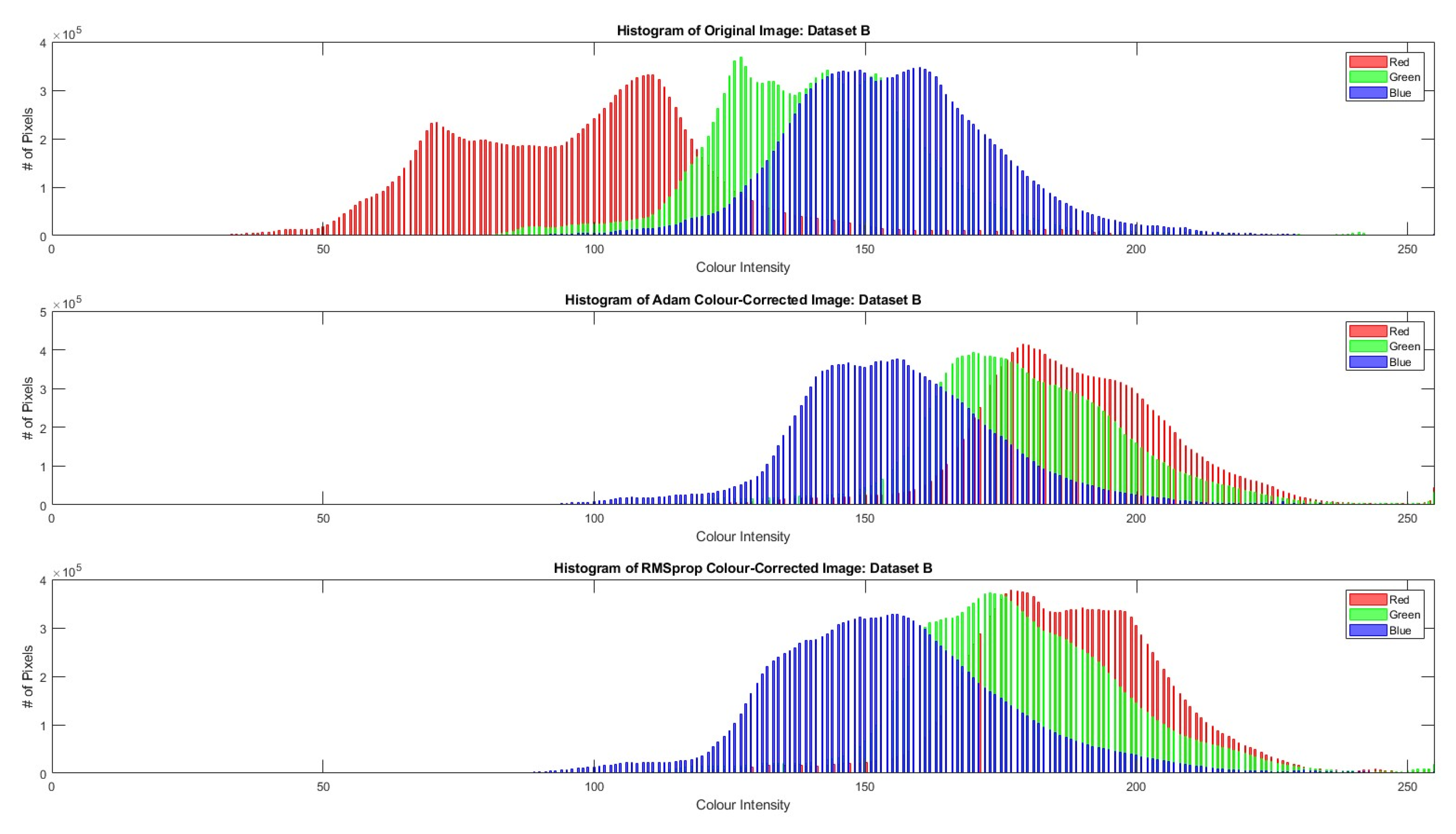
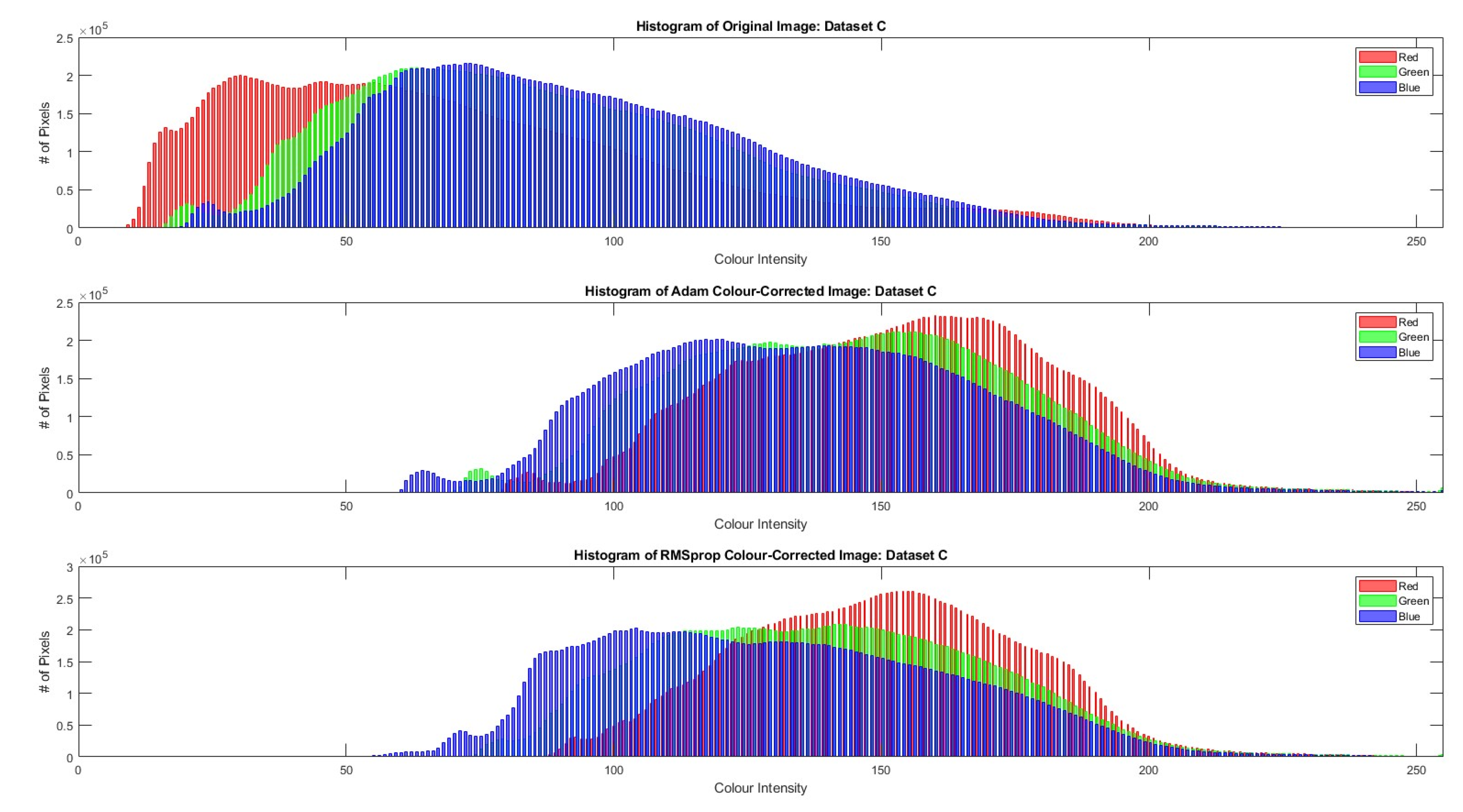
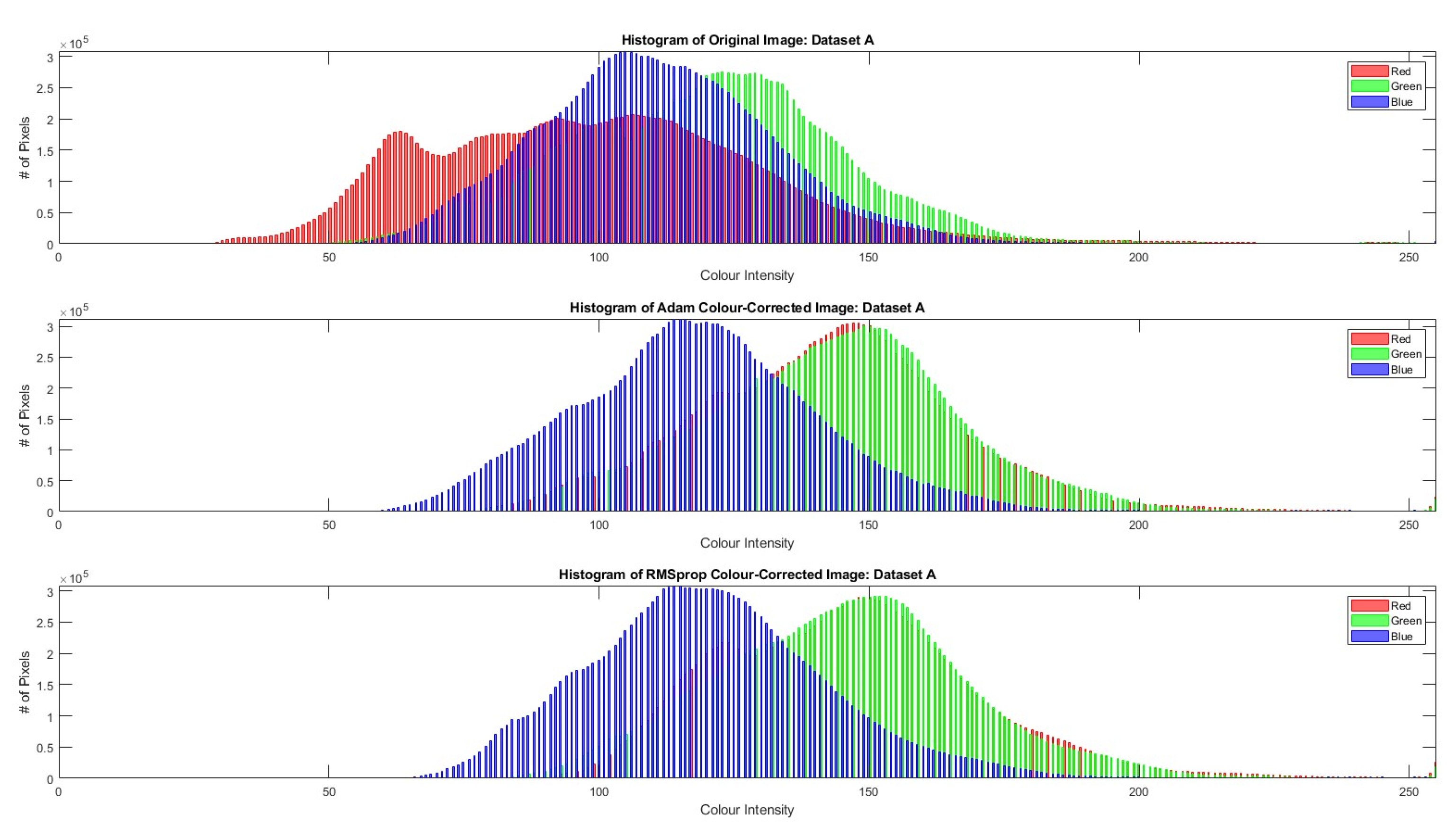
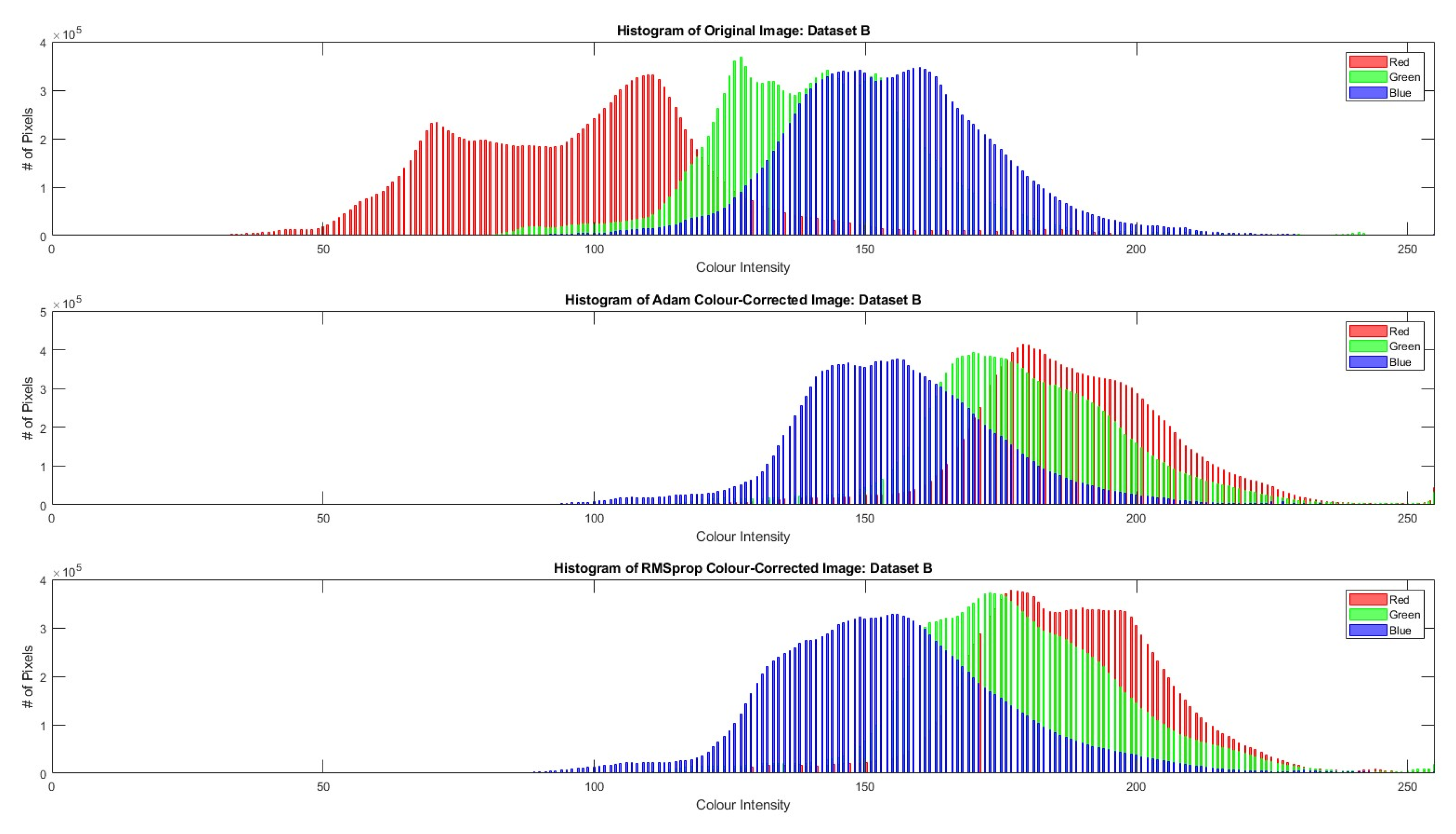
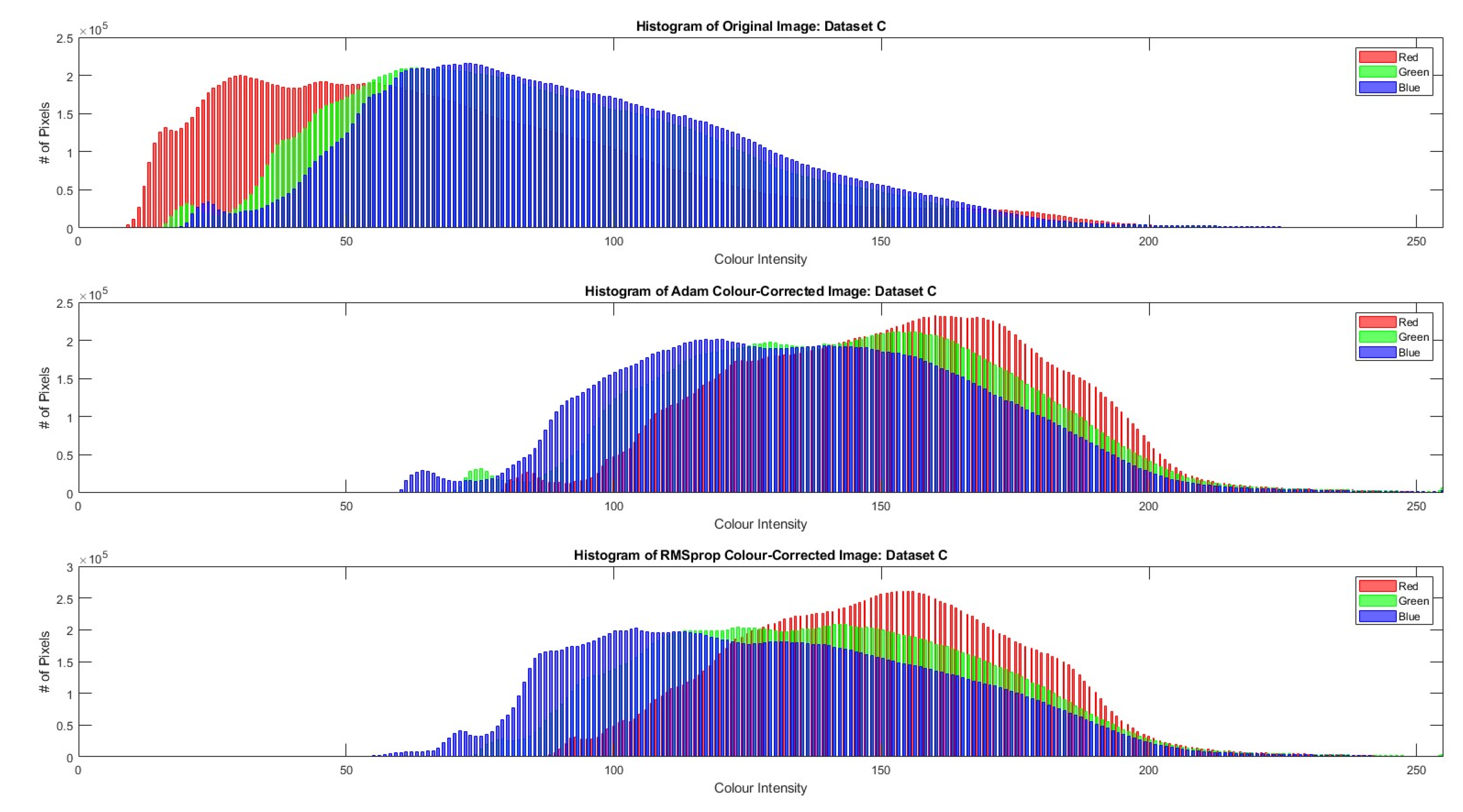
4. Results
5. Discussion
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Klemen, I. Underwater Image-Based 3D Reconstruction with Quality Estimation; University of Girona: Girona, Spain, 2021. [Google Scholar]
- Wang, Y.; Song, W.; Fortino, G.; Qi, L.Z.; Zhang, W.; Liotta, A. An Experimental-Based Review of Image Enhancement and Image Restoration Methods for Underwater Imaging. IEEE Access 2019, 7, 140233–140251. [Google Scholar] [CrossRef]
- Bekerman, Y.; Avidan, S.; Treibitz, T. Unveiling Optical Properties in Underwater Images. In Proceedings of the 2020 IEEE International Conference on Computational Photography (ICCP), St. Louis, MO, USA, 24–26 April 2020; pp. 1–12. [Google Scholar] [CrossRef]
- Morel, A.; Gentili, B.; Claustre, H.; Babin, M.; Bricaud, A.; Ras, J.; Tièche, F. Opticals Properties of the “Clearest” Natural Waters. Limnol. Oceanogr. 2007, 52, 217–229. [Google Scholar] [CrossRef]
- Menna, F.; Agrafiotis, P.; Georgopoulos, A. State of the Art and Applications in Archaeological Underwater 3D Recording and Mapping. J. Cult. Herit. 2018, 33, 231–248. [Google Scholar] [CrossRef]
- Jerlov, N.G.; Koczy, F.F.; Schooner, A. Photographic Measurements of Daylight in Deep Water; Reports of the Swedish Deep-Sea Expedition, 1947–1948 ; v. 3: Physics and Chemistry; Elanders Boktr: Mölnlycke, Sweden, 1951. [Google Scholar]
- Solonenko, M.G.; Mobley, C.D. Inherent Optical Properties of Jerlov Water Types. Appl. Opt. 2015, 54, 5392. [Google Scholar] [CrossRef] [PubMed]
- Akkaynak, D.; Treibitz, T.; Shlesinger, T.; Tamir, R.; Loya, Y.; Iluz, D. What Is the Space of Attenuation Coefficients in Underwater Computer Vision? Proceedings of thr 30th IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 568–577. [Google Scholar] [CrossRef]
- Blasinski, H.; Breneman IV, J.; Farrell, J. A model for estimating spectral properties of water from rgb images. In Proceedings of the International Conference on Image Processing (ICIP), Paris, France, 27–30 October 2014; pp. 610–614. [Google Scholar]
- Lebart, K.; Smith, C.; Trucco, E.; Lane, D.M. Automatic Indexing of Underwater Survey Video: Algorithm and Benchmarking Method. IEEE J. Ocean. Eng. 2003, 28, 673–686. [Google Scholar] [CrossRef]
- Yuh, J.; West, M. Underwater Robotics; Taylor & Francis: Oxfordshire, UK, 2001; Volume 15, ISBN 1568553013. [Google Scholar]
- Chao, L.; Wang, M. Removal of Water Scattering. In Proceedings of the ICCET 2010—2010 International Conference on Computer Engineering and Technology, Proceedings, Chengdu, China, 16–18 April 2010; Volume 2, pp. 35–39. [Google Scholar] [CrossRef]
- Hou, W.; Gray, D.J.; Weidemann, A.D.; Fournier, G.R.; Forand, J.L. Automated Underwater Image Restoration and Retrieval of Related Optical Properties. In Proceedings of the IEEE International Geoscience & Remote Sensing Symposium, IGARSS 2007, Barcelona, Spain, 23–28 July 2007; pp. 1889–1892. [Google Scholar] [CrossRef]
- Schechner, Y.Y.; Karpel, N. Recovery of Underwater Visibility and Structure by Polarization Analysis. IEEE J. Ocean. Eng. 2005, 30, 570–587. [Google Scholar] [CrossRef]
- Murphy, K.P. Machine Learning: A Probabilistic Perspective; MIT Press: Cambridge, MA, USA, 2013; ISBN 9780262018029 0262018020. [Google Scholar]
- Pyle, D. Data Preparation for Data Mining; The Morgan Kaufmann Series in Data Management Systems; Elsevier Science: Amsterdam, The Netherlands, 1999; ISBN 9781558605299. [Google Scholar]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning; Springer Series in Statistics; Springer New York Inc.: New York, NY, USA, 2001. [Google Scholar]
- Jordan, M.I.; Mitchell, T.M. Machine Learning: Trends, Perspectives, and Prospects. Science 2015, 349, 255–260. [Google Scholar] [CrossRef] [PubMed]
- Aggarwal, C.C. Teaching Deep Learners to Generalize; Springer: Cham, Switzerland, 2018; ISBN 9783319944623. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Russell, S.; Norvig, P. Artificial Intelligence: A Modern Approach, 3rd ed.; Prentice Hall: Hoboken, NJ, USA, 2010. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the Advances in Neural Information Processing Systems; Pereira, F., Burges, C.J., Bottou, L., Weinberger, K.Q., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2012; Volume 25. [Google Scholar]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-Image Translation with Conditional Adversarial Networks. In Proceedings of the Proceedings—30th IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 5967–5976. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. In Proceedings of the Advances in Neural Information Processing Systems; Ghahramani, Z., Welling, M., Cortes, C., Lawrence, N., Weinberger, K.Q., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2014; Volume 27. [Google Scholar]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network. In Proceedings of the Proceedings—30th IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 105–114. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern. Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Akkaynak, D.; Treibitz, T. A Revised Underwater Image Formation Model. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6723–6732. [Google Scholar] [CrossRef]
- Akkaynak, D.; Treibitz, T. Sea-THRU: A Method for Removing Water from Underwater Images. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition 2019, Long Beach, CA, USA, 15–20 June 2019; pp. 1682–1691. [Google Scholar] [CrossRef]
- Bryson, M.; Johnson-Roberson, M.; Pizarro, O.; Williams, S.B. Colour-Consistent Structure-from-Motion Models Using Underwater Imagery. Robot. Sci. Syst. 2013, 8, 33–40. [Google Scholar] [CrossRef]
- Bryson, M.; Johnson-Roberson, M.; Pizarro, O.; Williams, S.B. True Color Correction of Autonomous Underwater Vehicle Imagery. J. Field Robot. 2016, 33, 853–874. [Google Scholar] [CrossRef]
- Demesticha, S. The 4th-Century-BC Mazotos Shipwreck, Cyprus: A Preliminary Report. Int. J. Naut. Archaeol. 2011, 40, 39–59. [Google Scholar] [CrossRef]
- Demesticha, S.; Skarlatos, D.; Neophytou, A. The 4th-Century B.C. Shipwreck at Mazotos, Cyprus: New Techniques and Methodologies in the 3D Mapping of Shipwreck Excavations. J. Field Archaeol. 2014, 39, 134–150. [Google Scholar] [CrossRef]
- Corchs, S.; Schettini, R. Underwater Image Processing: State of the Art of Restoration and Image Enhancement Methods. EURASIP J. Adv. Signal Process. 2010, 2010, 1–14. [Google Scholar] [CrossRef]
- Vlachos, M.; Skarlatos, D. An Extensive Literature Review on Underwater Image Colour Correction. Sensors 2021, 21, 5690. [Google Scholar] [CrossRef]
- Ancuti, C.; Ancuti, C.O.; Haber, T.; Bekaert, P. Enhancing Underwater Images and Videos by Fusion. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition 2012, Providence, RI, USA, 16–21 June 2012; pp. 81–88. [Google Scholar] [CrossRef]
- Bianco, G.; Muzzupappa, M.; Bruno, F.; Garcia, R.; Neumann, L. A New Color Correction Method for Underwater Imaging. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci.—ISPRS Arch. 2015, 40, 25–32. [Google Scholar] [CrossRef]
- Nurtantio Andono, P.; Eddy Purnama, I.K.; Hariadi, M. Underwater Image Enhancement Using Adaptive Filtering for Enhanced Sift-Based Image Matching. J. Theor. Appl. Inf. Technol. 2013, 52, 273–280. [Google Scholar]
- Ancuti, C.O.; Ancuti, C.; De Vleeschouwer, C.; Neumann, L.; Garcia, R. Color Transfer for Underwater Dehazing and Depth Estimation. In Proceedings of the Proceedings—International Conference on Image Processing, ICIP 2018, Athens, Greece, 7–10 October 2018; pp. 695–699. [Google Scholar] [CrossRef]
- Zhao, X.; Jin, T.; Qu, S. Deriving Inherent Optical Properties from Background Color and Underwater Image Enhancement. Ocean Eng. 2015, 94, 163–172. [Google Scholar] [CrossRef]
- Yan-Tsung, P.; Xiangyun, Z.; Pamela, C. Single underwater image enhancement using depth estimation based on blurriness. In Proceedings of the 2015 IEEE International Conference on Image Processing (ICIP), Quebec City, QC, Canada, 28 September 2015; pp. 2–6. [Google Scholar]
- Torres-Méndez, L.A.; Dudek, G. Color Correction of Underwater Images for Aquatic Robot Inspection; Springer: Berlin/Heidelberg, Germany, 2005; pp. 60–73. [Google Scholar] [CrossRef]
- Li, C.; Guo, J.; Guo, C. Emerging from Water: Underwater Image Color Correction Based on Weakly Supervised Color Transfer. IEEE Signal Process Lett 2018, 25, 323–327. [Google Scholar] [CrossRef]
- Hashisho, Y.; Albadawi, M.; Krause, T.; von Lukas, U.F. Underwater Color Restoration Using U-Net Denoising Autoencoder; IEEE: Piscataway, NJ, USA, 2019. [Google Scholar]
- Awan, H.S.A.; Mahmood, M.T. Underwater Image Restoration through Color Correction and UW-Net. Electronics 2024, 13, 199. [Google Scholar] [CrossRef]
- Ertan, Z.; Korkut, B.; Gördük, G.; Kulavuz, B.; Bakırman, T.; Bayram, B. Enhancement of underwater images with artificial intelligence. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2024, XLVIII-4/W9-2024, 149–156. [Google Scholar] [CrossRef]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired Image-to-Image Translation Using Cycle-Consistent Adversarial Networks. In Proceedings of the IEEE International Conference on Computer Vision 2017, Venice, Italy, 22–29 October 2017; pp. 2242–2251. [Google Scholar] [CrossRef]
- Lu, J.; Li, N.; Zhang, S.; Yu, Z.; Zheng, H.; Zheng, B. Multi-Scale Adversarial Network for Underwater Image Restoration. Opt. Laser Technol. 2019, 110, 105–113. [Google Scholar] [CrossRef]
- Li, J.; Skinner, K.A.; Eustice, R.M.; Johnson-Roberson, M. WaterGAN: Unsupervised Generative Network to Enable Real-Time Color Correction of Monocular Underwater Images. IEEE Robot. Autom. Lett. 2018, 3, 387–394. [Google Scholar] [CrossRef]
- Wang, N.; Zhou, Y.; Han, F.; Zhu, H.; Zheng, Y. UWGAN: Underwater GAN for Real-World Underwater Color Restoration and Dehazing. arXiv 2019, arXiv:1912.10269v2. [Google Scholar]
- Fabbri, C.; Islam, M.J.; Sattar, J. Enhancing Underwater Imagery Using Generative Adversarial Networks. Proc. IEEE Int. Conf. Robot Autom. 2018, 7159–7165. [Google Scholar] [CrossRef]
- Gulrajani, I.; Ahmed, F.; Arjovsky, M.; Dumoulin, V.; Courville, A. Improved Training of Wasserstein GANs. arXiv 2017, arXiv:1704.00028. [Google Scholar]
- Mu, D.; Li, H.; Liu, H.; Dong, L.; Zhang, G. Underwater Image Enhancement Using a Mixed Generative Adversarial Network. IET Image Process. 2023, 17, 1149–1160. [Google Scholar] [CrossRef]
- Aggarwal, C.C. Neural Networks and Deep Learning; Springer International Publishing: Cham, Switzerland, 2018. [Google Scholar]
- Müller, A.C.; Guido, S. Introduction to Machine Learning with Python a Guide for Data Scientists Introduction to Machine Learning with Python; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2016. [Google Scholar]
- Géron, A. Hands-on Machine Learning with Scikit-Learn, Keras, and TensorFlow Concepts, Tools, and Techniques to Build Intelligent Systems, 2nd ed.; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2019. [Google Scholar]
- Kingma, D.P.; Ba, J.L. Adam: A Method for Stochastic Optimization. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015—Conference Track Proceedings, San Diego, CA, USA, 7–9 May 2015; pp. 1–15. [Google Scholar]
- Hinton, G.E.; Srivastava, N.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R.R. Improving Neural Networks by Preventing Co-Adaptation of Feature Detectors. arXiv 2012, arXiv:1207.0580. [Google Scholar]
- Yang, M.; Sowmya, A. An Underwater Color Image Quality Evaluation Metric. IEEE Trans. Image Process. 2015, 24, 6062–6071. [Google Scholar] [CrossRef]
- Panetta, K.; Gao, C.; Agaian, S. Human-Visual-System-Inspired Underwater Image Quality Measures. IEEE J. Ocean. Eng. 2016, 41, 541–551. [Google Scholar] [CrossRef]
- Wang, Y.; Li, N.; Li, Z.; Gu, Z.; Zheng, H.; Zheng, B.; Sun, M. An Imaging-Inspired No-Reference Underwater Color Image Quality Assessment Metric. Comput. Electr. Eng. 2018, 70, 904–913. [Google Scholar] [CrossRef]
- Li, C.; Guo, C.; Ren, W.; Cong, R.; Hou, J.; Kwong, S.; Tao, D. An Underwater Image Enhancement Benchmark Dataset and Beyond. IEEE Trans. Image Process. 2020, 29, 4376–4389. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | A | B | C |
|---|---|---|---|
| Adam Val R | 0.781 | 0.874 | 0.799 |
| Adam Test R | 0.809 | 0.821 | 0.812 |
| RMSprop Val R | 0.777 | 0.821 | 0.807 |
| RMSprop Test R | 0.807 | 0.751 | 0.817 |
| Dataset | A | B | C |
|---|---|---|---|
| Camera | Sony SLT-A57 | Sony SLT-A57 | Canon EOS 7D |
| Housing | Ikelite (dome) | Ikelite (dome) | Nauticam (dome) |
| Strobes | Ikelite DS125 | Ikelite DS125 | Inon Z-240 Type 4 |
| Resolution | 4912 × 3264 | 4912 × 3264 | 5184 × 3456 |
| Date | 23 October 2019 | 20 October 2019 | 15 October 2018 |
| Time (EEST) | 09:00–09:20 | 13:12–13:32 | 12:48–13:08 |
| # of images | 307 | 173 | 104 |
| # of SfM points | 154 k | 225 k | 180 k |
| # of GT points | 29 k | 22 k | 22 k |
| # of training samples | 139 k | 69 k | 46 k |
| Bundle adjustment RMSE | 2.7 cm | 2.9 cm | 2.6 cm |
| Min CoD of GT points | 0.702 m | 0.424 m | 0.523 m |
| Max CoD of GT points | 1.327 m | 0.883 m | 1.171 m |
| Mean CoD of GT points | 1.010 m | 0.681 m | 0.958 m |
| Mean Acquisition Distance | 1.52 m | 1.38 m | 1.07 m |
| UCIQE | UIQM | CCF | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Image | Original | Adam | RMSprop | Original | Adam | RMSprop | Original | Adam | RMSprop |
| A1 | 0.4995 | 0.415 | 0.415 | 0.4521 | 0.337 | 0.3277 | 11.6494 | 10.9878 | 10.7899 |
| A2 | 0.4525 | 0.3991 | 0.3991 | 0.4935 | 0.4205 | 0.4155 | 14.1839 | 13.0842 | 13.086 |
| A3 | 0.4777 | 0.3889 | 0.3889 | 0.3994 | 0.340 | 0.3244 | 13.5161 | 10.7012 | 9.8241 |
| A4 | 0.4111 | 0.3585 | 0.3585 | 0.4591 | 0.3943 | 0.3851 | 11.2058 | 10.7861 | 10.4697 |
| A5 | 0.429 | 0.3673 | 0.3673 | 0.4241 | 0.3825 | 0.3762 | 12.1364 | 11.692 | 11.7376 |
| B1 | 0.499 | 0.3983 | 0.3983 | 0.3874 | 0.3057 | 0.3145 | 11.3282 | 9.9403 | 10.2349 |
| B2 | 0.5059 | 0.4207 | 0.4207 | 0.5013 | 0.4055 | 0.4117 | 14.8991 | 13.7815 | 13.9383 |
| B3 | 0.4172 | 0.3523 | 0.3523 | 0.3314 | 0.3143 | 0.3283 | 10.0052 | 9.6501 | 9.9734 |
| B4 | 0.4863 | 0.3745 | 0.3745 | 0.4331 | 0.3803 | 0.3865 | 12.8144 | 12.0295 | 12.5552 |
| C1 | 0.4817 | 0.3412 | 0.3412 | 0.5974 | 0.4694 | 0.4675 | 12.9167 | 11.2434 | 10.9898 |
| C2 | 0.569 | 0.423 | 0.423 | 0.6624 | 0.4964 | 0.4925 | 16.5993 | 14.6705 | 14.3572 |
| C3 | 0.5504 | 0.4355 | 0.4355 | 0.6395 | 0.494 | 0.5106 | 19.1362 | 15.8096 | 15.6753 |
| C4 | 0.5382 | 0.4183 | 0.4183 | 0.635 | 0.4679 | 0.4754 | 16.6003 | 15.9823 | 15.5284 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Vlachos, M.; Skarlatos, D. Self-Adaptive Colour Calibration of Deep Underwater Images Using FNN and SfM-MVS-Generated Depth Maps. Remote Sens. 2024, 16, 1279. https://doi.org/10.3390/rs16071279
Vlachos M, Skarlatos D. Self-Adaptive Colour Calibration of Deep Underwater Images Using FNN and SfM-MVS-Generated Depth Maps. Remote Sensing. 2024; 16(7):1279. https://doi.org/10.3390/rs16071279
Chicago/Turabian StyleVlachos, Marinos, and Dimitrios Skarlatos. 2024. "Self-Adaptive Colour Calibration of Deep Underwater Images Using FNN and SfM-MVS-Generated Depth Maps" Remote Sensing 16, no. 7: 1279. https://doi.org/10.3390/rs16071279
APA StyleVlachos, M., & Skarlatos, D. (2024). Self-Adaptive Colour Calibration of Deep Underwater Images Using FNN and SfM-MVS-Generated Depth Maps. Remote Sensing, 16(7), 1279. https://doi.org/10.3390/rs16071279