
High-Resolution Multi-Scale Feature Fusion Network for Running Posture Estimation


Abstract
1. Introduction
2. Related Work
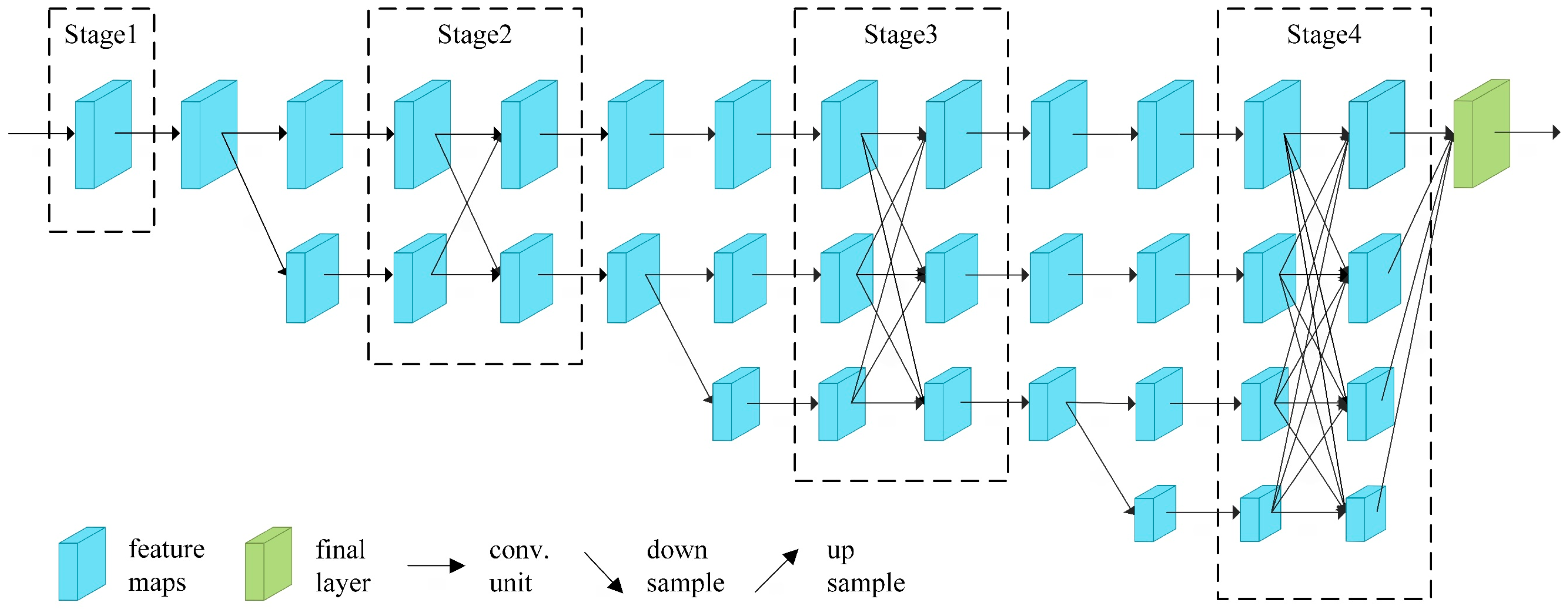
2.1. Multi-Branch High-Resolution Human Pose Estimation Networks
2.2. Gaussian Heatmap
2.3. Multi-Scale Feature Fusion
3. Method
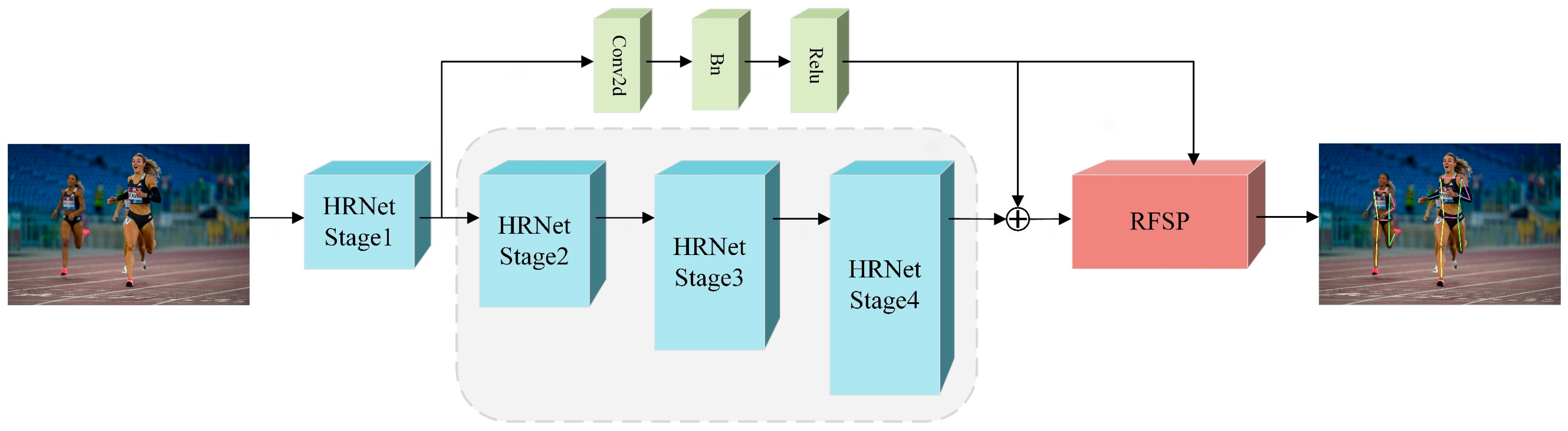
3.1. RHPNet Architecture
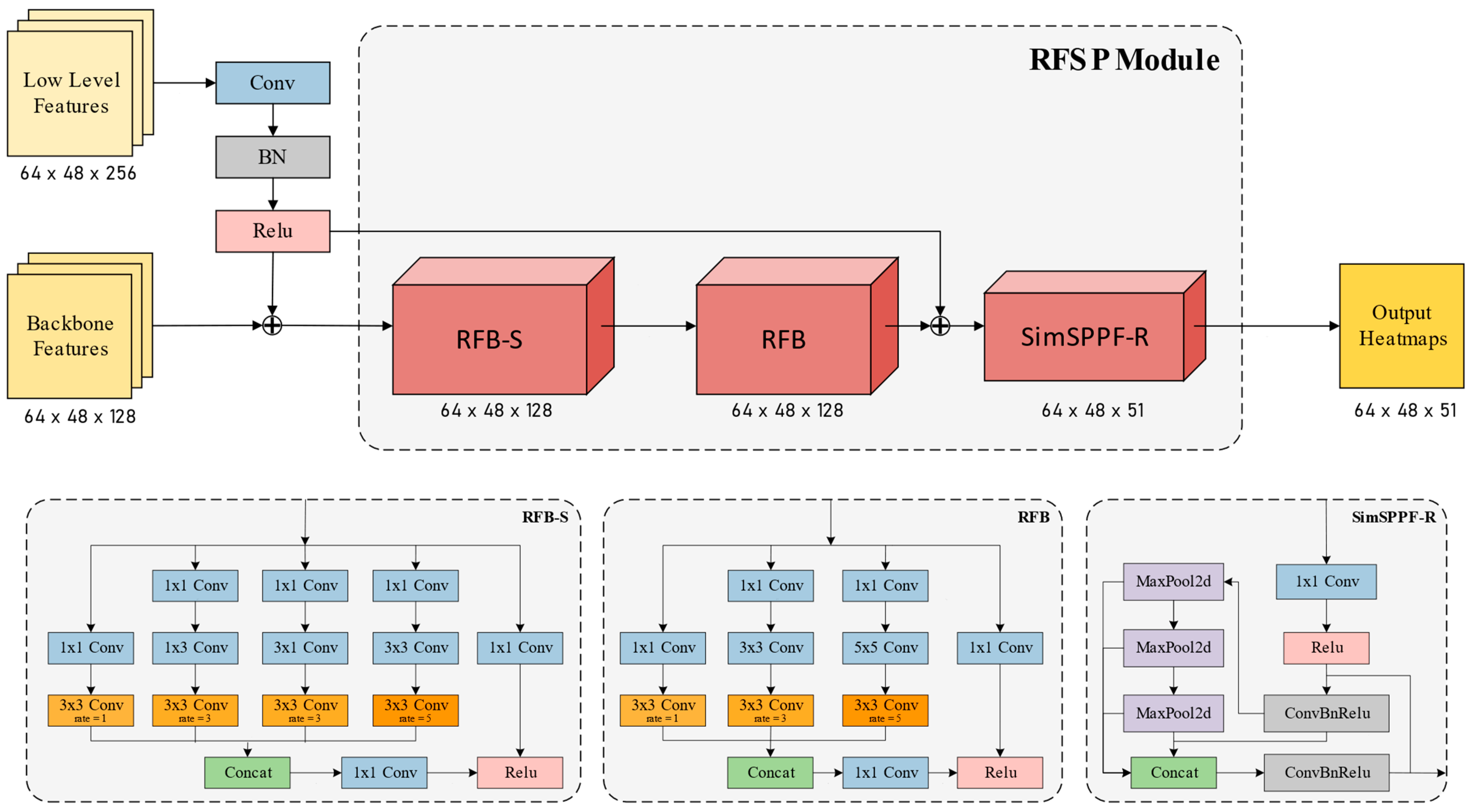
3.2. RFSP Module
3.3. Loss Function
3.4. Dataset
3.4.1. Running Human Dataset
- Dataset Annotations
- Dataset Split
- Dataset Augmentation
3.4.2. COCO Dataset
3.4.3. MPII Dataset
4. Experiments
4.1. Experiment Methods
4.2. Evaluation Metric
4.3. Results from the Running Human Dataset
4.4. Results on the COCO Dataset
4.5. Results on the MPII Dataset
4.6. Ablation Study
4.6.1. The Main Modules of RHPNet
4.6.2. The RFB Module
4.6.3. Augmentation of the Running Human Dataset
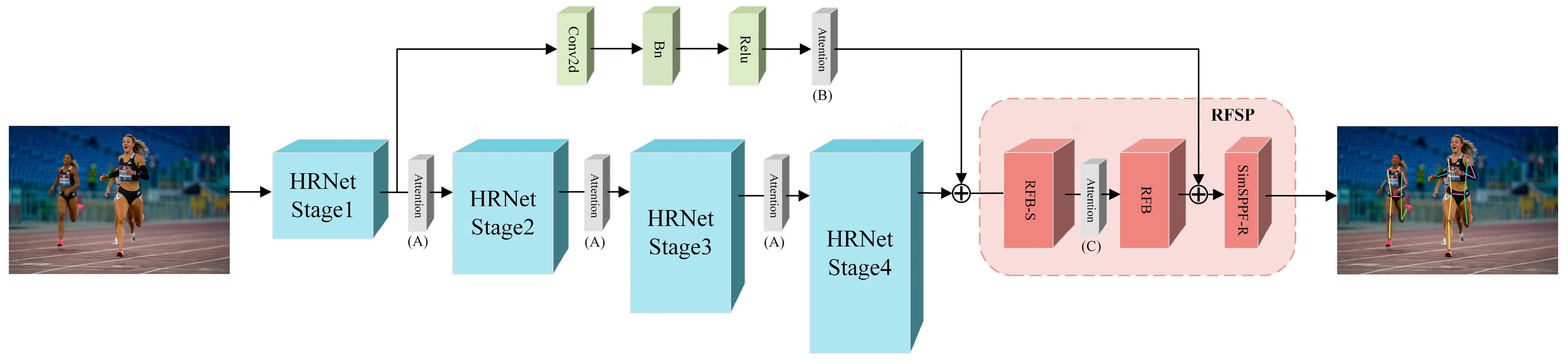
4.6.4. Attention Modules in RHPNet
4.6.5. Choice of Optimizer
5. Conclusions and Future Works
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Toshev, A.; Szegedy, C. DeepPose: Human Pose Estimation via Deep Neural Networks. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1653–1660. [Google Scholar]
- Alejandro, N.; Yang, K.; Deng, J. Stacked hourglass networks for human pose estimation. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part VIII 14. Springer International Publishing: New York, NY, USA, 2016. [Google Scholar]
- Bin, X.; Wu, H.; Wei, Y. Simple baselines for human pose estimation and tracking. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Sun, K.; Xiao, B.; Liu, D.; Wang, J. Deep high-resolution representation learning for human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Proceedings, Part V 13. Springer International Publishing: New York, NY, USA, 2014. [Google Scholar]
- Xu, Y.; Zhang, J.; Zhang, Q.; Tao, D. Vitpose: Simple vision transformer baselines for human pose estimation. Adv. Neural Inf. Process. Syst. 2022, 35, 38571–38584. [Google Scholar]
- Geng, Z.; Wang, C.; Wei, Y.; Liu, Z.; Li, H.; Hu, H. Human pose as compositional tokens. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2023. [Google Scholar]
- Andriluka, M.; Pishchulin, L.; Gehler, P.; Schiele, B. 2D Human Pose Estimation: New Benchmark and State of the Art Analysis. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; Available online: https://ieeexplore.ieee.org/document/6909866 (accessed on 24 June 2023).
- Cheng, B.; Xiao, B.; Wang, J.; Shi, H.; Huang, T.S.; Zhang, L. HigherHRNet: Scale-Aware Representation Learning for Bottom-Up Human Pose Estimation. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2019, Seattle, WA, USA, 13–19 June 2020. [Google Scholar] [CrossRef]
- Zhang, H.; Ouyang, H.; Liu, S.; Qi, X.; Shen, X.; Yang, R.; Jia, J. Human pose estimation with spatial contextual information. arXiv 2019, arXiv:1901.01760. [Google Scholar]
- Su, Z.; Ye, M.; Zhang, G.; Dai, L.; Sheng, J. Cascade feature aggregation for human pose estimation. arXiv 2019, arXiv:1902.07837. [Google Scholar]
- Cai, Y.; Wang, Z.; Luo, Z.; Yin, B.; Du, A.; Wang, H.; Zhang, X.; Zhou, X.; Zhou, E.; Sun, J. Learning delicate local representations for multi-person pose estimation. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part III 16. Springer International Publishing: New York, NY, USA, 2020. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. Available online: https://ieeexplore.ieee.org/document/8237584 (accessed on 24 June 2023).
- Tompson, J.; Goroshin, R.; Jain, A.; LeCun, Y.; Bregler, C. Efficient object localization using convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Ke, L.; Chang, M.C.; Qi, H.; Lyu, S. Multi-scale structure-aware network for human pose estimation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Lin, G.; Milan, A.; Shen, C.; Reid, I. Refinenet: Multi-path refinement networks for high-resolution semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef]
- Liu, S.; Huang, D. Receptive Field Block Net for Accurate and Fast Object Detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; Available online: https://link.springer.com/chapter/10.1007/978-3-030-01252-6_24 (accessed on 24 June 2023).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. In Computer Vision–ECCV 2014. ECCV 2014. Lecture Notes in Computer Science; Spring: Cham, Switzerland, 2014; Volume 8691, pp. 346–361. [Google Scholar]
- Wandell, B.A.; Winawer, J. Computational Neuroimaging and Population Receptive Fields. Trends Cogn. Sci. 2015, 19, 349–357. [Google Scholar] [CrossRef] [PubMed]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A single-stage object detection framework for industrial applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Zhong, Z.; Zheng, L.; Kang, G.; Li, S.; Yang, Y. Random erasing data augmentation. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34. [Google Scholar]
- Chen, P.; Liu, S.; Zhao, H.; Jia, J. Gridmask data augmentation. arXiv 2020, arXiv:2001.04086. [Google Scholar]
- Huang, J.; Zhu, Z.; Guo, F.; Huang, G. The Devil Is in the Details: Delving into Unbiased Data Processing for Human Pose Estimation. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2020; pp. 5699–5708. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Artacho, B.; Savakis, A. Omnipose: A multi-scale framework for multi-person pose estimation. arXiv 2021, arXiv:2103.10180. [Google Scholar]
- Johnson, S.; Everingham, M. Clustered Pose and Nonlinear Appearance Models for Human Pose Estimation. Br. Mach. Vis. Conf. 2010, 2, 5. [Google Scholar]
- Liu, H.; Liu, F.; Fan, X.; Huang, D. Polarized self-attention: Towards high-quality pixel-wise regression. arXiv 2021, arXiv:2107.00782. [Google Scholar]
- Zhang, F.; Zhu, X.; Dai, H.; Ye, M.; Zhu, C. Distribution-aware coordinate representation for human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Yang, S.; Quan, Z.; Nie, M.; Yang, W. TransPose: Keypoint Localization via Transformer. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 11782–11792. [Google Scholar]
- Li, Y.; Zhang, S.; Wang, Z.; Yang, S.; Yang, W.; Xia, S.T.; Zhou, E. Tokenpose: Learning keypoint tokens for human pose estimation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 10–17 October 2021. [Google Scholar]
- Yuan, Y.; Rao, F.; Lang, H.; Lin, W.; Zhang, C.; Chen, X.; Wang, J. Hrformer: High-resolution transformer for dense prediction. arXiv 2021, arXiv:2110.09408. [Google Scholar]
- Li, Y.; Yang, S.; Liu, P.; Zhang, S.; Wang, Y.; Wang, Z.; Yang, W.; Xia, S.T. Simcc: A simple coordinate classification perspective for human pose estimation. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022. [Google Scholar]
- Bin, Y.; Cao, X.; Chen, X.; Ge, Y.; Tai, Y.; Wang, C.; Li, J.; Huang, F.; Gao, C.; Sang, N. Adversarial semantic data augmentation for human pose estimation. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XIX 16. Springer International Publishing: New York, NY, USA, 2020. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate Attention for Efficient Mobile Network Design. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 13708–13717. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Backbone | Input Size | Params | GFLOPs | AP | AP50 | AP75 | APM | APL | AR |
|---|---|---|---|---|---|---|---|---|---|---|
| HRNet-W32 [4] | HRNet-W32 | 256 × 192 | 28.5 M | 7.10 | 93.3 | 96.9 | 95.9 | 81.1 | 94.0 | 94.2 |
| Simple Baseline [3] | ResNet-50 | 256 × 192 | 34.0 M | 8.90 | 91.5 | 95.9 | 93.9 | 79.2 | 92.2 | 92.2 |
| Simple Baseline [3] | ResNet-152 | 256 × 192 | 68.6 M | 15.7 | 92.6 | 96.0 | 96.0 | 86.5 | 93.1 | 93.3 |
| OmniPose [26] | HRNet-W48 | 256 × 192 | 68.2 M | 17.1 | 83.8 | 94.7 | 87.5 | 63.0 | 85.2 | 84.9 |
| PCT [7] | Swin-Base | 256 × 256 | - | 15.2 | 78.7 | 89.6 | 83.5 | 66.1 | 79.6 | 83.0 |
| PCT [7] | Swin-Large | 256 × 256 | - | 34.1 | 78.8 | 89.1 | 82.5 | 70.3 | 79.6 | 83.2 |
| ViTPose-B [6] | ViT-Base | 256 × 192 | 86 M | 17.9 | 84.2 | 90.7 | 87.4 | 55.1 | 86.1 | 85.3 |
| UDP-Pose-PSA [28] | HRNet-W32 | 256 × 192 | 34.0 M | 9.60 | 94.1 | 96.0 | 96.0 | 86.2 | 94.3 | 94.4 |
| RHPNet | HRNet-W32 | 256 × 192 | 30.5 M | 7.51 | 95.7 | 98.0 | 97.0 | 92.5 | 95.9 | 96.3 |
| Method | Backbone | Input Size | Params | GFLOPs | AP | AP50 | AP75 | APM | APL | AR |
|---|---|---|---|---|---|---|---|---|---|---|
| Simple Baseline [3] | ResNet-152 | 256 × 192 | 68.6 M | 15.7 | 72.0 | 89.3 | 79.8 | 68.7 | 78.9 | 77.8 |
| Simple Baseline [3] | ResNet-152 | 384 × 288 | 68.6 M | 35.6 | 74.3 | 89.6 | 81.1 | 70.5 | 79.7 | 79.7 |
| HRNet-W32 [4] | HRNet-W32 | 256 × 192 | 28.5 M | 7.10 | 74.4 | 90.5 | 81.9 | 70.8 | 81.0 | 79.8 |
| HRNet-W32 [4] | HRNet-W32 | 384 × 288 | 28.5 M | 16.0 | 75.8 | 90.6 | 82.7 | 71.9 | 82.8 | 81.0 |
| HRNet-W48 [4] | HRNet-W48 | 256 × 192 | 63.6 M | 14.6 | 75.1 | 90.6 | 82.2 | 71.5 | 81.8 | 80.4 |
| HRNet-W48 [4] | HRNet-W48 | 384 × 288 | 63.6 M | 32.9 | 76.3 | 90.8 | 82.9 | 72.3 | 83.4 | 81.2 |
| UDP-Pose [24] | HRNet-W48 | 384 × 288 | 63.6 M | 32.9 | 77.8 | 92.0 | 84.3 | 74.2 | 84.5 | 82.5 |
| DarkPose [29] | HRNet-W48 | 384 × 288 | 63.6 M | 33.0 | 76.8 | 90.6 | 83.2 | 72.8 | 84.0 | 81.7 |
| TransPose [30] | HRNet-W48 | 256 × 192 | 18 M | 21.8 | 75.8 | 90.1 | 82.1 | - | - | 80.8 |
| TokenPose [31] | HRNet-W48 | 256 × 192 | 28 M | 22.1 | 75.8 | 90.3 | 82.5 | - | - | 80.9 |
| HRFormer-B [32] | HRFormer-B | 256 × 192 | 43 M | - | 75.6 | - | - | - | - | 80.8 |
| HRFormer-B [32] | HRFormer-B | 384 × 288 | 43 M | 29.1 | 77.2 | 91.0 | 83.6 | - | - | 82.0 |
| ViTPose-B [6] | ViT-Base | 256 × 192 | 86 M | 17.9 | 75.8 | 90.7 | 83.2 | - | - | 81.1 |
| ViTPose-L [6] | ViT-Large | 256 × 192 | 307 M | 59.8 | 78.3 | 91.4 | 85.2 | - | - | 83.5 |
| PCT [7] | Swin-Base | 256 × 256 | - | 15.2 | 77.7 | 91.2 | 84.7 | - | - | - |
| PCT [7] | Swin-Large | 256 × 256 | - | 34.1 | 78.3 | 91.4 | 85.3 | - | - | - |
| RHPNet | HRNet-W32 | 256 × 192 | 30.5 M | 7.51 | 78.3 | 93.5 | 84.7 | 75.6 | 83.0 | 81.0 |
| Method | Head | Shoulder | Elbow | Wrist | Hip | Knee | Ankle | Mean | Mean@0.1 |
|---|---|---|---|---|---|---|---|---|---|
| Simple Baseline [3] | 97.0 | 95.9 | 90.0 | 85.0 | 89.2 | 85.3 | 81.3 | 89.6 | 35.0 |
| HRNet-W32 [4] | 97.1 | 95.9 | 90.3 | 86.4 | 89.1 | 87.1 | 83.3 | 90.3 | 37.7 |
| DarkPose [29] | 97.2 | 95.9 | 91.2 | 86.7 | 89.7 | 86.7 | 84.0 | 90.6 | 42.0 |
| UDP-Pose [24] | 97.4 | 96.0 | 91.0 | 86.5 | 89.1 | 86.6 | 83.3 | 90.4 | 42.1 |
| SimCC [33] | 97.2 | 96.0 | 90.4 | 85.6 | 89.5 | 85.8 | 81.8 | 90.0 | - |
| TokenPose [31] | 97.1 | 95.9 | 90.4 | 86.0 | 89.3 | 87.1 | 82.5 | 90.2 | - |
| 4 × RSN-50 [12] | 96.7 | 96.7 | 92.3 | 88.2 | 90.3 | 89.0 | 85.3 | 91.6 | - |
| ASDA [34] | 97.3 | 96.5 | 91.7 | 87.9 | 90.8 | 88.2 | 84.2 | 91.4 | - |
| PCT [7] | 97.5 | 97.2 | 92.8 | 88.4 | 92.4 | 89.6 | 87.1 | 92.5 | - |
| RHPNet | 97.5 | 96.8 | 92.2 | 88.9 | 90.7 | 89.4 | 86.1 | 92.0 | 44.3 |
| Method | SimSPPF-R | RFB | RFB-S | AP | APM | APL |
|---|---|---|---|---|---|---|
| HRNet-w32 | 93.3 | 81.1 | 94.0 | |||
| RHPNet | ✓ | 95.2 | 89.5 | 95.6 | ||
| RHPNet | ✓ | ✓ | 95.4 | 90.5 | 95.7 | |
| RHPNet | ✓ | ✓ | 94.9 | 87.6 | 95.2 | |
| RHPNet | ✓ | ✓ | ✓ | 95.7 | 92.5 | 95.9 |
| Dataset | Sequence | AP | APM | APL | |
| Running Human | RFB + RFB-S | 95.5 | 91.7 | 95.6 | |
| RFB-S + RFB | 95.7 | 92.5 | 95.9 | ||
| COCO 2017 | RFB + RFB-S | 78.1 | 74.9 | 82.8 | |
| RFB-S + RFB | 78.3 | 75.6 | 83.0 | ||
| Dataset | Sequence | Mean | Mean@0.1 | ||
| MPII | RFB + RFB-S | 91.9 | 43.8 | ||
| RFB-S + RFB | 92.0 | 44.3 | |||
| Dataset | Combination | AP | APM | APL |
|---|---|---|---|---|
| Running Human | RFB + RFB | 94.6 | 88.7 | 94.9 |
| RFB-S + RFB-S | 94.3 | 90.2 | 94.5 | |
| RFB-S + RFB | 95.7 | 92.5 | 95.9 |
| Method | Data Augmentation | AP | APM | APL |
|---|---|---|---|---|
| HRNet | 93.0 | 87.7 | 93.3 | |
| ✓ | 93.3 | 81.1 | 94.0 | |
| RHPNet | 94.5 | 90.1 | 94.7 | |
| ✓ | 95.7 | 92.5 | 95.9 |
| Method | Dataset | Location | AP | APM | APL | |
|---|---|---|---|---|---|---|
| RHPNet | Running Human | 95.7 | 92.5 | 95.9 | ||
| +PSA [28] | Running Human | Basic Block (A) | 95.3(−0.4) | 90.3 | 95.6 | |
| +PSA [28] | Running Human | Skip Connect (B) | 95.1(−0.6) | 91.5 | 95.2 | |
| +PSA [28] | Running Human | RFSP (C) | 95.5(−0.2) | 91.2 | 95.7 | |
| +CA [35] | Running Human | RFSP (C) | 95.0(−0.7) | 90.9 | 95.3 | |
| +CBAM [36] | Running Human | RFSP (C) | 94.9(−0.8) | 89.4 | 95.1 | |
| Method | Dataset | Location | Mean | Mean@0.1 | ||
| RHPNet | MPII | 92.0 | 44.3 | |||
| +PSA [28] | MPII | Basic Block (A) | 91.7(−0.3) | 43.8 | ||
| +PSA [28] | MPII | Skip Connect (B) | 91.6(−0.4) | 43.2 | ||
| Optimizer | AP | APM | APL |
|---|---|---|---|
| SGD | 84.4 | 73.9 | 85.2 |
| Adadelta | 82.2 | 76.9 | 82.7 |
| AdamW | 95.5 | 91.3 | 95.9 |
| Adam | 95.7 | 92.5 | 95.9 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, X.; Zhang, Y. High-Resolution Multi-Scale Feature Fusion Network for Running Posture Estimation. Appl. Sci. 2024, 14, 3065. https://doi.org/10.3390/app14073065
Xu X, Zhang Y. High-Resolution Multi-Scale Feature Fusion Network for Running Posture Estimation. Applied Sciences. 2024; 14(7):3065. https://doi.org/10.3390/app14073065
Chicago/Turabian StyleXu, Xiaobing, and Yaping Zhang. 2024. "High-Resolution Multi-Scale Feature Fusion Network for Running Posture Estimation" Applied Sciences 14, no. 7: 3065. https://doi.org/10.3390/app14073065
APA StyleXu, X., & Zhang, Y. (2024). High-Resolution Multi-Scale Feature Fusion Network for Running Posture Estimation. Applied Sciences, 14(7), 3065. https://doi.org/10.3390/app14073065