
Improved Weed Detection in Cotton Fields Using Enhanced YOLOv8s with Modified Feature Extraction Modules
Abstract
1. Introduction
- We propose an improved cotton field weed detection model EY8-MFEM to address real-time and efficient issues such as diverse target scales and occlusion of crops and weeds during the growth cycle during the detection process.
- To emphasize crucial feature information, we introduce the ALGA module, which evaluates both local and global information within the feature map to generate an attention matrix. This approach enhances the focus on and utilization of spatial information within the feature map.
- We’ve introduced the C2F-ALGA module with the aim of enhancing the feature extraction capacity of the backbone network. This module facilitates the adaptive fusion of local and global features, enabling the model to capture local details and global contextual information in images more effectively.
- We introduce the MDPM module, designed to selectively extract and leverage horizontal and vertical information from feature maps. It generates attention matrices to enhance the model’s awareness of spatial structure and diverse directional features.
2. Related Work
2.1. Weed Detection
2.2. YOLO Algorithm
2.3. Attention
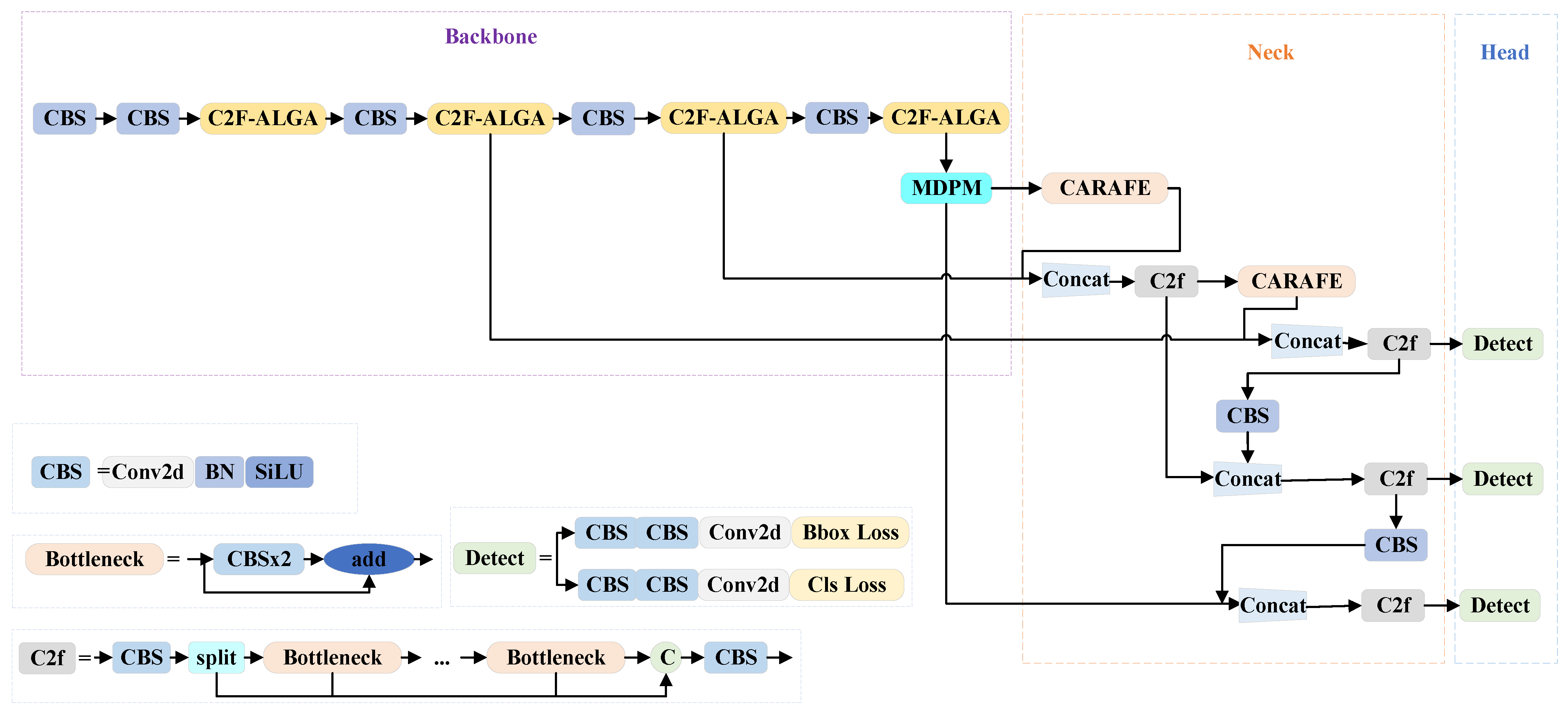
3. Proposed Method
3.1. Model
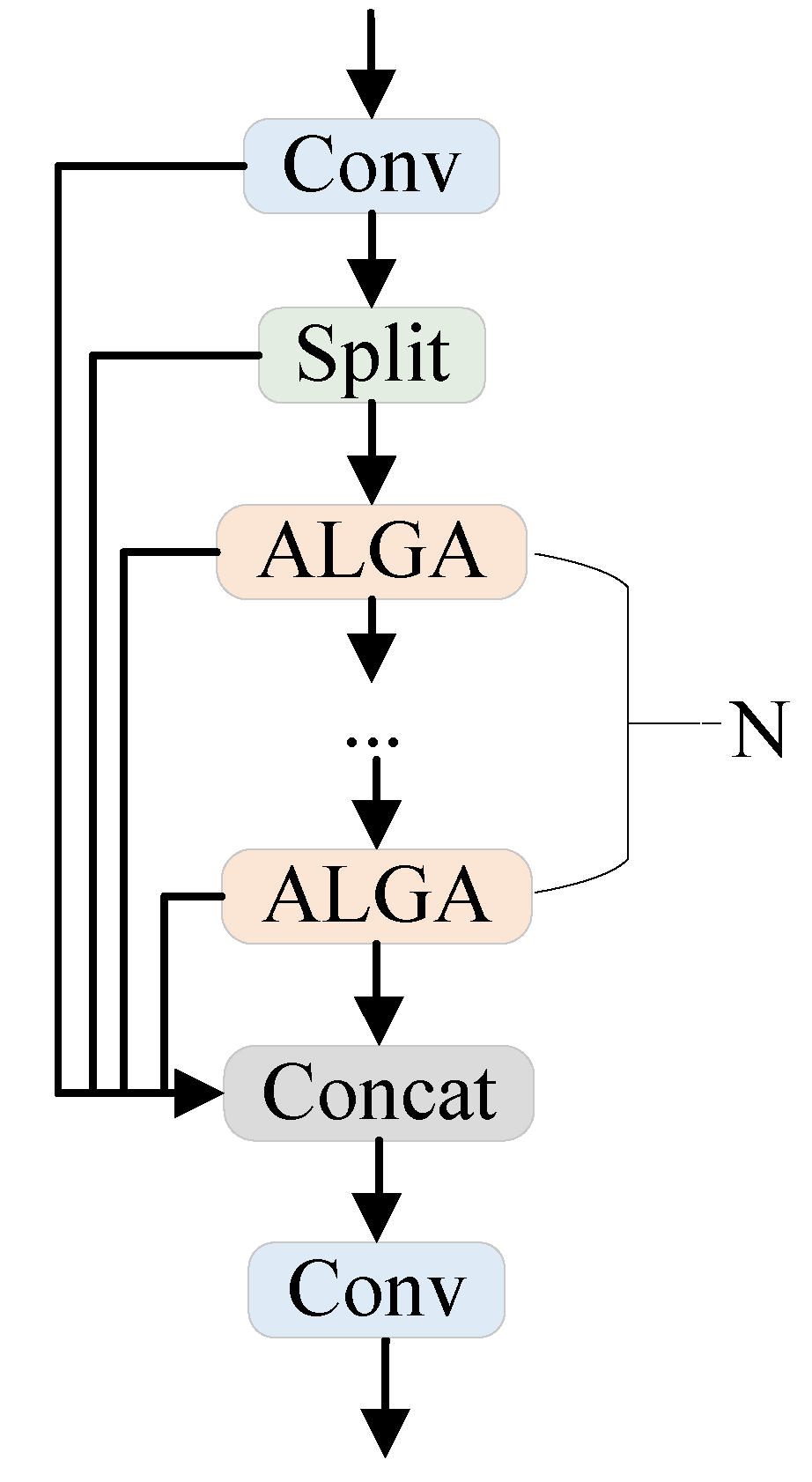
3.2. Adaptive Local–Global Attention & C2F-ALGA
3.2.1. Adaptive Local–Global Attention
3.2.2. C2F-ALGA
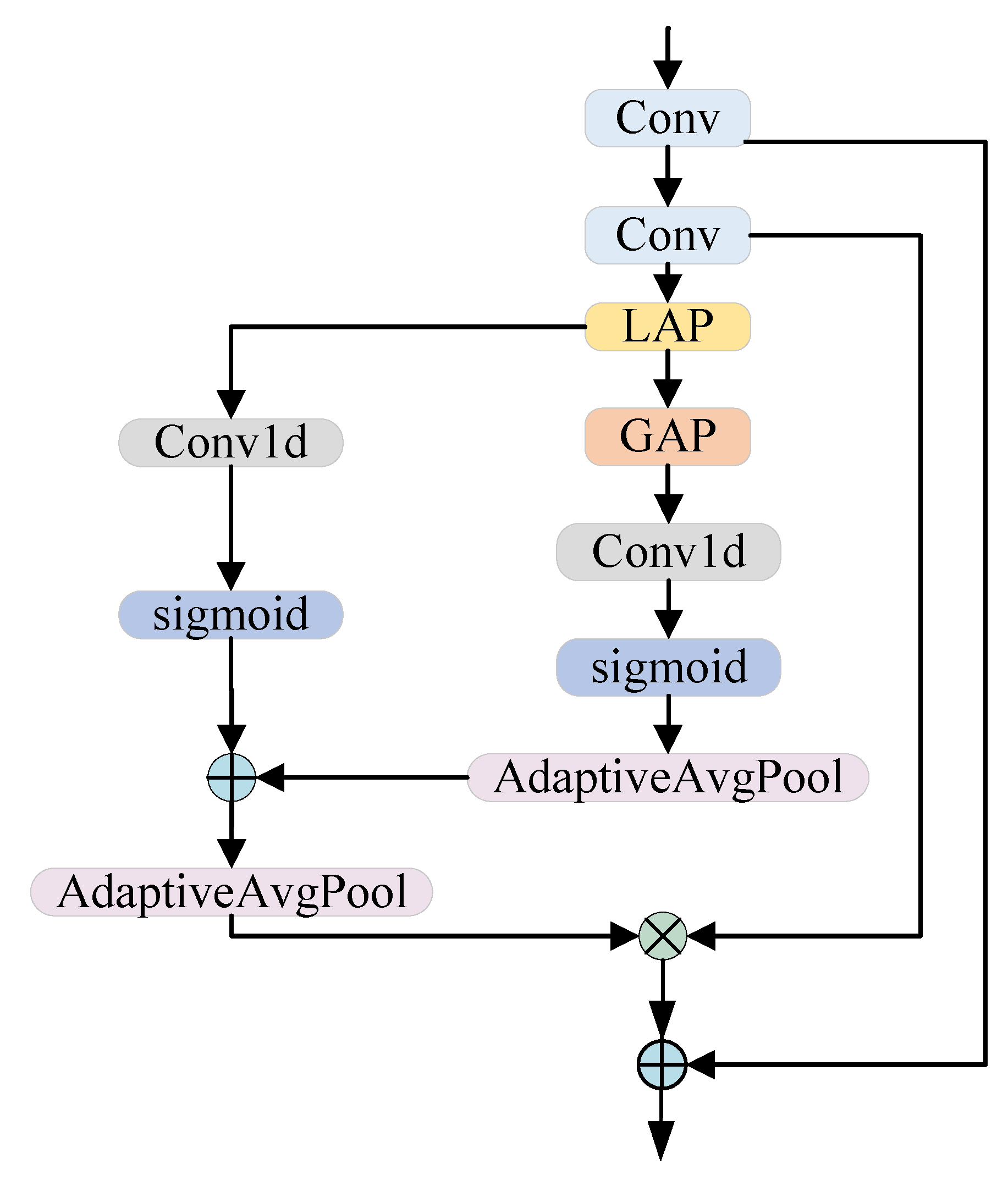
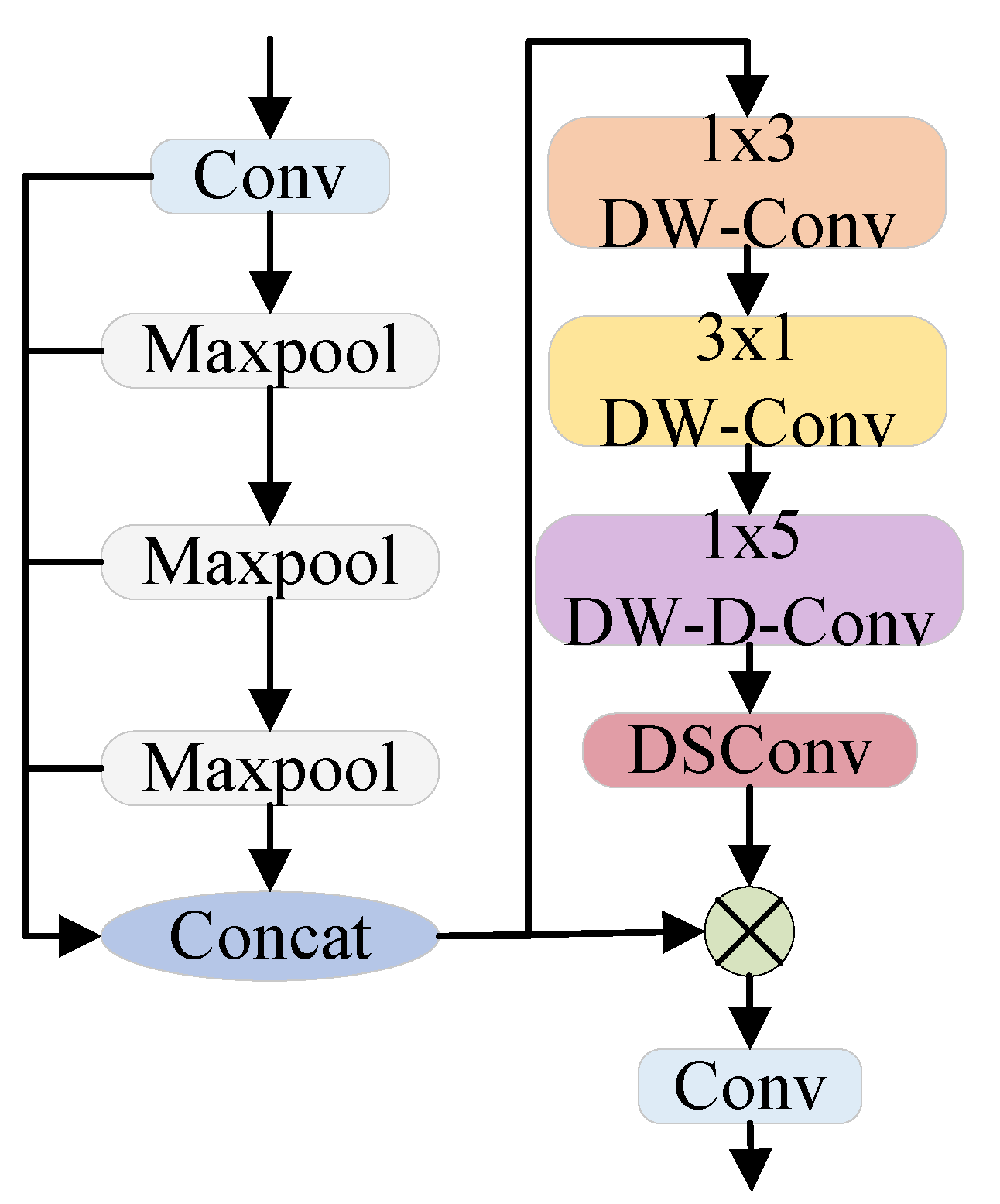
3.3. Multi-Scale Directional Perception Module
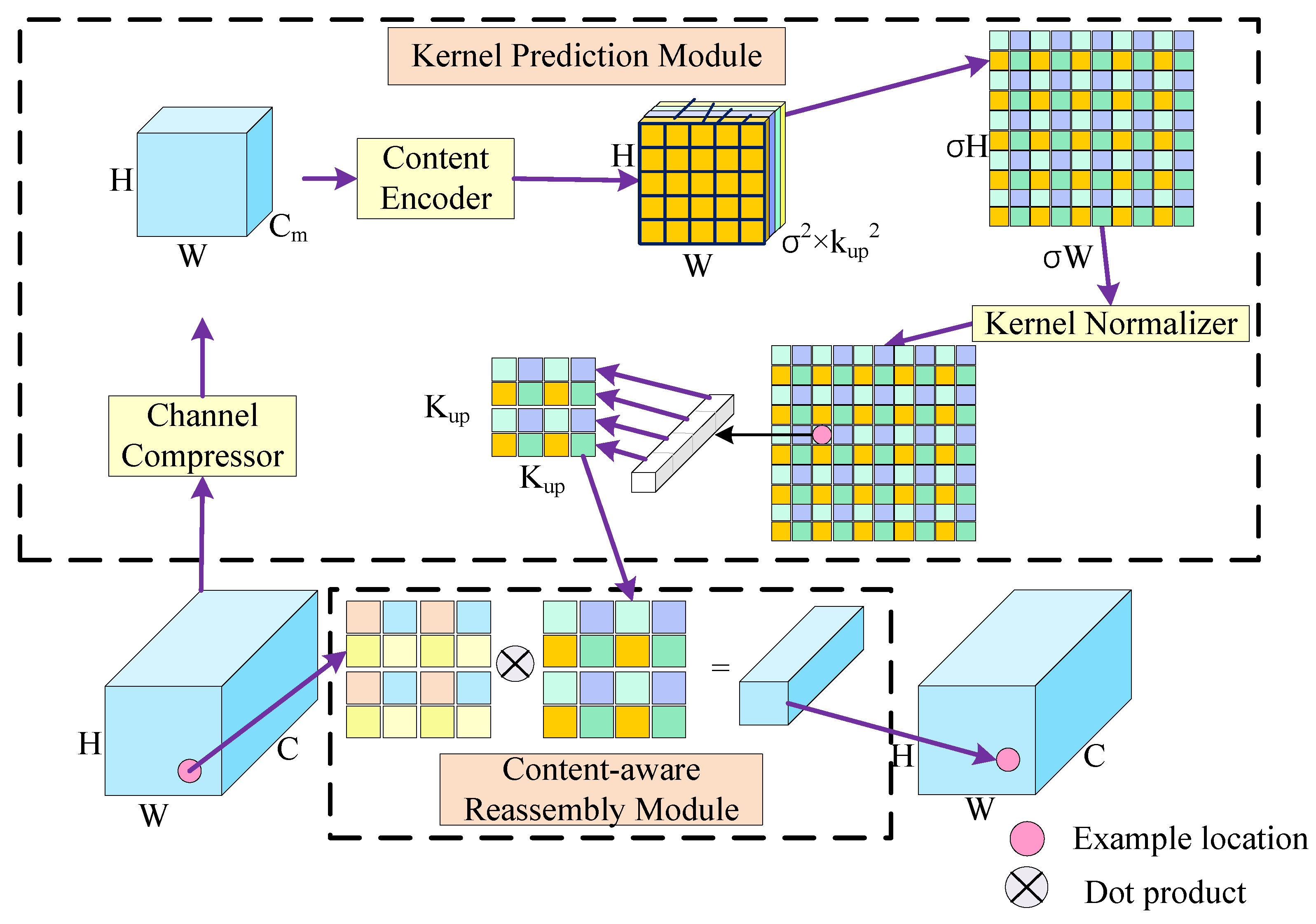
3.4. CARAFE
4. Experiment
4.1. Implementation
4.2. Datasets
4.3. Ablation Experiment
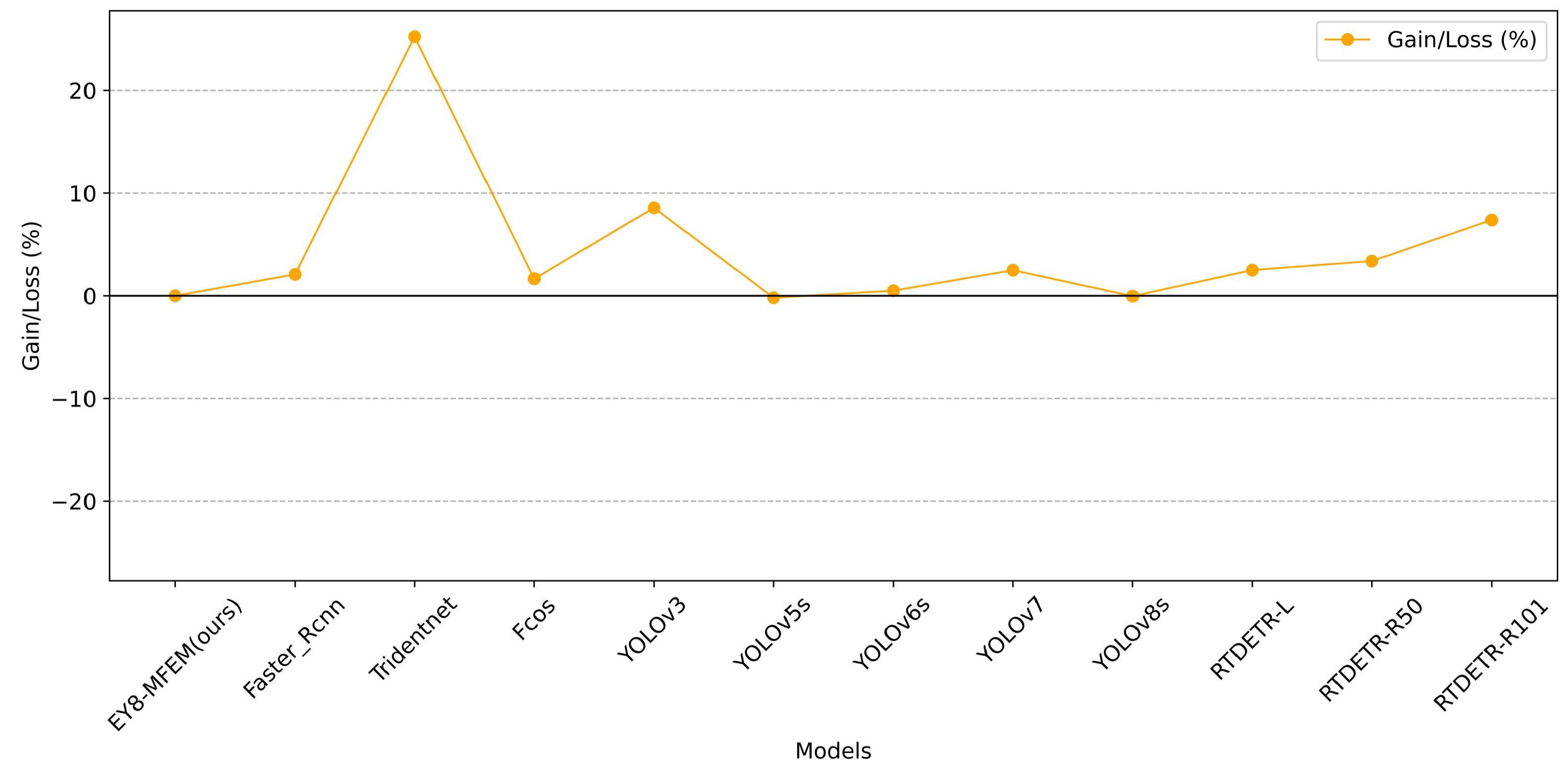
4.4. Compared with Other Methods
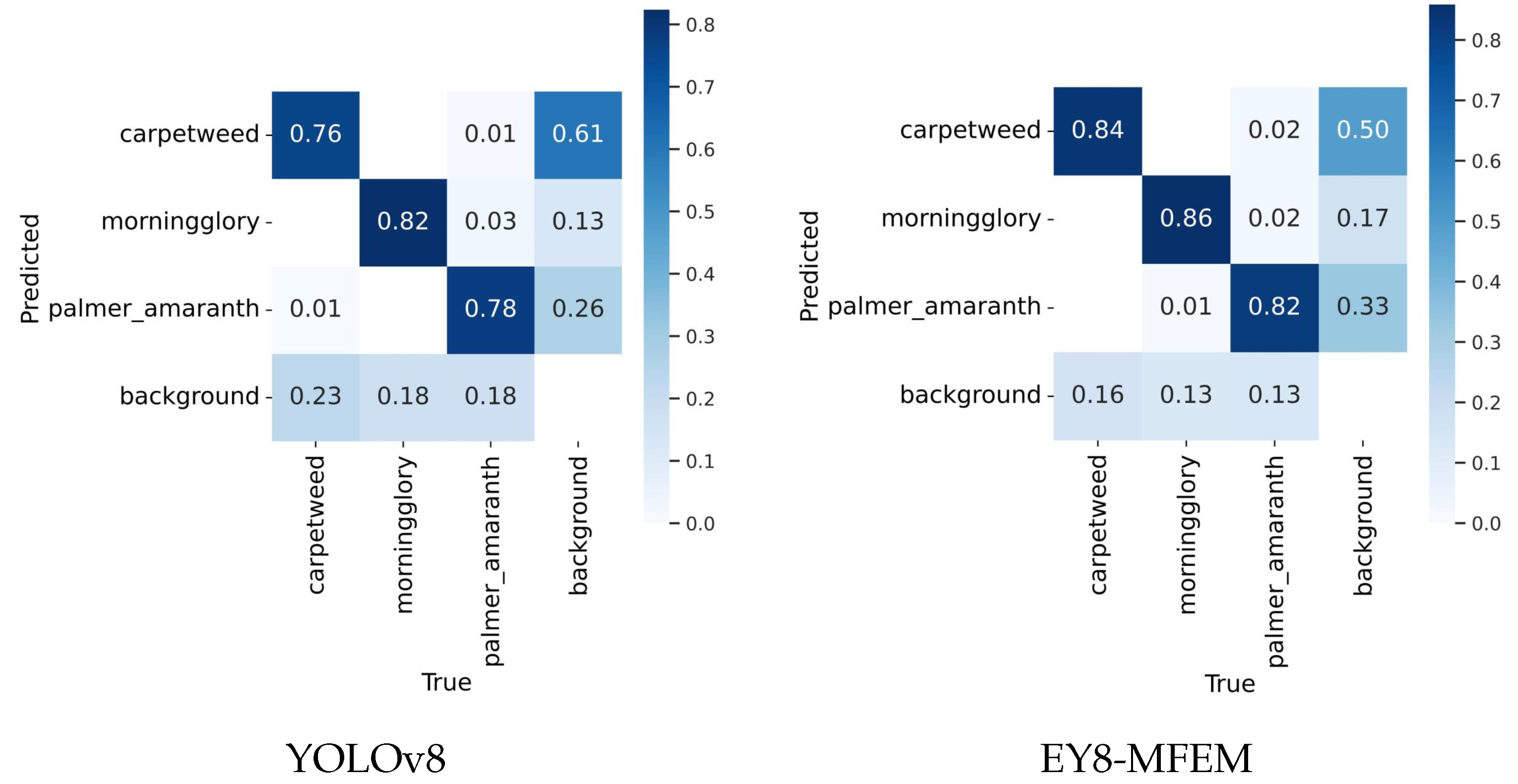
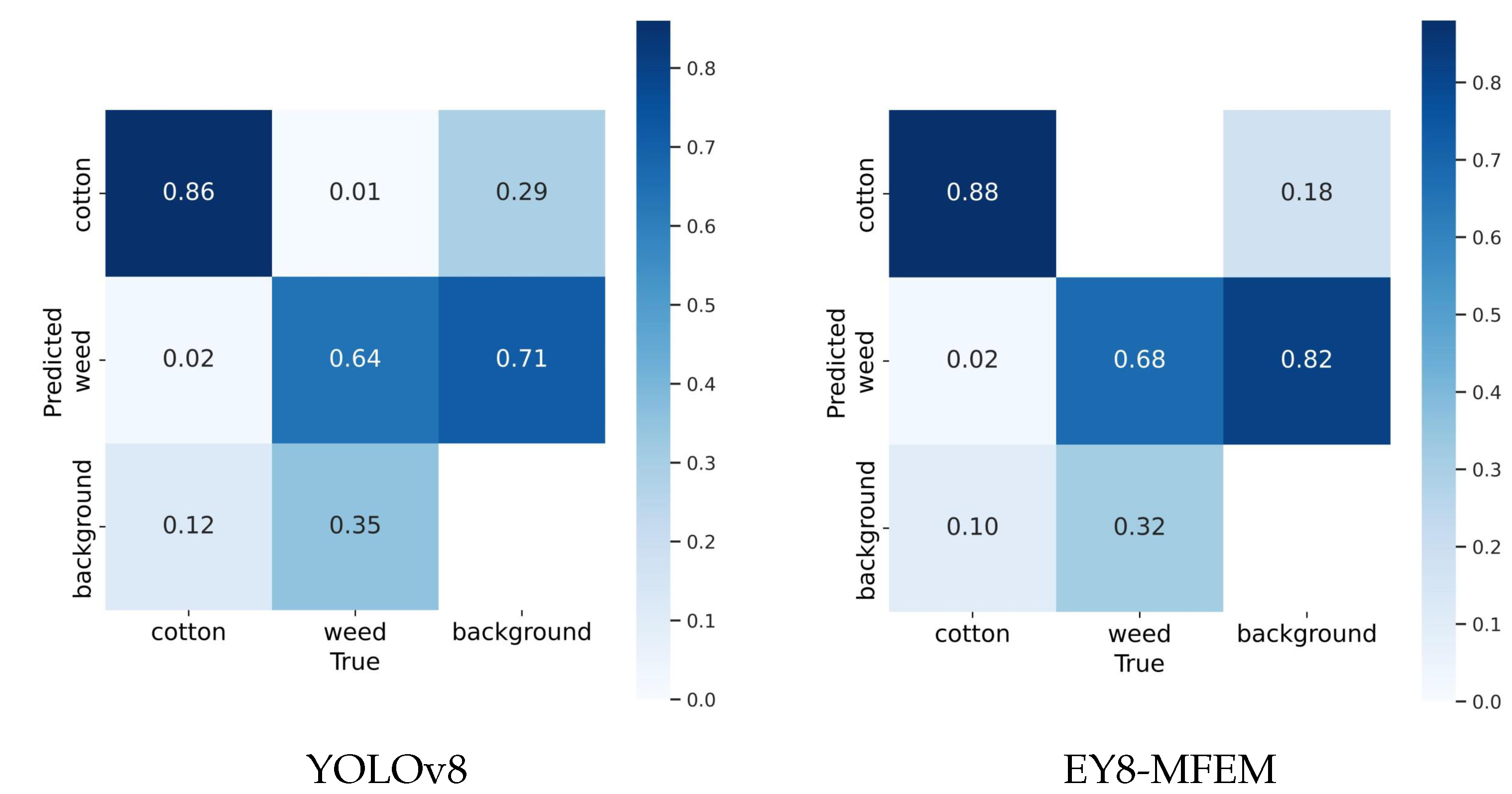
4.5. Visualization
5. Conclusions and Future Work
5.1. Conclusions
5.2. Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Kwaghtyo, D.K.; Eke, C.I. Smart farming prediction models for precision agriculture: A comprehensive survey. Artif. Intell. Rev. 2023, 56, 5729–5772. [Google Scholar] [CrossRef]
- Phang, S.K.; Chiang, T.H.A.; Happonen, A.; Chang, M.M.L. From Satellite to UAV-based Remote Sensing: A Review on Precision Agriculture. IEEE Access 2023, 11, 127057–127076. [Google Scholar] [CrossRef]
- Zhou, R.; Yin, Y. Digital agriculture: Mapping knowledge structure and trends. IEEE Access 2023, 11, 103863–103880. [Google Scholar] [CrossRef]
- Iqbal, N.; Manalil, S.; Chauhan, B.S.; Adkins, S.W. Investigation of alternate herbicides for effective weed management in glyphosate-tolerant cotton. Arch. Agron. Soil Sci. 2019, 65, 1885–1899. [Google Scholar] [CrossRef]
- Liu, B.; Bruch, R. Weed detection for selective spraying: A review. Curr. Robot. Rep. 2020, 1, 19–26. [Google Scholar] [CrossRef]
- Raja, R.; Slaughter, D.C.; Fennimore, S.A.; Siemens, M.C. Real-time control of high-resolution micro-jet sprayer integrated with machine vision for precision weed control. Biosyst. Eng. 2023, 228, 31–48. [Google Scholar] [CrossRef]
- Eide, A.; Koparan, C.; Zhang, Y.; Ostlie, M.; Howatt, K.; Sun, X. UAV-assisted thermal infrared and multispectral imaging of weed canopies for glyphosate resistance detection. Remote Sens. 2021, 13, 4606. [Google Scholar] [CrossRef]
- Chen, Y.; Wu, Z.; Zhao, B.; Fan, C.; Shi, S. Weed and corn seedling detection in field based on multi feature fusion and support vector machine. Sensors 2020, 21, 212. [Google Scholar] [CrossRef] [PubMed]
- Li, X.; Duan, F.; Hu, M.; Hua, J.; Du, X. Weed Density Detection Method Based on a High Weed Pressure Dataset and Improved PSP Net. IEEE Access 2023, 11, 98244–98255. [Google Scholar] [CrossRef]
- Moazzam, S.I.; Khan, U.S.; Qureshi, W.S.; Tiwana, M.I.; Rashid, N.; Alasmary, W.S.; Iqbal, J.; Hamza, A. A patch-image based classification approach for detection of weeds in sugar beet crop. IEEE Access 2021, 9, 121698–121715. [Google Scholar] [CrossRef]
- Wang, Q.; Cheng, M.; Huang, S.; Cai, Z.; Zhang, J.; Yuan, H. A deep learning approach incorporating YOLO v5 and attention mechanisms for field real-time detection of the invasive weed Solanum rostratum Dunal seedlings. Comput. Electron. Agric. 2022, 199, 107194. [Google Scholar] [CrossRef]
- Wang, B.; Yan, Y.; Lan, Y.; Wang, M.; Bian, Z. Accurate detection and precision spraying of corn and weeds using the improved YOLOv5 model. IEEE Access 2023, 11, 29868–29882. [Google Scholar] [CrossRef]
- Wan, D.; Lu, R.; Shen, S.; Xu, T.; Lang, X.; Ren, Z. Mixed local channel attention for object detection. Eng. Appl. Artif. Intell. 2023, 123, 106442. [Google Scholar] [CrossRef]
- Sheng, W.; Shen, J.; Huang, Q.; Liu, Z.; Lin, J.; Zhu, Q.; Zhou, L. Symmetry-Based Fusion Algorithm for Bone Age Detection with YOLOv5 and ResNet34. Symmetry 2023, 15, 1377. [Google Scholar] [CrossRef]
- Wang, J.; Chen, K.; Xu, R.; Liu, Z.; Loy, C.C.; Lin, D. Carafe: Content-aware reassembly of features. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 3007–3016. [Google Scholar]
- Sheffield, K.J.; Clements, D.; Clune, D.J.; Constantine, A.; Dugdale, T.M. Detection of aquatic alligator weed (Alternanthera philoxeroides) from aerial imagery using random forest classification. Remote Sens. 2022, 14, 2674. [Google Scholar] [CrossRef]
- Naveed, A.; Muhammad, W.; Irshad, M.J.; Aslam, M.J.; Manzoor, S.M.; Kausar, T.; Lu, Y. Saliency-Based Semantic Weeds Detection and Classification Using UAV Multispectral Imaging. IEEE Access 2023, 11, 11991–12003. [Google Scholar] [CrossRef]
- Xu, B.; Fan, J.; Chao, J.; Arsenijevic, N.; Werle, R.; Zhang, Z. Instance segmentation method for weed detection using UAV imagery in soybean fields. Comput. Electron. Agric. 2023, 211, 107994. [Google Scholar] [CrossRef]
- Chen, J.; Wang, H.; Zhang, H.; Luo, T.; Wei, D.; Long, T.; Wang, Z. Weed detection in sesame fields using a YOLO model with an enhanced attention mechanism and feature fusion. Comput. Electron. Agric. 2022, 202, 107412. [Google Scholar] [CrossRef]
- Peng, H.; Li, Z.; Zhou, Z.; Shao, Y. Weed detection in paddy field using an improved RetinaNet network. Comput. Electron. Agric. 2022, 199, 107179. [Google Scholar] [CrossRef]
- Arsa, D.M.S.; Ilyas, T.; Park, S.H.; Won, O.; Kim, H. Eco-friendly weeding through precise detection of growing points via efficient multi-branch convolutional neural networks. Comput. Electron. Agric. 2023, 209, 107830. [Google Scholar] [CrossRef]
- Punithavathi, R.; Rani, A.D.C.; Sughashini, K.; Kurangi, C.; Nirmala, M.; Ahmed, H.F.T.; Balamurugan, S. Computer Vision and Deep Learning-enabled Weed Detection Model for Precision Agriculture. Comput. Syst. Sci. Eng. 2023, 44, 2759–2774. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Jocher, G. Ultralytics YOLOv5. 2020. Available online: https://doi.org/10.5281/zenodo.3908559 (accessed on 16 March 2024).
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A single-stage object detection framework for industrial applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar]
- Jocher, G.; Chaurasia, A.; Qiu, J. Ultralytics YOLOv8. 2023. Available online: https://github.com/ultralytics/ultralytics (accessed on 16 March 2024).
- Lau, K.W.; Po, L.M.; Rehman, Y.A.U. Large separable kernel attention: Rethinking the large kernel attention design in cnn. Expert Syst. Appl. 2024, 236, 121352. [Google Scholar] [CrossRef]
- Hassani, A.; Walton, S.; Li, J.; Li, S.; Shi, H. Neighborhood attention transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 6185–6194. [Google Scholar]
- Tan, C.; Gao, Z.; Wu, L.; Xu, Y.; Xia, J.; Li, S.; Li, S.Z. Temporal attention unit: Towards efficient spatiotemporal predictive learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 18770–18782. [Google Scholar]
- Cao, Y.; Bin, J.; Hamari, J.; Blasch, E.; Liu, Z. Multimodal object detection by channel switching and spatial attention. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 403–411. [Google Scholar]
- Ning, C.; Gan, H. Trap attention: Monocular depth estimation with manual traps. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 5033–5043. [Google Scholar]
- Tang, Z.; Qiu, Z.; Hao, Y.; Hong, R.; Yao, T. 3D human pose estimation with spatio-temporal criss-cross attention. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 4790–4799. [Google Scholar]
- Zhu, L.; Wang, X.; Ke, Z.; Zhang, W.; Lau, R.W. Biformer: Vision transformer with bi-level routing attention. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 10323–10333. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11534–11542. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Rahman, A.; Lu, Y.; Wang, H. Deep Neural Networks for Weed Detections Towards Precision Weeding. In Proceedings of the 2022 ASABE Annual International Meeting. American Society of Agricultural and Biological Engineers, Houston, TX, USA, 17–20 July 2022. [Google Scholar]
- Kumaran, D.T. Cotton-Weed Dataset. 2021. Available online: https://universe.roboflow.com/deepak-kumaran-t/cotton-weed (accessed on 16 March 2024).
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 1–9. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Chen, Y.; Wang, N.; Zhang, Z. Scale-aware trident networks for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6054–6063. [Google Scholar]
- Tian, Z.; Chu, X.; Wang, X.; Wei, X.; Shen, C. Fully convolutional one-stage 3d object detection on lidar range images. Adv. Neural Inf. Process. Syst. 2022, 35, 34899–34911. [Google Scholar]
- Lv, W.; Xu, S.; Zhao, Y.; Wang, G.; Wei, J.; Cui, C.; Du, Y.; Dang, Q.; Liu, Y. Detrs beat yolos on real-time object detection. arXiv 2023, arXiv:2304.08069. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Attribute | Value |
|---|---|
| OS | Ubuntu 18.04.6 LTS |
| GPU | NVIDIA A40 |
| Driver Version for A40 | 460.106.00 |
| CUDA Version | 11.2 |
| Deep Learning Framework | Pytorch 2.0.1 |
| Torchvision Version | 0.15.2 |
| Attribute | Value |
|---|---|
| lr0 | 0.01 |
| lrf | 0.01 |
| momentum | 0.937 |
| weight_decay | 0.0005 |
| optimizer | SGD |
| epoch | 110 |
| batchsize | 16 |
| YOLOv8s | C2F-ALGA | MDPM | CARAFE | P | R | F1 | mAP50 | mAP75 | Params (M) | FLOPs (G) |
|---|---|---|---|---|---|---|---|---|---|---|
| ✔ | 81.1 | 75.5 | 78.1 | 77.2 | 66.8 | 11.12 | 28.4 | |||
| ✔ | ✔ | 81.1 | 77.3 | 79.1 | 80.1 | 69.5 | 11.12 | 28.4 | ||
| ✔ | ✔ | 79.0 | 77.6 | 78.2 | 79.1 | 67.2 | 12.19 | 29.3 | ||
| ✔ | ✔ | 80.6 | 77.9 | 79.2 | 79.3 | 69.7 | 12.19 | 28.6 | ||
| ✔ | ✔ | ✔ | 77.7 | 77 | 77.3 | 80.2 | 66.6 | 12.19 | 29.3 | |
| ✔ | ✔ | ✔ | 83.3 | 77.6 | 80.3 | 81.7 | 69.6 | 12.28 | 29.5 | |
| ✔ | ✔ | ✔ | 86.2 | 70.4 | 77.5 | 80.5 | 70.0 | 12.28 | 29.5 | |
| ✔ | ✔ | ✔ | ✔ | 81.6 | 77.2 | 79.2 | 82.3 | 69.7 | 12.28 | 29.5 |
| YOLOv8s | C2F-ALGA | MDPM | CARAFE | P | R | F1 | mAP50 | mAP75 | Params (M) | FLOPs (G) |
|---|---|---|---|---|---|---|---|---|---|---|
| ✔ | 84.1 | 67.2 | 74.7 | 76.3 | 53.4 | 11.12 | 28.4 | |||
| ✔ | ✔ | 83.5 | 74.9 | 78.9 | 76.8 | 56.3 | 11.12 | 28.4 | ||
| ✔ | ✔ | 84.2 | 72.5 | 77.9 | 77.5 | 55.0 | 12.19 | 29.3 | ||
| ✔ | ✔ | 82.9 | 73.3 | 77.8 | 76.8 | 55.1 | 12.19 | 28.6 | ||
| ✔ | ✔ | ✔ | 84.0 | 72.0 | 77.5 | 77.2 | 55.2 | 12.19 | 29.3 | |
| ✔ | ✔ | ✔ | 88.3 | 67.9 | 76.7 | 76.9 | 53.6 | 12.28 | 29.5 | |
| ✔ | ✔ | ✔ | 83.1 | 73.6 | 78.0 | 76.6 | 57.1 | 12.28 | 29.5 | |
| ✔ | ✔ | ✔ | ✔ | 87.8 | 71.1 | 78.5 | 77.6 | 55.6 | 12.28 | 29.5 |
| Method | P | R | F1 | mAP50 | mAP75 |
|---|---|---|---|---|---|
| Faster_Rcnn [42] | 67.7 | 79.2 | 72.9 | 78.1 | 63.3 |
| Tridentnet [43] | 56.1 | 78.6 | 65.4 | 74.6 | 63.5 |
| Fcos [44] | 75.2 | 56.4 | 64.4 | 65.6 | 42.2 |
| YOLOv3 [25] | 78.7 | 68.6 | 73.3 | 75.3 | 63.4 |
| YOLOv5s [27] | 82.5 | 70.6 | 76.1 | 77.2 | 61.3 |
| YOLOv6s [28] | 76.2 | 72.6 | 74.3 | 77.6 | 61.2 |
| YOLOv7 [29] | 82.9 | 80.6 | 81.7 | 81.3 | 69.8 |
| YOLOv8s [30] | 81.1 | 75.5 | 78.1 | 77.2 | 66.8 |
| RTDETR-L [45] | 86.9 | 75.3 | 80.6 | 78.8 | 68.2 |
| RTDETR-R50 [45] | 79.6 | 71.5 | 75.3 | 73.6 | 59.9 |
| RTDETR-R101 [45] | 82.4 | 70.4 | 75.9 | 74.1 | 59.2 |
| EY8-MFEM (ours) | 81.6 | 77.2 | 79.3 | 82.3 | 69.7 |
| Method | Size | Params (M) | FLOPs (G) |
|---|---|---|---|
| Faster_Rcnn [42] | 640 × 640 | 41.36 | 69.32 |
| Tridentnet [43] | 640 × 640 | 33.07 | 76.3 |
| Fcos [44] | 640 × 640 | 32.11 | 56.58 |
| YOLOv3 [25] | 640 × 640 | 103.66 | 282.2 |
| YOLOv5s [27] | 640 × 640 | 9.11 | 23.8 |
| YOLOv6s [28] | 640 × 640 | 16.29 | 44.0 |
| YOLOv7 [29] | 640 × 640 | 36.49 | 103.2 |
| YOLOv8s [30] | 640 × 640 | 11.12 | 28.4 |
| RTDETR-L [45] | 640 × 640 | 31.99 | 103.4 |
| RTDETR-R50 [45] | 640 × 640 | 41.96 | 129.6 |
| RTDETR-R101 [45] | 640 × 640 | 74.66 | 247.1 |
| EY8-MFEM (ours) | 640 × 640 | 12.28 | 29.5 |
| Method | P | R | F1 | mAP50 | mAP75 |
|---|---|---|---|---|---|
| Faster_Rcnn [42] | 54.0 | 77.2 | 63.5 | 72.9 | 52.2 |
| Tridentnet [43] | 54.2 | 81.1 | 64.9 | 74.5 | 53.7 |
| Fcos [44] | 87.0 | 71.8 | 78.6 | 75.3 | 50.9 |
| YOLOv3 [25] | 83.2 | 71.5 | 76.9 | 78.0 | 54.5 |
| YOLOv5s [27] | 80.3 | 71.0 | 75.3 | 79.2 | 51.4 |
| YOLOv6s [28] | 85.3 | 69.2 | 76.4 | 77.8 | 55.1 |
| YOLOv7 [29] | 77.6 | 72.1 | 74.7 | 74.9 | 45.2 |
| YOLOv8s [30] | 84.1 | 67.2 | 74.7 | 76.3 | 53.4 |
| RTDETR-L [45] | 86.2 | 74.0 | 79.6 | 77.8 | 57.0 |
| RTDETR-R50 [45] | 91.7 | 62.6 | 74.4 | 75.5 | 53.7 |
| RTDETR-R101 [45] | 85.2 | 65.1 | 73.8 | 73.0 | 53.1 |
| EY8-MFEM (ours) | 87.8 | 71.1 | 78.5 | 77.6 | 55.6 |
| Method | Size | Params (M) | FLOPs (G) |
|---|---|---|---|
| Faster_Rcnn [42] | 640 × 640 | 41.36 | 90.91 |
| Tridentnet [43] | 640 × 640 | 33.07 | 77.4 |
| Fcos [44] | 640 × 640 | 32.11 | 78.59 |
| YOLOv3 [25] | 640 × 640 | 103.66 | 282.2 |
| YOLOv5s [27] | 640 × 640 | 9.11 | 23.8 |
| YOLOv6s [28] | 640 × 640 | 16.29 | 44.0 |
| YOLOv7 [29] | 640 × 640 | 36.49 | 103.2 |
| YOLOv8s [30] | 640 × 640 | 11.12 | 28.4 |
| RTDETR-L [45] | 640 × 640 | 31.98 | 103.4 |
| RTDETR-R50 [45] | 640 × 640 | 41.95 | 129.5 |
| RTDETR-R101 [45] | 640 × 640 | 74.65 | 247.1 |
| EY8-MFEM (ours) | 640 × 640 | 12.28 | 29.5 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ren, D.; Yang, W.; Lu, Z.; Chen, D.; Shi, H. Improved Weed Detection in Cotton Fields Using Enhanced YOLOv8s with Modified Feature Extraction Modules. Symmetry 2024, 16, 450. https://doi.org/10.3390/sym16040450
Ren D, Yang W, Lu Z, Chen D, Shi H. Improved Weed Detection in Cotton Fields Using Enhanced YOLOv8s with Modified Feature Extraction Modules. Symmetry. 2024; 16(4):450. https://doi.org/10.3390/sym16040450
Chicago/Turabian StyleRen, Doudou, Wenzhong Yang, Zhifeng Lu, Danny Chen, and Houwang Shi. 2024. "Improved Weed Detection in Cotton Fields Using Enhanced YOLOv8s with Modified Feature Extraction Modules" Symmetry 16, no. 4: 450. https://doi.org/10.3390/sym16040450
APA StyleRen, D., Yang, W., Lu, Z., Chen, D., & Shi, H. (2024). Improved Weed Detection in Cotton Fields Using Enhanced YOLOv8s with Modified Feature Extraction Modules. Symmetry, 16(4), 450. https://doi.org/10.3390/sym16040450