Abstract
The rapid growth of smartphone financial services raises the need for secure mobile authentication. Continuous authentication is a user-friendly way to strengthen the security of smartphones by implicitly monitoring a user’s identity through sessions. Mobile continuous authentication can be viewed as an anomaly detection problem in which models discriminate between one genuine user and the rest of the impostors (anomalies). In practice, complete impostor profiles are hardly available due to the time and monetary cost, while leveraging genuine data alone yields poorly generalized models due to the lack of knowledge about impostors. To address this challenge, we recast continuous mobile authentication as a few-shot anomaly detection problem, aiming to enhance the inference robustness of unseen impostors by using partial knowledge of available impostor profiles. Specifically, we propose a novel deep learning-based model, namely a local feature pooling-based temporal convolution network (LFP-TCN), which directly models raw sequential mobile data, aggregating global and local feature information. In addition, we introduce a random pattern mixing augmentation to generate class-unconstrained impostor data for the training. The augmented pool enables characterizing various impostor patterns from limited impostor data. Finally, we demonstrate practical continuous authentication using score-level fusion, which prevents long-term dependency or increased model complexity due to extended re-authentication time. Experiments on two public benchmark datasets show the effectiveness of our method and its state-of-the-art performance.
1. Introduction
With the growing use of financial services in smartphones, robust security is required to protect mobile devices from unauthorized access. Nowadays, one-time or static authentication mechanisms such as PIN-, pattern-based authentication, and biometrics, e.g., TouchID, and FaceID, are widely deployed on smartphones. However, they authenticate users only once at the initial log-in and are vulnerable to shoulder-surfing or presentation attacks [1].
Continuous authentication is a promising way to provide an additional security layer for mobile devices, which monitors user identities implicitly through their behavioral biometrics using device built-in sensor data [2,3,4,5,6,7,8,9,10,11,12,13,14,15].
Unlike physical biometrics, which utilizes human physical attributes such as face and fingerprint, behavioral biometrics exploits user behavioral patterns such as screen-touch gestures and gait patterns. Physical biometrics are generally more unique and stable than behavioral ones; however, they require users’ cooperation to capture their biometric traits, such as touching a sensor with a finger or turning a face to a camera. In contrast, behavioral biometrics can capture users’ biometric data tacitly with built-in sensors of mobile devices such as the touch screen, accelerometer, and gyroscope. Therefore, behavioral biometrics can actualize implicit continuous authentication, further enhancing the security of mobile devices without deteriorating the user experience.
For deployment, mobile continuous authentication systems first capture sensor data of a genuine user (and impostors if available), which is used to construct the user’s profile. Then, claimants are monitored during re-authentication time and judged as “accept” or “reject”.
Motivation and Contribution
Since mobile devices are personal and hardly shared, mobile-based biometric authentication can be deemed an anomaly detection problem, in which models differentiate a single genuine user and all other impostors (anomalies). Prior works have different assumptions about the availability of impostor data with respect to unsupervised, semi-supervised, and fully-supervised learning. The approach relying on unsupervised or semi-supervised anomaly detection assumes that impostor data cannot be obtained in advance, solely depending on unlabeled or genuine data for the training [2,3,4,5,6,7]. However, this approach is poor at detecting impostors because they do not leverage prior knowledge of impostors.
On the other hand, the fully-supervised approach assumes that genuine and all impostor profiles (seen impostors) are available for learning [3,8,9,10,16,17]. An apparent issue of this approach is that models are not designed to work in an open-set setting—a practical scenario for biometrics, where it is unfeasible to have all impostor profiles available for training due to time and monetary costs. During authentication, the model may not infer correct decisions when encountering a never-seen impostor (unseen impostor).
Considering the issues of previous approaches, we posit the mobile-based authentication as a few-shot anomaly detection (FSAD) problem [18]. FSAD is a subfield of weakly supervised learning in that only an incomplete set of anomaly classes is known at the training. In addition to the unavailability of complete knowledge of anomalies, FSAD is allowed to use only a few anomalous data. Recent works have addressed FSAD considering the availability of small-scale labeled anomaly data in real-world scenarios [19,20,21,22].
Compared to the fully supervised approach, FSAD is practical in mobile-based authentication. First, our model is sample-efficient because it uses only a few seen impostor (anomaly class) data for training. Secondly, our model aims to work in an open-set setting, where models encounter unseen impostors. By leveraging partial knowledge of seen impostors, our model excels at detecting unseen impostors more than unsupervised and semi-supervised models.
This work is the first attempt to address mobile-based biometrics authentication from the FSAD vein. Specifically, we define the challenges as follows:
- Limited impostor profiles for training:The core challenge of FSAD is the limited availability of seen impostor profiles. However, the models need to be able to detect arbitrary unseen impostors during inference.
- Class imbalance between genuine and impostor data:Since FSAD uses extensive genuine and small impostor data, models inherently suffer from the class-imbalance problem. This can emphasize the genuine class and under-fit the impostor classes, preventing learning the impostor patterns adequately.
- Large intra-class variance of user behavior data:Due to the significant intra-class variance of raw touch sensor data, most touch-gesture authentication solutions have adopted hand-crafted features and conventional machine learning models such as support-vector machine, random forest, etc., which are more noise-robust than learned features [11,12,13,14,23,24,25,26,27,28]. However, hand-crafted features lack refined feature information, making it hard to characterize delicate impostor patterns.
To address the first two challenges, we propose random pattern mixing—a data augmentation method tailored for sequential touch sensor data. While data augmentation has been extensively studied for visual data [29], it is under-explored for anomaly detection [18] and sequential data [17]. A few primitive augmentation methods for sequential data, such as jittering and scaling [3,16,17], are intended to generate data of a minority class (seen impostors in our case) by adding small noises or changing their magnitudes slightly, for example. Despite the fact that smooth decision boundaries between a genuine user and seen impostors yield better generalization, they do not help detect unseen impostors because unseen impostors may have completely different patterns from seen impostors. To improve the robustness against unseen impostors, the proposed random pattern mixing aims to enlarge the feature space of impostor data, producing various synthetic patterns not present in seen impostors.
To respond to the third challenge, we devise a novel local feature pooling (LFP)-enabled temporal convolution network (TCN) for raw sequential touch sensor data modeling. The TCN [30] is a variant of the convolution neural network (CNN) modified for sequential data modeling. Kim et al. exploited the TCN for touch-gesture authentication, showing its superior performance over the LSTM baseline [31]. Indeed, the TCN can learn global information with its large receptive field and yields noise-robust global representations of touch screen data.
In this paper, we enhance the TCN with the LFP module, which enables aggregating local feature information to learn fine-grained representations of impostors. Specifically, the LFP module prevents local information loss due to the sparsity of the kernel in the dilated convolution. Moreover, the LFP module is parameter-free; thus, it is suitable for applications on memory-constrained mobile devices such as smartphones.
Finally, we demonstrate continuous authentication based on the decision and score-level fusion. Although many researchers have worked on continuous authentication, prior works have applied the sensor-level fusion, which enlarges window size according to re-authentication time [2,3,5,10]. However, this approach exaggerates the long-term dependency problem for the recurrent neural networks (RNNs) or increases the model complexity of the CNNs. Therefore, we explore alternatives using the decision and score-level fusion, which maintain the window size and prevent the problems above.
In summary, our contributions are as follows.
- We formulate continuous mobile-based biometric authentication as a few-shot anomaly detection problem, aiming to enhance the discrimination robustness of the genuine user and seen and unseen impostors.
- We present a sequential data augmentation method, random pattern mixing, which expands the feature space of impostor data, providing synthetic impostor patterns not present in seen impostors.
- We propose the LFP-TCN, which aggregates global and local feature information, characterizing fine-grained impostor patterns from noisy sensor data.
- We demonstrate the continuous authentication based on the decision and score-level fusion, which can effectively improve the authentication performance for longer re-authentication time.
2. Related Works
This section presents relevant works on touch-gesture features, anomaly detection in mobile-based biometrics, few-shot anomaly detection, and data augmentation for mobile-based biometrics.
2.1. Touch-Gesture Features for Authentication
Touch-gesture authentication verifies users based on screen-touch behaviors, summarized by touch trajectory, device motion, and orientation. Prior works either utilize the screen touch coordinates, pressure, or motion sensor data captured by the accelerometer and gyroscope [10,11,12,13,14,15,24,25,26,27,28].
Most existing methods have relied on hand-crafted features such as length of trajectory, the median of finger pressure, etc. [11,12,13,14,15,24,25,26,27,28]. This is mainly attributed to touch-gesture being sensitive to behavioral changes. Typically, the systems first extract hand-crafted features and train prediction models, such as the one class-SVM [12,15], kernel ridge regression [26], random forest [27], temporal regression forest [25], SVM [11,13], and MLP [14,24,28]. Criticisms for hand-crafted features are that they are task- or user-dependent and require expert knowledge to design, which are not trivial. Furthermore, hand-crafted features lack delicate features and are unlikely to characterize refined impostor patterns.
Several works attempted to combine hand-crafted and deep learned features [23] or build an end-to-end feature learning model [10,31]. To address the limitations of hand-crafted features, we opt to learn the features from raw touch-gesture data directly with a deep network.
2.2. Deep Anomaly Detection in Mobile-Based Biometrics
Mobile-based biometric authentication is often formulated as an anomaly detection problem. Here, we limit the scope to deep learning-based anomaly detection models. Based on how a model is trained, the existing models can be broadly categorized into unsupervised, semi-supervised, or fully-supervised ones. Table 1 tabulates several recent deep anomaly detection models in mobile-based biometrics. Most methods utilize motion sensor data, such as the accelerometer, gyroscope, and magnetometer. Many works utilize behavior data while walking [3,9,16] or operating a smartphone [2,4,5,6,7,8,10,17].

Table 1.
End-to-end models for mobile-based biometrics.
Autoencoder is a popular architecture for unsupervised learning [2,3]. This approach uses an encoder network for input dimension reduction and a decoder network to reconstruct inputs and compute reconstruction losses as anomaly scores.
The semi-supervised models are composed of a pretrained CNN feature extractor, dimensionality reduction, and a one-class classifier such as OC-SVM [4,5,6,7]. Many of them are designed as light-weighted models, accounting for the deployment in mobile devices [4,5,6]. An advantage of this approach is that classifiers can leverage powerful representations from pretrained feature extractors. However, the training of the feature extractors is completely decoupled from that of the classifiers. Therefore, the learned representations are not optimized for the classifiers. Besides, the disuse of impostor data yields decision boundaries without characterizing impostor patterns, often failing to detect impostors when genuine or unlabeled data have large intra-class variances.
The other approach is fully supervised anomaly detection, in which a large set of genuine and labeled impostor data are given at the training. Existing works have mainly utilized CNNs [16], LSTM [3,8], and ConvLSTM [9,17]. Using the large-scale labeled impostor data, they reduce an anomaly detection problem to a binary (a genuine user with a positive label vs. the rest with a negative label) or multi-class (a genuine user vs. multiple impostors) classification problem. The use of impostor data can significantly boost the model performance [3]. However, the availability of large impostor data is often unrealistic due to time and monetary costs. In particular, it is not feasible to utilize full knowledge of impostors because they can be unseen in biometrics.
One related approach to ours (FSAD) is weakly-supervised anomaly detection. It aims to detect unseen impostors by utilizing labeled genuine and seen impostor data for the training. Kim et al. explored this approach in touch-gesture authentication [31]. However, large-scale impostor data is necessary for weakly supervised models, which have the same constraint as the fully supervised approach.
In this work, we study few-shot anomaly detection (FSAD), which addresses the drawbacks of previous approaches by leveraging small-scale seen impostor data.
2.3. Few-Shot Anomaly Detection
Few-shot anomaly detection is a recently emerged problem, which considers the availability of a few labeled anomaly data for training [18]. Pang et al. proposed the deviation loss for anomaly image detection problems, which forces anomaly scores of anomalies to be statistically significant [19]. Ding et al. leveraged a meta-learning technique to transfer knowledge of anomalies from multiple few-shot anomaly detection tasks [20]. Finally, Tian et al. trained an encoder, maximizing the mutual information between normal images and their embedding, and utilized the deviation loss to optimize a score inference network [21]. However, none of the works directly addressed the class imbalance in FSAD, which may cause under-fitting to the minority class (impostor data).
In this work, we explore the FSAD solution for anomaly touch-gesture detection problems. Our paper is the first to do so to the best of our knowledge.
2.4. Data Augmentation for Mobile-Based Biometrics
Data augmentation is a common approach to address the class-imbalance problem [29]. Typical augmentation methods for time series data are categorized into random transformation, pattern mixing, and generative model-based methods [32].
The random transformation-based methods generate new time series using some transformation function on a minority class data. Representative methods are jittering, scaling, permutation, warping, rotation, cropping, etc., commonly used in mobile-based biometrics (Table 2). The authors of [3,7,15,16,17] applied jittering, scaling, permutation, etc. for motion sensor data.
Table 2.
Data augmentation methods applied in mobile-based biometrics.
The pattern mixing-based methods produce a new time series by combining multiple time series. Interpolation and the SMOTE [33] are popular methods. The SMOTE interpolates a minority class sample and its k-nearest sample. Incel et al. applied this method for touch screen and motion sensor data [13]. Our proposed random pattern mixing belongs to this category; however, it differs because existing methods combine class-constrained seen patterns, while ours does class-unconstrained random patterns.
Several researchers attempted the generative model-based methods. For example, the authors in [11,27] utilized a GAN for hand-crafted touch screen data. However, this approach demands a large set of training data from the minority class, which is unavailable in FSAD as we use only a few impostor data.
3. Method
This section first gives an overview of our proposed authentication system and then introduces each component, including the random pattern mixing, LFP-TCN, and decision-making mechanism.
3.1. System Overview
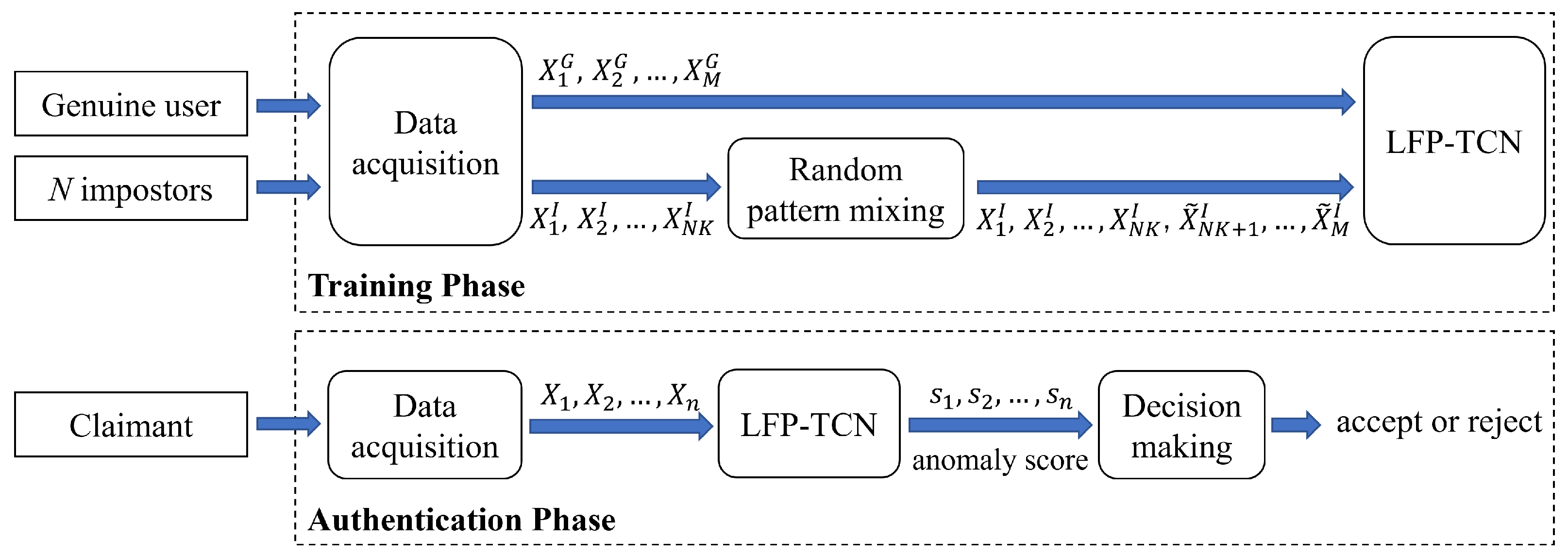
Figure 1 illustrates an overview of our proposed FSAD mobile-based continuous authentication system. For data acquisition, the system collects the touch screen and motion sensor data from the accelerator and gyroscope when a user touches a smartphone screen.
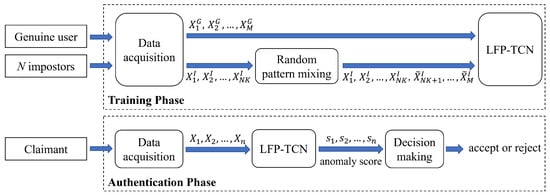
Figure 1.
Framework of our authentication method.
These sensors capture 11 raw touch-gesture readings with 100 Hz. The touch screen gives x-y coordinates of touched points, touch pressure, and horizontal-vertical touched area information. The accelerometer and gyroscope give x-y-z axis values of velocity and rotation, respectively. Each sensor reading is min-max normalized.
The captured sensor readings are then converted into data samples by the sliding window with the window size of seconds ( readings) and overlapping of seconds. Each raw reading is concatenated along the time dimension. We obtain a raw data matrix , where , , and are the raw readings from the touch screen, accelerometer, and gyroscope, respectively.
In the training phase, the system utilizes M genuine samples, , and K(=10) samples from each of N(=10) impostors, . After that, the random pattern mixing augments the impostor samples to M samples, , so that the number of genuine and impostor samples is balanced up. Finally, they are used to train the LFP-TCN with the binary cross entropy loss.
In the authentication phase, the sensor data are continuously captured, and a claimant is verified every seconds for re-authentication. Here, samples can be acquired by the sliding window for each verification. For instance, we obtain five samples when , , and . For n samples, the LFP-TCN returns n anomaly scores, . Finally, the decision-making module yields a decision of “accept” or “reject” based on the decision or score-level fusion of the n scores.
3.2. Random Pattern Mixing
To better illustrate our proposed augmentation method, we first revisit augmentation techniques designed for time series, namely jittering, scaling, permutation, and SMOTE [33].
Suppose is a multivariate time series that has d(=11) variate, and each variate has a length of .
3.2.1. Jittering
Jittering is one of the most common augmentation techniques for adding noise to an original signal. In this work, Gaussian noises are adopted:
where is a hyper-parameter. Then, a generated sample is:
3.2.2. Scaling
Scaling is another popular augmentation technique, which changes the magnitude of a time series according to a scaling factor. We take the scaling factor from the Gaussian distribution:
where ⊙ denotes the element-wise product, and is a hyper-parameter. A new sample is given by following Equation (2).
3.2.3. Permutation
Permutation rearranges segments of a time series in order to produce a new pattern. Permutation splits a time series in the time axis into P segments with a length of and permutes them.
3.2.4. SMOTE
The SMOTE [33] is a popular augmentation method for imbalanced data. It randomly selects a sample X from a minority class and its k-nearest sample . Then, a synthetic sample is produced by interpolating these samples:
where is a random value in [0, 1].
These conventional augmentation methods generate synthetic samples of a minority class (seen impostors in our case) within the feature space of seen classes. However, unseen impostors have unbounded and arbitrary behavior patterns. Therefore, augmenting impostor data in class-constrained feature space may not sufficiently increase the generalizability against unseen impostors.
- Random Pattern Mixing
To improve the robustness to unseen impostors, we propose random pattern mixing. We hypothesize that the feature space of unseen impostors is larger than that of seen impostors. This hypothesis is reasonable in our task because seen impostors are only partial profiles of a few impostors, while unseen impostor profiles are unbounded. To simulate unseen impostor features, we enlarge the feature space of impostors by mixing seen impostor and uniform random patterns. Since random patterns are class-unconstrained, our method can produce synthetic instances not present in the feature space of seen impostors.
Given a matrix , in which each value in follows the uniform distribution:
where the uniform distribution is bounded by , supposing every sample is min-max normalized.
Then, we mix the seen impostor and random patterns. By letting a seen impostor sample be X, it follows:
where ⊙ is the element-wise product, and is a mask of zeros and ones, in which the ratio of the number zero is adjustable. As the mask contains fewer zeros, the feature space of the generated patterns becomes as narrow as seen impostors. When the values in the mask are all ones, our method is equivalent to up-sampling.
In a nutshell, the proposed random pattern mixing can efficiently enlarge the feature space of impostors, diversifying impostor features in training data.
3.3. Local Feature Pooling-Based Temporal Convolution Network (LFP-TCN)
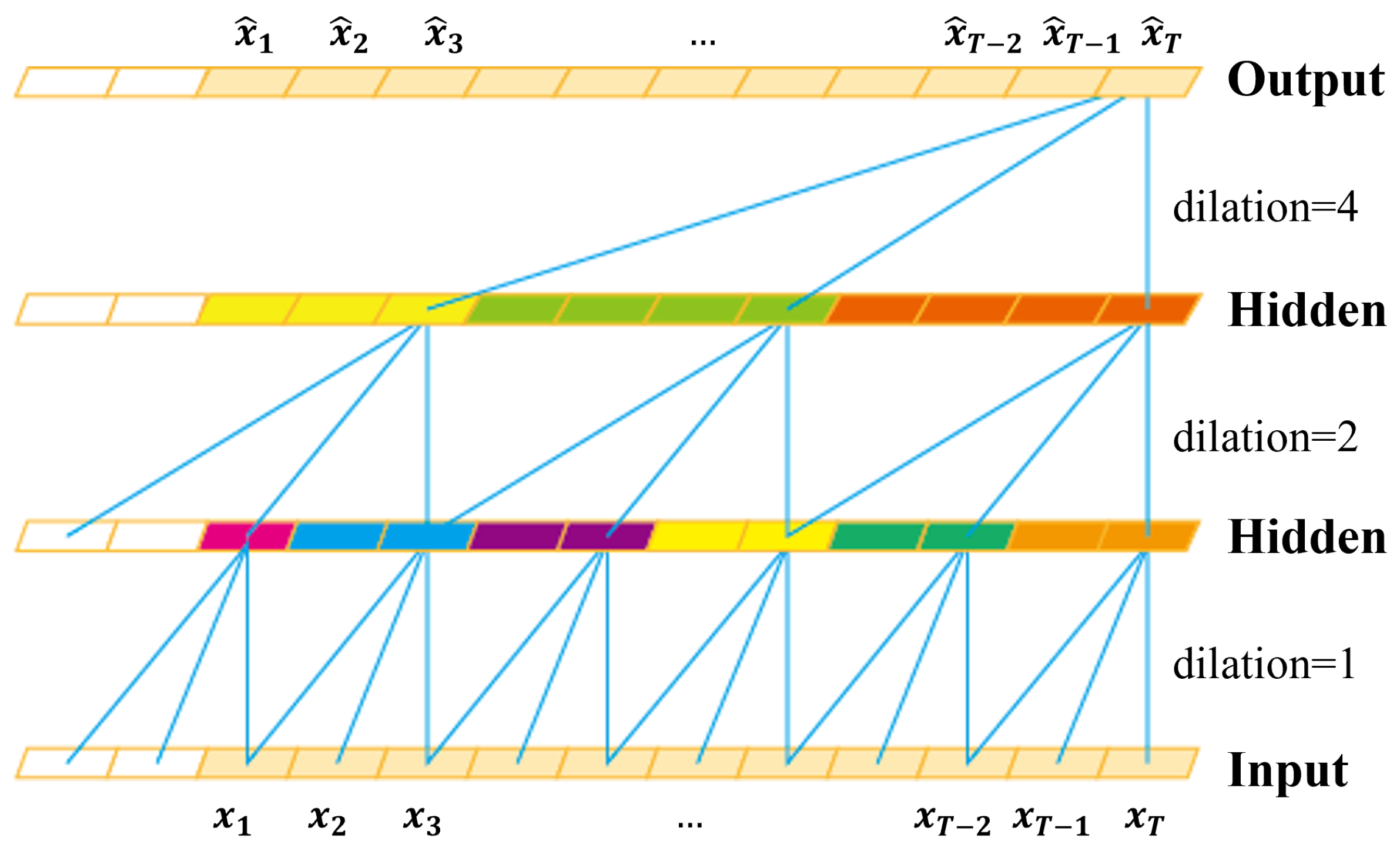
The TCN is a CNN variant for sequential data modeling [30]. The characteristics of TCN are manifested by causal convolution and dilated convolution. In Figure 2, the blue lines illustrate convolutional filters by the dilated causal convolution with the kernel size of 3. The causal convolution is performed on elements only at the same and earlier time steps in the previous layer. This is achieved by the causal padding, i.e., adding zero-padding of length of in front of inputs. Additionally, the dilated convolution is performed on non-successive elements with a fixed step (dilation rate), which efficiently enlarges the receptive field. These characteristics enable the TCN to learn relationships of very long sequences effectively.
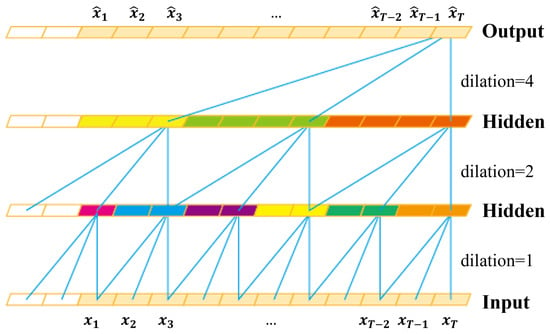
Figure 2.
Convolution by the LFP-TCN: The convolution is performed with the kernel size of 3 and dilation rate of . The colored elements in hidden layers illustrate max-pooled elements. The kernel size of the max-pooling is the same as the dilation rate on each layer. This operation compresses local information of neighboring non-filtered elements.
On the other hand, the dilated convolution fails to aggregate local feature information neighboring elements have [34,35]. This is because the dilated convolution kernel is spatially discrete. In image segmentation, this problem hinders the learning of small objects. Hamaguchi et al. addressed it by adding the local feature extraction (LFE) module, composed of convolutional layers with decreasing dilation rates along with the depth of layers [34]. Park et al. proposed the concentrated-comprehensive convolution, in which two depth-wise convolutions are performed before the dilated convolution [35].
The local information loss also occurs in the TCN. For example, in Figure 2, the output at the last time step is affected by the elements connected with blue lines. We can observe that every detail is connected between layers when the dilation rate is one. In contrast, the connection becomes more sparse as the dilation rate increases, and many hidden layer elements are completely non-connected. This means that more feature information is lost in higher layers, and only specific global features are aggregated at the output layer. Note that classifiers for time series are based on the many-to-one architecture, classifying inputs based on the output only at the last time step. This issue forces the TCN to focus on specific global information and prevents learning refined representations of touch-gestures.
However, for this problem, the existing methods [34,35] are not preferable in mobile-based biometrics because using additional convolution layers increases model complexity. Considering the limited memory capacity of mobile devices, we designed the LFP module, a parameter-free method to prevent local information loss. Specifically, the LFP module extracts salient feature information from neighboring elements with max-pooling before the dilated convolution is performed.
Figure 2 illustrates the convolution by the LFP-TCN. The LFP module performs the causal padding and max-pooling to inputs of convolution layers when their dilation rates are more than one. The causal padding is used to maintain the time consistency and input length. Additionally, max-pooling is used to compress features of the non-filtered elements in a skipped interval with the length of a dilation rate (the same color elements in Figure 2). To this end, the kernel size of the pooling layer is set as the dilation rate of the following convolution layer.
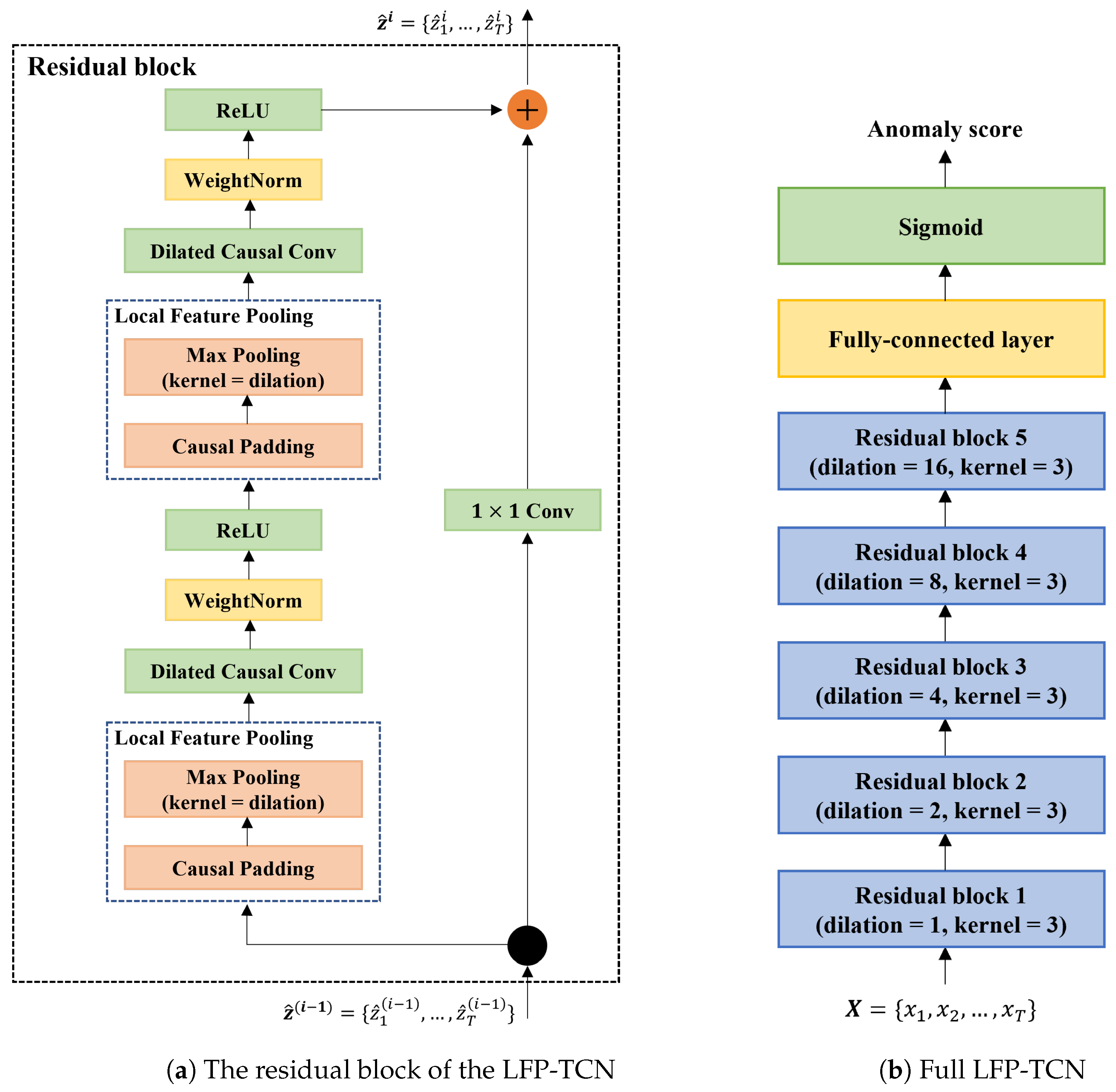
Figure 3a depicts the base unit of LFP-TCN. The LFP module first applies the causal padding and then max-pools every non-filtered element in the skipped interval. By doing this, all elements in the interval are max-pooled first, and the compressed feature information is convoluted, propagating local feature information into higher layers.
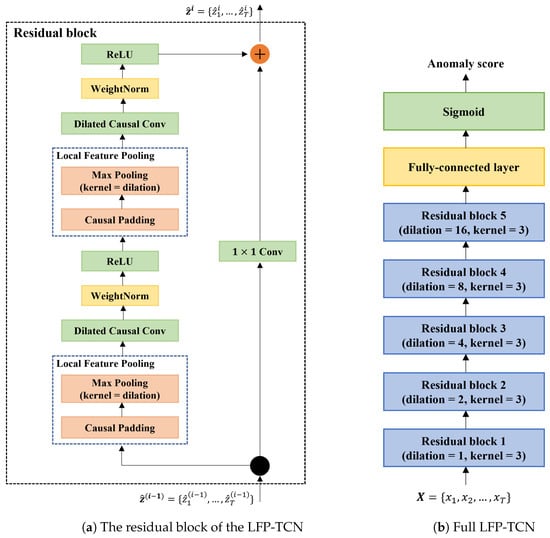
Figure 3.
(a) The LFP modules are added in front of the dilated causal convolution layers. They aggregate local information of inputs and pass compressed feature information to the convolution layers. (b) Full LFP-TCN consists of 5 stacked residual blocks and a fully connected layer.
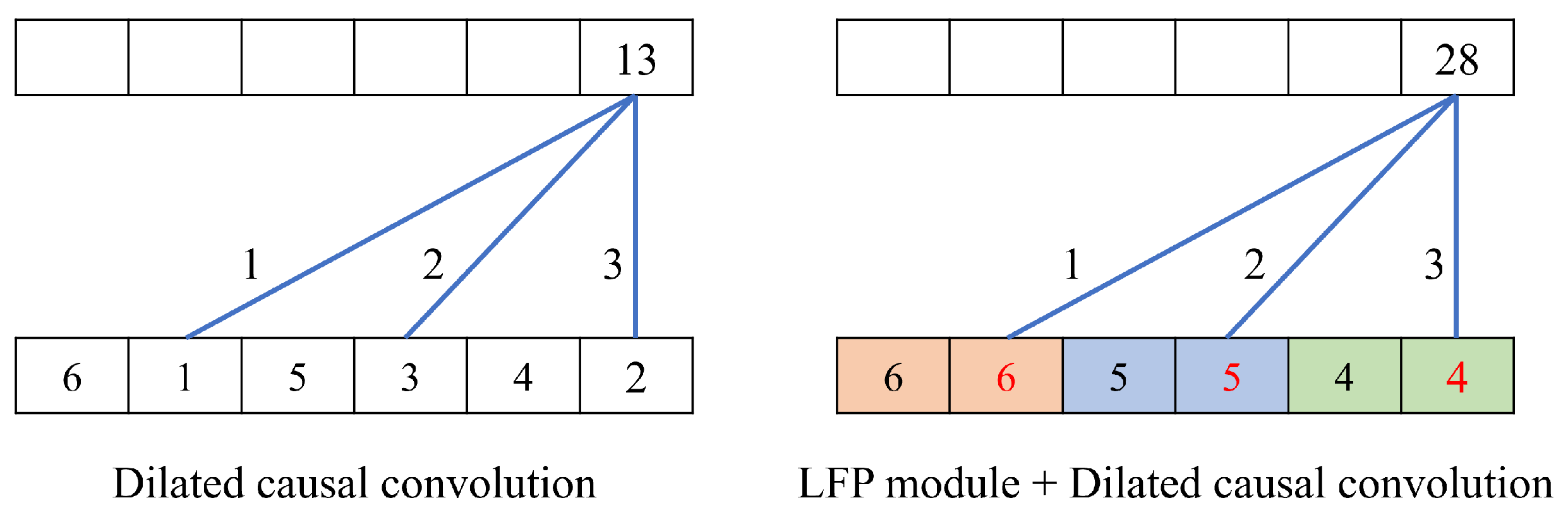
Figure 4 illustrates a toy example of the LFP module. In the example, the sequence of is convoluted with a filter kernel of and a dilation rate of two. Without the LFP module, the elements of are convoluted, where the information of the non-filtered elements is wholly discarded. On the contrary, the LFP module causally max-pools the sequence with the kernel size of two, and the elements of are convoluted. As a result, more salient features of non-filtered elements are propagated into the next layer, helping learn fine-grained representations of impostors.
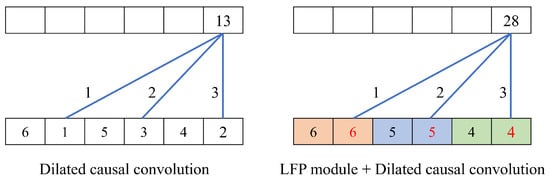
Figure 4.
Toy example of the LFP module: the sequence of is convoluted with and without the LFP module. The dilated causal convolution has a filter kernel of and a dilation rate of two. The LFP module extracts salient features from neighboring elements in the dilation interval.
Our LFP-TCN comprises 5 stacked residual blocks, as illustrated in Figure 3b. The dilation rate is set as for each block, and all convolution layers contain 128 kernel filters with size 3. The outputs at the last time step are fed into the output layer, a fully connected layer with a single neuron, to render an anomaly score. The higher anomaly scores indicate that the claimant is more likely to be an impostor. This model is trained with the binary cross-entropy loss.
3.4. Decision-Making Mechanism
Continuous authentication yields a decision of “accept” or “reject” after every re-authentication. In general, longer re-authentication time improves authentication performance due to better-accumulated information; however, few works have discussed how to make decisions with variable re-authentication time.
Primary decision-making mechanisms are categorized into the sensor, decision, and score-level fusion [36]. Some prior works have followed the sensor-level fusion, enlarging the window size (input sequence length) according to re-authentication time () [2,3,5,10].
However, due to the long-term dependency, networks such as RNN may not fully benefit from longer input sequences. Moreover, a larger window size increases the model size of CNNs, increasing the output feature map size [5]. Additionally, the TCN requires more layers or a larger kernel size to have a larger receptive field to cover input sequences. Therefore, sensor-level fusion is problematic regarding performance stability and model complexity.
We consider the decision and score-level fusion as alternatives to the sensor-level fusion, which maintains the window size and is free from the above problems.
3.4.1. Decision-Level Fusion
The decision-level fusion combines decisions from multiple classifiers [36]. However, in mobile continuous authentication, it is not feasible to utilize many different classifiers because of the limited memory capacity of mobile devices. Therefore, we resort to accumulating a number of decisions with a single model by dividing the captured data into multiple segments. To this end, the data acquisition in Figure 1 applies the sliding window with a window size shorter than re-authentication time ().
The entire data acquisition renders n data samples. Then, the obtained samples deliver n decisions of “accept” or “reject” based on a preset threshold. Finally, we can obtain a final decision based on the majority voting on these decisions.
3.4.2. Score-Level Fusion
The score-level fusion combines multiple scores from multiple classifiers. Popular approaches are taking the mean or maximum value of multiple scores [36]. Similar to decision-level fusion, we consider taking multiple scores with a single model by dividing the captured data into multiple segments.
With n samples obtained in re-authentication time, the model renders n anomaly scores; then, we can compute the combined scores by fusion. This work takes the mean and maximum of the obtained scores.
Since the decision and score-level fusion does not increase the window size with respect to re-authentication time, the RNNs and CNNs do not suffer from the long-term dependency problem or increase the model complexity.
4. Experiments
This section describes our experiment settings, including datasets, experiment protocol, model hyperparameters, and accuracy metrics.
4.1. Dataset
Two publicly available datasets were used for our experiments. We utilized three types of sensor data, i.e., touch screen, accelerometer, and gyroscope data, while users touch a smartphone screen.
- The HMOG dataset [37] is a multimodal dataset containing touch screen, accelerometer, and gyroscope data captured from 100 subjects while doing three tasks, e.g., reading web articles, typing texts, and navigating a map. The dataset comprises 24 sessions (8 sessions for each task) for each subject. The data are captured under sitting and walking situations. We used data of these tasks under sitting situations.
- The BBMAS dataset [38] captures touch screen, accelerometer, and gyroscope data from 117 subjects while typing free and fixed texts. These data are captured under sitting and walking situations. We used only data under the sitting situations. We removed five subjects’ data because of too small a data size, resulting in 112 subjects’ data.
In both datasets, we obtained data samples by a sliding window with a window size of 1 s (100 sensor readings). The overlapping of the window was set as 0.5 s (50 readings) in the HMOG dataset and 0.9 s (90 readings) in the BBMAS dataset. We obtained an average of 1672 and 862 samples per user in the HMOG and BBMAS datasets, respectively.
4.2. Experiment Protocol
To prepare for seen and unseen impostors, we divided the subjects randomly in half in each dataset. The first half (50 subjects in the HMOG dataset and 56 subjects in the BBMAS dataset) was used for training, i.e., a genuine user and seen impostors. We regarded one of the subjects as a genuine user and N(=10) subjects as seen impostors. All subjects in the second half were used for the testing as unseen impostors. Then, we repeated this procedure, using the second half for training and the first half for unseen impostors.
Considering the real-world usage of continuous authentication, we maintained the temporal dependency of the training and test data: the initial 80% of genuine samples were taken for the training, and the latter 20% of them were for testing. Similarly, initial consecutive K(=10) samples were taken from each of N(=10) seen impostors, and the rest were used for testing. To adhere to the few-shot protocol, we extracted only ten samples from each of the ten impostors, i.e., . As the choice of seen impostors can be an essential factor for the performance, we fixed seen impostors for each genuine user across whole experiments.
For the testing, impostor data amounted to 3000 samples, in which 1500 samples were randomly taken from unseen impostors. Finally, considering the randomness of the results, we repeated the training and testing five times and reported the average performance over the five trials.
4.3. Implementation Detail
If data augmentation was applied, we used the binary cross entropy loss. Otherwise, we used the balanced binary cross-entropy loss, whose class-weighting parameter is adjusted according to the ratio of impostor samples in the training data:
where y is the ground-truth label, is the target probability, and is the class-weighting parameter. We set as the ratio of genuine samples to impostor ones in the training set.
Our models were trained with the Adam optimizer and batch size of 64. In the HMOG dataset, the number of epochs was 100, and the learning rate was .
For experiments on the BBMAS dataset, models were pretrained on the HMOG dataset and fine-tuned with the BBMAS dataset for 50 epochs. The learning rate was for the residual blocks and for the output layer.
4.4. Accuracy Metrics
We evaluate model performance with the false rejection rate (FRR), the false acceptance rate (FAR), and the equal error rate (EER). The FRR represents the ratio at which a genuine subject is falsely rejected. Similarly, the FAR is the ratio at which impostors are falsely accepted. The EER is a point where the FRR = FAR, depending on a threshold. In the experiments, we present the averaged EER over each user’s model, e.g., 100 models in the HMOG dataset.
5. Experimental Result
5.1. Effectiveness of the LFP Module
We compare the LFP-TCN with baselines, including the MLP, LSTM, CNN, and TCN. The output layer for each model is a fully-connected layer with a single neuron, which renders anomaly scores. These baselines have almost the same parameter size as our LFP-TCN. Moreover, we compare our LFP module with the LFE module [34] to handle the local information loss. The details of each model are as follows:
- MLP: 3-layer MLP with neurons of on each layer. We use the ReLU activation function.
- LSTM: 5 stacked LSTM blocks with hidden states of 128. The hidden states at the last time step are fed into the output layer.
- CNN: 10 convolution layers with a kernel size of three. ReLU is used for the activation function. The final feature map is flattened and fed into the output layer. This is equivalent to the below TCN, in which we replace the dilated causal convolution layers with ordinary convolution layers and remove the skip connection.
- TCN: 5 stacked residual blocks in Figure 3 without the LFP module.
- LFE-TCN: the above TCN with the LFE module [34]. The LFE module puts an additional five residual blocks on top of the TCN with the decreasing dilation rate, resulting in 10 stacked residual blocks with the dilation rate in each block.
Table 3 demonstrates the averaged EERs and the number of parameters for different models. As depicted in Table 3, the TCN outperforms the MLP, LSTM, and CNN with an EER of 12.76% and 14.02% in the HMOG and BBMAS dataset, respectively. The TCN can learn noise-robust features from sensor data, exploiting its sizeable receptive field.
Table 3.
Averaged EERs for different architectures.
On top of that, our LFP-TCN achieved the lowest EERs in both datasets, showing values of 12.25% and 13.70%, respectively. This result shows the effectiveness of our LFP module, which improved the EER by 0.51% and 0.32% in each dataset. This improvement is contributed by aggregating local feature information, yielding fine-grained impostor representations.
Additionally, we implemented the LFE module with the TCN, even though it was originally designed for image segmentation. We confirmed that the LFE module doubled the parameters and did not improve the EER in our task. On the other hand, our LFP module kept the parameter size, and the LFP-TCN outperformed the baselines.
5.2. Effectiveness of the Random Pattern Mixing
This experiment evaluates our random pattern mixing. For comparison, we apply jittering, scaling, permutation, up-sampling, and the SMOTE to the LFP-TCN. We tune the hyper-parameters for each method. For the jittering, we add Gaussian noises with the standard deviation . For the scaling, we set the scaling factor according to Gaussian distribution , where . For the permutation, we consider the number of segments . For the SMOTE, we interpolate a sample with its k-nearest neighbor where with a step of 2. Finally, for the random pattern mixing, we adjust the ratio of the number zero in the mask (the ratio of injected random patterns) in .
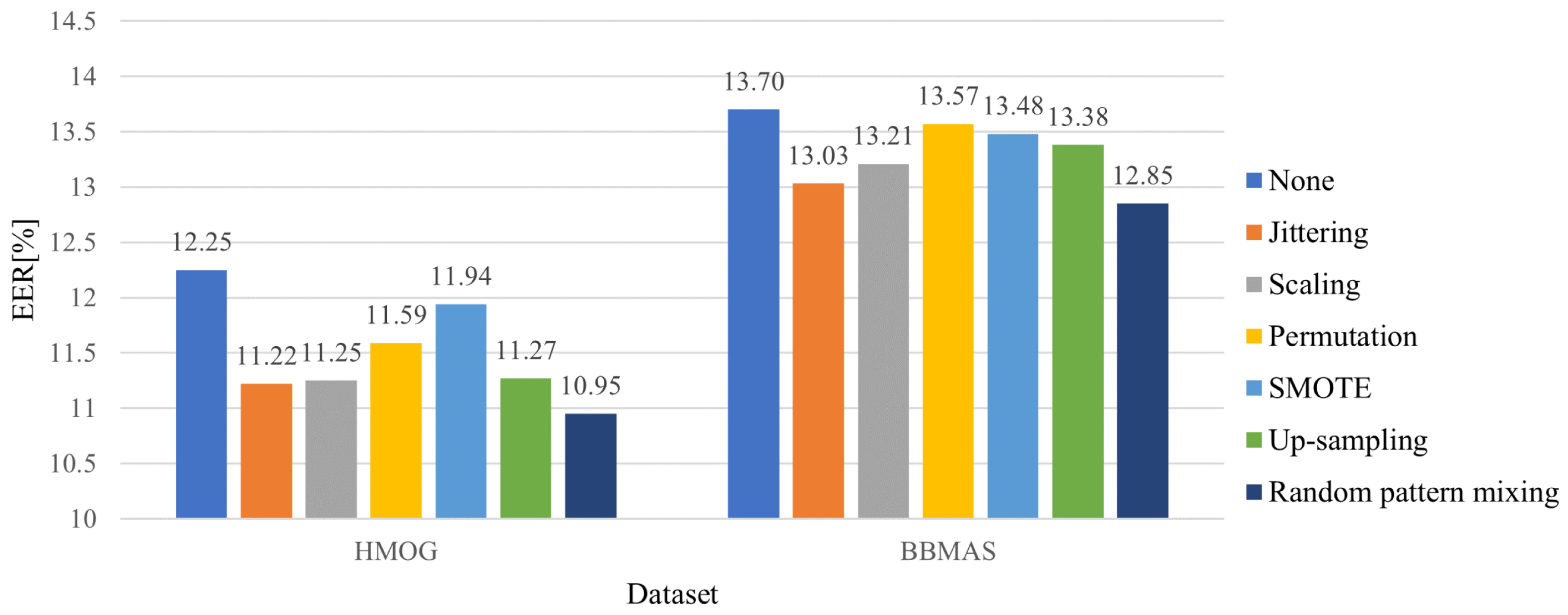
Figure 5 illustrates the averaged EERs for different data augmentation methods. As illustrated in Figure 5, the random pattern mixing outperforms other methods with the margins of 0.27% and 0.18% in the HMOG and BBMAS datasets, respectively. In particular, the use of random pattern mixing improves the EER by 1.30% and 0.85% over the model without data augmentation in each dataset.
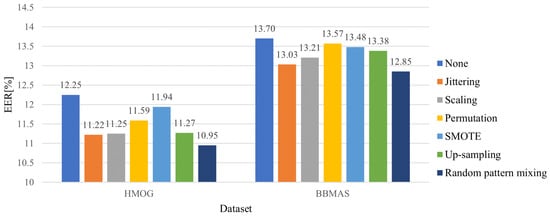
Figure 5.
Averaged EERs (%) for different data augmentation methods.
Interestingly, the up-sampling improved the EER by 0.98% and 0.32% in each dataset. This is because it prevents the penalties for the impostor class from being heavily biased to a few impostor instances in a batch, which helps balance the genuine and impostor classes.
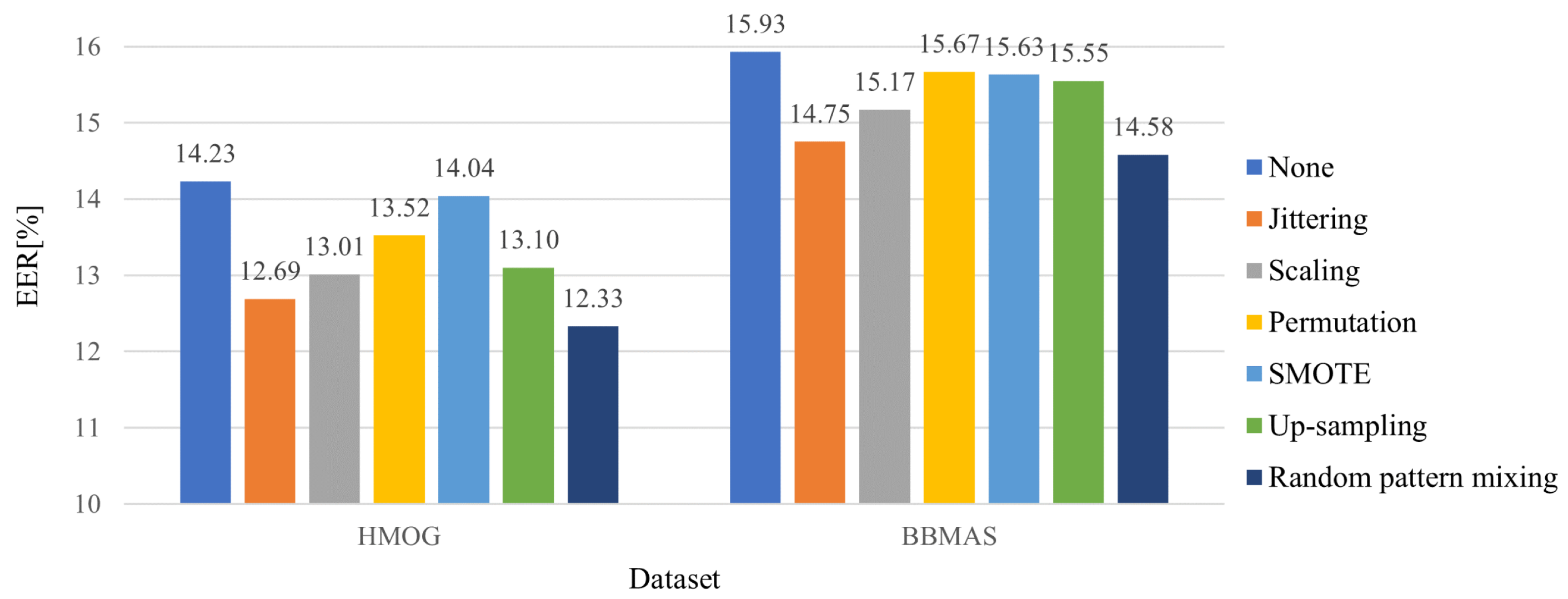
Figure 6 depicts the averaged EERs against only unseen impostors. We can see that every existing method improves the EERs in both datasets. This is because some unseen impostors share a part of the feature space with seen impostors.
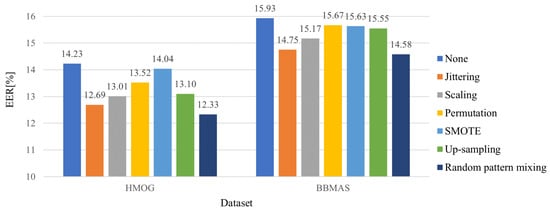
Figure 6.
Averaged EERs against only unseen impostors for different data augmentation methods.
Among competing methods, the random pattern mixing is the most robust to unseen impostors, with the EER of 12.33% and 14.58% in each dataset. Note that the difference between the random pattern mixing and the up-sampling is whether the uniform-based random patterns are injected into seen impostor set. Figure 6 shows that mixing random and seen impostor patterns further reduce the EERs from up-sampling by 0.77% and 0.97% in each dataset. This implies that the random pattern mixing can effectively simulate unseen impostor patterns.
5.3. Comparison with State of the Arts
This experiment compares our method with state-of-the-art techniques in different sets of sensors. First, we pick some recent mobile-based authentication methods based on semi-supervision and full supervision, which comply with the HMOG and BBMAS datasets. Then, we train and test those models with the same procedure of Section 4.2.
We reproduce the models in [10,13,14] for the touch screen, accelerometer, and gyroscope. The AUToSen [10] is an end-to-end learning-based model, while the others are based on hand-crafted features. The DAKOTA [13] first extracts hand-crafted features and verifies users by the SVM. Volaka et al. [14] train a three-layers MLP on hand-crafted features, which has 128 neurons in each layer.
The competing models for accelerometer and gyroscope [3,4,6,9] are all end-to-end models. The CNNAuth [4] and DeFFusion [6] are semi-supervised models, while the others are fully supervised models.
Table 4 shows the averaged EERs of SOTA methods. As illustrated in Table 4, our method achieves the lowest EERs for both sets of sensors. For the touch screen, accelerometer, and gyroscope, our model showed the EER 10.95% and 12.85% in the HMOG and BBMAS datasets, outperforming SOTA methods with margins of 0.76% and 1.21%, respectively. For the accelerometer and gyroscope, the proposed model achieves an EER of 18.32% and 22.98% in each dataset, outperforming others with margins of 8.04% and 0.30%, respectively.
Table 4.
Averaged EERs (%) of SOTA methods.
We observe that the non-end-to-end methods, such as the DAKOTA, were superior to the end-to-end AUToSen. This is because deep features are sensitive to the intra-class variance of touch screen data. Even though our method is end-to-end, it significantly outperformed the AUToSen by 11.18% and 2.49% in each dataset. This is because LFP-TCN learns fine-grained representations of impostors from noisy data by aggregating global and local feature information.
Overall, our proposed method is superior to other methods in three aspects. The first is the use of scarce impostor data. Table 4 shows that the impostor-informed models, such as ours and Giorgi et al., significantly outperformed the semi-supervised models for the accelerometer and gyroscope data. Another advantage is model architecture; a few competing models, such as AUToSen and DeFFusion, are based on LSTM and CNN. In addition, the LFP-TCN is a more robust architecture designed to characterize detailed impostor patterns. Finally, our model learns diverse impostor patterns with random pattern mixing, which generates synthetic impostor instances not present in seen impostors.
5.4. Impact of the Number of impostor Profiles and Sample Size for Training
This experiment analyzes the impact of the number of impostor profiles and samples for training. By default, we use ten samples for each impostor profile, where there are ten profiles in total. Here, we analyze the sensitivity of our model with respect to the number of impostor profiles and samples per profile. The following experiments are based on the HMOG dataset.
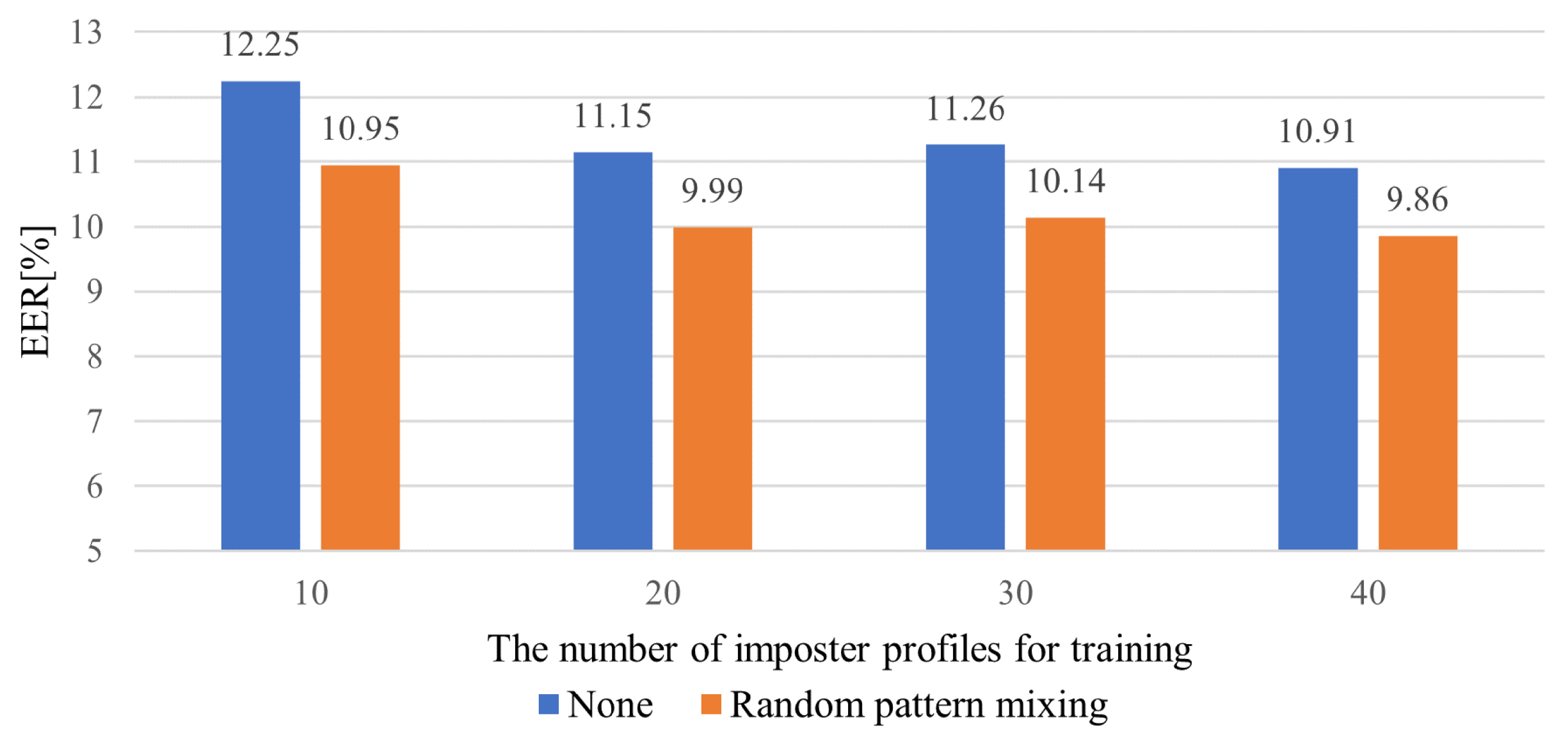
Figure 7 illustrates the averaged EERs for the different numbers of impostor profiles involved in training. We observe that the EERs tend to decrease as the number of profiles increases. The LFP-TCN without data augmentation shows EER values of 10.91% and 12.25% when using 40 and 10 impostor profiles, respectively, which represents a performance degradation of 1.34%. On the other hand, the LFP-TCN with the random pattern mixing shows EER values of 9.86% and 10.95% when using 40 and 10 impostor profiles, respectively, in which the performance degradation remains 1.09%. This suggests that the random pattern mixing alleviates the negative impact on performance due to using only a few impostor profiles.
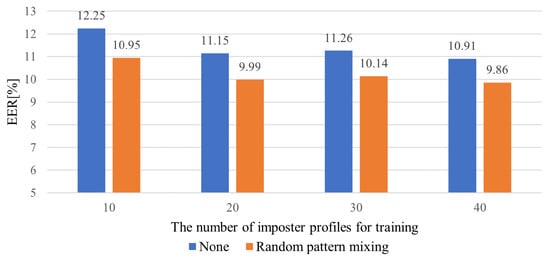
Figure 7.
Averaged EERs for different numbers of impostor profiles for training.
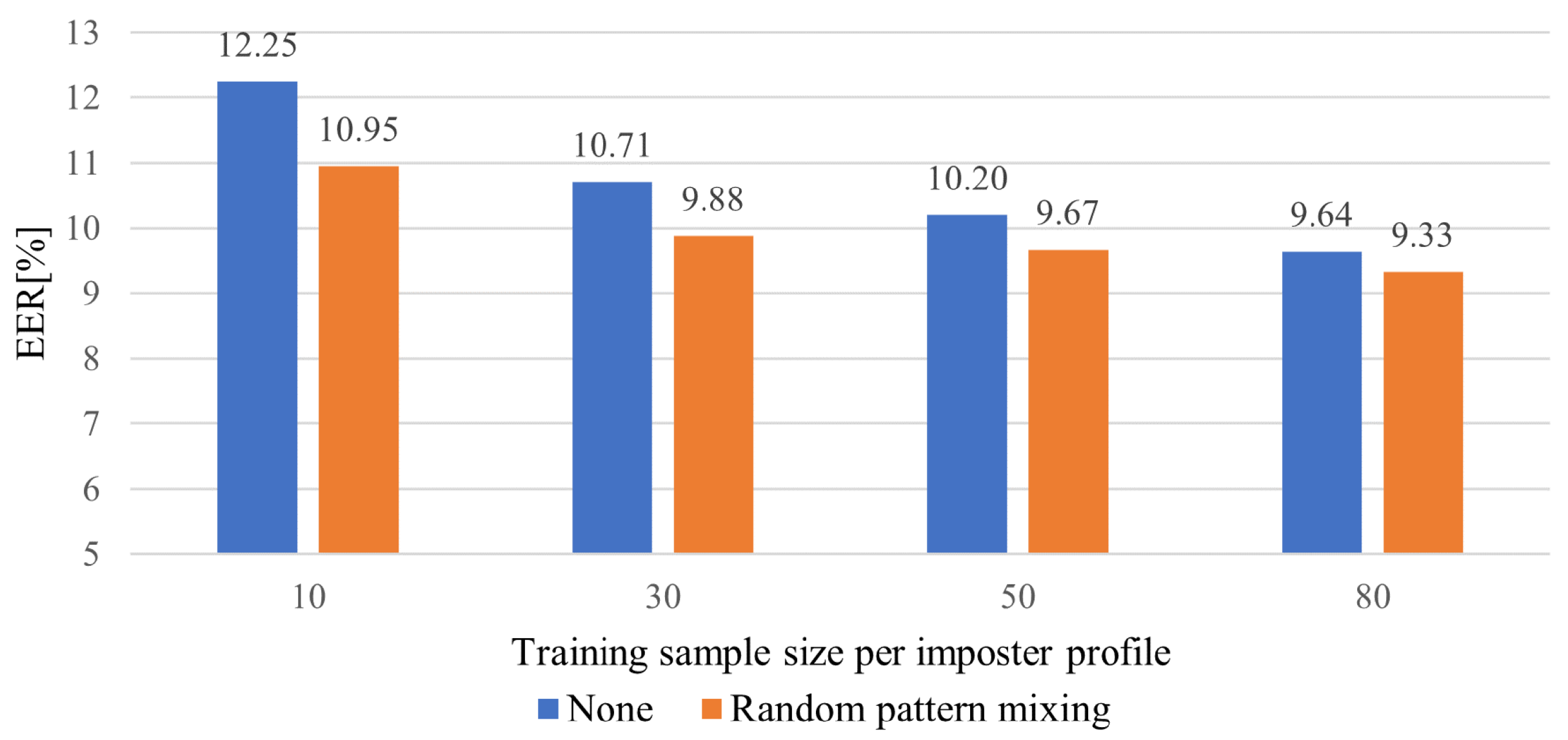
Figure 8 illustrates the averaged EERs for the different training sample sizes per impostor profile. Similar to Figure 7, the EERs constantly decrease as the sample size increases. The sample size ranges from 10 to 80. The LFP-TCN without data augmentation achieves an EER of 9.64% with 80 samples. Then, the EER degrades to 12.25% with ten samples, which is an increase of 2.61%. On the other hand, the LFP-TCN with random pattern mixing achieves values of EER of 9.33% and 10.95% with 80 and 10 samples, in which the performance degradation remains 1.62%. This shows that the random pattern mixing improves the sample efficiency, diversifying impostor patterns for the training even with limited impostor data.
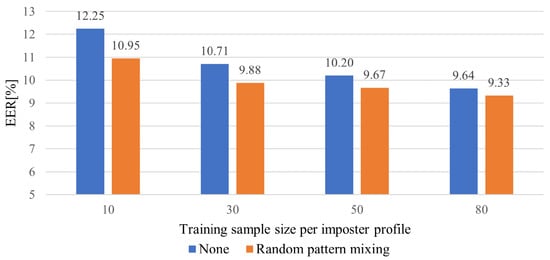
Figure 8.
Averaged EERs for different training sample sizes per impostor profile.
5.5. Impact of Re-Authentication Time
This experiment analyzes the fluctuation of the authentication performance over re-authentication time. We compare the decision, score, and sensor-level fusion. We fix the window size at 1 s for the decision and score-level fusion, while we adjust the window size for the sensor-level fusion according to re-authentication time. We apply this setting to LFP-TCN with random pattern mixing. The following experiments are based on the HMOG dataset.
5.5.1. Decision and Score-Level Fusion
Table 5 shows the averaged EERs of the decision and score-level fusion for different re-authentication time. As shown in Table 5, longer re-authentication time yields significantly better performance. For the re-authentication time of 29 s, the score-level fusion of max-score shows the EER 3.55%. On the other hand, the score-level fusion of the mean score achieves the EER of 5.11%, followed by the decision-level fusion with 5.86%.
Table 5.
Averaged EERs of the decision and score-level fusion for different re-authentication times.
Among these three mechanisms, the score-level fusion of max-score works the best for each re-authentication time. This result indicates that impostors can hardly imitate genuine users completely.
5.5.2. Sensor-Level Fusion
The sensor-level fusion provides one input sample in re-authentication time by enlarging the window size (). To adjust to the longer input sequence, we introduce additional residual blocks and make the receptive field of the LFP-TCN cover the whole sequence.
For the re-authentication time 3 and 5 s, we use 7 residual blocks with the dilation rate of for each block. For the re-authentication time 7 s, we use 8 residual blocks with the dilation rate of for each block.
Table 6 tabulates the number of parameters and the averaged EERs of the sensor-level fusion at different re-authentication times. The EERs decrease for longer re-authentication times; however, the performances are inferior to the decision and score-level fusion. Moreover, the number of model parameters increases according to the re-authentication time, which hinders the use of memory-limited devices. This experiment shows that decision and score-level fusion are preferred for continuous authentication in terms of performance and model complexity.
Table 6.
Averaged EERs of the sensor-level fusion for different re-authentication time.
6. Conclusions
This paper proposed a mobile continuous authentication method using the touch-gesture signals acquired from the touch screen, accelerometer, and gyroscope. We posit continuous mobile authentication as a few-shot anomaly detection problem utilizing a novel sequential data augmentation technique and network architecture. We proposed random pattern mixing to diversify impostor features for the training by producing class-unconstrained impostor patterns. Moreover, we presented the local feature pooling-based TCN, a variant of the temporal convolutional network (TCN), aggregating global and local feature information to learn delicate impostor patterns from sensor data. Accordingly, our proposed method can characterize various fine-grained impostor patterns from limited seen impostor samples, gaining high robustness against unseen impostors. Finally, we demonstrated practical continuous authentication based on the decision and score-level fusion. They constantly improve the accuracy performance against extended re-authentication time without causing the long-term dependency problem or increasing model complexity. Our experiments showed the effectiveness of our method compared to baselines and its state-of-the-art performance over the recent seven mobile authentication methods.
Despite the state-of-the-art performance of our method, there is room for further improvement. First, unlike the classical cross entropy loss, a more powerful loss function could be explored, especially for anomaly detection problems. Secondly, how to transfer knowledge from different domains could be investigated to utilize additional prior knowledge of impostors. Lastly, one could design a novel decision-making framework tailored for continuous authentication.
Author Contributions
Conceptualization, K.W. and A.B.J.T.; methodology, K.W.; software, K.W.; validation, K.W. and A.B.J.T.; formal analysis, K.W.; investigation, K.W.; resources, K.W.; data curation, K.W.; writing—original draft preparation, K.W.; writing—review and editing, K.W. and A.B.J.T.; visualization, K.W.; supervision, A.B.J.T.; project administration, A.B.J.T.; funding acquisition, A.B.J.T. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the National Research Foundation of Korea (NRF) grant funded by the Korea government (MSIP) (NO. NRF-2022R1A2C1010710).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
This study leveraged two publicly available datasets, the HMOG [37] and BBMAS [38] datasets. The HMOG dataset is downloadable from https://www.cs.wm.edu/~qyang/hmog.html (accessed on 20 August 2022). The BBMAS dataset is downloadable from https://ieee-dataport.org/open-access/su-ais-bb-mas-syracuse-university-and-assured-information-security-behavioral-biometrics (accessed on 20 August 2022).
Conflicts of Interest
The authors declare no conflict of interest.
References
- Wang, X.; Yan, Z.; Zhang, R.; Zhang, P. Attacks and defenses in user authentication systems: A survey. J. Netw. Comput. Appl. 2021, 188, 103080. [Google Scholar] [CrossRef]
- Centeno, M.P.; van Moorsel, A.; Castruccio, S. Smartphone continuous authentication using deep learning autoencoders. In Proceedings of the 2017 15th Annual Conference on Privacy, Security and Trust (PST), Calgary, AB, Canada, 27–29 August 2017; pp. 147–1478. [Google Scholar]
- Giorgi, G.; Saracino, A.; Martinelli, F. Using recurrent neural networks for continuous authentication through gait analysis. Pattern Recognit. Lett. 2021, 147, 157–163. [Google Scholar] [CrossRef]
- Hu, H.; Li, Y.; Zhu, Z.; Zhou, G. CNNAuth: Continuous authentication via two-stream convolutional neural networks. In Proceedings of the 2018 IEEE International Conference on Networking, Architecture and Storage (NAS), Chongqing, China, 11–14 October 2018; pp. 1–9. [Google Scholar]
- Li, Y.; Hu, H.; Zhu, Z.; Zhou, G. SCANet: Sensor-based continuous authentication with two-stream convolutional neural networks. ACM Trans. Sens. Netw. 2020, 16, 1–27. [Google Scholar] [CrossRef]
- Li, Y.; Tao, P.; Deng, S.; Zhou, G. DeFFusion: CNN-based Continuous Authentication Using Deep Feature Fusion. ACM Trans. Sens. Netw. 2021, 18, 1–20. [Google Scholar] [CrossRef]
- Deng, S.; Luo, J.; Li, Y. CNN-Based Continuous Authentication on Smartphones with Auto Augmentation Search. In Proceedings of the International Conference on Information and Communications Security, Chongqing, China, 19–21 November 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 169–186. [Google Scholar]
- Amini, S.; Noroozi, V.; Pande, A.; Gupte, S.; Yu, P.S.; Kanich, C. Deepauth: A framework for continuous user re-authentication in mobile apps. In Proceedings of the 27th ACM International Conference on Information and Knowledge Management, Turin, Italy, 22–26 October 2018; pp. 2027–2035. [Google Scholar]
- Mekruksavanich, S.; Jitpattanakul, A. Deep learning approaches for continuous authentication based on activity patterns using mobile sensing. Sensors 2021, 21, 7519. [Google Scholar] [CrossRef] [PubMed]
- Abuhamad, M.; Abuhmed, T.; Mohaisen, D.; Nyang, D. AUToSen: Deep-learning-based implicit continuous authentication using smartphone sensors. IEEE Internet Things J. 2020, 7, 5008–5020. [Google Scholar] [CrossRef]
- Agrawal, M.; Mehrotra, P.; Kumar, R.; Shah, R.R. Defending Touch-based Continuous Authentication Systems from Active Adversaries Using Generative Adversarial Networks. In Proceedings of the 2021 IEEE International Joint Conference on Biometrics (IJCB), Shenzhen, China, 4–7 August 2021; pp. 1–8. [Google Scholar]
- Yang, Y.; Guo, B.; Wang, Z.; Li, M.; Yu, Z.; Zhou, X. BehaveSense: Continuous authentication for security-sensitive mobile apps using behavioral biometrics. Ad Hoc Netw. 2019, 84, 9–18. [Google Scholar] [CrossRef]
- Incel, Ö.D.; Günay, S.; Akan, Y.; Barlas, Y.; Basar, O.E.; Alptekin, G.I.; Isbilen, M. DAKOTA: Sensor and touch screen-based continuous authentication on a mobile banking application. IEEE Access 2021, 9, 38943–38960. [Google Scholar] [CrossRef]
- Volaka, H.C.; Alptekin, G.; Basar, O.E.; Isbilen, M.; Incel, O.D. Towards continuous authentication on mobile phones using deep learning models. Procedia Comput. Sci. 2019, 155, 177–184. [Google Scholar] [CrossRef]
- Li, Y.; Hu, H.; Zhou, G. Using data augmentation in continuous authentication on smartphones. IEEE Internet Things J. 2018, 6, 628–640. [Google Scholar] [CrossRef]
- Mekruksavanich, S.; Jantawong, P.; Jitpattanakul, A. Enhancement of Sensor-based User Identification using Data Augmentation Techniques. In Proceedings of the 2022 Joint International Conference on Digital Arts, Media and Technology with ECTI Northern Section Conference on Electrical, Electronics, Computer and Telecommunications Engineering (ECTI DAMT & NCON), Chiang Rai, Thailand, 26–28 January 2022; pp. 333–337. [Google Scholar]
- Benegui, C.; Ionescu, R.T. To augment or not to augment? Data augmentation in user identification based on motion sensors. In Proceedings of the International Conference on Neural Information Processing, Sanur, Indonesia, 8–12 December 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 822–831. [Google Scholar]
- Pang, G.; Shen, C.; Cao, L.; Hengel, A.V.D. Deep learning for anomaly detection: A review. ACM Comput. Surv. 2021, 54, 1–38. [Google Scholar] [CrossRef]
- Pang, G.; Shen, C.; van den Hengel, A. Deep anomaly detection with deviation networks. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 353–362. [Google Scholar]
- Ding, K.; Zhou, Q.; Tong, H.; Liu, H. Few-shot network anomaly detection via cross-network meta-learning. In Proceedings of the Web Conference 2021, Ljubljana, Slovenia, 19–23 April 2021; pp. 2448–2456. [Google Scholar]
- Tian, Y.; Maicas, G.; Pu, L.Z.C.T.; Singh, R.; Verjans, J.W.; Carneiro, G. Few-shot anomaly detection for polyp frames from colonoscopy. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Lima, Peru, 4–8 October 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 274–284. [Google Scholar]
- Pang, G.; Ding, C.; Shen, C.; Hengel, A.v.d. Explainable deep few-shot anomaly detection with deviation networks. arXiv 2021, arXiv:2108.00462. [Google Scholar]
- Song, Y.; Cai, Z. Integrating Handcrafted Features with Deep Representations for Smartphone Authentication. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2022, 6, 1–27. [Google Scholar] [CrossRef]
- Keykhaie, S.; Pierre, S. Mobile match on card active authentication using touchscreen biometric. IEEE Trans. Consum. Electron. 2020, 66, 376–385. [Google Scholar] [CrossRef]
- Ooi, S.Y.; Teoh, A.B.J. Touch-stroke dynamics authentication using temporal regression forest. IEEE Signal Process. Lett. 2019, 26, 1001–1005. [Google Scholar] [CrossRef]
- Chang, I.; Low, C.Y.; Choi, S.; Teoh, A.B.J. Kernel deep regression network for touch-stroke dynamics authentication. IEEE Signal Process. Lett. 2018, 25, 1109–1113. [Google Scholar] [CrossRef]
- Buriro, A.; Ricci, F.; Crispo, B. SwipeGAN: Swiping Data Augmentation Using Generative Adversarial Networks for Smartphone User Authentication. In Proceedings of the 3rd ACM Workshop on Wireless Security and Machine Learning, Abu Dhabi, United Arab Emirates, 2 July 2021; pp. 85–90. [Google Scholar]
- Buriro, A.; Crispo, B.; Gupta, S.; Del Frari, F. Dialerauth: A motion-assisted touch-based smartphone user authentication scheme. In Proceedings of the Eighth ACM Conference on Data and Application Security and Privacy, Tempe, AZ, USA, 19–21 March 2018; pp. 267–276. [Google Scholar]
- Wen, Q.; Sun, L.; Yang, F.; Song, X.; Gao, J.; Wang, X.; Xu, H. Time series data augmentation for deep learning: A survey. arXiv 2020, arXiv:2002.12478. [Google Scholar]
- Bai, S.; Kolter, J.Z.; Koltun, V. An empirical evaluation of generic convolutional and recurrent networks for sequence modeling. arXiv 2018, arXiv:1803.01271. [Google Scholar]
- Kim, J.; Kang, P. Draw-a-Deep Pattern: Drawing Pattern-Based Smartphone User Authentication Based on Temporal Convolutional Neural Network. Appl. Sci. 2022, 12, 7590. [Google Scholar] [CrossRef]
- Iwana, B.K.; Uchida, S. An empirical survey of data augmentation for time series classification with neural networks. PLoS ONE 2021, 16, e0254841. [Google Scholar] [CrossRef]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Hamaguchi, R.; Fujita, A.; Nemoto, K.; Imaizumi, T.; Hikosaka, S. Effective use of dilated convolutions for segmenting small object instances in remote sensing imagery. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 1442–1450. [Google Scholar]
- Park, H.; Yoo, Y.; Seo, G.; Han, D.; Yun, S.; Kwak, N. C3: Concentrated-comprehensive convolution and its application to semantic segmentation. arXiv 2018, arXiv:1812.04920. [Google Scholar]
- Modak, S.K.S.; Jha, V.K. Multibiometric fusion strategy and its applications: A review. Inf. Fusion 2019, 49, 174–204. [Google Scholar] [CrossRef]
- Sitová, Z.; Šeděnka, J.; Yang, Q.; Peng, G.; Zhou, G.; Gasti, P.; Balagani, K.S. HMOG: New behavioral biometric features for continuous authentication of smartphone users. IEEE Trans. Inf. Forensics Secur. 2015, 11, 877–892. [Google Scholar] [CrossRef]
- Belman, A.K.; Wang, L.; Iyengar, S.; Sniatala, P.; Wright, R.; Dora, R.; Baldwin, J.; Jin, Z.; Phoha, V.V. Insights from BB-MAS—A Large Dataset for Typing, Gait and Swipes of the Same Person on Desktop, Tablet and Phone. arXiv 2019, arXiv:1912.02736. [Google Scholar]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).