
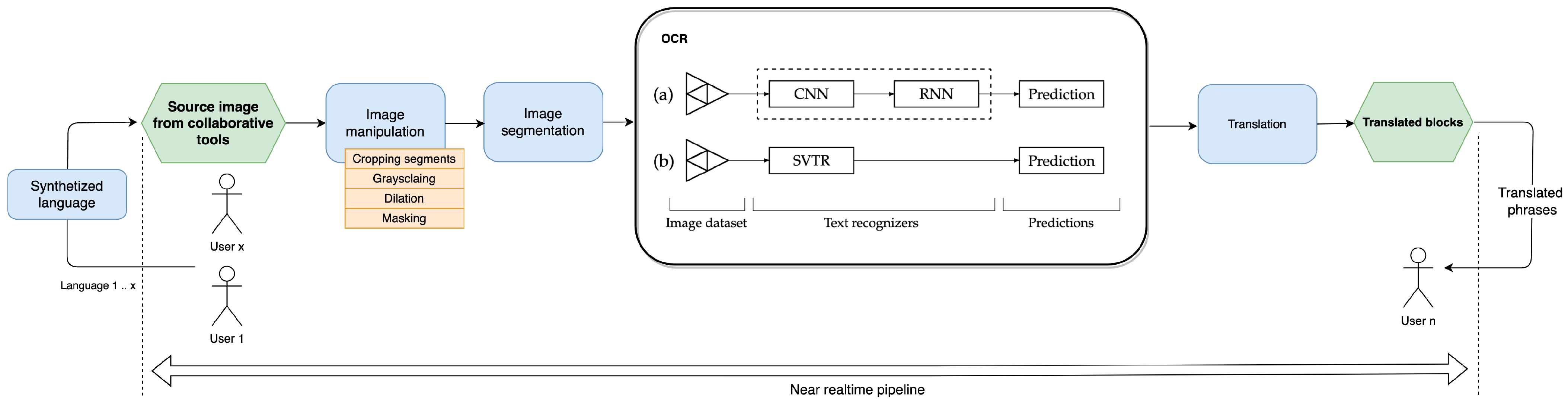
Synthetized Multilanguage OCR Using CRNN and SVTR Models for Realtime Collaborative Tools

 ,
,  , ,
, ,  and
and
Abstract
:1. Introduction
2. Novelty of the Approach
3. Objectives
- Customize hyperparameters of the PaddleOCR [28] system to accurately recognize text in multiple languages by using CRNN and SVTR models.
- Compare the performance of CRNN and SVTR models for multilanguage OCR to identify which model is more effective for this task.
- Evaluate the performance and limitations of the PaddleOCR on a large dataset of multilingual images.
- Investigate the impact of different multi/synthetic language models and parameters on the PaddleOCR system to identify which languages and vocabulary sets are more challenging for the system to recognize.
- Investigate the impact of different levels of text blurriness, distortion, and noise on the performance of the OCR system, to identify which image conditions are more challenging for the system to recognize.
- Investigate the scalability of the OCR system to handle large volumes of images, to ensure that it can handle real-time collaborative tasks efficiently.
- Investigate the robustness of the OCR system to handle different font types and sizes, to ensure that it can handle real-world scenarios efficiently.
- Investigate the customized vocabulary on synthesized, multilanguage models.
4. Materials and Methods
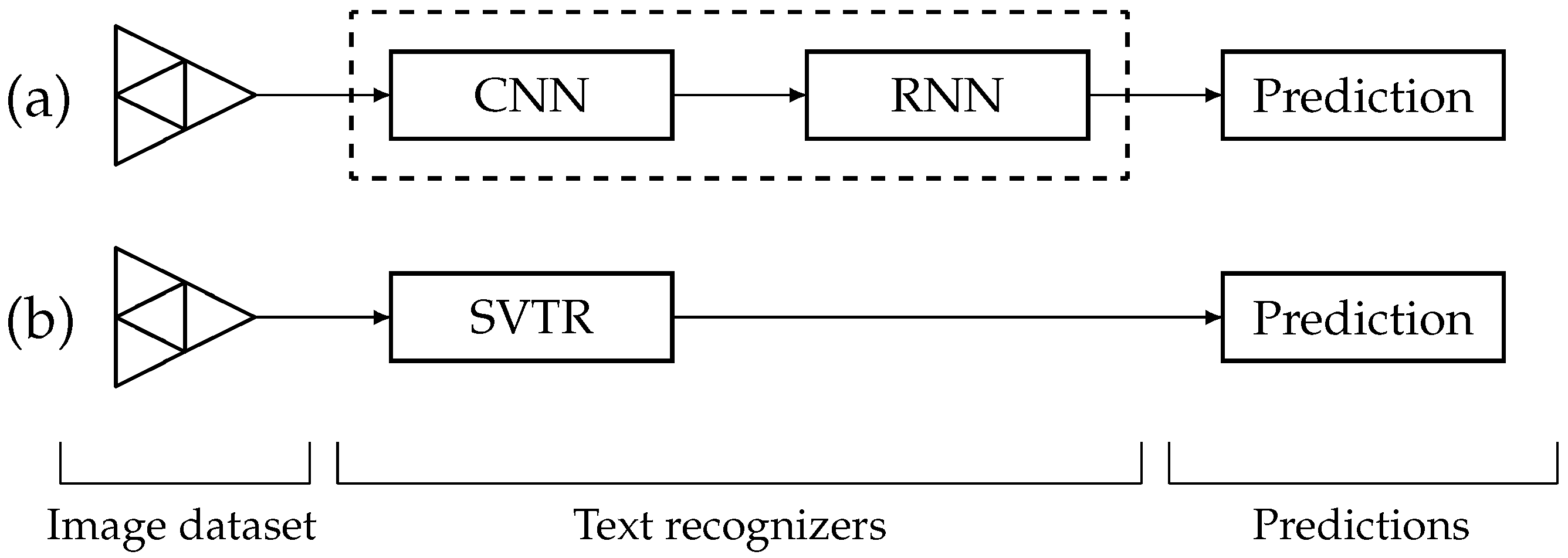
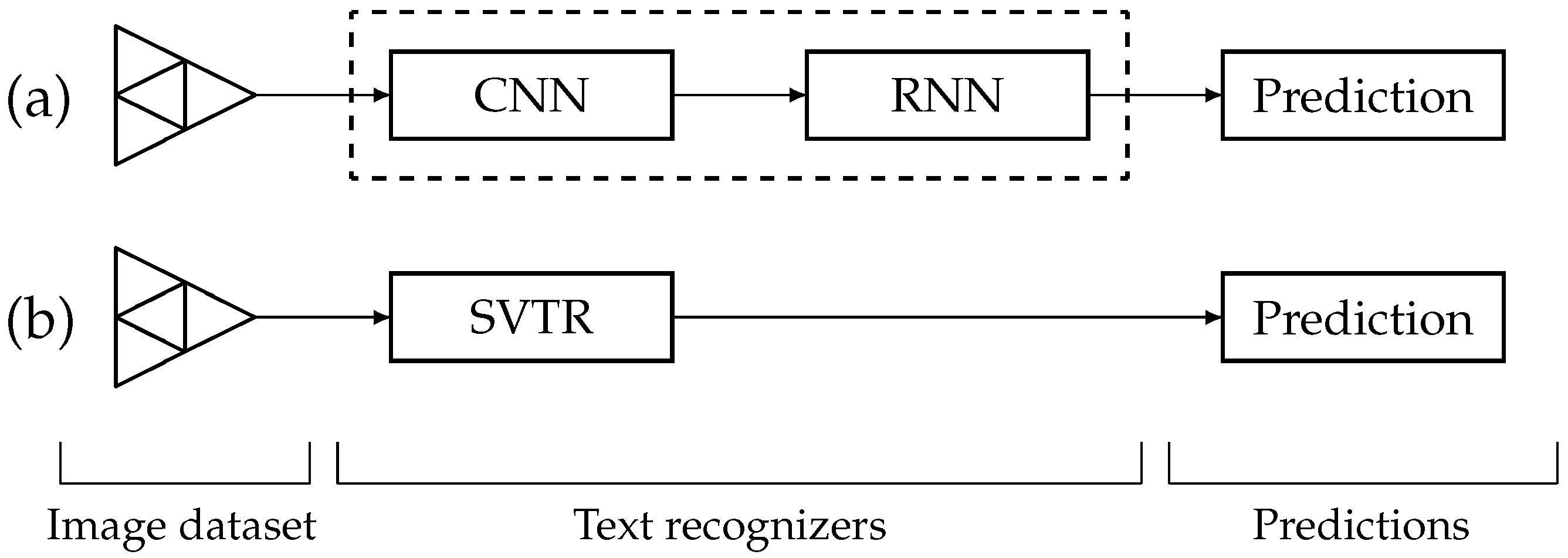
4.1. ML-Based Text Recognizers
4.2. CRNN Model Type
4.3. SVTR Model Type
4.4. Differences between CRNN and SVTR Models
- Inputs: CRNNs are designed to operate with image inputs, but SVTRs can process pictures, videos, and live video streams. CRNNs use a combination of CNNs and RNNs to detect text in images, whereas SVTRs use a combination of deep learning and conventional image processing techniques.
- Text recognition: CRNNs are adept at recognizing texts of various font styles, sizes, and orientations, as well as multiple lines of text in an image, and can perform well on scene text recognition, whereas SVTRs are specifically designed to handle scene text in images, which can vary significantly in terms of lighting, orientation, and skew.
- Attention mechanism: CRNNs lack an attention mechanism, but SVTRs possess one. This attention mechanism enables the network to concentrate on an image’s significant parts and increases the model’s noise and distortion resistance. Because of the attention mechanism they employ, SVTRs are more resistant to noise and distortion. CRNNs are susceptible to noise and distortion.
- Training and fine-tuning: Both CRNN and SVTR architectures are adaptive and can be fine-tuned with more data to increase their accuracy. However, CRNN models require substantial training data to produce accurate results. SVTR models, in contrast, can also learn from fewer data. CRNNs are quicker than conventional OCR engines because they can run on parallel architectures such as GPUs. In contrast, SVTRs can run on various platforms, including smartphones and embedded systems.
4.5. Hyperparameter Tuning
4.5.1. Max Epoch Number
4.5.2. Max Text Length
4.5.3. Optimizer
4.5.4. Learning Rate
4.5.5. Regularization Logic
4.5.6. Model Hidden Layers
4.6. Image Size
4.7. Batch Size
4.8. Data
4.8.1. Datasets and Volumes
4.8.2. Vocabularies
4.9. Experimental Environment
4.10. Pre-Processing
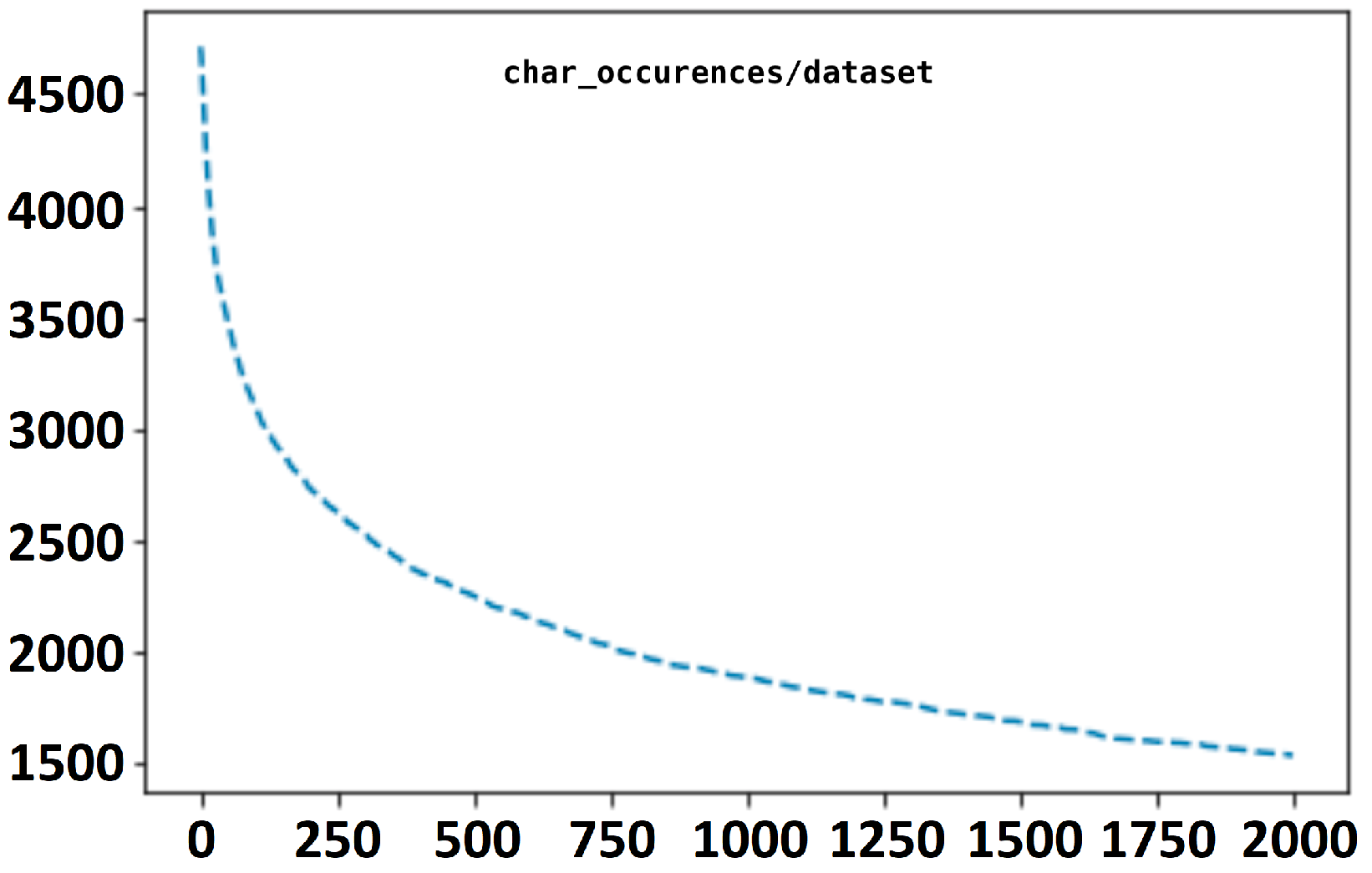
4.10.1. Exploratory Data Analysis
4.10.2. Vocabulary Generation
4.10.3. Filter, Split, and Save the Training Dataset
5. Data Analysis
6. Results
6.1. Settings
6.2. Accuracy
6.3. Project Results
6.3.1. English and Hungarian Multilanguage Experiments
6.3.2. Hungarian Single Language Experiments
6.3.3. Hybrid Multilanguage Experiments
7. Discussion
7.1. Single and Hybrid Language Results
7.1.1. English and Hungarian Multilanguage Experiments
7.1.2. Hungarian Single Language Experiments
7.1.3. Hybrid Multilanguage Experiments
8. Conclusions
- Multiline OCR: As a result of the documentation provided by Paddle OCR and the initial research, it was unclear whether PaddleOCR was capable performing of multiline OCR. We validated that the framework has limited multiline capabilities based on dedicated experiments if the vocabulary is small enough (100–200 characters) and the training examples are carefully selected. To handle multiline capabilities, it is necessary to have a GPU-intensive environment and an extensive training dataset in case we have to use a large or/and extended vocabulary (e.g., when we involve Asian languages with special characters in the vocabulary). This means a long training period as well.
- Vocabulary generation: There is no vocabulary generator tool in PaddleOCR. It is recommended to perform vocabulary generation manually or by using a dedicated tool.
- SVTR could not outperform CRNN: PaddleOCR released a version of its software during the experimental period that supports the Visual Transformer-based SVTR model. According to PaddleOCR, this new model architecture may perform better than the previous one (CRNN). Several experiments were conducted with the proposed model architecture, which underperformed the previous model architecture each time. Having conducted several experiments, we decided to return to the CRNN model.
- Character coding: A high-level view of OCR engines [42] shows that their operation is quite simple. Each character is identified by the model based on its appearance. However, some errors may be caused by this process. Let us assume that there are identically shaped characters that have different character codes. In the training process, the model will look at the given character and determine if it is one of the two options. The model will, however, indicate that it made a mistake if this character belongs to another character code. As a result, during the training process, the model will make some errors that will manifest themselves during the inference process. The problem can be solved by identifying similar characters and changing them to the selected symbols. They are referred to as homoglyphs [43,44,45]. The use of homoglyph filtering [44] is recommended.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| OCR | optical character recognition |
| AI | artificial intelligence |
| CNN | convolutional neural network |
| CRNN | Convolutional Recurrent Neural Networks |
| SVTR | Single Visual model for scene Text Recognition |
| PaddleOCR | Multilingual OCR toolkits based on PaddlePaddle |
| WANDB | Weight and Biases |
| ML | machine learning |
| NN | neural network |
| GRU | Gated Recurrent Unit |
| LR | Learning rate |
| Adam | alternative optimization algorithm |
| COVID-19 | Coronavirus disease |
| IT | information technology |
| LSTM | long short-term memory |
| RNN | Recurrent Neural Networks |
| EDA | Exploratory Data Analysis |
| JSON | JavaScript object notation |
| GPU | Graphics processing unit |
| CPU | Central processing unit |
| GB | gigabyte |
References
- Qaddumi, B.; Ayaad, O.; Al-Ma’aitah, M.A.; Akhu-Zaheya, L.; Alloubani, A. The factors affecting team effectiveness in hospitals: The mediating role of using electronic collaborative tools. J. Interprofessional Educ. Pract. 2021, 24, 100449. [Google Scholar] [CrossRef]
- Biró, A.; Jánosi-Rancz, K.T.; Szilágyi, L.; Cuesta-Vargas, A.I.; Martín-Martín, J.; Szilágyi, S.M. Visual Object Detection with DETR to Support Video-Diagnosis Using Conference Tools. Appl. Sci. 2022, 12, 5977. [Google Scholar] [CrossRef]
- Huang, J.; Pang, G.; Kovvuri, R.; Toh, M.; Liang, K.J.; Krishnan, P.; Yin, X.; Hassner, T. A Multiplexed Network for End-to-End, Multilingual OCR. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 4547–4557. [Google Scholar] [CrossRef]
- Li, L.C.; Gao, F.Y.; Bu, J.J.; Wang, Y.P.; Yu, Z.; Zheng, Q. An End-to-End OCR Text Reorganization Sequence Learning for Rich-text Detail Image Comprehension. European Conference on Computer Vision. LNCS 2020, 12370, 85–100. [Google Scholar] [CrossRef]
- Du, Y.N.; Li, C.X.; Guo, R.Y.; Yin, X.T.; Liu, W.W.; Zhou, J.; Bai, Y.F.; Yu, Z.L.; Yang, Y.H.; Dang, Q.Q.; et al. PP-OCR: A Practical Ultra Lightweight OCR System. arXiv 2020, arXiv:2009.09941. [Google Scholar]
- Du, Y.N.; Li, C.X.; Guo, R.Y.; Cui, C.; Liu, W.W.; Zhou, J.; Lu, B.; Yang, Y.H.; Liu, Q.; Hu, W.; et al. PP-OCRv2: Bag of Tricks for Ultra Lightweight OCR System. arXiv 2021, arXiv:2109.03144. [Google Scholar]
- Nguyen, T.T.H.; Jatowt, A.; Coustaty, M.; Doucet, A. Survey of Post-OCR Processing Approaches. ACM Comput. Surv. 2021, 6. [Google Scholar] [CrossRef]
- Zhao, Z.P.; Zhao, Y.Q.; Bao, Z.T.; Wang, H.S.; Zhang, Z.X.; Li, C. Deep Spectrum Feature Representations for Speech Emotion Recognition. In Proceedings of the Joint Workshop of the 4th Workshop on Affective Social Multimedia Computing and first Multi-Modal Affective Computing of Large-Scale Multimedia Data, Seoul, Republic of Korea, 26 October 2018; pp. 27–33. [Google Scholar] [CrossRef]
- Fischer-Suárez, N.; Lozano-Paniagua, D.; García-González, J.; Castro-Luna, G.; Requena-Mullor, M.; Alarcón-Rodríguez, R.; Parrón-Carreño, T.; Nievas-Soriano, B.J. Use of Digital Technology as a Collaborative Tool among Nursing Students—Survey Study and Validation. Int. J. Environ. Res. Public Health 2022, 19, 14267. [Google Scholar] [CrossRef]
- Li, X.; Zhang, Y.; Yuan, W.; Luo, J. Incorporating External Knowledge Reasoning for Vision-and-Language Navigation with Assistant’s Help. Appl. Sci. 2022, 12, 7053. [Google Scholar] [CrossRef]
- Bulut, S.Ö. Integrating machine translation into translator training: Towards ‘Human Translator Competence’? Translogos Transl. Stud. J. 2019, 2, 1–26. [Google Scholar] [CrossRef]
- Bizzoni, Y.; Juzek, T.S.; España-Bonet, C.; Chowdhury, K.D.; van Genabith, J.; Teich, E. How human is machine translationese? Comparing human and machine translations of text and speech. In Proceedings of the 17th International Conference on Spoken Language Translation; Association for Computational Linguistics: Online, 2020; pp. 280–290. [Google Scholar] [CrossRef]
- Zhang, B.; Bapna, A.; Sennrich, R.; Firat, O. Share or Not? Learning to Schedule Language-Specific Capacity for Multilingual Translation. In Proceedings of the International Conference on Learning Representations, Virtual, 3–7 May 2021; pp. 1–19. Available online: https://openreview.net/pdf?id=Wj4ODo0uyCF (accessed on 22 March 2023).
- Shekar, K.C.; Cross, M.A.; Vasudevan, V. Optical Character Recognition and Neural Machine Translation Using Deep Learning Techniques. In Innovations in Computer Science and Engineering. Lecture Notes in Networks and Systems; Saini, H.S., Sayal, R., Govardhan, A., Buyya, R., Eds.; Springer: Singapore, 2021; Volume 171, pp. 277–283. [Google Scholar] [CrossRef]
- Yang, J.; Yin, Y.W.; Ma, S.M.; Zhang, D.D.; Li, Z.J.; Wei, F.R. High-resource Language-specific Training for Multilingual Neural Machine Translation. Int. Jt. Conf. Artif. Intell. 2022, 4436–4442. [Google Scholar] [CrossRef]
- Qi, J.W.; Peng, Y.X. Cross-modal bidirectional translation via reinforcement learning. Int. Jt. Conf. Artif. Intell. 2018, 2630–2636. [Google Scholar] [CrossRef] [Green Version]
- Shin, J.H.; Georgiou, P.G.; Narayanan, S. Towards modeling user behavior in interactions mediated through an automated bidirectional speech translation system. Comput. Speech Lang. 2010, 24, 232–256. [Google Scholar] [CrossRef]
- Ding, L.A.; Wu, D.; Tao, D.C. Improving neural machine translation by bidirectional training. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing; Association for Computational Linguistics: Online; Punta Cana, Dominican Republic; 2021; pp. 3278–3284. [Google Scholar] [CrossRef]
- Kaur, J.; Goyal, V.; Kumar, M. Improving the accuracy of tesseract OCR engine for machine printed Hindi documents. AIP Conf. Proc. 2022, 2455, 040007. [Google Scholar] [CrossRef]
- Rijhwani, S.; Anastasopoulos, A.; Neubig, G. OCR Post Correction for Endangered Language Texts Pages. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), online, 16–20 November 2020; pp. 5931–5942. Available online: https://aclanthology.org/2020.emnlp-main.478.pdf (accessed on 22 March 2023).
- Gunna, S.; Saluja, R.; Jawahar, C.V. Improving Scene Text Recognition for Indian Languages with Transfer Learning and Font Diversity. J. Imaging 2022, 8, 86. [Google Scholar] [CrossRef]
- Ignat, O.; Maillard, J.; Chaudhary, V.; Guzmán, F. OCR Improves Machine Translation for Low-Resource Languages Pages. arXiv 2022, arXiv:2202.13274. [Google Scholar]
- Park, J.; Lee, E.; Kim, Y.; Kang, I.; Koo, H.I.; Cho, N.I. Multi-Lingual Optical Character Recognition System Using the Reinforcement Learning of Character Segmenter. IEEE Access 2020, 8, 174437–174448. [Google Scholar] [CrossRef]
- Gifu, D. AI-backed OCR in Healthcare. Procedia Comput. Sci. 2022, 207, 1134–1143. [Google Scholar] [CrossRef]
- Bartz, C.; Yang, H.J.; Meinel, C. STN-OCR: A single Neural Network for Text Detection and Text Recognition. arXiv 2017, arXiv:1707.08831. [Google Scholar]
- Lowe, A.; Harrison, N.; French, A.P. Hyperspectral image analysis techniques for the detection and classification of the early onset of plant disease and stress. Plant Methods 2017, 13, 80. [Google Scholar] [CrossRef] [PubMed]
- PaddleOCR. Available online: https://github.com/PaddlePaddle/PaddleOCR (accessed on 22 March 2023).
- Paddle Japanese Model—Japan Ultra-Lightweight OCR Model. Available online: https://github.com/1849349137/PaddleOCR (accessed on 22 March 2023).
- Wu, H.; Prasad, S. Convolutional Recurrent Neural Networks for Hyperspectral Data Classification. Remote Sens. 2017, 9, 298. [Google Scholar] [CrossRef] [Green Version]
- Du, Y.K.; Chen, Z.N.; Jia, C.Y.; Yin, X.T.; Zheng, T.L.; Li, C.X.; Du, Y.N.; Jiang, Y.G. SVTR: Scene Text Recognition with a Single Visual Model. In Proceedings of the 31st International Joint Conference on Artificial Intelligence Main Track, Vienna, Austria, 23–29 July; 2022. [Google Scholar]
- Kloft, M.; Stiehler, F.; Zheng, Z.L.; Pinkwart, N. Predicting MOOC Dropout over Weeks Using Machine Learning Methods. In EMNLP Workshop on Analysis of Large Scale Social Interaction in MOOCs; Association for Computational Linguistics: Doha, Qatar, 2014; pp. 60–65. [Google Scholar] [CrossRef] [Green Version]
- Al-Nabhi, H.; Krishna, K.; Abdullah, A.; Shareef, A. Efficient CRNN Recognition Approaches for Defective Characters in Images. Int. J. Comput. Digit. Syst. 2022, 12, 1417–1427. [Google Scholar] [CrossRef]
- Kang, P.; Singh, A.K. CTC—Problem Statement. The AI Learner. 2021. Available online: https://theailearner.com/ (accessed on 22 March 2023).
- Shi, B.; Bai, X.; Yao, C. An End-to-End Trainable Neural Network for Image-Based Sequence Recognition and Its Application to Scene Text Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2298–2304. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Keren, G.; Schuller, B. Convolutional RNN: An Enhanced Model for Extracting Features from Sequential Data. In Proceedings of the 2016 International Joint Conference on Neural Networks (IJCNN), Vancouver, BC, Canada, 24–29 July 2016; Available online: https://arxiv.org/pdf/1602.05875.pdf (accessed on 22 March 2023).
- Wu, H.; Prasad, S. Semi-Supervised Deep Learning Using Pseudo Labels for Hyperspectral Image Classification. IEEE Trans. Image Process. 2018, 27, 1259–1270. [Google Scholar] [CrossRef] [PubMed]
- Gan, Z.; Singh, P.D.; Joshi, A.; He, X.D.; Chen, J.S.; Gao, J.F.; Deng, L. Character-level Deep Conflation for Business Data Analytics. arXiv 2017, arXiv:1702.02640. [Google Scholar]
- Lee, T. EMD and LSTM Hybrid Deep Learning Model for Predicting Sunspot Number Time Series with a Cyclic Pattern. Sol. Phys. 2020, 295, 82. [Google Scholar] [CrossRef]
- Zhuang, J.; Ren, Y.; Li, X.; Liang, Z. Text-Level Contrastive Learning for Scene Text Recognition. In Proceedings of the 2022 International Conference on Asian Language Processing (IALP), Singapore, 27–28 October 2022; pp. 231–236. [Google Scholar] [CrossRef]
- Jung, M.J.; Lee, H.; Tani, J. Adaptive detrending to accelerate convolutional gated recurrent unit training for contextual video recognition. Neural Netw. J. 2018, 105, 356–370. [Google Scholar] [CrossRef] [Green Version]
- Brownlee, J. Understand the Impact of Learning Rate on Neural Network Performance. Deep. Learn. Perform. 2019. Available online: https://machinelearningmastery.com/understand-the-dynamics-of-learning-rate-on-deep-learning-neural-networks(accessed on 22 March 2023).
- Schneider, P.; Maurer, Y. Rerunning OCR: A Machine Learning Approach to Quality Assessment and Enhancement Prediction. J. Data Min. Digit. Humanit. 2021, 2022, 1–14. [Google Scholar] [CrossRef]
- Almuhaideb, A.M.; Aslam, N.; Alabdullatif, A.; Altamimi, S.; Alothman, S.; Alhussain, A.; Aldosari, W.; Alsunaidi, S.J.; Alissa, K.A. Homoglyph Attack Detection Model Using Machine Learning and Hash Function. J. Sens. Actuator Netw. 2022, 11, 54. [Google Scholar] [CrossRef]
- Majumder, M.T.H.; Rahman, M.M.; Iqbal, A.; Rahman, M.S. Convolutional Neural Network Based Ensemble Approach for Homoglyph Recognition. Math. Comput. Appl. 2020, 25, 71. [Google Scholar] [CrossRef]
- Suzuki, H.; Chiba, D.; Yoneya, Y.; Mori, T.; Goto, S. ShamFinder: An Automated Framework for Detecting IDN Homographs. In Proceedings of the IMC’19: ACM Internet Measurement Conference, Amsterdam, The Netherlands, 21–23 October 2019; pp. 449–462. [Google Scholar] [CrossRef] [Green Version]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 1cProject | Name | Data | Training Size | Evaluation Size |
|---|---|---|---|---|
| OCR_hun | 155k_hu_v2_2 | hun_train | 77 k | 15 k |
| OCR_hun | 155k_hu_v2_1 | hun_train | 77 k | 15 k |
| OCR_enhu | SVTR | training1 | 66 k | 33 k |
| OCR_enhu | CRNN | training1 | 66 k | 33 k |
| OCR_multilang | 5M_enhujp_v2_8 | training10-200 | 5 M | 101 k |
| OCR_multilang | 5M_enhujp_v2_6 | training9-200 | 5 M | 101 k |
| OCR_multilang | 5M_enhujp_v2_5 | training10-200 | 5 M | 101 k |
| OCR_multilang | 5M_enhujp_v2_4 | training9-200 | 5 M | 101 k |
| OCR_multilang | 5M_enhujp_v2_3 | training8-200 | 8.5 M | 170 k |
| OCR_multilang | 5M_enhujp_v2_2 | training8-200 | 8.5 M | 170 k |
| OCR_multilang | 5M_enhujp_v2_1 | training7-100 | 5 M | 100 k |
| OCR_multilang | 10M_enhujp_v3_1 | training8-200 | 8.5 M | 170 k |
| OCR_multilang | 5M_enhujp_v3_4 | training7-100 | 5 M | 100 k |
| OCR_multilang | 5M_enhujp_v3_3 | training7-100 | 5 M | 100 k |
| OCR_multilang | 5M_enhujp_v3_2 | training7-100 | 5 M | 100 k |
| OCR_multilang | 4M_enhujp_pre_v3_1 | training6 | 4.4 M | 88 k |
| OCR_multilang | 4M_enhujp_pre_v3_1 | training6 | 4.4 M | 88 k |
| OCR_multilang | 4M_enhujp_v3_5 | training6 | 4.4 M | 88 k |
| OCR_multilang | 4M_enhujp_v3_4 | training6 | 4.4 M | 88 k |
| OCR_multilang | 2M_enhujp_v2_2 | training3 | 2 M | 220 k |
| OCR_hun | 186k_hu_v2_1 | training2 | 186 k | 34 k |
| Character Dictionary | Dict Size (Characters) | Vocabulary Type |
|---|---|---|
| 606k_hun_vocab.txt | 112 | Generated |
| extended_vocab.txt | 201 | Unified |
| training9-200_vocab_min9500.txt | 803 | Generated |
| training9-200_vocab_min200.txt | 2737 | Generated |
| jpn_latin_dict.txt | 4444 | Unified |
| 4M_vocab.txt | 4721 | Generated |
| 4M_min20_vocab.txt | 3980 | Generated |
| 2M_min2k_vocab.txt | 968 | Generated |
| 186k_extended_vocab.txt | 112 | Unified |
| Experiment Name | Data | Character Dictionary | Dictionary Size | Train Batch Size | Evaluation Batch Size | Training Size | Evaluation Size |
|---|---|---|---|---|---|---|---|
| 155k_hu_v2_2 | hun_train | 606 k_hun_vocab.txt | 112 | 128 | 128 | 77 k | 15 k |
| 155k_hu_v2_1 | hun_train | 606k_hun_vocab.txt | 112 | 600 | 256 | 77 k | 15 k |
| SVTR | training1 | extended_vocab.txt | 201 | 128 | 128 | 66 k | 33 k |
| CRNN | training1 | extended_vocab.txt | 201 | 768 | 256 | 66 k | 33 k |
| 5M_enhujp_v2_8 | training10-200 | training9-200_vocab_min9500.txt | 803 | 48 | 48 | 5 M | 101 k |
| 5M_enhujp_v2_6 | training9-200 | training9-200_vocab_min200.txt | 2737 | 64 | 64 | 5 M | 101 k |
| 5M_enhujp_v2_5 | training10-200 | training9-200_vocab_min9500.txt | 803 | 48 | 48 | 5 M | 101 k |
| 5M_enhujp_v2_4 | training9-200 | training9-200_vocab_min200.txt | 2737 | 64 | 64 | 5 M | 101 k |
| 5M_enhujp_v2_3 | training8-200 | jpn_latin_dict.txt | 4444 | 50 | 50 | 8.5 M | 170 k |
| 5M_enhujp_v2_2 | training8-200 | jpn_latin_dict.txt | 4444 | 30 | 30 | 8.5 M | 170 k |
| 5M_enhujp_v2_1 | training7-100 | jpn_latin_dict.txt | 4444 | 50 | 50 | 5 M | 100 k |
| 10M_enhujp_v3_1 | training8-200 | jpn_latin_dict.txt | 4444 | 60 | 60 | 8.5 M | 170 k |
| 5M_enhujp_v3_4 | training7-100 | jpn_latin_dict.txt | 4444 | 50 | 50 | 5 M | 100 k |
| 5M_enhujp_v3_3 | training7-100 | jpn_latin_dict.txt | 4444 | 50 | 50 | 5 M | 100 k |
| 5M_enhujp_v3_2 | training7-100 | jpn_latin_dict.txt | 4444 | 50 | 50 | 5 M | 100 k |
| 4M_enhujp_pre_v3_1 | training6 | jpn_latin_dict.txt | 4444 | 24 | 24 | 4.4 M | 88 k |
| 4M_enhujp_pre_v3_1 | training6 | jpn_latin_dict.txt | 4444 | 28 | 28 | 4.4 M | 88 k |
| 4M_enhujp_v3_5 | training6 | 4M_vocab.txt | 4721 | 28 | 28 | 4.4 M | 88 k |
| 4M_enhujp_v3_4 | training6 | 4 M_min20_vocab.txt | 3980 | 28 | 28 | 4.4 M | 88 k |
| 2M_enhujp_v2_2 | training3 | 2M_min2k_vocab.txt | 968 | 64 | 64 | 2 M | 220 k |
| 186 k_hu_v2_1 | training2 | 186 k_extended_vocab.txt | 112 | 128 | 128 | 186 k | 34 k |
| Experiment Name | Data | Character Dictionary | Dictionary size | Train Batch Size | Learning Rate | Max Text Length | Image Shape | Epoch Number | Warmup Epochs |
|---|---|---|---|---|---|---|---|---|---|
| 155k_hu_v2_2 | hun_train | 606k_hun_vocab.txt | 112 | 128 | 0.0050 | 100 | [3, 32, 512] | 2000 | 2 |
| 155k_hu_v2_1 | hun_train | 606k_hun_vocab.txt | 112 | 600 | 0.0050 | 100 | [3, 32, 128] | 2000 | 2 |
| SVTR | training1 | extended_vocab.txt | 201 | 128 | 0.0010 | 150 | [3, 48, 320] | 100 | 5 |
| CRNN | training1 | extended_vocab.txt | 201 | 768 | 0.0005 | 250 | [3, 32, 100] | 100 | 0 |
| 5M_enhujp_v2_8 | training10-200 | training9-200_vocab_min9500.txt | 803 | 48 | 0.0005 | 200 | [3, 32, 1024] | 100 | 1 |
| 5M_enhujp_v2_6 | training9-200 | training9-200_vocab_min200.txt | 2737 | 64 | 0.0050 | 200 | [3, 32, 1024] | 100 | 1 |
| 5M_enhujp_v2_5 | training10-200 | training9-200_vocab_min9500.txt | 803 | 48 | 0.0050 | 200 | [3, 32, 1024] | 100 | 2 |
| 5M_enhujp_v2_4 | training9-200 | training9-200_vocab_min200.txt | 2737 | 64 | 0.0050 | 200 | [3, 32, 1024] | 100 | 2 |
| 5M_enhujp_v2_3 | training8-200 | jpn_latin_dict.txt | 4444 | 50 | 0.0050 | 200 | [3, 32, 1024] | 100 | 2 |
| 5M_enhujp_v2_2 | training8-200 | jpn_latin_dict.txt | 4444 | 30 | 0.0050 | 200 | [3, 32, 2048] | 100 | 2 |
| 5M_enhujp_v2_1 | training7-100 | jpn_latin_dict.txt | 4444 | 50 | 0.0050 | 100 | [3, 32, 1024] | 100 | 2 |
| 10M_enhujp_v3_1 | training8-200 | jpn_latin_dict.txt | 4444 | 60 | 0.0010 | 200 | [3, 32, 1024] | 50 | 0 |
| 5M_enhujp_v3_4 | training7-100 | jpn_latin_dict.txt | 4444 | 50 | 0.0001 | 100 | [3, 32, 512] | 50 | 0 |
| 5M_enhujp_v3_3 | training7-100 | jpn_latin_dict.txt | 4444 | 50 | 0.0001 | 100 | [3, 32, 512] | 50 | 0 |
| 5M_enhujp_v3_2 | training7-100 | jpn_latin_dict.txt | 4444 | 50 | 0.0001 | 110 | [3, 32, 512] | 50 | 0 |
| 4M_enhujp_pre_v3_1 | training6 | jpn_latin_dict.txt | 4444 | 24 | 0.0005 | 200 | [3, 32, 768] | 50 | 0 |
| 4M_enhujp_pre_v3_1 | training6 | jpn_latin_dict.txt | 4444 | 28 | 0.0005 | 200 | [3, 32, 768] | 50 | 2 |
| 4M_enhujp_v3_5 | training6 | 4M_vocab.txt | 4721 | 28 | 0.0010 | 200 | [3, 32, 768] | 50 | 0 |
| 4M_enhujp_v3_4 | training6 | 4M_min20_vocab.txt | 3980 | 28 | 0.0005 | 200 | [3, 32, 768] | 50 | 0 |
| 2M_enhujp_v2_2 | training3 | 2M_min2k_vocab.txt | 968 | 64 | 0.0050 | 200 | [3, 32, 1024] | 100 | 2 |
| 186k_hu_v2_1 | training2 | 186k_extended_vocab.txt | 112 | 128 | 0.0050 | 100 | [3, 32, 512] | 2000 | 2 |
| Name | Image Shape | Train Batch Size | Learning Rate | Warmup Epochs | Train Epochs | Steps | Train Best Acc | Train Min Loss | Train Best Norm Edit Dist | Eval Best Accuracy |
|---|---|---|---|---|---|---|---|---|---|---|
| 155k_hu_v2_2 | [3, 32, 512] | 128 | 0.0050 | 2 | 673 | 407,677 | 0.949 | 3.623 | 0.985 | 0.857 |
| 155k_hu_v2_1 | [3, 32, 128] | 600 | 0.0050 | 2 | 1224 | 157,896 | 0.301 | 0.002 | 0.475 | 0.272 |
| SVTR | [3, 48, 320] | 128 | 0.0010 | 5 | 100 | 17,225 | 0.055 | 0.970 | 0.177 | 0.001 |
| CRNN | [3, 32, 100] | 768 | 0.0005 | 0 | 100 | 1521 | 0.003 | 0.963 | 0.119 | 0.002 |
| 5M_enhujp_v2_8 | [3, 32, 1024] | 48 | 0.0005 | 1 | 21 | 1,287,568 | 0.958 | 0.260 | 0.999 | 0.938 |
| 5M_enhujp_v2_6 | [3, 32, 1024] | 64 | 0.0050 | 1 | 23 | 867,561 | 0.938 | 0.529 | 0.997 | 0.909 |
| 5M_enhujp_v2_5 | [3, 32, 1024] | 48 | 0.0050 | 2 | 4 | 350,376 | 0.885 | 4.871 | 0.976 | 0.850 |
| 5M_enhujp_v2_4 | [3, 32, 1024] | 64 | 0.0050 | 2 | 6 | 209,172 | 0.922 | 0.628 | 0.998 | 0.902 |
| 5M_enhujp_v2_3 | [3, 32, 1024] | 50 | 0.0050 | 2 | 2 | 314,836 | 0.780 | 13.366 | 0.968 | 0.736 |
| 5M_enhujp_v2_2 | [3, 32, 2048] | 30 | 0.0050 | 2 | 3 | 391,741 | 0.767 | 10.594 | 0.976 | 0.716 |
| 5M_enhujp_v2_1 | [3, 32, 1024] | 50 | 0.0050 | 2 | 39 | 921,738 | 0.920 | 2.545 | 0.989 | 0.888 |
| 10M_enhujp_v3_1 | [3, 32, 1024] | 60 | 0.0010 | 0 | 3 | 179,147 | 0.483 | 6.961 | 0.704 | 0.448 |
| 5M_enhujp_v3_4 | [3, 32, 512] | 50 | 0.0001 | 0 | 18 | 408,688 | 0.750 | 4.010 | 0.904 | 0.714 |
| 5M_enhujp_v3_3 | [3, 32, 512] | 50 | 0.0001 | 0 | 14 | 322,937 | 0.690 | 5.179 | 0.901 | 0.678 |
| 5M_enhujp_v3_2 | [3, 32, 512] | 50 | 0.0001 | 0 | 3 | 116,924 | 0.300 | 2.998 | 0.574 | 0.272 |
| 4M_enhujp_pre_v3_1 | [3, 32, 768] | 24 | 0.0005 | 0 | 6 | 537,619 | 0.500 | 1.427 | 0.681 | 0.443 |
| 4M_enhujp_pre_v3_1 | [3, 32, 768] | 28 | 0.0005 | 2 | 1 | 57,629 | 0.429 | 2.108 | 0.668 | 0.381 |
| 4M_enhujp_v3_5 | [3, 32, 768] | 28 | 0.0010 | 0 | 3 | 176,068 | 0.429 | 2.305 | 0.737 | 0.399 |
| 4M_enhujp_v3_4 | [3, 32, 768] | 28 | 0.0005 | 0 | 3 | 159,235 | 0.464 | 1.903 | 0.704 | 0.423 |
| 2M_enhujp_v2_2 | [3, 32, 1024] | 64 | 0.0050 | 2 | 100 | 1,644,300 | 0.672 | 41.946 | 0.912 | 0.648 |
| 186k_hu_v2_1 | [3, 32, 512] | 128 | 0.0050 | 2 | 267 | 194,505 | 0.961 | 2.341 | 0.990 | 0.927 |
| Experiment: CRNN Model | Experiment: SVTR Model | |
|---|---|---|
| Architecture | CRNN | SVTR |
| Training data | training1 | |
| Training data size | 66 k | |
| Vocabulary | extended_vocab.txt | |
| Vocab size | 201 | |
| Epochs | 100 | |
| Max text length | 250 | 150 |
| Image shape (H × W) | 32 × 100 | 48 × 320 |
| Learning rate | 0.0005 | 0.001 |
| Regularization | None | 0.00003 |
| Best Train acc | 0.26% | 5.47% |
| Best Train loss | 0.96 | 0.97 |
| Best Distance score | 11.92% | 17.71% |
| Best Eval acc | 0.16% | 0.11% |
| Experiment: Training 1 | Experiment: Training 2 | |
|---|---|---|
| Architecture | CRNN | |
| Training data | hun_train | |
| Training data size | 77 k | |
| Vocabulary | 606k_hun_vocab.txt | |
| Vocab size | 112 | |
| Epochs | 1224 | 673 |
| Max text length | 100 | |
| Image shape (H × W) | 32 × 128 | 32 × 512 |
| Learning rate | 0.005 | |
| Regularization | 0.000002 | |
| Best Train acc | 30.08% | 94.92% |
| Best Train loss | 0.002 | 3.623 |
| Best Distance score | 46.55% | 98.46% |
| Best Eval acc | 27.18% | 85.73% |
| Experiment: 186k_hu_v2_1 | |
|---|---|
| Architecture | CRNN |
| Training data | training2 |
| Training data size | 186 k |
| Vocabulary | 186k_extended_vocab.txt |
| Vocab size | 112 |
| Epochs | 267 |
| Max text length | 100 |
| Image shape (H × W) | 32 × 512 |
| Learning rate | 0.005 |
| Regularization | 0.000005 |
| Best Train acc | 96.09% |
| Best Train loss | 2.3410 |
| Best Distance score | 99.02% |
| Best Eval acc | 92.75% |
| Experiment 1: 4M_enhujp_v3_4 | Experiment 2: 4M_enhujp_v3_5 | |
|---|---|---|
| Architecture | SVTR | |
| Training data | training6 | |
| Training data size | 4.4 M | |
| Vocabulary | 4M_min20_vocab.txt | 4M_vocab.txt |
| Vocab size | 3980 | 4721 |
| Epochs | 3 | |
| Max text length | 200 | |
| Image shape (H × W) | 32 × 768 | |
| Learning rate | 0.0005 | 0.001 |
| Regularization | 0.000015 | 0.00004 |
| Best Train acc | 46.43% | 42.86% |
| Best Train loss | 1.9033 | 2.3046 |
| Best Distance score | 70.41% | 73.69% |
| Best Eval acc | 42.29% | 39.87% |
| Exp 3: 5M_enhujp_v3_2 | Exp 4: 5M_enhujp_v3_3 | Exp 5: 5M_enhujp_v3_4 | |
|---|---|---|---|
| Architecture | SVTR | ||
| Training data | training7-100 | ||
| Training data size | 5 M | ||
| Vocabulary | jpn_latin_dict.txt | ||
| Vocab size | 4444 | ||
| Epochs | 3 | 14 | 18 |
| Max text length | 110 | 100 | |
| Image shape (H × W) | 32 × 512 | ||
| Learning rate | 0.0001 | ||
| Regularization | 0.00005 | ||
| Best Train acc | 30% | 69% | 75% |
| Best Train loss | 2.998 | 5.1791 | 4.0096 |
| Best Distance score | 57.44% | 90.10% | 90.44% |
| Best Eval acc | 27.24% | 67.76% | 71.35% |
| Exp 6: 4M_enhujp_pre_v3_1 | Exp 7: 10M_enhujp_v3_1 | |
|---|---|---|
| Architecture | SVTR | |
| Training data | training6 | training8-200 |
| Training data size | 4.4 M | 8.5 M |
| Vocabulary | jpn_latin_dict.txt | |
| Vocab size | 4444 | |
| Epochs | 6 | 3 |
| Max text length | 200 | |
| Image shape (H × W) | 32 × 768 | 32 × 1024 |
| Learning rate | 0.0005 | 0.001 |
| Regularization | 0.000015 | 0.0001 |
| Best Train acc | 50% | 48.33% |
| Best Train loss | 1.427 | 6.9611 |
| Best Distance score | 68.05% | 70.35% |
| Best Eval acc | 44.32% | 44.81% |
| Exp 8: 5M_enhujp_v2_1 | Exp 9: 5M_enhujp_v2_2 | Exp 10: 5M_enhujp_v2_3 | |
|---|---|---|---|
| Architecture | CRNN | ||
| Training data | training7-100 | training8-200 | |
| Training data size | 5 M | 8.5 M | |
| Vocabulary | jpn_latin_dict.txt | ||
| Vocab size | 4444 | ||
| Epochs | 39 | 3 | 2 |
| Max text length | 100 | 200 | |
| Image shape (H × W) | 32 × 1024 | 32 × 2048 | 32 × 1024 |
| Learning rate | 0.005 | ||
| Regularization | 0.000005 | 0.00005 | |
| Best Train acc | 92% | 76,67% | 78% |
| Best Train loss | 2.5454 | 10.594 | 13.366 |
| Best Distance score | 98.87% | 97.60% | 96.81% |
| Best Eval acc | 88.83% | 71.56% | 73.56% |
| Exp 11: 5M_enhujp_v2_4 | Exp 12: 5M_enhujp_v2_6 | Exp 13: 5M_enhujp_v2_5 | Exp 14: 5M_enhujp_v2_8 | |
|---|---|---|---|---|
| Architecture | CRNN | |||
| Training data | training9-200 | training10-200 | ||
| Training data size | 5 M | |||
| Vocabulary | training9-200_vocab_min200.txt | training9-200_vocab_min9500.txt | ||
| Vocab size | 2737 | 803 | ||
| Epochs | 6 | 31 | 4 | 26 |
| Max text length | 200 | |||
| Image shape (H × W) | 32 × 1024 | 32 × 768 | ||
| Learning rate | 0.005 | 0.0005 | ||
| Regularization | 0.00005 | 0.0001 | 0.00005 | 0.0001 |
| Best Train acc | 92.19% | 93.75% | 88.54% | 95.83% |
| Best Train loss | 0.6278 | 0.5287 | 4.8713 | 0.2601 |
| Best Distance score | 99.76% | 99.75% | 97.65% | 99.92% |
| Best Eval acc | 90.25% | 91.35% | 85.02% | 93.89% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Biró, A.; Cuesta-Vargas, A.I.; Martín-Martín, J.; Szilágyi, L.; Szilágyi, S.M. Synthetized Multilanguage OCR Using CRNN and SVTR Models for Realtime Collaborative Tools. Appl. Sci. 2023, 13, 4419. https://doi.org/10.3390/app13074419
Biró A, Cuesta-Vargas AI, Martín-Martín J, Szilágyi L, Szilágyi SM. Synthetized Multilanguage OCR Using CRNN and SVTR Models for Realtime Collaborative Tools. Applied Sciences. 2023; 13(7):4419. https://doi.org/10.3390/app13074419
Chicago/Turabian StyleBiró, Attila, Antonio Ignacio Cuesta-Vargas, Jaime Martín-Martín, László Szilágyi, and Sándor Miklós Szilágyi. 2023. "Synthetized Multilanguage OCR Using CRNN and SVTR Models for Realtime Collaborative Tools" Applied Sciences 13, no. 7: 4419. https://doi.org/10.3390/app13074419
APA StyleBiró, A., Cuesta-Vargas, A. I., Martín-Martín, J., Szilágyi, L., & Szilágyi, S. M. (2023). Synthetized Multilanguage OCR Using CRNN and SVTR Models for Realtime Collaborative Tools. Applied Sciences, 13(7), 4419. https://doi.org/10.3390/app13074419