1. Introduction
The Transformer model, since its inception by [
1], has revolutionized the field of natural language processing (NLP) with its unparalleled ability to capture the intricacies of language through self-attention mechanisms. A pivotal feature of Transformer-based large language models (LLMs) is their capability for in-context learning (ICL) [
2], enabling them to adapt to new tasks without explicit retraining, merely by conditioning on few-shot examples provided within their input context. This ability not only showcases the flexibility of Transformer-based models, but also underscores the importance of the context window—the span of tokens a model can consider at any given time. The size of this context window directly influences the number of examples that can be included for in-context learning, thereby impacting the model’s performance on tasks requiring understanding and synthesis of information spread across longer texts.
The concept of the context window is foundational to understanding how Transformers operate. In essence, it determines the maximum scope of direct relationships and dependencies that the model can learn and leverage for prediction. A larger context window allows the inclusion of more examples for in-context learning, facilitating a richer understanding of context and enabling the model to make more informed predictions. Conversely, a smaller context window restricts the model’s ability to capture long-range dependencies, potentially limiting its effectiveness in tasks that necessitate a comprehensive grasp of extended narratives or arguments.
Position encoding plays a crucial role in enabling Transformers to process sequential data. Unlike traditional sequential models such as RNN [
3] and LSTM [
4], Transformers do not inherently process data in sequence. Instead, they treat input as a set of tokens without any inherent order. Position encoding injects this missing sequence information, allowing the model to differentiate between the same word appearing in different positions within the text. The evolution from absolute to relative position encoding [
5] has been a significant milestone in the development of Transformers, allowing models to better generalize to different sequence lengths and more effectively capture the relational dynamics within sequences.
While techniques such as ALiBi [
6] and LeX [
7] enable length extrapolation, they risk insufficient long-range dependencies due to their explicit long-range decay. Many LLMs, including LLaMA [
8], GPT-NeoX [
9], and PaLM [
10], utilize RoPE [
11] for their positional encoding. RoPE, without explicit long-range decay, is crucial for models targeting long contexts. It distinguishes between long and short ranges through varying frequencies of trigonometric functions, akin to hierarchical positional encoding, which is vital for long context processing. RoPE’s direct application to Q and K, compatibility with Flash Attention, and scalability underscore the importance of finding an effective method to extend its context window.
Despite the advances in position encoding techniques, extending the effective context window of Transformers, especially for large language models (LLMs) such as GPT-NeoX, LLaMA, and PaLM, remains a significant challenge. These models, employing RoPE for their position encoding, must balance the need for long-context understanding with the computational and memory constraints inherent in processing large sequences.
Current approaches for extending the context window, including Positional Interpolation (PI) [
12], Neural Tangent Kernel (NTK) [
13], and YaRN [
14], tackle various facets of this issue, yet each has its own drawbacks. PI, for example, compresses the space between tokens, potentially distorting the model’s understanding of local context—a critical aspect for language models, given their reliance on local relationships for prediction accuracy. NTK, while offering a mathematical framework for extending context windows, can suffer from practical issues such as out-of-bounds rotation angles, leading to suboptimal extrapolation performance. YaRN attempts to mitigate some of these issues by partitioning the NTK approach, but it introduces additional complexity and necessitates fine-tuning of hyperparameters for each specific model.
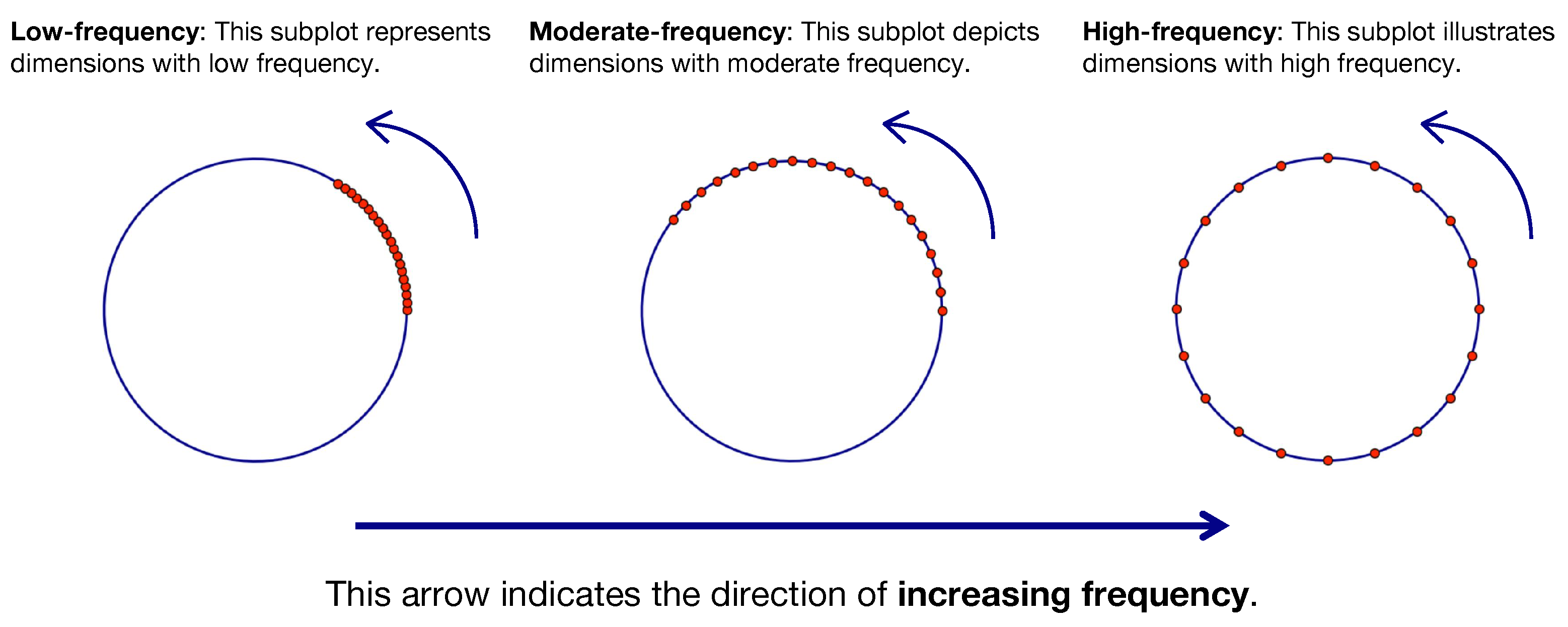
To address these limitations, we propose Segmental Base Adjustment for RoPE (SBA-RoPE), a novel technique aimed at expanding the context window of pre-trained LLMs by strategically adjusting the base values used in RoPE. By selectively extrapolating high-frequency dimensions and interpolating those with maximum angles less than
, we treat length extrapolation as a prediction-stage Out-Of-Distribution (OOD) problem. RoPE allocates different angles to different dimensions, with some high-frequency dimensions having fully learned all angles within 0 to
. Extrapolating these dimensions does not degrade performance, as these angles have been thoroughly trained during pre-training. However, some low-frequency dimensions have only learned partial angles within 0 to
, making them unable to extrapolate on longer texts and only able to interpolate. Thus, due to the periodic nature of trigonometric functions, even with high-frequency dimensions extrapolated, the thoroughly trained angles within 0 to
during pre-training do not cause a perplexity explosion problem. Meanwhile, by selecting interpolation for low-frequency dimensions, OOD is avoided for these dimensions. This process is illustrated in
Figure 1. SBA-RoPE facilitates an efficient extension of the context window with minimal fine-tuning. This method not only preserves the model’s performance for tasks within the original context window, but also enhances its adaptability to tasks that demand longer contexts.
Our contributions are as follows:
We introduce SBA-RoPE, a novel method for extending the context window of LLMs by segmentally adjusting the base of Rotary Position Embeddings, requiring only minimal fine-tuning steps.
For tasks within the original context window, our method minimally impacts model performance, showing minimal degradation compared to the original Pythia-2.8B model based on the GPT-NeoX architecture.
For tasks in the extended context window, our method achieves comparable or superior performance on passkey and perplexity tasks, indicating our model’s ability to generalize to longer lengths without sacrificing performance.
2. Backgrounds and Methods
2.1. Background: Rotary Position Embedding
In transformer models, positional information needs to be provided in some way, which is typically achieved through positional encoding. The positional encoding used in models such as GPT-NeoX and LLaMA is the Rotary Position Embedding (RoPE). Given a position index
and an embedding vector
, where
d is the dimension of the attention heads, RoPE defines the complex function as Equation (
1):
where
denotes the imaginary unit and
, where in RoPE,
is typically set to 10,000. With RoPE, the calculation of self-attention scores is performed as Equation (
2):
The value of
depends only on the relative position
, where
and
are query and key vectors. In Cartesian coordinates, RoPE can be written as Equation (
3):
It should be noted that this transformation of RoPE is equivalent to rotating (where ) in complex space. This is why this type of positional encoding is named Rotary Position Encoding, with the corresponding rotation angles being the focus of extrapolation research on out-of-distribution in longer texts.
2.2. Positional Interpolation
Since Large Language Models (LLMs) are typically pre-trained with fixed context lengths, such as 2048 for LLaMA, 4096 for LLaMA-2, and 2048 for Pythia models (based on GPT-NeoX), it is a natural idea to extend the context length by fine-tuning with a small amount of data. The first method to extend the existing LLMs using fine-tuning was Position Interpolation (PI) [
12], where it was found that directly extrapolating the angles of RoPE through fine-tuning did not yield satisfactory results. However, the effect of fine-tuning with Position Interpolation showed promising results in extending the context window. They modified the RoPE method as Equation (
4):
where
L represents the maximum context length during pre-training and
is the larger context length used during fine-tuning. They empirically demonstrated that decent results could be achieved on the new context length with just 1000 steps of fine-tuning.
2.3. NTK Interpolation
Although Position Interpolation has shown some effectiveness in extending the context window, models fine-tuned using this method suffer performance degradation within the original context window [
14]. The reason for this performance degradation is apparent: while position interpolation avoids the issue of RoPE rotation angle out-of-bounds at large indices, it compresses the distance between tokens, severely disrupting the model’s local resolution. Given that language modeling heavily relies on local relationships, disrupting local relationships inevitably leads to inaccurate predictions.
NTK [
13] addresses the “local distortion” problem caused by stretching all dimensions equally in PI. They derive NTK Interpolation using Neural Tangent Kernel (NTK) theory as Equations (
5) and (
6):
where
represents the scaling factor,
is the value used in RoPE during pre-training,
is the new corresponding value used during fine-tuning, and
d denotes the embedding dimension of the attention head. This adjustment avoids uniformly stretching all dimensions, instead dispersing interpolation pressure across multiple dimensions. After this adjustment, the lowest-frequency dimensions are scaled similarly to PI, while the highest-frequency dimensions remain unchanged (i.e., unscaled). It is noteworthy that this adjustment offers an ability to extend the context window without the need for fine-tuning. However, when used for fine-tuning, this method may lead to out-of-bounds values in some dimensions compared to the maximum rotation angles during pre-training, resulting in performance degradation.
YaRN [
14] proposes segment-wise adjustment of
values in RoPE based on the period of different dimensions for interpolation. This method addresses the issue of out-of-bounds values in some dimensions in NTK and achieves better results in extending the context window compared to NTK. However, this method introduces additional hyperparameters that need to be adjusted for different models to achieve particularly good results. Additionally, we argue that interpolation for certain high-frequency dimensions may lead to performance degradation in these dimensions, as we believe these dimensions have fully learned the
angle during pre-training and do not require interpolation.
2.4. Our Proposal: SBA-RoPE
By observing the out-of-bounds values in certain dimensions of the NTK Interpolation, it becomes evident that for low-frequency dimensions, the maximum rotation angles learned during the pre-training process do not exceed . These dimensions carry absolute position information, as the rotation angle corresponding to each position is unique. Extrapolating these angles would lead to significantly increased model perplexity, since the model has not been trained on these extrapolated angles. On the other hand, high-frequency dimensions have been thoroughly trained within the range, and the sine and cosine values of these angles reoccur in RoPE due to the periodicity of trigonometric functions. Thus, we can simply extrapolate these angles, as they carry relative position information.
To delineate the dimensions requiring interpolation from those needing extrapolation, we define the following notation as Equation (
7) for the rotation angle at position
and dimension
:
where
represents the position index corresponding to the current rotation angle,
represents the dimension corresponding to the current rotation angle, and
d represents the embedding dimension of the attention head. Based on our discussion, we need to identify the smallest dimension
such that it is just less than
; this dimension marks the boundary as Equation (
8) between extrapolation and interpolation:
where
and
L are, respectively, the
and the maximum context window used in RoPE during LLM pre-training. For
, we employ an interpolation method similar to NTK, ensuring the scaling at dimension
matches that of the Positional Interpolation (PI) method. The
for these low-frequency dimensions
can be calculated under the new fine-tuning length
as Equations (
9)–(
11):
This calculation determines the
used for interpolating low-frequency dimensions. Consequently, we can express the rotation angles in Segmental Base Adjustment for RoPE (SBA-RoPE) as Equation (
12):
Through our derivation, we have demonstrated that this approach yields rotation angles that, under the new fine-tuning length , do not produce out-of-bounds values for high-frequency dimensions nor low-frequency dimensions , maintaining consistency with the PI method. For high-frequency dimensions, we directly perform extrapolation to avoid the loss of high-frequency information, as seen with PI. For low-frequency dimensions, we adopt a method similar to NTK, distributing the interpolation load across all low-frequency dimensions.
3. Experiments and Results
We demonstrate that SBA-RoPE effectively extends the context window of Large Language Models (LLMs) with just 10,000 fine-tuning data points, a quantity negligible compared to the data volume used in model pre-training stages. We evaluated the model’s perplexity on long texts and conducted passkey retrieval experiments, proving that SBA-RoPE surpasses all previous methods for extending the context window.
3.1. Setup
Baselines. We compared SBA-RoPE against three methods: Positional Interpolation (PI), Neural Tangent Kernel (NTK), and YaRN. Additionally, to assess performance within the original context window of LLMs, we included baselines of LLMs without fine-tuning.
Considering computational costs, we selected Pythia-2.8b as our fine-tuning starting point. This model size is sufficient to highlight the performance differences between methods. Pythia [
15] includes LLMs ranging from 14M to 12B parameters, utilizing the same architecture as GPT-NeoX [
9]. It was pre-trained on the Pile [
16] dataset by EleutherAI (
https://www.eleuther.ai, accessed on 1 March 2024) for research into the interpretability analysis and scaling laws of LLMs, aiming to understand how knowledge develops and evolves during autoregressive transformer training. The model checkpoint used in our experiments is available on Hugging Face (
https://huggingface.co/EleutherAI/pythia-2.8b accessed on 1 March 2024). Other than adjusting the implementation of position embeddings using various methods, we also employed Memory-Efficient Attention from xFormers [
17], provided by PyTorch [
18], to replace the native attention mechanism of GPT-NeoX, thereby accelerating the training and inference processes on NVIDIA V100 GPU. Apart from these modifications, we did not modify the GPT-NeoX model architecture in any way.
Training. We fine-tuned all model variants using the next-token prediction objective and cross-entropy [
19] loss function, combined with various methods. We employed the AdamW [
20] optimizer, with
and
set to 0.9 and 0.95, respectively. For the scheduler, we used a linear warmup of 60 steps. The maximum learning rate was set to
, with weight decay set to zero. Utilizing eight NVIDIA V100 GPUs, we set the global batch size to 8 and fine-tuned each model variant for 1250 steps. FP16 mixed precision training [
21] was enabled. All models were trained using PyTorch and DeepSpeed Zero-3 [
22]. For the training dataset, we fine-tuned models using data from PG-19 [
23], truncating texts to lengths of 4 k tokens and appending BOS and EOS tokens at the beginning and end, respectively. We fine-tuned two variants of each method for scaling factors
and
. Given that the original context window of the Pythia model is 2048, the fine-tuned models have expanded context windows of 4096 and 8192, respectively.
3.2. Long Sequence Language Modeling
To evaluate performance in long sequence language modeling, we utilized the Proof-pile [
24] dataset, which comprises numerous long sequence texts, specifically employing its test split for our analysis. We adopted the sliding window technique [
6] to assess perplexity across various context window sizes, setting the stride
S to 256.
Initially, we assessed how model variants, fine-tuned using different methods, performed as the context window size increased. Following the approach used by YaRN, we selected 10 random samples from the Proof-pile dataset, each containing at least 10 k tokens. For the scaling factor , we evaluated the perplexity for sequence lengths from 1 k to 5 k tokens, in 1 k token steps.
Table 1 presents a comparison of perplexity for the Pythia model, expanded from an original context window of 2048 to 4096, utilizing the original model, PI, NTK, YaRN, and SBA-RoPE. From the experimental results, it is evident that, initially, within the original context lengths (1 k and 2 k), all models fine-tuned with various context window extension methods experienced an increase in perplexity to varying degrees. The PI method saw the most significant increase within this range, likely due to the equal stretching of all dimensions, resulting in the loss of high-frequency information.
In contrast, the model variants fine-tuned with our method exhibited the smallest increase in perplexity, indicating minimal performance degradation. This minimal increase is attributed to our method’s direct extrapolation of high-frequency dimensions, preventing the loss of this part of the pre-trained information. In the extended context window (3 k to 4 k), the original model’s perplexity significantly increased, indicating that the original model became impractical for extended windows. Our method achieved lower perplexity in the extended window compared to all other methods. Furthermore, at the 5 k window, which exceeds the extended context window (4 k), our method still maintained the lowest value, signifying superior extrapolation performance.
We further increased the scaling factor
s to 4, applying fine-tuning to the original model through various methods. The outcomes are presented in
Table 2. Despite the maximum length of the fine-tuning data being 4 k, adjusting the scaling factor
s to 4 allows us to infer that the model’s maximum context length has now been extended to 8 k. This extension is noteworthy because, although the model has never been exposed to context lengths between 4 k and 8 k, it still demonstrates a degree of transfer learning capability.
Data presented in
Table 2 show performance within the 1 k to 4 k context window that is similar to the behavior observed with a scaling factor
. Notably, even within the 7 k to 8 k length, which fal ls within the extended context window of NTK, this method exhibits significantly higher perplexity compared to others. This higher perplexity can be attributed to the NTK method’s adjusted rotation angles producing out-of-bounds values. Conversely, our method maintains superior performance in the previously unseen 5 k to 10 k window range, consistently demonstrating the most favorable outcomes.
3.3. Passkey Retrieval
To investigate the effective context window size of models after extension—that is, the maximum distance of tokens that can be effectively attended to during the inference process—we adhered to the passkey retrieval task as defined by [
25]. In this task, the model is required to recover a hidden five-digit passkey embedded within a context of largely nonsensical text. The specific format of the prompt used for this task is detailed in
Figure 2.
To evaluate the models, we conducted the passkey retrieval task 20 times for each model variant, positioning the key as close to the beginning of the context as possible to more accurately reflect the model’s capability to attend to the longest distance. The accuracy of models fine-tuned with a scaling factor
on the passkey retrieval task is shown in
Table 3. It is observed that all fine-tuned model variants exhibit high accuracy in the extended window. Notably, PI outperforms NTK and YaRN across all context window sizes on this task, suggesting that evenly stretching all embedding dimensions, despite causing “local distortion” do not significantly impact the dependency relationships between local tokens in the context of passkey retrieval. Our SBA-RoPE achieves the best results in all context windows except for the 3 k window, by combining the advantages of PI’s non-exceeding bounds and NTK’s distribution of interpolation stress across all dimensions.
To assess the extended capabilities of the models, we further tested them under the passkey retrieval task with the scaling factor increased to
, representing an expanded context window up to 8 k tokens. The outcomes, as documented in
Table 4, reveal that the models fine-tuned with this larger scaling factor continue to perform with notable accuracy across extended context lengths. Particularly, the PI method and our SBA-RoPE exhibit remarkably consistent performance, even at the higher context ranges of 5 k to 8 k tokens, underscoring the effectiveness of our approach in managing extended contexts. SBA-RoPE, especially, demonstrates superior adaptability and accuracy, effectively leveraging its hybrid strategy to maintain high retrieval accuracy, a testament to its robust extrapolation capabilities in previously unseen context lengths.
4. Discussions of the Results
The experiments conducted for SBA-RoPE have demonstrated its effectiveness in extending the context window of LLMs with a relatively small fine-tuning dataset. The comparison of SBA-RoPE with other methods, such as PI, NTK, and YaRN, across different metrics and tasks has provided a comprehensive understanding of its performance and advantages.
4.1. Perplexity Analysis
The perplexity measurements, as presented in
Table 1 and
Table 2, illustrate the capability of SBA-RoPE to maintain lower perplexity across extended context windows, surpassing the baseline methods. This is particularly significant in the context of long sequence language modeling, where maintaining coherence over longer spans of text is crucial. The minimal increase in perplexity within the original context lengths for models fine-tuned with SBA-RoPE suggests that our method successfully preserves the model’s original performance while effectively extending its context window. This indicates a balanced approach to extrapolating high-frequency dimensions, which is critical for minimizing the loss of pre-trained information.
Furthermore, the extended context window experiments, especially with the scaling factor , highlight SBA-RoPE’s superior extrapolation performance. Despite the models never being exposed to context lengths between 4 k and 8 k during training, SBA-RoPE demonstrates a robust transfer learning capability, effectively leveraging learned representations to adapt to and perform within these expanded context windows. This underscores the potential of SBA-RoPE in enhancing model flexibility and generalization across various context lengths, a key advantage for applications requiring comprehension of long documents or conversations.
4.2. Passkey Retrieval Performance
The passkey retrieval task results, as shown in
Table 3 and
Table 4, further validate the effectiveness of SBA-RoPE in managing extended context windows. The high accuracy of SBA-RoPE in this task across all evaluated context windows, especially with the scaling factor
, demonstrates its capability to attend to tokens over long distances without significant loss of performance. This is indicative of SBA-RoPE’s efficient handling of the extended context, combining the advantages of PI’s non-exceeding bounds and NTK’s distribution of interpolation stress across dimensions.
Notably, the performance of SBA-RoPE in the previously unseen 5 k to 10 k window range with high retrieval accuracy is a testament to its robust extrapolation capabilities. This suggests that SBA-RoPE not only effectively extends the context window, but also ensures that the model can maintain functional coherence and understanding over these longer spans, a critical requirement for tasks involving detailed comprehension and retention of information across large text bodies.
4.3. Applications and Implementation
Extending the context window of large language models offers multiple benefits for document summarization or long-document question-answering tasks. These benefits primarily stem from the ability to process longer texts, thereby enhancing the model’s understanding and generation quality. Here are some specific benefits:
Improved Document Understanding: By expanding the context window, models can process and understand longer texts at once. This means that when summarizing documents or answering questions related to long documents, the model can capture the content and structure of the document more comprehensively, thus improving the accuracy of understanding.
Reduced Information Loss: With long documents, smaller context windows may lead to the loss of important information since the model cannot view the entire document at once. Expanding the context window can reduce this information loss, allowing the model to consider more relevant information when generating summaries or answering questions.
Enhanced Accuracy and Relevance of Answers: For long-document question-answering tasks, being able to consider more information within the document can help the model generate more accurate and relevant answers. This is because the model has a greater chance of finding the exact answer to a question within the entire document, rather than relying on partial information for inference.
Improved Handling of Long-Distance Dependencies: In long documents, there may be long-distance dependencies between certain points of information. Expanding the context window allows the model to better capture these dependencies, thus providing more coherent and accurate information when generating summaries or answering questions.
Enhanced Comprehensive Understanding: In complex document summarization tasks, the model needs to understand not just individual sentences or paragraphs but the main theme and structure of the entire document. A larger context window enables the model to perform this comprehensive understanding over a broader range, thereby generating higher quality summaries.
Optimized Information Integration for Long Documents: In long-document question-answering or summarization, it is necessary to effectively integrate information scattered across different parts. A larger context window allows the model to identify and integrate this information over a wider range, making the final output more accurate and comprehensive.
Furthermore, adding the SBA-RoPE method to existing models based on rotational position embedding, such as Llama, Llama-2, and GPT-NeoX, is very easy, requiring only a few lines of code. This ease of modification is because the SBA-RoPE method does not require changes to the calculation of attention scores but only modifications to the model’s embedding-related code. We will release the source code after the paper is accepted.
5. Conclusions
In this study, we introduced SBA-RoPE, a novel technique designed to extend the context window of pre-trained LLMs by strategically adjusting the base values used in RoPE. Our approach, which selectively extrapolates high-frequency dimensions and interpolates those with maximum angles less than , conceptualizes length extrapolation as a prediction-stage Out-Of-Distribution (OOD) problem. This method leverage the inherent properties of RoPE to maintain performance integrity across extended contexts while efficiently addressing the challenges posed by OOD in low-frequency dimensions.
The empirical results presented in this paper validate the effectiveness of SBA-RoPE, demonstrating its superiority over existing methods, such as PI, NTK, and YaRN, across various context window sizes. Notably, SBA-RoPE’s ability to maintain high accuracy and low perplexity in extended contexts—even those previously unseen during training—highlights its robustness and adaptability.
Looking forward, the promising results achieved by SBA-RoPE open up new avenues for research into extending the capabilities of LLMs. Future studies could explore the integration of SBA-RoPE with other model architectures, delve into the potential of larger context windows, and investigate its applicability to few-shot learning scenarios. Such research could further unravel the complexities of model performance across varying context lengths and contribute to the development of more sophisticated and versatile language models.







{kind=link}
{kind=link}