
Ontology-Based Methodology for Knowledge Acquisition from Groupware


Abstract
:Future Application
Abstract
1. Introduction
- (1)
- An ontology-based framework with changeable modules to harvest knowledge from groupware discussions. The uniqueness of this framework lies in its five processing phases and components; earlier closet framework [23] focuses on event extraction with four processing phases, which are covered by the first three phases in our proposed framework. This novelty of our framework is the inclusion of an acquisition hub and a knowledge chamber, which are not present in earlier frameworks.
- (2)
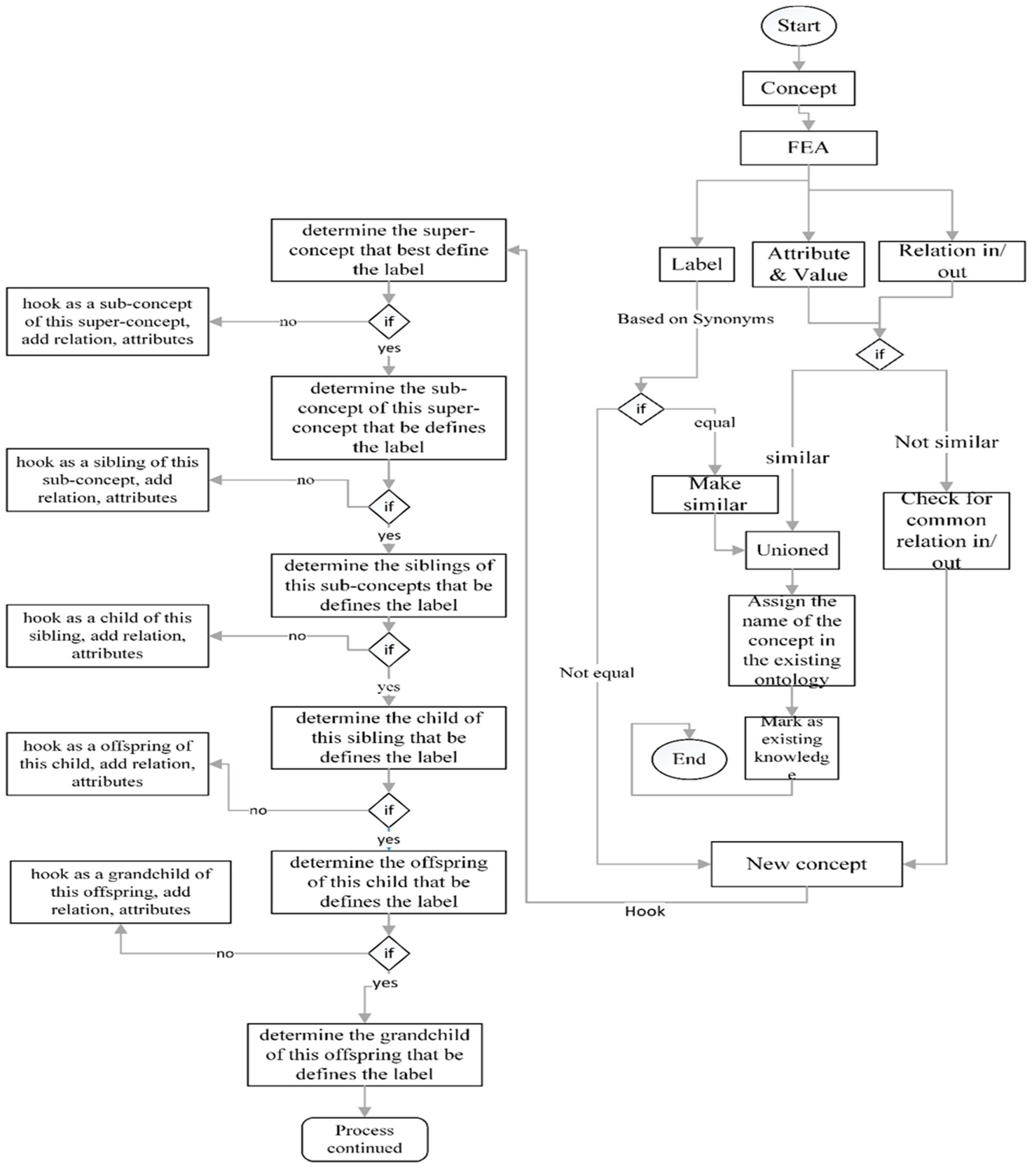
- A facts enrichment approach (FEA) for the identification and hooking of new concepts from sentences into an existing ontology, taking into consideration the notions of equality, similarity, and equivalence of concepts. The novelty of the FEA lies within its ability to identify and insert/hook a concept with less information such as those coming from sentences into an existing ontology.
2. Literature Survey
2.1. Ontology in Knowledge Representation
2.2. Framework for Knowledge Extraction
2.3. Ontology Equality of Concepts
- Most of the previous research efforts in this domain are similar in that all are looking for new knowledge to add into a destination ontology from another existing ontology.
- Within such efforts, there is no clear consensus on the notion of equality, similarity, and equivalence of concepts, which is a necessity for the recognition of new concepts from any given source to be compared with an existing ontology.
- The literature is also scant on a technique for the insertion/hooking of a newly recognized concept into an existing ontology.
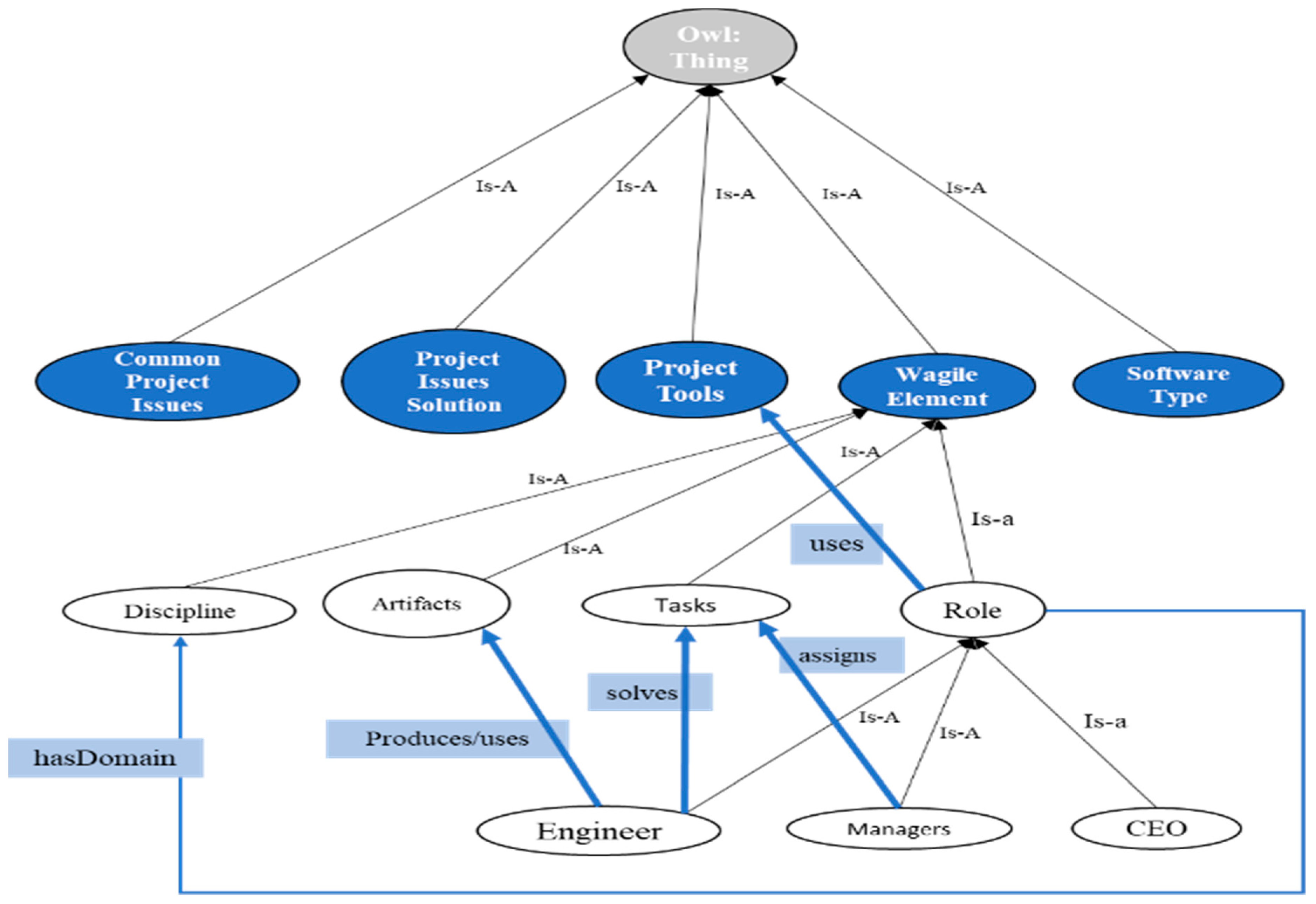
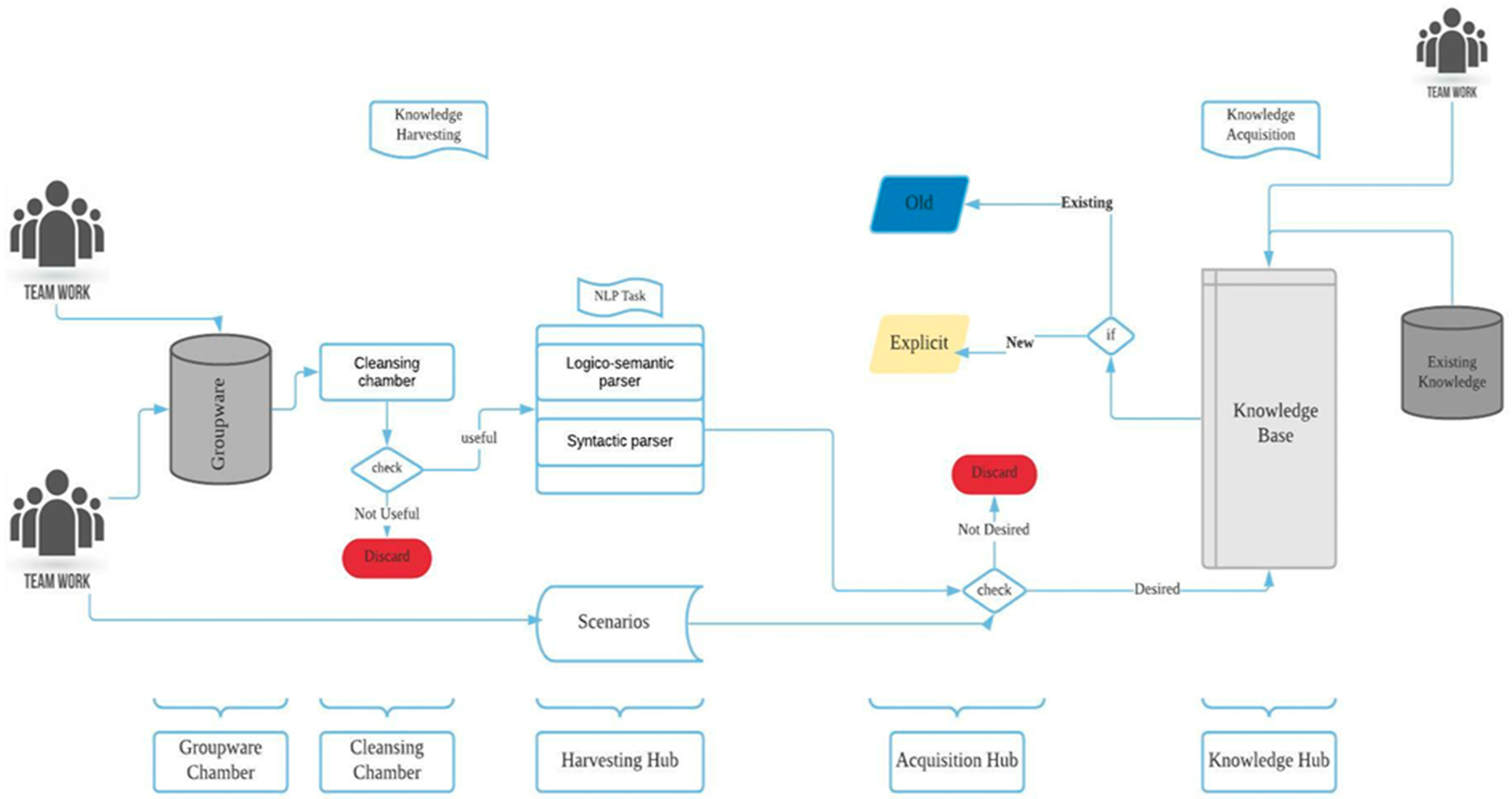
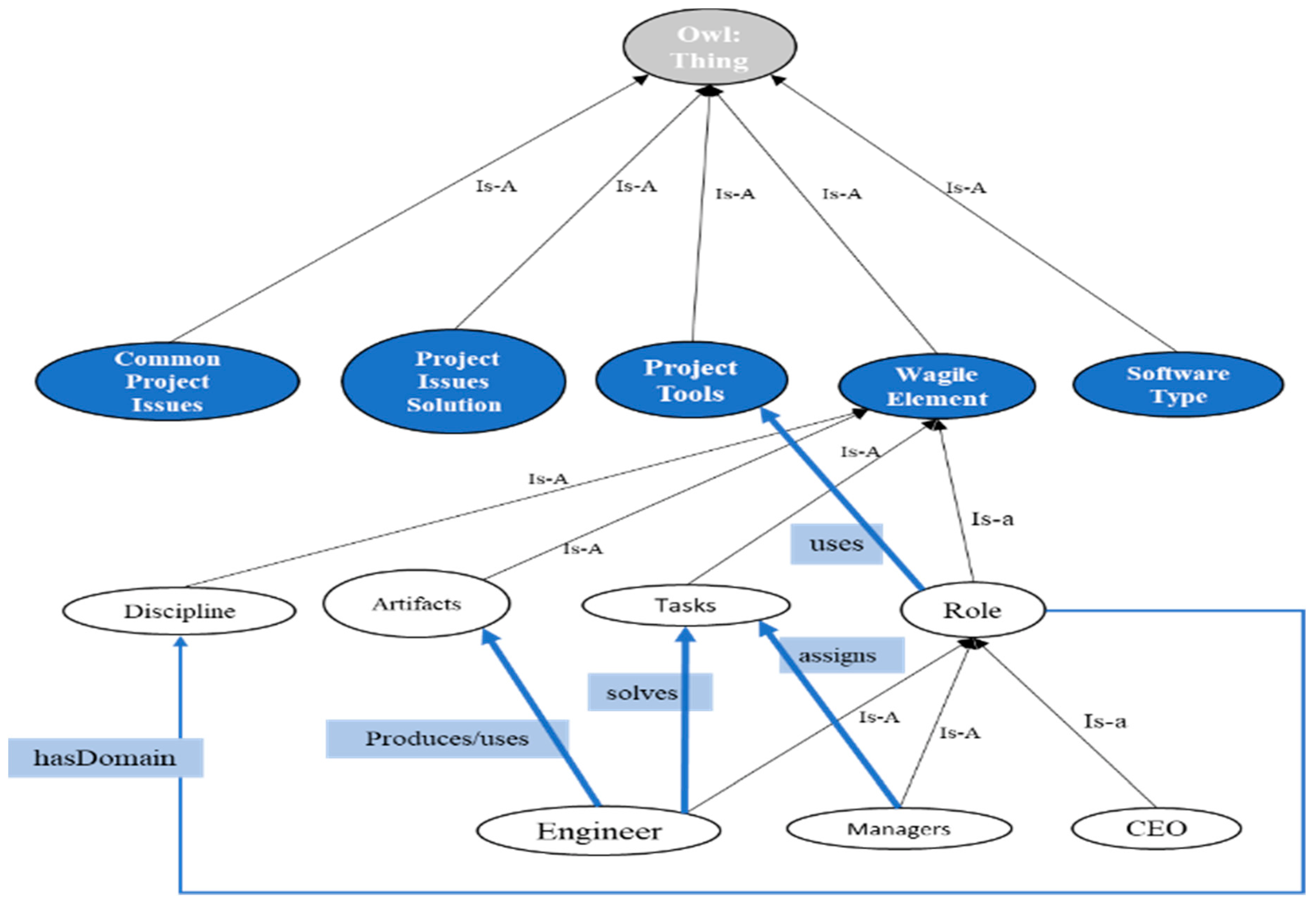
3. Design
3.1. Groupware Chamber
3.2. Cleansing Chamber
3.3. Harvesting Hub
3.4. Acquisition Hub
- (a)
- New knowledge is recognised.
- (b)
- New knowledge is inserted/hooked into the existing knowledge base.
- an entirely new concept, or
- an existing concept with a new relation, or
- an existing concept with a new attribute.
- Labels need not be the same at the outset but should be made the same once recognised as equal, similar and/or of equivalence.
- The set of attributes and values cannot be expected to be the same, but they must not contradict. Once they are deemed to be the same, then the attributes must be unioned (take the union of both sets).
- The relations in and out of the concept cannot be expected to be the same, but they must not contradict. Once they are deemed to be the same, then the relations also must be unioned.
- ❖
- one attribute in a concept labelled B but not in a concept labelled C.
- ❖
- the same for relations in and out of B and C.
- ❖
- but if the same attribute is in both, the values cannot be different,
- ❖
- if the same relations exist, they must go to or come from the same concepts.
- ❖
- if the same attribute is in both, the values cannot be different,
- ❖ if the same relations exist, they must go to or come from the same concepts
- Equality
- ❖ Exact equality can be when all are the same (label, attributes and values, and relations in/out). This is, however, not very likely to be obtained since the inputs are sentences, hence with lesser information. Other forms of equality may be defined in terms of some level of equivalence and/or similarity.
- Equivalence
- ❖ Equivalence characterises a condition of being equal or equivalent in value, worth, function, etc. (e.g., equivalent equations are algebraic equations that have identical solutions or roots). This may translate to having different labels but with attributes and values and relations in/out that may be similar. Considering the aim of this study, this notion is not very useful at the moment.
- Similarity
- ❖ Similarity describes having resemblance in appearance, character, or quantity without being identical (e.g., similar triangles are the same shape <same angles>, but not necessarily the same size). It may be seen as being equal in certain parts but not in all, with these being defined at the level of label, attributes, and relations in/out. This is the most useful but there must be no contradictions in the parts with some commonality.
- ▪ Exactly equal if all the three aspects are exactly the same. If this is obtained, then it is not a new concept.
- ▪ May or may not be equal if some aspects belong to one but not the other (and vice versa).
- ▪ Not equal if there are any contradictions within the attributes and values and/or relations in and out (excluding labels). If this is obtained, then it may be equal to another concept.
- − May still be equal, as the labels may be synonyms, or in different languages, and so on.
- − May still be equal, as they differ in labels but no contradictions in the attributes.
- − Not equal, as there is a contradiction in the attribute.
- − May still be equal, as they differ in labels but no contradictions in the relations in and out.
- − Not equal, as there is a contradiction in the relations in and out.
- The labels are the same or synonymous.
- No contradictions.
- Have at least one or more exactly same attributes or relations in/out.
3.5. Knowledge Hub
4. Evaluation
4.1. Approaches
- Error rate (ERR) (1) is calculated as the number of all incorrect predictions divided by the total number in the dataset. The acceptance rate should be less than 0.10 indicating a minimal error.
- Accuracy (ACY) (2) is calculated as the number of all of the correct predictions divided by the total number of the dataset. The acceptance rate should be greater than 0.90 showing excellent classification.
- F1-Score (3) is a harmonic mean of precision and recall. The acceptance rate should be greater than 0.90 suggesting excellent precision and recall.
4.2. Processes
- (1)
- Concepts were properly named, and
- (2)
- Their hooking locations in the ontology were accurate.
4.3. Results
5. Discussion
6. Conclusions & Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| List of Abbreviations | |
| AH | Acquisition Hub |
| AI | Artificial Intelligence |
| CC | Cleansing Chamber |
| FEA | Facts Enrichment Approach. |
| FCA | Formal Concept Analysis |
| FN | False negative |
| FP | False Positive |
| GC | Groupware Chamber |
| GO 1 | Grand Ontology 1 |
| GO2 | Grand Ontology 2 |
| HH | Harvesting Hub |
| II | Identification Instrument |
| JEOPS | Java Embedded Object Production System |
| KG | Knowledge Graph |
| KH | Knowledge Hub |
| LCS | Longest Common Substring |
| OAEI | Ontology Alignment Evaluation Initiative |
| OWL | Web Ontology Language |
| RDF | Resource Descriptive Framework |
| SWRL | Semantic Web Rule Language |
| TN | True Negative |
| TO | Target Ontology |
| TP | True positive |
| List of Mathematical Symbols | |
| C | the concept in question. |
| Sj | a super-concept of C. |
| IS_A, RI, Rm | relations. |
| atri atrk | attributes with values. |
| vi vk | attributes values. |
| Al Bm | related concepts in and out of C. |
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Grand Ontology 1 | Grand Ontology 2 | ||
|---|---|---|---|
| Sentences | Concepts | Sentences | Concepts |
| 1 | api | 1 | gitflow |
| 2 | code(new) | 2 | conversation |
| 3 | vertical scale | 3 | milestone |
| 4 | cookie | 4 | - |
| 5 | feature(new) | 5 | bug |
| 6 | testlog | 6 | impact |
| 7 | signoff | 7 | journey |
| 8 | rollback | 8 | misuse |
| 9 | script | 9 | toggle |
| 10 | production | 10 | debt |
| 11 | go-no-go | - | - |
| 12 | attend | - | - |
| 13 | codebase | - | - |
| 14 | build | - | - |
| 15 | codefreeze | - | - |
| 16 | timelines | - | - |
| 17 | sprint | - | - |
| 18 | backlog | - | - |
| 19 | tag | - | - |
| 20 | log | - | - |
References
- Wang, B.; Liu, Y.; Qian, J.; Parker, S.K. Achieving Effective Remote Working during the COVID-19 Pandemic: A Work Design Perspective. Appl. Psychol. 2021, 70, 16–59. [Google Scholar] [CrossRef] [PubMed]
- Sako, M. From remote work to working from anywhere. Commun. ACM 2021, 64, 20–22. [Google Scholar] [CrossRef]
- Saba, D.; Sahli, Y.; Maouedj, R.; Hadidi, A.; Medjahed, M.B. Towards Artificial Intelligence: Concepts, Applications, and Innovations. In Enabling AI Applications in Data Science; Springer: Cham, Switzerland, 2021; pp. 103–146. [Google Scholar] [CrossRef]
- Gacitua, R.; Astudillo, H.; Hitpass, B.; Osorio-Sanabria, M.; Taramasco, C. Recent Models for Collaborative E-Government Processes: A Survey. IEEE Access 2021, 9, 19602–19618. [Google Scholar] [CrossRef]
- Xanthopoulou, S.; Kessopoulou, E.; Tsiotras, G. KM tools alignment with KM processes: The case study of the Greek public sector. Knowl. Manag. Res. Pract. 2021, 19, 1–11. [Google Scholar] [CrossRef]
- Baronian, L. The regime of truth of knowledge management: The role of information systems in the production of tacit knowledge. Knowl. Manag. Res. Pract. 2021, 1–11. [Google Scholar] [CrossRef]
- Kodama, M. Managing IT for Innovation: Dynamic Capabilities and Competitive Advantage; Routledge: London, UK, 2021; ISBN 9780367462987. [Google Scholar]
- Uwasomba, C.F.; Seeam, P.; Bellekens, X.; Seeam, A. Managing knowledge flows in Mauritian multinational cor-porations: Empirical analysis using the SECI model. In Proceedings of the 2016 IEEE International Conference on Emerging Technologies and Innovative Business Practices for the Transformation of Societies (EmergiTech), Balaclava, Mauritius, 3–6 August 2016; pp. 341–344. [Google Scholar] [CrossRef]
- Confalonieri, R.; Weyde, T.; Besold, T.R.; Martín, F.M.D.P. Using ontologies to enhance human understandability of global post-hoc explanations of black-box models. Artif. Intell. 2021, 296, 103471. [Google Scholar] [CrossRef]
- Rodrigo, A.; Peñas, A. A study about the future evaluation of Question-Answering systems. Knowl.-Based Syst. 2017, 137, 83–93. [Google Scholar] [CrossRef]
- Charalampous, M.; Grant, C.A.; Tramontano, C.; Michailidis, E. Systematically reviewing remote e-workers’ well-being at work: A multidimensional approach. Eur. J. Work Organ. Psychol. 2019, 28, 51–73. [Google Scholar] [CrossRef]
- Juric, D.; Stoilos, G.; Melo, A.; Moore, J.; Khodadadi, M. A System for Medical Information Extraction and Verification from Unstructured Text. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 13314–13319. [Google Scholar] [CrossRef]
- Ye, X.; Lu, Y. Automatic Extraction of Engineering Rules from Unstructured Text: A Natural Language Processing Approach. J. Comput. Inf. Sci. Eng. 2020, 20, 034501. [Google Scholar] [CrossRef]
- Kolesnikov, A.; Kikin, P.; Niko, G.; Komissarova, E. Natural language processing systems for data extraction and mapping on the basis of unstructured text blocks. Proc. Int. Conf. InterCarto/InterGIS 2020, 26, 375–384. [Google Scholar] [CrossRef]
- Arani, Z.M.; Barforoush, A.A.; Shirazi, H. Representing unstructured text semantics for reasoning purpose. J. Intell. Inf. Syst. 2020, 56, 303–325. [Google Scholar] [CrossRef]
- Uwasomba, C.F.; Lee, Y.; Zaharin, Y.; Chin, T.M. FHKG: A Framework to Harvest Knowledge from Groupware Raw Data for AI. In Proceedings of the 2021 IEEE International Conference on computing (ICOCO), Online Conference, 17–19 November 2021; pp. 49–54. [Google Scholar]
- Pietranik, M.; Kozierkiewicz, A.; Wesolowski, M. Assessing Ontology Mappings on a Level of Concepts and Instances. IEEE Access 2020, 8, 174845–174859. [Google Scholar] [CrossRef]
- Djenouri, Y.; Belhadi, H.; Akli-Astouati, K.; Cano, A.; Lin, J.C. An ontology matching approach for semantic modeling: A case study in smart cities. Comput. Intell. 2021, 1–27. [Google Scholar] [CrossRef]
- Lv, Z.; Peng, R. A novel periodic learning ontology matching model based on interactive grasshopper optimization algorithm. Knowl.-Based Syst. 2021, 228, 107239. [Google Scholar] [CrossRef]
- Liu, X.; Tong, Q.; Liu, X.; Qin, Z. Ontology matching: State of the art, future challenges and thinking based on utilized information. IEEE Access 2021, 9, 91235–91243. [Google Scholar] [CrossRef]
- Xue, X.; Yang, C.; Jiang, C.; Tsai, P.-W.; Mao, G.; Zhu, H. Optimizing ontology alignment through linkage learning on entity correspondences. Complexity 2021, 2021, 5574732. [Google Scholar] [CrossRef]
- Patel, A.; Jain, S. A Novel Approach to Discover Ontology Alignment. Recent Adv. Comput. Sci. Commun. 2021, 14, 273–281. [Google Scholar] [CrossRef]
- Abebe, M.A.; Getahun, F.; Asres, S.; Chbeir, R. Event extraction for collective knowledge in multimedia digital EcoSystem. In Proceedings of the AFRICON, Addis Ababa, Ethiopia, 14–17 September 2015; pp. 1–5. [Google Scholar] [CrossRef]
- Murtazina, M.S.; Avdeenko, T.V. An ontology-based knowledge representation in the field of cognitive functions assessment. IOP Conf. Ser. Mater. Sci. Eng. 2020, 919, 052013. [Google Scholar] [CrossRef]
- Qi, J.; Ding, L.; Lim, S. Ontology-based knowledge representation of urban heat island mitigation strategies. Sustain. Cities Soc. 2019, 52, 101875. [Google Scholar] [CrossRef]
- Ebrahimipour, V.; Yacout, S. Ontology-Based Schema to Support Maintenance Knowledge Representation with a Case Study of a Pneumatic Valve. IEEE Trans. Syst. Man Cybern. Syst. 2015, 45, 702–712. [Google Scholar] [CrossRef]
- Hogan, A. Resource Description Framework. In The Web of Data; Springer: Cham, Switzerland, 2020; pp. 59–109. [Google Scholar] [CrossRef]
- Abburu, S.; Golla, S.B. Ontology and NLP support for building disaster knowledge base. In Proceedings of the 2017 2nd International Conference on Communication and Electronics Systems (ICCES), Coimbatore, India, 19–20 October 2017. [Google Scholar] [CrossRef]
- Bruno, B.; Recchiuto, C.T.; Papadopoulos, I.; Saffiotti, A.; Koulouglioti, C.; Menicatti, R.; Mastrogiovanni, F.; Zaccaria, R.; Sgorbissa, A. Knowledge Representation for Culturally Competent Personal Robots: Requirements, Design Principles, Implementation, and Assessment. Int. J. Soc. Robot. 2019, 11, 515–538. [Google Scholar] [CrossRef] [Green Version]
- Diab, M.; Akbari, A.; Din, M.U.; Rosell, J. PMK: A Knowledge Processing Framework for Autonomous Robotics Perception and Manipulation. Sensors 2019, 19, 1166. [Google Scholar] [CrossRef] [Green Version]
- Larentis, A.V.; Neto, E.G.d.A.; Barbosa, J.L.V.; Barbosa, D.N.F.; Leithardt, V.R.Q.; Correia, S.D. Ontology-Based Reasoning for Educational Assistance in Noncommunicable Chronic Diseases. Computers 2021, 10, 128. [Google Scholar] [CrossRef]
- Vieira, V.; Tedesco, P.; Salgado, A.C. Towards an Ontology for Context Representation in Groupware. In International Conference on Collaboration and Technology; Springer: Berlin/Heidelberg, Germany, 2005; pp. 367–375. [Google Scholar] [CrossRef]
- Kertkeidkachorn, N.; Ichise, R. An automatic knowledge graph creation framework from natural language text. IEICE Trans. Inf. Syst. 2018, 101, 90–98. [Google Scholar] [CrossRef] [Green Version]
- Milosevic, N.; Gregson, C.; Hernandez, R.; Nenadic, G. A framework for information extraction from tables in biomedical literature. Int. J. Doc. Anal. Recognit. (IJDAR) 2019, 22, 55–78. [Google Scholar] [CrossRef] [Green Version]
- Wang, Y.; Yang, B.; Qu, L.; Spaniol, M.; Weikum, G. Harvesting facts from textual web sources by constrained label propagation. In Proceedings of the 20th ACM International Conference on Information and Knowledge Management—CIKM ’11, Glasgow, UK, 24–28 October 2011. [Google Scholar] [CrossRef]
- Chuanyan, Z.; Xiaoguang, H.; Zhaohui, P. An Automatic Approach to Harvesting Temporal Knowledge of Entity Relationships. Procedia Eng. 2012, 29, 1399–1409. [Google Scholar] [CrossRef] [Green Version]
- Kuzey, E.; Weikum, G. Extraction of temporal facts and events from Wikipedia. In Proceedings of the 2nd Temporal Web Analytics Workshop on—TempWeb ’12, Lyon, France, 16–17 April 2012. [Google Scholar] [CrossRef] [Green Version]
- Mahmood, A.; Khan, H.U.; Rehman, Z.; Iqbal, K.; Faisal, C.M.S. KEFST: A knowledge extraction framework using finite-state transducers. Electron. Libr. 2019, 37, 365–384. [Google Scholar] [CrossRef]
- Popov, O.; Bergman, J.; Valassi, C. A Framework for a Forensically Sound Harvesting the Dark Web. In Proceedings of the Central European Cybersecurity Conference 2018 on—CECC 2018, Ljubljana, Slovenia, 15–16 November 2018. [Google Scholar] [CrossRef]
- Masum, M.; Shahriar, H.; Haddad, H.M.; Ahamed, S.; Sneha, S.; Rahman, M.; Cuzzocrea, A. Actionable Knowledge Extraction Framework for COVID-19. In Proceedings of the 2020 IEEE International Conference on Big Data, Online Conference, 10–13 December 2020; pp. 4036–4041. [Google Scholar] [CrossRef]
- Becheru, A.; Popescu, E. Design of a conceptual knowledge extraction framework for a social learning environment based on Social Network Analysis methods. In Proceedings of the 2017 18th International Carpathian Control Conference (ICCC), Sinaia, Romania, 28–31 May 2017. [Google Scholar] [CrossRef]
- Ngom, A.N.; Diallo, P.F.; Kamara-Sangare, F.; Lo, M. A method to validate the insertion of a new concept in an ontology. In Proceedings of the 2016 12th International Conference on Signal-Image Technology & Internet-Based Systems (SITIS), Naples, Italy, 28 November–1 December 2016; pp. 275–281. [Google Scholar] [CrossRef]
- Yin, C.; Gu, J.; Hou, Z. An ontology mapping approach based on classification with word and context similarity. In Proceedings of the 2016 12th International Conference on Semantics, Knowledge and Grids (SKG), Beijing, China, 15–17 August 2016; pp. 69–75. [Google Scholar] [CrossRef]
- Xue, X.; Chen, J.; Ren, A. Interactive Ontology Matching Based on Evolutionary Algorithm. In Proceedings of the 2019 15th International Conference on Computational Intelligence and Security (CIS), Macao, China, 13–16 December 2019; pp. 1–5. [Google Scholar] [CrossRef]
- Oliveira, D.; Pesquita, C. Improving the interoperability of biomedical ontologies with compound alignments. J. Biomed. Semant. 2018, 9, 13. [Google Scholar] [CrossRef] [Green Version]
- Priya, M.; Kumar, C.A. An approach to merge domain ontologies using granular computing. Granul. Comput. 2019, 6, 69–94. [Google Scholar] [CrossRef]
- Liu, J.; Tang, Y.; Xu, X. HISDOM: A Hybrid Ontology Mapping System based on Convolutional Neural Network and Dynamic Weight. In Proceedings of the 6th IEEE/ACM International Conference on Big Data Computing, Applications and Technologies, Auckland, New Zealand, 2–5 December 2019; pp. 67–70. [Google Scholar] [CrossRef]
- Ernadote, D. Ontology reconciliation for system engineering. In Proceedings of the 2016 IEEE International Symposium on Systems Engineering (ISSE), Edinburgh, Scotland, 4–5 October 2016; pp. 1–8. [Google Scholar] [CrossRef]
- Maree, M.; Belkhatir, M. Addressing semantic heterogeneity through multiple knowledge base assisted merging of domain-specific ontologies. Knowl.-Based Syst. 2015, 73, 199–211. [Google Scholar] [CrossRef]
- Zhen-Xing, W.; Xing-Yan, T. Research of Ontology Merging Based on Concept Similarity. In Proceedings of the 2015 Seventh International Conference on Measuring Technology and Mechatronics Automation, Nanchang, China, 13–14 June 2015; pp. 831–834. [Google Scholar] [CrossRef]
- Huang, Y.; Bian, L. Using ontologies and formal concept analysis to integrate heterogeneous tourism information. IEEE Trans. Emerg. Top. Comput. 2015, 3, 172–184. [Google Scholar] [CrossRef]
- Ilyas, I.; Chu, X. Data Cleaning, 2nd ed.; Association for Computing Machinery: New York, NY, USA, 2019; p. 285. ISBN 978-1-4503-7152-0. [Google Scholar]
- Jaziri-Bouagina, D.; Jamil, G. Handbook of Research on Tacit Knowledge Management for Organizational Success, 1st ed.; IGI Global: Hershey, PA, USA, 2017; p. 542. ISBN 978-1522523949. [Google Scholar]
- Qi, P.; Zhang, Y.; Zhang, Y.; Bolton, J.; Manning, C.D. Stanza: A Python natural language processing toolkit for many human languages. In Proceedings of the 58th Annual Meeting of the ACL: System Demonstrations, Online Conference, 5–10 July 2020; pp. 101–108. [Google Scholar] [CrossRef]
- Musen, M.A. The protégé project: A look back and a look forward. AI Matters 2015, 1, 4–12. [Google Scholar] [CrossRef] [PubMed]
- Bourque, P.; Fairley, R.E. Guide to the Software Engineering Body of Knowledge, Version 3.0; IEEE Computer Society: Washington, DC, USA, 2014; ISBN 978-0769551661. [Google Scholar]
- Borges, P.; Monteiro, P.; Machado, R.-J. Mapping RUP Roles to Small Software Development Teams. In Software Quality. Process Automation in Software Development; SWQD 2012. Lecture Notes in BIP; Biffl, S., Winkler, D., Bergsmann, J., Eds.; Springer: Berlin, Germany, 2012; Volume 94. [Google Scholar] [CrossRef]
- Kuhrmann, M.; Diebold, P.; Münch, J.; Tell, P.; Garousi, V.; Felderer, M.; Trektere, K.; McCaffery, F.; Linssen, O.; Hanser, E.; et al. Hybrid software and system development in practice: Waterfall, scrum, and beyond. In Proceedings of the 2017 ICSSP, Paris, France, 30–31 July 2017; pp. 30–39. [Google Scholar] [CrossRef]
- Sfar, H.; Chaibi, A.H.; Bouzeghoub, A.; Ghezala, H.B. Gold standard based evaluation of ontology learning techniques. In Proceedings of the 31st Annual ACM Symposium on Applied Computing, Pisa, Italy, 4–8 April 2016; pp. 339–346. [Google Scholar] [CrossRef]
- Raad, J.; Cruz, C. A Survey on Ontology Evaluation Methods. In Proceedings of the 7th International Joint Conference on Knowledge Discovery, Knowledge Engineering and Knowledge Management, Lisbon, Portugal, 12–14 November 2015; pp. 179–186. [Google Scholar] [CrossRef]
- Cavalin, P.; Oliveira, L. Confusion matrix-based building of hierarchical classification. In Progress in Pattern Recognition, Image Analysis, Computer Vision, and Applications, Proceedings of the Iberoamerican Congress on Pattern Recognition, Havana, Cuba, 28–31 October 2019; Springer: Cham, Switzerland, 2019; pp. 271–278. [Google Scholar] [CrossRef]
- Ruuska, S.; Hämäläinen, W.; Kajava, S.; Mughal, M.; Matilainen, P.; Mononen, J. Evaluation of the confusion matrix method in the validation of an automated system for measuring feeding behaviour of cattle. Behav. Process. 2018, 148, 56–62. [Google Scholar] [CrossRef] [PubMed] [Green Version]






| Authors/Year | Source of New Knowledge | Research Focus | Sampled Ontology | Techniques Used | Evaluation |
|---|---|---|---|---|---|
| Ngom et al. [42] | Existing ontology | Adding a concept from one ontology to another ontology | WordNet | Similarity measure | Correlation among ontologies |
| Yin et al. [43] | Existing ontology | Merging two or more existing ontologies | WordNet | Classification with Word and CONtext Similarity | LCS |
| Xue et al. [44] | Existing ontology | Matching two or more existing ontologies | WordNet | Similarity measure | Recall, Precision, F-measure |
| Oliveira and Pesquita [45] | Existing ontology | Matching two or more existing ontologies | Biomedical ontologies | Similarity measure | Recall, Precision, F-measure |
| Priya and Kumar [46] | Existing ontology | Mapping two or more existing ontologies | Transportation and vehicles ontologies | Granular computing | Use case |
| Liu et al. [47] | Existing ontology | Mapping two or more existing ontologies | OAEI dataset | Mapping similarity | Accuracy |
| Ernadote [48] | Existing ontology | Aligning two or more existing ontologies | Metamodel-based ontologies | NA | NA |
| Maree and Belkhatir [49] | Existing ontology | Combining two or more existing ontologies | EMET, AGROVOC, and NAL | OAEI | Recall, Precision |
| Zhen-Xing and Xing-Yan [50] | Existing ontology | Matching two or more existing ontologies | WordNet | Similarity measure | FCA |
| Huang and Bian [51] | Existing ontology | Matching two or more existing ontologies | Tourism info and tourists ontologies | FCA-based approaches | FCA and Bayesian analysis |
| This research | Sentences in groupware | Recognizing new concepts from sentences and inserting/hooking into an existing ontology | Software knowledge ontology | FEA | Error rate, Accuracy, F1 score |
| Discipline Concept | Waterfall Role | Agile Role | WAGILE Role |
|---|---|---|---|
| Project-management | PM | PO | PM |
| Team-focus | PM | SM | SM |
| Product-ownership | PM | PO | PO |
| Requirement-analysis | BSA | DT | BSA |
| Design | PM & UX | DT | UX |
| Implementation | Dev | DT | Dev |
| Test/QA | QA | DT | QA |
| Deployment | RM | DT | RM |
| Maintenance | ASA | DT | ASA |
| Matrix Variables | Grand Ontology 1 | Grand Ontology 2 | Total | ||
|---|---|---|---|---|---|
| Concept Naming | Hooking Location | Concept Naming | Hooking Location | ||
| True-positive | 457 | 456 | 213 | 214 | 1340 |
| False-positive | 32 | 34 | 15 | 14 | 95 |
| True-negative | 232 | 231 | 109 | 106 | 678 |
| False-negative | 3 | 4 | 2 | 4 | 13 |
| Total | 724 | 725 | 339 | 338 | 2126 |
| Parameters | Grand Ontology 1 | Grand Ontology 2 | ||||
|---|---|---|---|---|---|---|
| ER | ACY | F1 | ER | ACY | F1 | |
| Concept Naming | 0.048 | 0.952 | 0.963 | 0.050 | 0.949 | 0.984 |
| Hooking locations | 0.052 | 0.948 | 0.960 | 0.053 | 0.947 | 0.957 |
| Mean | 0.05 | 0.95 | 0.96 | 0.05 | 0.95 | 0.97 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Uwasomba, C.F.; Lee, Y.; Yusoff, Z.; Chin, T.M. Ontology-Based Methodology for Knowledge Acquisition from Groupware. Appl. Sci. 2022, 12, 1448. https://doi.org/10.3390/app12031448
Uwasomba CF, Lee Y, Yusoff Z, Chin TM. Ontology-Based Methodology for Knowledge Acquisition from Groupware. Applied Sciences. 2022; 12(3):1448. https://doi.org/10.3390/app12031448
Chicago/Turabian StyleUwasomba, Chukwudi Festus, Yunli Lee, Zaharin Yusoff, and Teck Min Chin. 2022. "Ontology-Based Methodology for Knowledge Acquisition from Groupware" Applied Sciences 12, no. 3: 1448. https://doi.org/10.3390/app12031448