


Explainability of Automated Fact Verification Systems: A Comprehensive Review



Abstract
:1. Introduction
- Provide a comprehensive overview of the current state of explainability in AFV.
- Identify the challenges in the current landscape of AFV explainability, including the concepts of local and global explainability.
- Highlight the importance of creating explanation-learning-friendly (ELF) datasets to advance research in AFV explainability.
- Propose future research directions, including a balanced approach to explainability.
- Contribute to bridging the gap between AFV and XAI principles and ultimately enhancing the transparency and accountability of AFV systems.
Shortcomings of the Previous Reviews
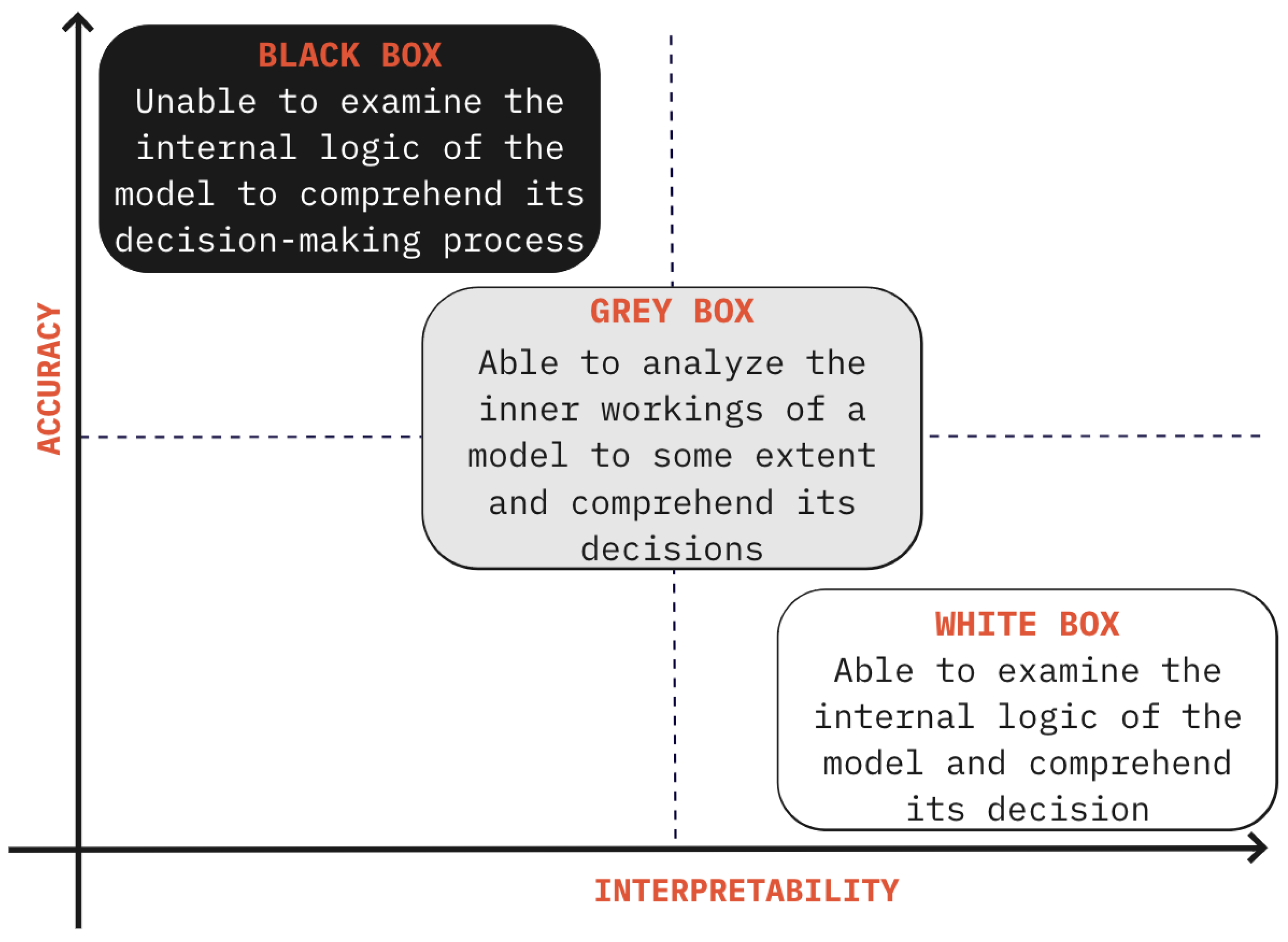
2. Explainable Artificial Intelligence
2.1. XAI Objectives
2.2. XAI Approaches
2.2.1. Model-Based Explainability
2.2.2. Post Hoc Explainability
2.3. XAI Taxonomy
3. Explainable AFV
3.1. Architectural Perspective
3.2. Methodological Perspective
3.2.1. Summarization Approach
3.2.2. Logic-Based Approach
3.2.3. Attention-Based Approach
3.2.4. Counterfactual Approach
3.3. Data Perspective
4. Discussion
Limitations
5. Future Research Directions
- Direction 1: Exploring a Balanced Approach to Explainability in AFV: Researchers should explore the development of techniques and methodologies aimed at achieving a balanced approach to explainability, integrating both global and local perspectives into AFV systems. This involves understanding the broader relationships and patterns that underlie AFV model decisions across diverse factual claims and evidence (global explainability), while also addressing the specific concerns related to individual instances (local explainability). For instance, a nuanced exploration of gray explainability could involve refining gray-box models to optimize the trade-off between interpretability and accuracy, ensuring that the explanations provided are as meaningful and understandable as possible without incurring a substantial loss in predictive accuracy. Although examples such as dispute resolution and individual patient treatment decisions illustrate the broader applicability and importance of this approach beyond the realm of fact verification, they underscore the universal need for tailored and comprehensible explanations in individual cases. In fact verification systems, a balanced approach is particularly crucial for gaining both a localized understanding of individual claims and a broader insight that can inform strategies for handling diverse types of information and evidence. By investigating methods that provide insights into AFV model behavior and reasoning patterns on both the macro and micro levels, researchers can work towards achieving a holistic understanding of explainability in AFV systems. Following the principles of XAI, a potential starting point could be to explain multiple representative individual predictions (locally) as a means to gain insights towards a more comprehensive understanding, as suggested in [25]. This nuanced exploration, which aligns with the overarching goal of achieving explainability in AFV systems, ensures that the insights gained are as widely applicable as they are individually relevant, potentially leading to more informed and equitable decision-making processes across different domains.
- Direction 2: Comprehensive Investigation and Comparative Analysis of AFV Datasets: Future research endeavors could benefit from undertaking a meticulous and comprehensive review of the applicable datasets for AFV, informed by the insights provided in Table 1 and Table 2. Table 1 outlines a comparative analysis of various methodologies used to improve explainability in AFV systems, while Table 2 delves into the distinctive attributes and inherent diversity within various types of datasets in AFV. A focused study in this direction could reveal deeper insights into the suitability and compatibility of various datasets with different AFV models and explainability techniques, providing a more nuanced understanding of the interactions between dataset characteristics and explainability. Such an investigation would not only enrich the understanding of the influence of diverse datasets on the explainability of AFV models but also reveal untapped potential in utilizing underexplored types of dataset to enhance model transparency and interpretability. By synergizing the diverse techniques for explainability and the variety of dataset types highlighted in the tables, this research direction has substantial potential to reduce the gap in the field of explainable AFV.
- Direction 3: Development of an Explainability-Focused, Explanation-Learning-Friendly (ELF) Dataset: As a logical progression from Direction 2, researchers should prioritize developing an ELF dataset to address the lack of explanations in existing AFV datasets, enabling more nuanced studies in explainability in AFV. This customized dataset would serve as a benchmark to assess the effectiveness of various AFV models in generating meaningful explanations, thereby fostering advancements in creating explainable AFV systems. Such a focused endeavor would be pivotal in bridging existing gaps and furthering research in explainable AFV, allowing for an exploration of the interplay between dataset attributes, model structures, and explainability methodologies.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AI | Artificial Intelligence |
| XAI | Explainable Artificial Intelligence |
| AFV | Automated Fact Verification |
| ELF | Explanation-Learning-Friendly |
| DNN | Deep Neural Network |
| RTE | Recognizing Textual Entailment |
References
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; Volume 2017-Decem, pp. 5999–6009. [Google Scholar] [CrossRef]
- Ali, S.; Abuhmed, T.; El-Sappagh, S.; Muhammad, K.; Alonso-Moral, J.M.; Confalonieri, R.; Guidotti, R.; Del Ser, J.; Díaz-Rodríguez, N.; Herrera, F. Explainable Artificial Intelligence (XAI): What we know and what is left to attain Trustworthy Artificial Intelligence. Inf. Fusion 2023, 99, 101805. [Google Scholar] [CrossRef]
- Guo, Z.; Schlichtkrull, M.; Vlachos, A. A Survey on Automated Fact-Checking. Trans. Assoc. Comput. Linguist. 2022, 10, 178–206. [Google Scholar] [CrossRef]
- Du, Y.; Bosselut, A.; Manning, C.D. Synthetic Disinformation Attacks on Automated Fact Verification Systems. In Proceedings of the Thirty-Sixth AAAI Conference on Artificial Intelligence (AAAI-22), Virtually, 22 February–1 March 2022. [Google Scholar]
- Hassan, N.; Zhang, G.; Arslan, F.; Caraballo, J.; Jimenez, D.; Gawsane, S.; Hasan, S.; Joseph, M.; Kulkarni, A.; Nayak, A.K.; et al. ClaimBuster: The First-Ever End-to-End Fact-Checking System. Proc. VLDB Endow. 2017, 10, 1945–1948. [Google Scholar] [CrossRef]
- Chen, J.; Bao, Q.; Sun, C.; Zhang, X.; Chen, J.; Zhou, H.; Xiao, Y.; Li, L. Loren: Logic-regularized reasoning for interpretable fact verification. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtually, 22 February–1 March 2022; Volume 36, pp. 10482–10491. [Google Scholar]
- Kotonya, N.; Toni, F. Explainable Automated Fact-Checking: A Survey. In Proceedings of the COLING 2020—28th International Conference on Computational Linguistics, Online, 8–13 December 2020; pp. 5430–5443. [Google Scholar] [CrossRef]
- Došilović, F.K.; Brčić, M.; Hlupić, N. Explainable artificial intelligence: A survey. In Proceedings of the 41st International Convention on Information and Communication Technology, Electronics and Microelectronics (MIPRO), Opatija, Croatia, 21–25 May 2018; pp. 0210–0215. [Google Scholar]
- Guidotti, R.; Monreale, A.; Ruggieri, S.; Turini, F.; Giannotti, F.; Pedreschi, D. A survey of methods for explaining black box models. ACM Comput. Surv. (CSUR) 2018, 51, 1–42. [Google Scholar] [CrossRef]
- Kim, T.W. Explainable artificial intelligence (XAI), the goodness criteria and the grasp-ability test. arXiv 2018, arXiv:1810.09598. [Google Scholar]
- Das, A.; Liu, H.; Kovatchev, V.; Lease, M. The state of human-centered NLP technology for fact-checking. Inf. Process. Manag. 2023, 60, 103219. [Google Scholar] [CrossRef]
- Olivares, D.G.; Quijano, L.; Liberatore, F. Enhancing Information Retrieval in Fact Extraction and Verification. In Proceedings of the Sixth Fact Extraction and VERification Workshop (FEVER), Dubrovnik, Croatia, 5 May 2023; pp. 38–48. [Google Scholar]
- Rani, A.; Tonmoy, S.M.T.I.; Dalal, D.; Gautam, S.; Chakraborty, M.; Chadha, A.; Sheth, A.; Das, A. FACTIFY-5WQA: 5W Aspect-based Fact Verification through Question Answering. arXiv 2023, arXiv:2305.04329. [Google Scholar]
- Wiegreffe, S.; Marasovic, A. Teach Me to Explain: A Review of Datasets for Explainable Natural Language Processing. In Proceedings of the Thirty-Fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 1), Virtual, 6–14 December 2021. [Google Scholar]
- Gunning, D.; Vorm, E.; Wang, J.Y.; Turek, M. DARPA’s explainable AI (XAI) program: A retrospective. Appl. Lett. 2021, 2, e61. [Google Scholar] [CrossRef]
- Doshi-Velez, F.; Kim, B. Towards a Rigorous Science of Interpretable Machine Learning. arXiv 2017, arXiv:1702.08608. [Google Scholar]
- Moradi, M.; Samwald, M. Post-hoc explanation of black-box classifiers using confident itemsets. Expert Syst. Appl. 2021, 165, 113941. [Google Scholar] [CrossRef]
- Rudin, C. Stop Explaining Black Box Machine Learning Models for High Stakes Decisions and Use Interpretable Models Instead. Nat. Mach. Intell. 2019, 1, 206–215. [Google Scholar] [CrossRef] [PubMed]
- Mueller, S.T.; Hoffman, R.R.; Clancey, W.; Emrey, A.; Klein, G. Explanation in Human-AI Systems: A Literature Meta-Review Synopsis of Key Ideas and Publications and Bibliography for Explainable AI; Technical Report; DARPA XAI Program; IHMC | Institute for Human IHMC | Institute for Human & Machine Cognition: Pensacola, FL, USA, 2019. [Google Scholar]
- Goodman, B.; Flaxman, S. European Union regulations on algorithmic decision-making and a “right to explanation”. AI Mag. 2017, 38, 50–57. [Google Scholar] [CrossRef]
- Gunning, D. Broad Agency Announcement Explainable Artificial Intelligence (XAI); Technical Report; Defense Advanced Research Projects Agency Information Innovation Office: Arlington, VA, USA, 2016. [Google Scholar]
- Murdoch, W.J.; Singh, C.; Kumbier, K.; Abbasi-Asl, R.; Yu, B. Definitions, methods, and applications in interpretable machine learning. Proc. Natl. Acad. Sci. USA 2019, 116, 22071–22080. [Google Scholar] [CrossRef]
- Atanasova, P.; Simonsen, J.G.; Lioma, C.; Augenstein, I. Generating Fact Checking Explanations. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 7352–7364. [Google Scholar] [CrossRef]
- Shu, K.; Cui, L.; Wang, S.; Lee, D.; Liu, H. dEFEND: Explainable fake news detection. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 395–405. [Google Scholar]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why Should I Trust You?” Explaining the Predictions of Any Classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1135–1144. [Google Scholar]
- Thorne, J.; Vlachos, A.; Cocarascu, O.; Christodoulopoulos, C.; Mittal, A. The Fact Extraction and VERification (FEVER) Shared Task. In Proceedings of the First Workshop on Fact Extraction and VERification (FEVER), Brussels, Belgium, 1 November 2018; pp. 1–9. [Google Scholar] [CrossRef]
- Soleimani, A.; Monz, C.; Worring, M. BERT for evidence retrieval and claim verification. In Advances in Information Retrieval, Proceedings of the 42nd European Conference on IR Research, ECIR 2020, Lisbon, Portugal, 14–17 April 2020, Proceedings, Part II; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2019; Volume 12036 LNCS, pp. 359–366. [Google Scholar] [CrossRef]
- Zhong, W.; Xu, J.; Tang, D.; Xu, Z.; Duan, N.; Zhou, M.; Wang, J.; Yin, J. Reasoning over semantic-level graph for fact checking. In Proceedings of the Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 6170–6180. [Google Scholar] [CrossRef]
- Jiang, K.; Pradeep, R.; Lin, J. Exploring Listwise Evidence Reasoning with T5 for Fact Verification. In Proceedings of the ACL-IJCNLP 2021—59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, Proceedings of the Conference, Virtual, 1–6 August 2021; Volume 2, pp. 402–410. [CrossRef]
- Chen, J.; Zhang, R.; Guo, J.; Fan, Y.; Cheng, X. GERE: Generative Evidence Retrieval for Fact Verification. In Proceedings of the SIGIR 2022—45th International ACM SIGIR Conference on Research and Development in Information Retrieval, Madrid, Spain, 11–15 July 2022; pp. 2184–2189. [Google Scholar] [CrossRef]
- DeHaven, M.; Scott, S. BEVERS: A General, Simple, and Performant Framework for Automatic Fact Verification. In Proceedings of the Sixth Fact Extraction and VERification Workshop (FEVER), Dubrovnik, Croatia, 5 May 2023; pp. 58–65. [Google Scholar]
- Krishna, A.; Riedel, S.; Vlachos, A. ProoFVer: Natural Logic Theorem Proving for Fact Verification. Trans. Assoc. Comput. Linguist. 2022, 10, 1013–1030. [Google Scholar] [CrossRef]
- Huang, Y.; Gao, M.; Wang, J.; Shu, K. DAFD: Domain Adaptation Framework for Fake News Detection. In Proceedings of the Neural Information Processing; Mantoro, T., Lee, M., Ayu, M.A., Wong, K.W., Hidayanto, A.N., Eds.; Springer International Publishing: Cham, Switzerland, 2021; pp. 305–316. [Google Scholar]
- Kotonya, N.; Toni, F. Explainable automated fact-checking for public health claims. In Proceedings of the EMNLP 2020—2020 Conference on Empirical Methods in Natural Language Processing; Online, 19–20 November 2020, pp. 7740–7754. [CrossRef]
- Popat, K.; Mukherjee, S.; Yates, A.; Weikum, G. Declare: Debunking fake news and false claims using evidence-aware deep learning. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, EMNLP 2018, Brussels, Belgium, 31 October–4 November 2018; pp. 22–32. [Google Scholar] [CrossRef]
- Jain, S.; Wallace, B.C. Attention is not Explanation. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 2–7 June 2019; pp. 3543–3556. [Google Scholar]
- Serrano, S.; Smith, N.A. Is attention interpretable? In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 2931–2951. [Google Scholar]
- Pruthi, D.; Gupta, M.; Dhingra, B.; Neubig, G.; Lipton, Z.C. Learning to deceive with attention-based explanations. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 4782–4793. [Google Scholar]
- Dai, S.C.; Hsu, Y.L.; Xiong, A.; Ku, L.W. Ask to Know More: Generating Counterfactual Explanations for Fake Claims. In Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Washington, DC, USA, 14–18 August 2022; pp. 2800–2810. [Google Scholar]
- Xu, W.; Liu, Q.; Wu, S.; Wang, L. Counterfactual Debiasing for Fact Verification. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Toronto, ON, Canada, 9–14 July 2023; pp. 6777–6789. [Google Scholar]
- Rashkin, H.; Choi, E.; Jang, J.Y.; Volkova, S.; Choi, Y. Truth of varying shades: Analyzing language in fake news and political fact-checking. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 7–11 September 2017; pp. 2931–2937. [Google Scholar] [CrossRef]
- Wang, W.Y. “Liar, Liar Pants on Fire”: A New Benchmark Dataset for Fake News Detection. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), Vancouver, BC, Canada, 30 July–4 August 2017; pp. 422–426. [Google Scholar] [CrossRef]
- Thorne, J.; Vlachos, A. Automated Fact Checking: Task Formulations, Methods and Future Directions. In Proceedings of the 27th International Conference on Computational Linguistics, Santa Fe, NM, USA, 20–26 August 2018; pp. 3346–3359. [Google Scholar]
- Shi, B.; Weninger, T. Discriminative predicate path mining for fact checking in knowledge graphs. Knowl.-Based Syst. 2016, 104, 123–133. [Google Scholar] [CrossRef]
- Gardner, M.; Mitchell, T. Efficient and expressive knowledge base completion using subgraph feature extraction. In Proceedings of the Conference Proceedings—EMNLP 2015: Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 1488–1498. [Google Scholar] [CrossRef]
- Bordes, A.; Usunier, N.; Garcia-Durán, A.; Weston, J.; Yakhnenko, O. Translating embeddings for modeling multi-relational data. In Advances in Neural Information Processing Systems, Proceedings of the 26th International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–10 December 2013; Curran Associates Inc.: Red Hook, NY, USA, 2013. [Google Scholar]
- Sheehan, E.; Meng, C.; Tan, M.; Uzkent, B.; Jean, N.; Burke, M.; Lobell, D.; Ermon, S. Predicting economic development using geolocated wikipedia articles. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 2698–2706. [Google Scholar]
- Brailas, A.; Koskinas, K.; Dafermos, M.; Alexias, G. Wikipedia in Education: Acculturation and learning in virtual communities. Learn. Cult. Soc. Interact. 2015, 7, 59–70. [Google Scholar] [CrossRef]
- Schwenk, H.; Chaudhary, V.; Sun, S.; Gong, H.; Guzmán, F. WikiMatrix: Mining 135M Parallel Sentences in 1620 Language Pairs from Wikipedia. In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, Online, 19–23 April 2021; pp. 1351–1361. [Google Scholar] [CrossRef]
- Shorten, C.; Khoshgoftaar, T.M.; Furht, B. Deep Learning applications for COVID-19. J. Big Data 2021, 8, 1–54. [Google Scholar] [CrossRef] [PubMed]
- Stammbach, D. Evidence Selection as a Token-Level Prediction Task. In Proceedings of the FEVER 2021—Fact Extraction and VERification, Proceedings of the 4th Workshop, Online, 10 November 2021; pp. 14–20. [CrossRef]
- Wadden, D.; Lin, S.; Lo, K.; Wang, L.L.; van Zuylen, M.; Cohan, A.; Hajishirzi, H. Fact or Fiction: Verifying Scientific Claims. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020; pp. 7534–7550. [Google Scholar] [CrossRef]
- Hanselowski, A.; Stab, C.; Schulz, C.; Li, Z.; Gurevych, I. A richly annotated corpus for different tasks in automated fact-checking. In Proceedings of the 23rd Conference on Computational Natural Language Learning (CoNLL), Hong Kong, China, 3–4 November 2019; pp. 493–503. [Google Scholar] [CrossRef]
- Thorne, J.; Vlachos, A.; Christodoulopoulos, C.; Mittal, A. FEVER: A Large-scale Dataset for Fact Extraction and VERification. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, New Orleans, LA, USA, 1–6 June 2018; pp. 809–819. [Google Scholar] [CrossRef]
- Augenstein, I.; Lioma, C.; Wang, D.; Chaves Lima, L.; Hansen, C.; Hansen, C.; Simonsen, J.G. MultiFC: A Real-World Multi-Domain Dataset for Evidence-Based Fact Checking of Claims. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 4685–4697. [Google Scholar] [CrossRef]
- Stammbach, D.; Ash, E. e-FEVER: Explanations and Summaries for Automated Fact Checking. In Proceedings of the Conference for Truth and Trust Online, Virtually, 16–17 October 2020; pp. 12–19. [Google Scholar] [CrossRef]
- Gad-Elrab, M.H.; Stepanova, D.; Urbani, J.; Weikum, G. Exfakt: A framework for explaining facts over knowledge graphs and text. In Proceedings of the Twelfth ACM International Conference on Web Search and Data Mining, Melbourne, VIC, Australia, 11–15 February 2019; pp. 87–95. [Google Scholar]
- Ahmadi, N.; Lee, J.; Papotti, P.; Saeed, M. Explainable Fact Checking with Probabilistic Answer Set Programming. In Proceedings of the Conference for Truth and Trust Online, London, UK, 4–5 October 2019. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
| Methodological Aspect | Examples | Drawbacks |
|---|---|---|
| Summarization Approach | Ref. [23] utilizes the transformer model for extractive summarization. Two models are trained separately and jointly. Ref. [34] Fine-tuned for both extractive and abstractive summarization. | May generate misleading or inaccurate explanations. Particularly problematic for abstractive models. |
| Logic-based Approach | Ref. [6] LOREN framework uses logical rules for transparency. Ref. [32] ProoFVer uses natural logic theorem proving. | Complexity and computational cost limit scalability. May not capture all nuances of natural language. |
| Attention-based Approach | Ref. [35] uses the attention mechanism to focus on salient words. Ref. [24] utilizes attention for feature and evidence highlighting. | Relies on human experts for visualizations, diverging from the principles of XAI. |
| Counterfactual Approach | Ref. [39] focuses on interpretability by generating counterfactual explanations in AFV through question answering and entailment reasoning. Ref. [40] proposes the CLEVER method, which operates from a counterfactual perspective to mitigate biases in veracity prediction within AFV. | May face complexity in interpreting minimal input changes, particularly in intricate factual claims and evidence scenarios, potentially hindering the broader interpretability. |
| Fact_Verification Dataset Type | Example_Studies | Knowledge_Type | Text_Type | Domain_Type | Remarks | |||
|---|---|---|---|---|---|---|---|---|
| Knowledge-Free | External Knowledge | Structured Data | Free Text | Single Domain | Multi Domain | |||
| Knowledge-free Systems | [41,42] | √ | × | − | − | − | − | Lack of contextual understanding; dataset-level explainability infeasible |
| Knowledge-Base-Based | [44,45] | × | × | √ | × | √ | √ | Limited scalability; inability to capture nuanced information |
| Wikipedia-Based | [54] | × | √ | × | √ | × | √ | Biased and inaccurate content; limited comprehensiveness |
| Domain (Single)-Specific Corpus | [52] | × | √ | × | √ | √ | × | Limited size; potential for biased evaluation |
| Mixed-domain Corpus (non-Wikipedia-based) | [53] | × | √ | × | √ | × | √ | Challenges in classification due to heterogeneous data (impacts accuracy); evidence from unreliable sources (impacts fidelity) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Vallayil, M.; Nand, P.; Yan, W.Q.; Allende-Cid, H. Explainability of Automated Fact Verification Systems: A Comprehensive Review. Appl. Sci. 2023, 13, 12608. https://doi.org/10.3390/app132312608
Vallayil M, Nand P, Yan WQ, Allende-Cid H. Explainability of Automated Fact Verification Systems: A Comprehensive Review. Applied Sciences. 2023; 13(23):12608. https://doi.org/10.3390/app132312608
Chicago/Turabian StyleVallayil, Manju, Parma Nand, Wei Qi Yan, and Héctor Allende-Cid. 2023. "Explainability of Automated Fact Verification Systems: A Comprehensive Review" Applied Sciences 13, no. 23: 12608. https://doi.org/10.3390/app132312608
APA StyleVallayil, M., Nand, P., Yan, W. Q., & Allende-Cid, H. (2023). Explainability of Automated Fact Verification Systems: A Comprehensive Review. Applied Sciences, 13(23), 12608. https://doi.org/10.3390/app132312608