1. Introduction
Bridges constitute an indispensable component of infrastructure, mandating periodic safety assessments. Traditional approaches rely on manual bridge inspections, necessitating a substantial labor force and consequently incurring significant costs. In recent years, research related to the use of unmanned aerial vehicles (UAVs) equipped with cameras has steadily increased. As per the work of Zhang et al. [
1], the automated inspection process can be delineated into three phases: data acquisition via camera-equipped UAVs, data processing through automated damage detection software, and bridge condition assessment based on the determined damages. The primary emphasis of these investigations has centered on the second phase, automated damage detection, primarily leveraging deep learning methodologies.
To ensure the optimal performance of the damage detection methods, images captured from the bridge must conform to various quality requirements. These requirements, more detailed and specified later in this work, include considerations related to resolution and the angle of view on the surface, as well as the need for sufficient overlap with adjacent images to facilitate flawless composition into a comprehensive image or 3D model of the bridge. In conventional manual flights, this objective is achieved through the acquisition of an extensive quantity of images, yet this method often leads to unnecessary redundancies, resulting in prolonged computational times for the 3D reconstruction of the bridge, increased on-site time for inspections, and even so, not consistently ensure optimal coverage. Our paper aims to develop a methodology that ensures thorough coverage of the bridge surface through the captured images. First, a method was developed to determine camera poses time efficient even for larger bridges, and therefore, numerous viewpoints. Additionally, an algorithm was developed which adds new camera poses afterwards in insufficiently covered areas to ensure a full coverage of the bridge.
Looking into prior research on viewpoint planning methods for the 3D reconstruction of large-scale objects, in general, a detailed overview is provided by Maboudi et al. [
2]. Considering the specific structure of bridges and the necessity of capturing the object from below, a more specialized research field can be delineated. Focusing especially on viewpoint planning for bridges, research is relatively scarce, with only Shang et al. [
3] providing a comprehensive overview of previous approaches. In general, three distinct methodologies for viewpoint generation can be delineated, which will be described in the following paragraphs.
In the first method, the sweep-based approach, which is already employed by UAV software providers like Site Scan [
4], Pix4D [
5], or UgCS [
6] for automated surveys, the object is traversed into a grid pattern. Camera poses are positioned based on a bounding box around the object, although they are not further adapted to the object’s geometry, and therefore, keep a high safety distance leading to low image quality. A variation by Peng et al. [
7] generates individual planes adjusted roughly to the object’s geometry, resulting in more suitable but not necessarily optimal camera positions.
In the second method, the sampling-based approach, random camera poses are generated and iteratively refined. Bircher et al. [
8] divide the object’s surface into small regions, creating a random camera pose for each, subsequently improving to neighboring poses. Shang et al. [
9] employ a similar method for generating camera poses but imposes significantly stricter constraints on the allowable space. However, this approach foregoes subsequent optimization of camera poses. In a subsequent paper [
3], Shang et al. developed a methodology for post-hoc optimization of camera poses. Another approach by Li et al. [
10] places the camera poses by the Poisson disk sampling algorithm and refines the viewpoints in a two-step optimization by minimizing the viewpoint redundancies and maximizing the model point reconstructability.
In the third method, the next-best-view (NBV) approach, camera positions are established within a certain space around the object from which a subset of usable camera poses is computed as an optimization problem. The aim here is to identify the optimal set of poses to best capture the object. Sun et al. [
11] select their candidate set based on coverage and overlap parameters, along with flight distance. Schmid et al. [
12] also factor in redundancy criteria. In this case, every surface must be viewed from at least two different camera positions from different perspectives. Hoppe et al. [
13] employ the same criteria but define conditions for the extent to which camera images must differ to ensure image triangulation. Both Schmid et al. [
12] and Hoppe et al. [
13] treat the selection of camera poses and route planning as a joint optimization problem. However, they only consider only one flight in their optimization problem, as they focus on a small number of camera poses and not on high-resolution images. While for all NBV approaches the resolution may suffice for 3D reconstruction to capture geometry, it falls short of surveying the structural integrity. A much closer survey requires a significantly higher number of camera poses, rendering optimization infeasible in terms of computational time.
Only Wang et al. [
14] present a methodology tailored to close-range aerial surveys of bridges for structural assessment. In this approach, the bridge is divided into its structural components, and camera poses are defined based on predefined patterns for these components. However, this necessitates defining each possible structural component, which may prove challenging given the diversity of bridge structures. Additionally, it presupposes the availability of a building information modeling (BIM) model of the bridge, which may not be accessible in every bridge.
We propose a methodology for the automated generation of camera poses for aerial surface inspection of bridges. We use a surface mesh of the bridge as the data basis for all calculations. Given that bridges are often situated in environments with numerous obstacles such as dense vegetation and other objects, the camera poses are generated with consideration for the surrounding context. Inadmissible camera poses are systematically replaced with others until a comprehensive coverage of the inspectable area is attained through the generated camera poses. All computations are predicated on predefined image quality criteria, UAV and camera specifications, as well as the minimum safety distance pertaining to both the bridge’s surroundings and the bridge itself. Our investigations were conducted on three distinct bridge structures. The results demonstrate that, for all bridges, near-complete coverage of the inspectable areas can be achieved, thereby ensuring the bridge inspection complies with the specified quality standards.
2. Method
2.1. Method Overview
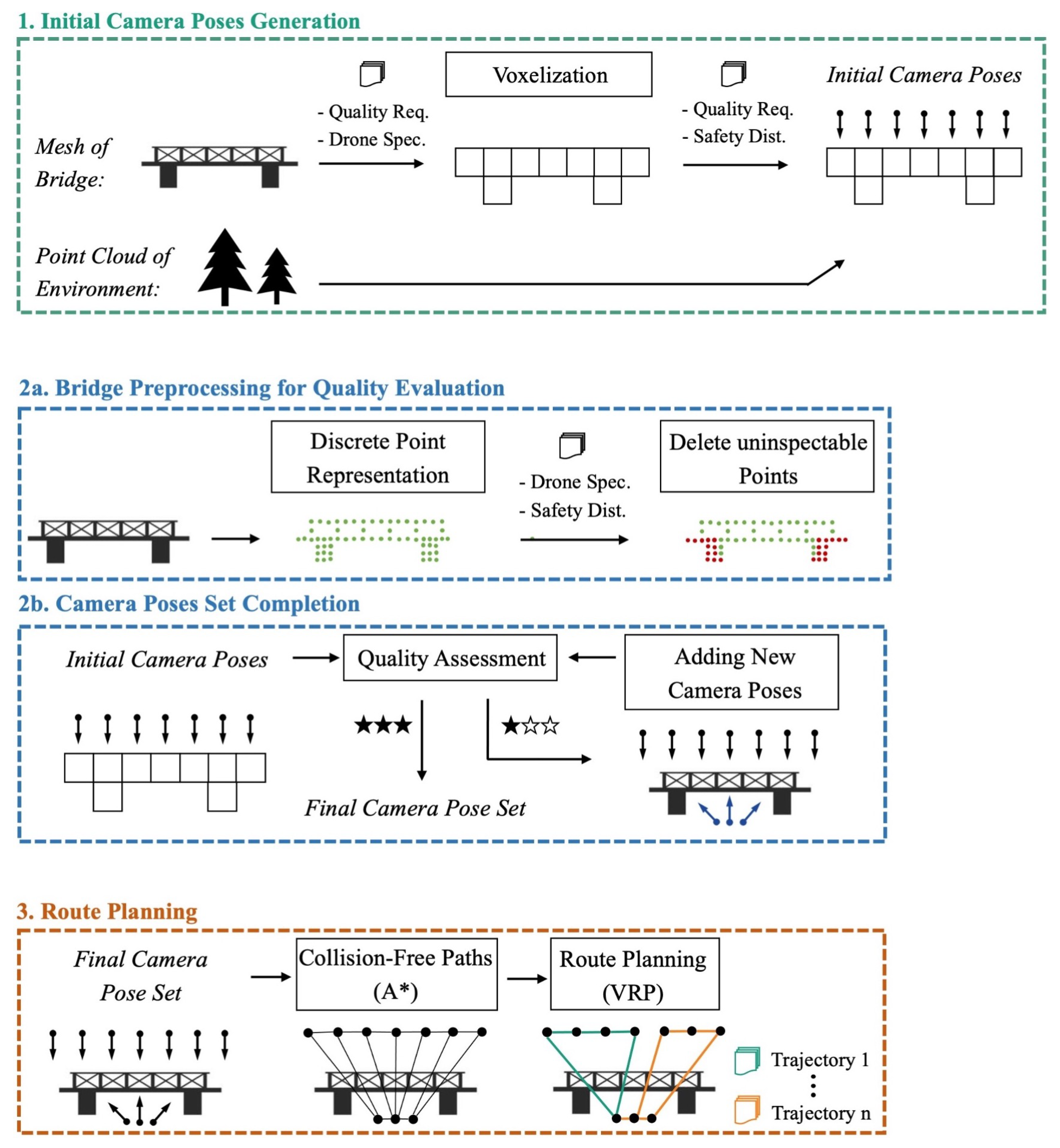
Figure 1 delineates the procedural framework of the proposed methodology. First, a voxelized representation of the bridge is calculated based on the required quality standards, both in terms of image quality and the overlap factor between individual images. Based thereon, a first set of camera poses is generated, elaborated in
Section 2.2.
To set a base for determining the regions of the bridge captured by each camera pose, the surface mesh of the bridge is discretized into points. To speed up later calculations and improve their accuracy, irrelevant points are removed. Subsequently, an evaluation is conducted to identify areas that meet the quality criteria and those requiring the generation of additional camera poses, given the removal of camera poses that fail to adhere to safety distances from the surroundings and the bridge structure. An iterative process is employed to assess coverage quality and add new camera poses until satisfactory coverage quality is achieved. The methodology developed for this purpose is detailed in
Section 2.3. Subsequently, the shortest path between individual camera poses is determined using the A* algorithm [
15], treating this network as a vehicle routing problem (VRP) to derive optimal flight routes, as discussed in
Section 2.4.
2.2. Calculation of Initial Camera Poses
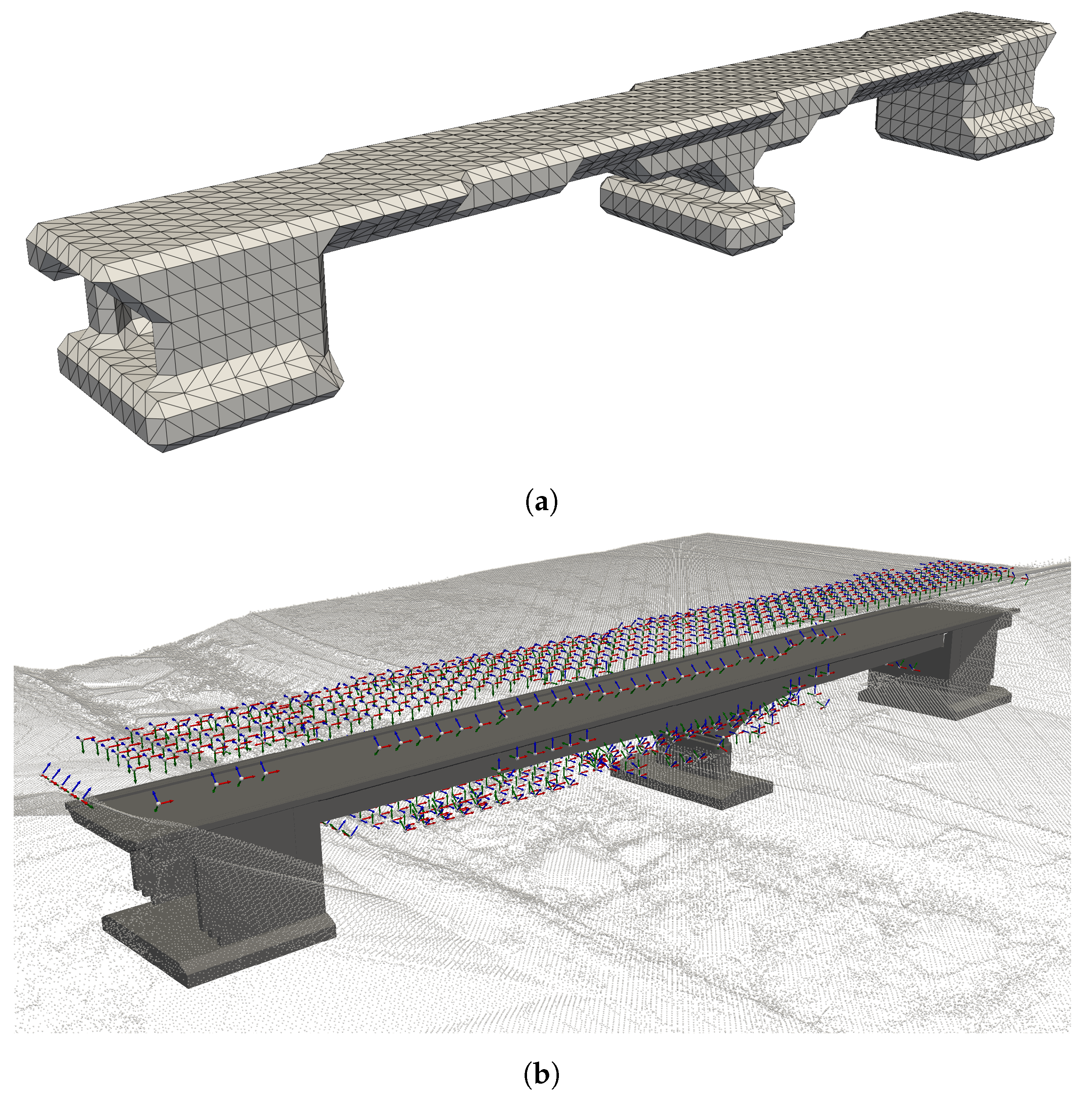
Our fundamental requirement for the computation of camera poses is the availability of a surface mesh representation of the bridge. One approach to acquiring such a mesh involves the utilization of a
mesh reconstruction algorithm, such as the Poisson surface reconstruction [
16] or Ball-Pivoting [
17] Algorithm. Both of these algorithms are applied to a point cloud of the bridge but may yield fragments in the resulting mesh when dealing with noisy or incomplete point clouds. Reconstructing the mesh from satellite imagery is possible but proves impractical due to the absence of information regarding the bridge’s underside. In our methodology, we employ a mesh obtained from bridge construction plans, as detailed by Poku et al. [
18], which results in a highly accurate model, even on the underside of the bridge.
The placement of the initial set of camera poses is approached from two distinct perspectives. Firstly, the camera poses should be distributed well along the bridge in regards to the geometrical structure of the bridge in each area to facilitate adequate image overlap and, consequently, successful image reconstruction. However, secondly, the distribution of camera poses should not be over-excessively tailored to the specific geometric characteristics of the bridge, as with a large number of cameras, an unbearable run-time follows. This goal is to adapt the cameras well enough to make the approach applicable to various bridge types while minimizing the algorithm’s computational time. These two objectives, however, inherently compete with each other.
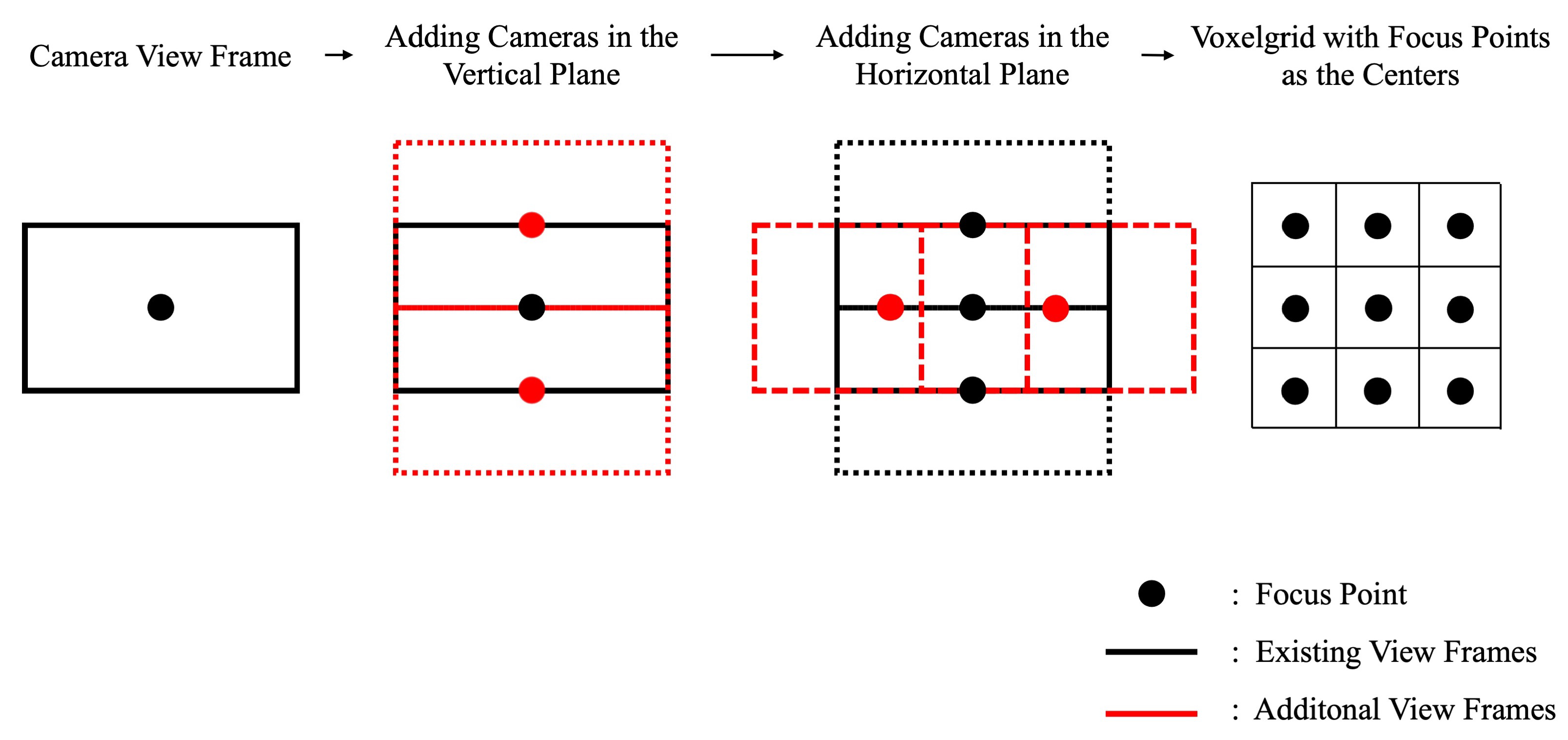
An approach, also employed by Sun et al. [
11] in aircraft flyovers, involves representing the object as voxels. This more abstract representation simplifies the object’s geometry while retaining essential information. The size of the voxels is determined based on various parameters, taking into account the image resolution quality requirements and the specifications of the UAV camera. The specific values used are listed in
Table A1.
From the desired ground sampling distance (GSD), the necessary distance between the UAV and the object can be calculated as
with the focal length and sensor width specified in millimeters and the image width given in pixels. The GSD is expressed as millimeters per pixel. The area covered on the bridge can be determined by:
The distance, as defined in Equation (
1), is expressed in meters. It is important to note that the calculated image area is an approximation, as the equation does not account for uneven surfaces and camera effects such as distortion. To reconstruct a point, images from three perspectives are required [
19,
20]. This necessitates an overlap of the image areas. Given that in most cameras the image area is typically wider horizontally than vertically, it is prudent to define an overlap factor for the vertical dimension. Ideally, the vertical overlap should also be set to a minimum of 50% to ensure complete 3D reconstruction [
21]. The horizontal overlap is determined by the distance between the focal points in the vertical direction. The calculation of the voxel size is illustrated schematically in
Figure 2.
The equation for calculating the voxel size results as follows:
Placing the camera poses on the voxelized mesh raises the problem that images acquired at the edges of the bridge would be oriented at a 90° angle to each other, resulting in a lack of image overlap and, consequently, making the reconstruction process significantly challenging. To address this issue, we employ the marching cubes algorithm [
22] on the voxelized bridge, which changes the object’s edges to a 45° angle relative to each other, facilitating the reconstruction process.
2.3. Creating Additional Camera Poses in Uncovered Areas
The initially placed cameras ideally already cover a significant portion of the bridge with high quality. However, by removing cameras that do not adhere to safety distances, it is unlikely that all inspectable areas are fully captured. Therefore, in the subsequent steps, the initial camera poses are supplemented with additional poses.
2.3.1. Preprocessing for Quality Evaluation
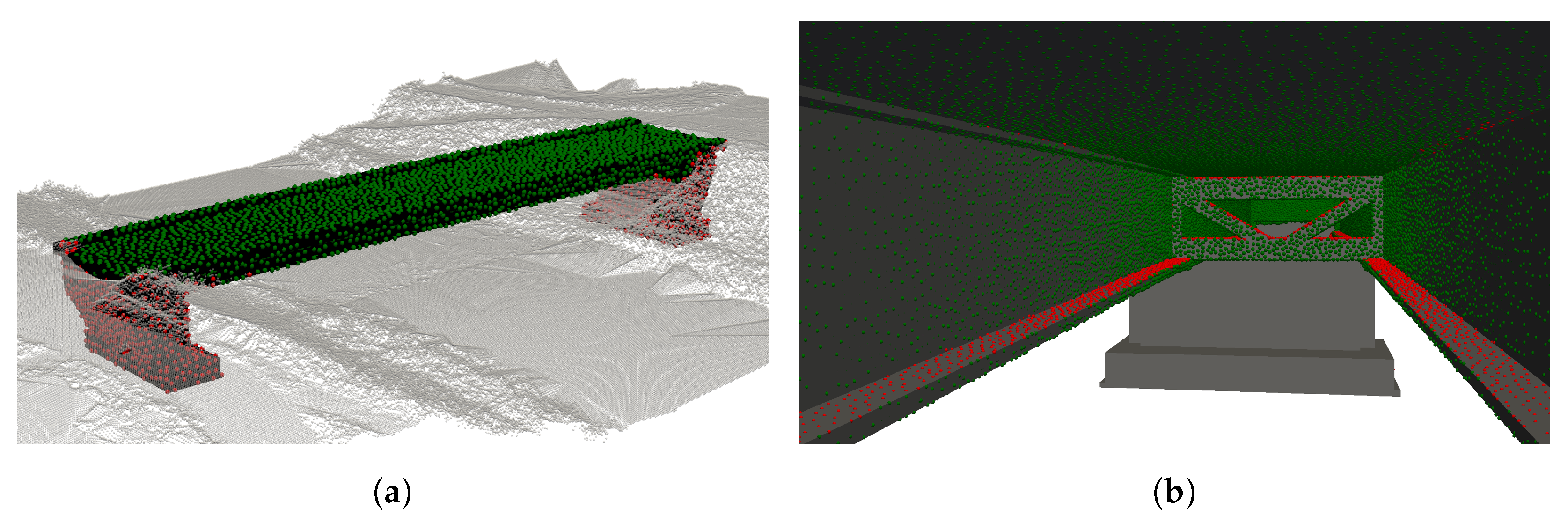
To assess the generated camera poses, evenly distributed points are created over the bridge surface using the Poisson-disk sampling algorithm. These points serve as the basis for evaluating the surface coverage at these locations. In our study, we examined point sets with varying inter-point distances, as depicted in
Figure 3. We selected a maximum average distance of 10 cm between the points, as by exceeding this value the points would not adequately represent the object’s geometry. A finer distribution of points is not recommended, as the number of points increases quadratically, resulting in a significant increase in computational time. The bridge models, such as those from [
18], include foundation structures located beneath the ground surface, making them inaccessible for inspection. To obtain more meaningful results and reduce the runtime of the algorithm, non-visible surface points of the bridge are removed.
The remaining points are visible through manual inspection, but not necessarily by UAV flights. In some areas of the bridge, it may be impossible to find a feasible camera pose to capture a surface point without violating the necessary safety distances. To prevent the algorithm, described in
Section 2.3.3, from attempting to create new camera poses for non-inspectable points, these points are also eliminated from the set of surface points. Inspectable points are determined by densely generating potential camera positions along the perimeter of the no-fly zone. If a surface point is visible from a camera position within the specified maximum incident angle constraints, it is deemed inspectable. Conversely, if no potential camera position can view the point, it is considered non-inspectable. The possible camera positions are generated while accounting for safety distances from the bridge and its surroundings.
Figure 4 illustrates both, not visible and not inspectable points.
The final set of points comprises both visible and inspectable points on the bridge surface. This enables more reliable assessments of the algorithm’s coverage percentage while simultaneously reducing run-time through a smaller number of surface points. However, it is important to note that the inspectability of a point does not automatically guarantee its complete reconstruction. Although a point is classified as inspectable if it is visible from at least one camera, a successful reconstruction typically requires images from multiple distinct perspectives. Even so, due to the substantial number of surface points, such an extensive verification process is impractical to implement.
2.3.2. Evaluating Point Reconstruction Quality
The evaluation of the surface points is based on fundamental principles that must be considered for 3D reconstruction [
3]:
- Principle 1:
Every point on the surface must be captured by at least two [
23], and for sparsely textured surfaces, three high-quality images [
19,
20].
- Principle 2:
Small angles between individual images can lead to triangulation errors in depth interpretation [
7].
- Principle 3:
Redundant images are uninformative and do not increase the reconstruction quality but only the computation time [
3].
Based on these fundamental principles, points are categorized. If a point satisfies the first two principles, meaning it is observed from at least three different positions, each with distinct incident angles, the point is considered captured. A point satisfies the first principle, if the points are within the focus range of the drone camera and a maximum angle of 65° between the camera view direction and the surface exists. For the second principle a minimum angle of 15° has to be between each of the three cameras relative to the others [
7]. Once a point is seen by three or more camera poses, each within the quality angle requirements it is not further considered for subsequent calculations, as dictated by principle 3. Consequently, this approach allows for a significant reduction in both the reconstruction run-time and the computational time of the subsequent algorithm for calculating additional camera poses. The calculations are conducted solely based on the points that have not yet been completely captured, leading to a substantial reduction in the run-time without compromising quality.
2.3.3. Camera Pose Placement Algorithm
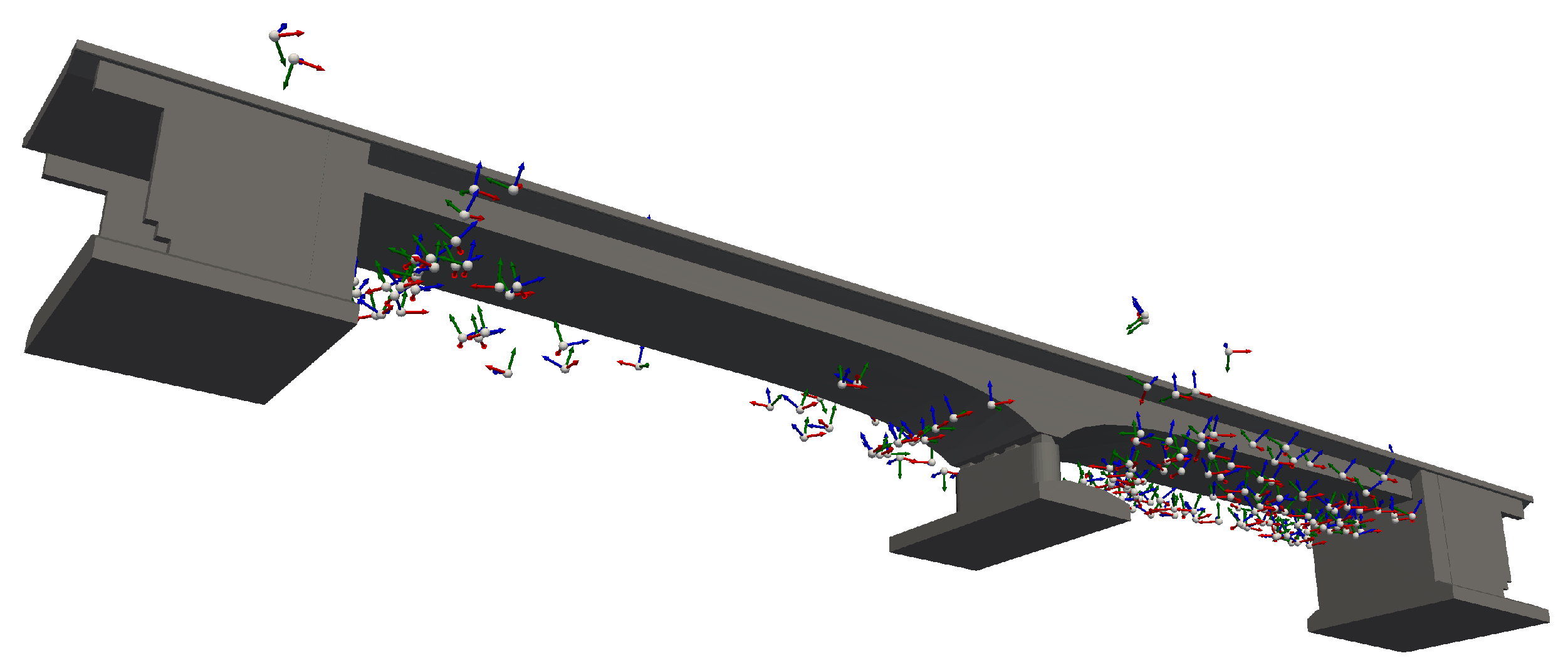
For areas where the coverage of the bridge is not yet complete, new camera poses are generated. The process is divided into three stages: grouping of points, with a new camera pose added for each group. Subsequently, the camera poses are improved in their position and lastly orientation. The process is schematically depicted in
Figure 5.
The points are grouped based on voxels, with the bridge area being segmented and points sharing the same voxel clustered together. Empirical tests into the most efficacious voxel sizes were undertaken, culminating in the selection of a voxel size twice that which was employed for the voxels delineated in
Section 2.2. A distinct camera pose is generated for each voxel group. The camera poses position is established emanating from the center of the points utilizing the normal vector of the center. The calculated GSD serves as the distance with the camera’s orientation directed towards the central coordinates of the points to ensure focused alignment.
The new camera may be situated in a non-flyable area or may not be optimally placed yet for the group of points. Therefore, variations of the camera position are created, with the camera focus always remaining on the center of the points, and the pose with the highest quality is selected. To avoid creating camera poses that are too similar to existing ones, new poses within close proximity to another pose with a viewing direction deviation of less than 15° are not allowed. The evaluation of the camera quality is based on the assessment of the distance to the points as well as the incident angle. The equation for calculating camera quality is
with
representing the set of points in a voxel. The evaluation of the camera-point quality
is derived from Shang et al. [
3] and incorporates, in addition to weighting the factors of distance
and incident angle
through parameter
w, the normalization and saturation of both factors.
The adjustment in the camera position is limited in relation to the points within the corresponding voxel, preventing the convergence of camera poses towards a singular point with minimal coverage and, consequently, a higher reachable
Q score. Instead, the optimization occurs at a local level for each voxel, as visualized in
Figure 5a. Following the refinement in position, a global enhancement of the camera poses’ viewing directions takes place, involving all as-yet-uncovered points. This strategic approach, illustrated in
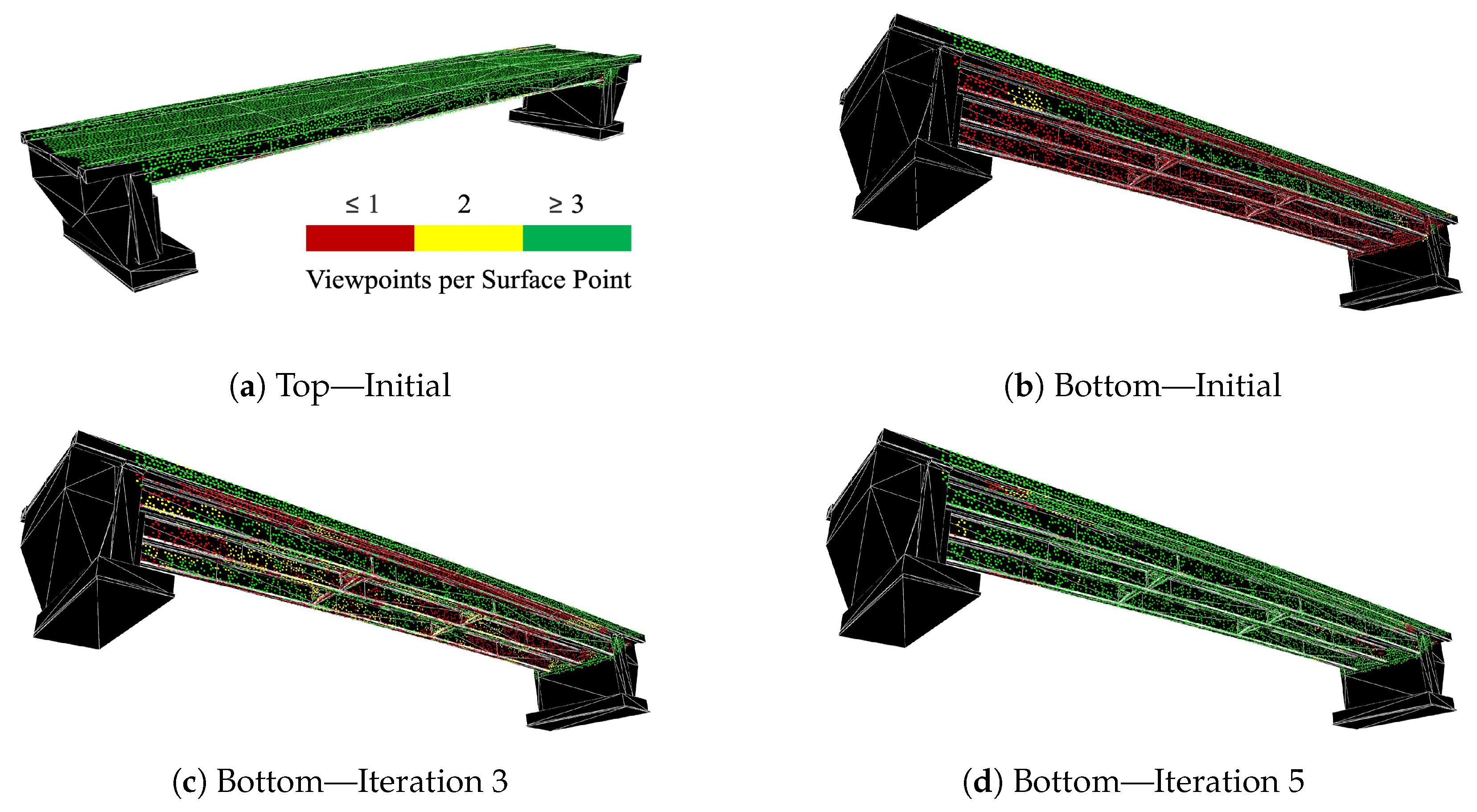
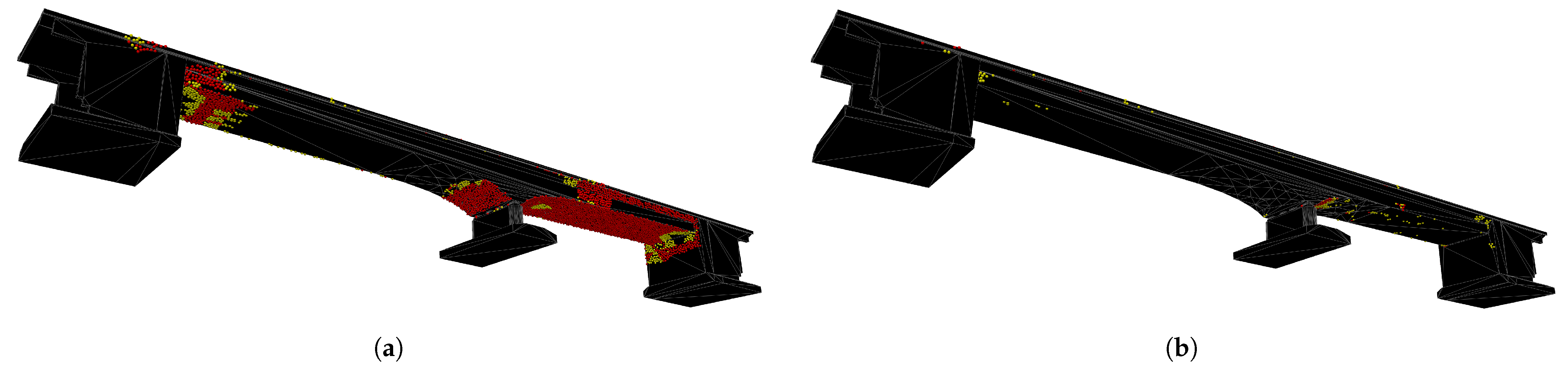
Figure 5b, aims to focus the camera poses on localized hotspots. The newly derived camera poses are added to the existing set, prompting a reassessment of points. The iterative repetition of this process continues until comprehensive coverage is achieved for those points that remain incompletely captured.
2.4. Path Planning and Route Optimization
The determination of the optimal trajectory, using the calculated camera positions as waypoints, is accomplished through the formulation of a VRP. This formulation places constraints on the flight duration based on the UAV’s battery capacity, for which the following specifications are defined:
- Specification 1:
The battery capacity is set to a maximum of 80% of its actual capacity.
- Specification 2:
Three seconds are added at each waypoint to account for reduced speed before and after the waypoint, as well as the time required for capturing images.
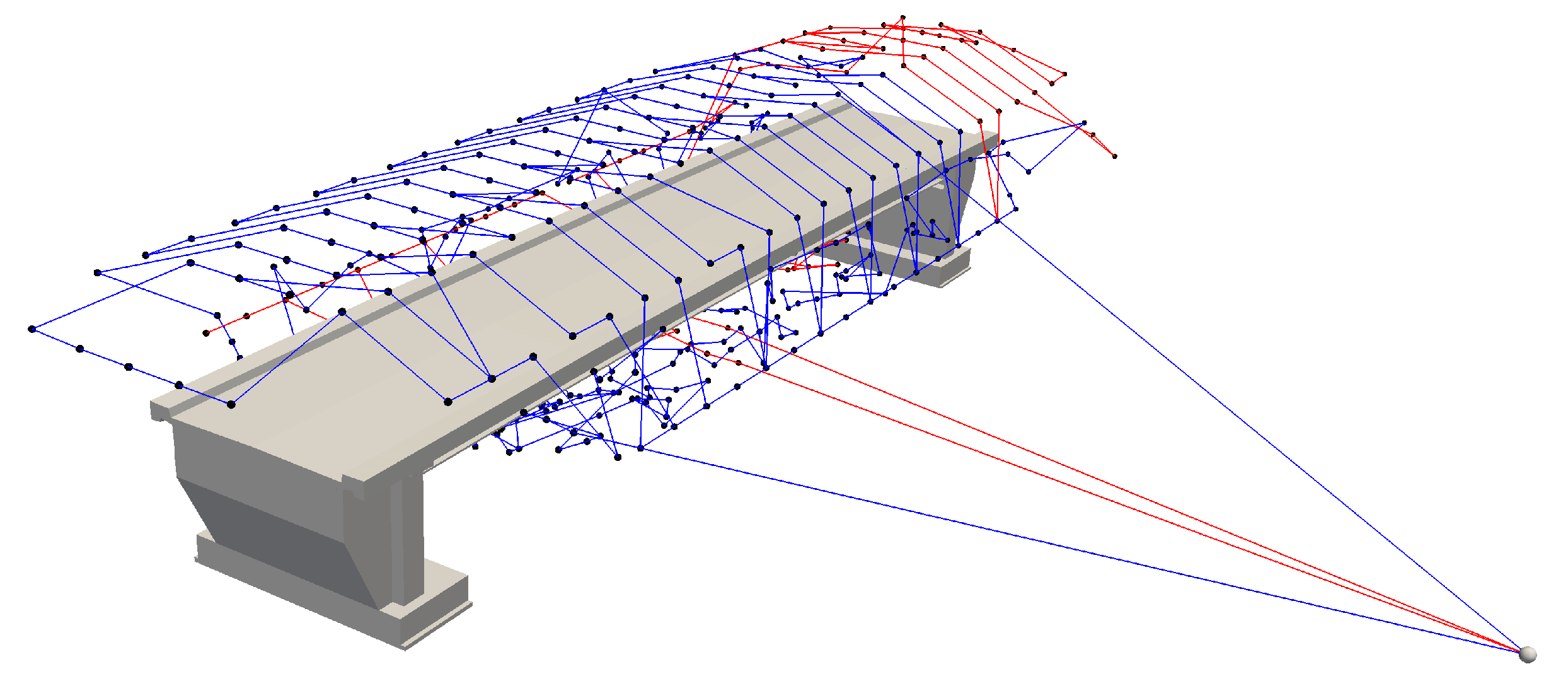
The connections between waypoints are computed using the A* algorithm. As A* is a graph-based algorithm, the first step involves constructing a network. This is achieved by evenly distributing points on a slightly expanded mesh within the permissible flying area around the bridge, representing the network nodes. The choice of point density has a direct impact on the optimality of the computed route, but it also affects the network’s size and computational time. Edges are established between nodes if the connection between points does not intersect restricted airspace. Additionally, each camera position is connected to all directly accessible network nodes. In the subsequently generated network, the shortest path is computed between each pair of camera poses by the A* algorithm.
The connections between camera positions, determined through A*, form the basis for defining the VRP. Distances between camera positions are converted into flight times. The optimization problem is then solved using the open-source library OR-Tools, developed by Google AI [
24].
4. Conclusions
This paper explores the possibility of automating the UAV camera pose generation for bridges to generate high-resolution images necessary for digital damage inspection and 3D reconstruction to overcome time and labor-consuming manual inspection.
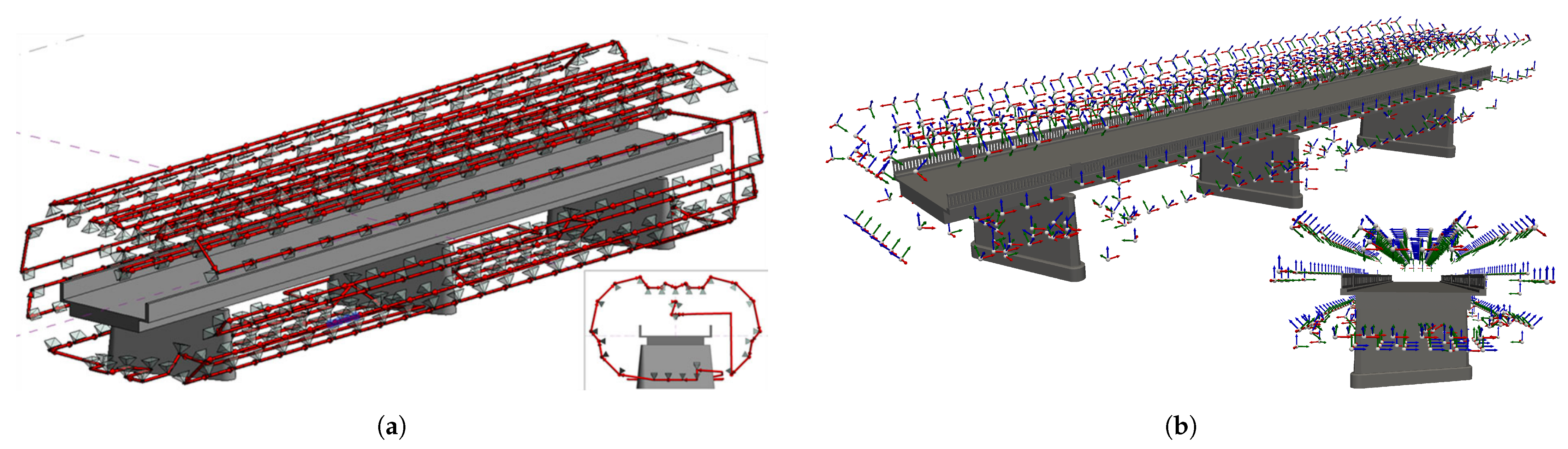
Camera poses are generated based on a voxelized mesh with the size of the voxels calculated from quality requirements and camera specifications with poses being checked for their safety distances to the bridge and the surroundings where disallowed camera poses are removed. The hereby unscanned areas were approached by a second algorithm with inadequately covered areas being grouped and new camera poses then being created and optimized in their position and orientation to the uncovered points. The process was iteratively repeated until complete coverage of the bridge was achieved.
The methodology was applied to three different bridges with varying structural components to validate the general applicability of the developed approach. Almost complete coverage was achieved for all three bridges. The voxel-based approach offers a significant advantage, especially for large bridges, as the majority of the bridge can be covered computationally efficiently with camera poses still tailored well to the geometry of the bridge in each area. The placement of additional cameras in incompletely covered areas is computationally intensive, and therefore, sensible only as a complement to voxel-based placement. However, applying this algorithm significantly increases the coverage for all three bridges, achieving almost maximum coverage of inspectable points. Complete coverage is practically impossible, as each point must be captured from three different positions, which is not achievable for every point.
Overall, this paper, through the combination of a computationally efficient, voxel-based method and individual placement of additional cameras in uncovered areas, provides the opportunity to calculate optimal camera poses for high-resolution 3D reconstruction and damage detection, even for large bridges. The inclusion of the bridge environment elevates the study to a practically applicable level, especially since many bridges are located in densely vegetated surroundings.
A potential improvement for this approach in future work lies in the improvement of the first voxel-based camera pose placement. In this study, poses based on voxels were not further optimized. However, for curved bridges, discontinuities arise along the voxelized mesh, causing sub-optimal orientation of camera poses to the bridge. A post-adjustment may here be beneficial. If a BIM-model of the bridge is available, a combination of our approach with Wang et al. [
14] could be of interest, where, instead of the voxel-based approach, cameras are placed according to Wang et al., and for areas where camera poses were not placed due to safety distances, additional cameras could be generated using our second algorithm.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}

















