1. Introduction
In recent years, many researchers have suggested that using “foundation models” [
1] as support for various downstream tasks is a promising trend in the development of AI. Well-known foundation models, such as BERT [
2], GPT-3 [
3], CLIP [
4], and ViT [
5], demonstrate remarkable feature learning and expression capabilities in crucial tasks within the domains of natural language processing (NLP), cross-modality matching (CMM), and computer vision (CV). Recently, the segment anything model (SAM) [
6], proposed by Meta, demonstrated remarkable and versatile capabilities in visual segmentation tasks, similar to the aforementioned foundation models. SAM is expected to become a crucial foundation model for basic image segmentation tasks and has the potential to serve as a supporting module for numerous downstream tasks.
However, the robustness and security of these foundation models have become crucial research topics that cannot be overlooked, as foundation models are widely used in downstream tasks. Many studies [
7,
8,
9,
10,
11] have indicated that almost all DNNs are vulnerable to attacks from adversarial examples. Recently, researchers have also started to pay attention to the robustness of foundation models. Paul and Chen [
12] conducted a study on the robustness of the ViT model and found that it has superior robustness compared to other models, as it is better able to defend against adversarial attacks. The researchers believe that the main reasons include the following: (1) the attention mechanism of ViT is capable of extracting rich global contextual information from images, which enhances the model’s robustness; (2) training the model on large-scale datasets increases its robustness. Similarly, SAM uses ViT as the backbone of its image encoder, and it is trained on an extremely large-scale dataset. Therefore, the robustness of SAM is likely to be higher than other DNNs. Huang et al. [
13] conducted adversarial attacks against SAM with single-point prompts using FGSM [
14], PGD [
15], BIM [
16], and SegPGD [
17] methods, and as a result, the background area is little affected.
What is particularly noteworthy is that SAM introduced a prompt mechanism, which requires adversarial examples to have some degree of transferability across different prompts to successfully perform the attack task. Unlike [
13], Zhang et al. [
18] explored the transferability of the cross-prompts of adversarial attacks against SAM by gradually increasing the number of point prompts. The examination of cross-prompt transferability in attacks, exploring variations in the number of point prompts, was conducted in [
19]. Based on the outcomes, the authors infer that it is challenging to enhance the cross-prompt transferability of attacks by simply further increasing the number of point prompts.
Similar to recent scholarly discussions [
18,
19], this paper focuses on the following question: How can one generate adversarial examples that possess higher cross-prompt transferability?
However, current methods [
18,
19] insufficiently delve into leveraging prompt information techniques. They primarily focus on attacking prominent foreground objects, neglecting attacks on the entirety of image scenes. Based on this understanding, our motivation comes from the need to make more use of prompt information to generate more cross-prompt transferable adversarial examples in the generation stage of an adversarial attack. Therefore, we propose a new adversarial attack method called PBA (prompt batch attack) to further improve the cross-prompt transferability of adversarial attacks against SAM. In this method, we leverage prompt information in a good way instead of attacking without prompts or with all prompts, which improves the attack success rate as well as the cross-prompt transferability of adversarial examples. Furthermore, our PBA method can cause the SAM segmentation results to fail across the entire image, shifting from ‘segment anything’ to ‘segment shards’.
In summary, our work makes the following contributions:
We design three adversarial attack methods with different ways of utilizing prompt information to perform adversarial attacks on SAM. The most effective method (PBA) exhibits both a high attack success rate and excellent cross-prompt transferability.
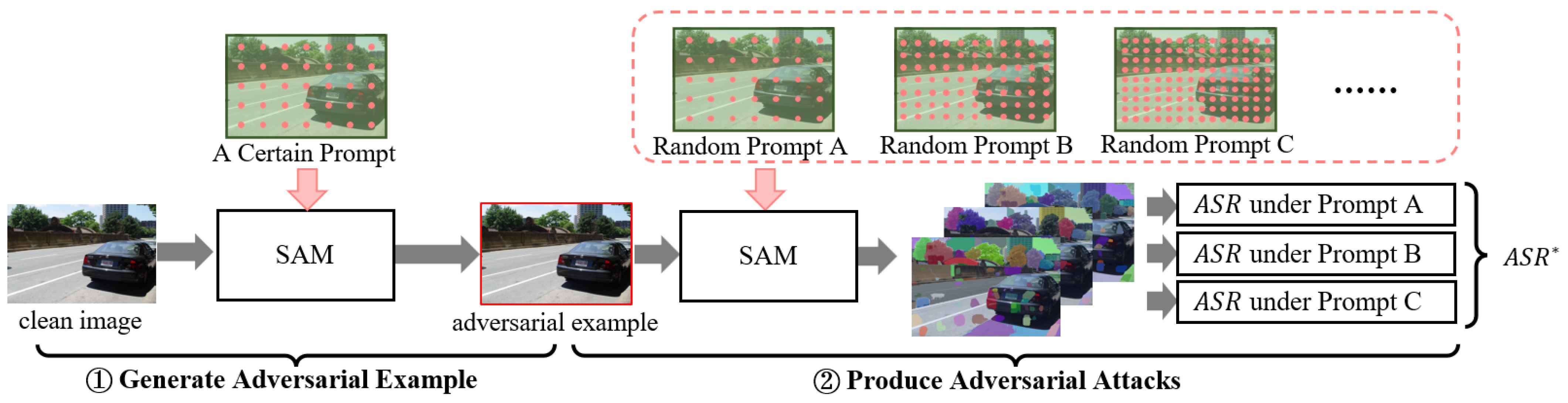
We propose an effective and clear metric (cross-prompt attack success rate, ∗) to evaluate the cross-prompt transferability of adversarial attacks. This metric takes into account both the degree of prompt variance and the attack success rate.
The rest of this paper is organized as follows.
Section 2 describes some background information about adversarial attacks, visual foundation models, and the adversarial robustness of the foundation model.
Section 3 deals with the definitions of adversarial attack, cross-prompt adversarial attack, and cross-prompt attack success rate.
Section 4 proposes the prompt batch attack (PBA) method along with two basic comparison algorithms: The no prompt attack (NPA) method and the prompt attack (PA) method.
Section 5 presents the experimental and numerical results, and some discussions of the experimental results are presented in
Section 6. Finally,
Section 7 presents the summary and future prospects for the entire paper.
2. Related Work
In this section, we first provide a concise overview of the pertinent background of this paper. Then, we dive into the details from three perspectives: adversarial attacks, visual foundation models, and adversarial attacks against foundation models.
2.1. Background
Adversarial attacks and foundation models constitute the two main background themes of this paper. An adversarial attack involves adding a small perturbation to the model’s input, causing a severe degradation in the neural network model’s performance. Inputs with this small perturbation are referred to as adversarial examples. On the other hand, the foundation model represents a recent paradigm of deep neural networks with strong generalization capabilities. In this paper, a novel adversarial attack method against a typical visual foundation model with cross-prompt transferability is proposed and investigated.
2.2. Adversarial Attack
In 2014, Szegedy et al. [
20] found the existence of adversarial examples and proposed the L-BFGS attack method. FGSM [
14], proposed by Goodfellow, is an adversarial perturbation generation method based on gradient backpropagation computation. In order to solve the problem of the FGSM attack’s instability and the obviousness of the perturbation, DeepFool [
21] and C&W [
22] methods were proposed, which are dedicated to finding a minimal adversarial perturbation. Furthermore, JSMA [
23] performed the adversarial attack by only changing the values of a few pixels. However, these methods [
14,
20,
21,
22,
23] focused on classifiers and lacked exploration in the more complex and practical deep neural network models. After that, DAG [
24] completed the adversarial attack on the object detection and instance segmentation model by the dense attack method. Then, many studies extended adversarial attacks to models in different domains, including object detection [
25], instance segmentation [
26,
27], human pose estimation [
28], person re-identification [
29], person detector [
30], visual language model [
31,
32], remote sensing [
33], and 3D point cloud processing [
34,
35]. These works show that adversarial attacks can threaten the security of various neural network-based application models.
Many research works show that adversarial examples have cross-model transferability. Zhou et al. [
36] proposed two methods to improve cross-model transferability: filtering high-frequency perturbations and maximizing the distance between the clean image and the adversarial example. References [
37,
38] generated more transferable adversarial examples by adding a variance-adjusted regularization module. In addition, some studies [
39,
40,
41,
42] have suggested that the transferability of adversarial examples can be improved by increasing the diversity of inputs.
With the emergence of SAM featuring prompt-guided inputs, few recent studies [
18,
19] have started to focus on the cross-prompt transferability of adversarial attack methods. (We compare these attack methods against SAM in detail in
Section 2.4). However, these research studies are confined to attacking only the image encoder or enhancing cross-prompt transferability by increasing the number of point prompts. Consequently, there is a lack of research on ways to leverage prompt information to improve cross-prompt transferability.
2.3. Visual Foundation Models
Foundation models, which are considered the next wave in AI, can be used for numerous downstream tasks with minimal fine-tuning. In the field of computer vision, foundation models are still in an early stage [
1]. However, quite a few studies [
4,
43,
44,
45,
46] have effectively contributed to the development process of Visual foundation models. Compared to traditional supervised models, foundation models can directly use super large-scale unlabeled raw data. The development of unsupervised learning in computer vision efficiently reduced the dependence on manually labeled datasets, which facilitated the development of visual foundation models; Chen et al. [
43] proposed an unsupervised learning technique using a contrast learning framework to train models. He et al. [
44] introduced self-supervised techniques in vision tasks and achieved results equivalent to the supervised model. Then, He et al. [
45] introduced Transformer to vision tasks and accomplished training on massive data with exciting effects. The pre-trained model (ViT) is widely reused in vision downstream tasks to extract the features of images. In addition, foundation models have contributed to the development of foundation models in visual generation. For example, the CLIP [
4] foundation model has inspired a range of CLIP-based visual generation studies. The DALL·E 2 model [
46], among them, shows an impressive ability to create images.
Recently, the segment anything model (SAM) [
6], a foundation model proposed by Meta for the visual segmentation task, has received a lot of attention from researchers. By building a special data engine with semi-supervised training, SAM has accomplished training on extremely large-scale data and has demonstrated extraordinary ability in the zero-shot segmentation task.
2.4. Adversarial Attack against the Foundation Model
The ability of a deep neural network model to resist attacks from adversarial examples is referred to as the model’s adversarial robustness. Given the extensive reuse of foundation models, their adversarial robustness is a significant and crucial topic. Bommasani et al. [
1] points out that improving the adversarial robustness of foundation models presents an important opportunity. Shafahi et al. [
47] suggested that robust feature extractors can be useful for transferring robustness to other domains.
Existing studies [
12,
15,
48,
49] have shown that large datasets and large model capacities are beneficial for improving adversarial robustness. Schmidt et al. [
48] suggested that training an adversarial robust model requires more data. References [
15,
49] found that improving adversarial robustness requires larger model parameters and capacity. Paul and Chen [
12] showed that Visual Transformers have higher adversarial robustness than other models. Unfortunately, it has been demonstrated that the CLIP foundation model does not exhibit sufficient robustness against adversarial attacks [
50].
Researchers still need to study more about the adversarial robustness of foundation models in different domains [
1]. The SAM, meanwhile, has not been sufficiently studied for its adversarial robustness as an important foundation model in the field of computer vision. As shown in
Table 1, we collected the latest adversarial attack methods against SAM and focused on their comparison regarding the topic of cross-prompt transferability. Huang et al. [
13] did not consider the influence of prompt changes on their attack success rate, and the attack results have limited effect in the background part of the image. Zhang et al. [
18] conducted targeted attacks against SAM, including mask removal, mask enlargement, and mask manipulation. Additionally, initial observations revealed an increase in the cross-prompt transferability of adversarial attacks against SAM, as the number of point prompts increased. Zheng and Zhang [
19] contend that an increase in the number of point prompts has a limited effect on the improvement of cross-prompt transferability. Therefore, they propose a prompt-agnostic attack method, which only attacks the image encoder of SAM. In this paper, we introduce a technique termed PBA (prompt batch attack) against SAM. The PBA method enhances the cross-prompt transferability of adversarial examples by attacking SAM with dense point prompts in batches. Furthermore, the attack effect generated by PBA, resembling fragmented glass, impacts the entire image.
4. Method
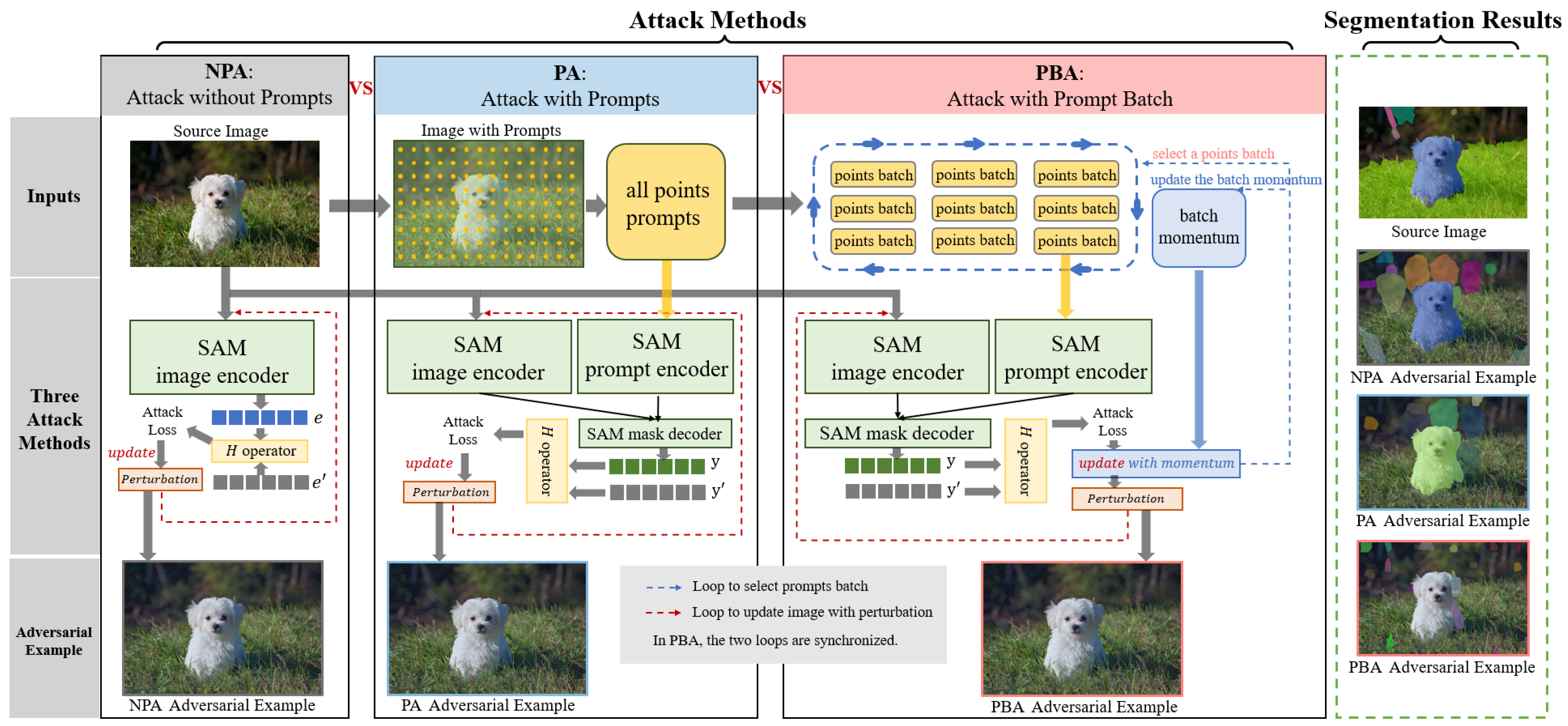
In this section, we introduce three different algorithms, namely NPA, PA, and PBA, to attack SAM in a white box setting. The different degrees of utilization of SAM’s prompt information are the main differences between these three algorithms.
As shown in
Figure 2, in the no prompt attack (NPA) method, gradient-based adversarial perturbation optimization only involves the image encoder structure of SAM. In the prompt attack (PA) method, gradient-based adversarial perturbation optimization involves all structures of SAM with prompt input as a whole. In the prompt batch attack (PBA) method, each optimization iteration uses only one of the prompt batches as input and keeps using different prompt batches during optimization iterations. Additionally, the PBA adds momentum information between different prompt batch iterations to stabilize the update direction. It is worth noting that momentum information between iterations is also used in the PA method but this momentum information is not obtained under the influence of different prompt batches. We will elaborate on these three attack algorithms (NPA, PA, and PBA) in
Section 4.1,
Section 4.2 and
Section 4.3. When reading these sections, one may refer to the symbol table (
Table 2) to help with comprehension.
4.1. NPA: Attack without Prompts
In the no prompt attack (NPA) method, we only use the output of
to calculate
as in Equation (
9), without considering
,
and the prompt input,
p. The overall pipeline of the NPA algorithm is illustrated in Algorithm 1.
where
denotes the image with adversarial perturbation, and
denotes a constant in the image embedding space, which can be generated from an arbitrary real image.
| Algorithm 1: NPA |
![Applsci 14 03312 i001]() |
4.2. PA: Attack with Prompts
As a further step, the PA method not only considers adversarial attacks against the image encoder but also takes into account the influence of the mask decoder on the final results. Therefore, the PA method defines
using the output of
as Equation (
10). The overall pipeline is illustrated in Algorithm 2.
where
denotes the image with adversarial perturbation,
p denotes a special prompt with dense point coordinates of the input image, and
denotes a constant in the space of output of
, which can be generated from an arbitrary real image.
| Algorithm 2: PA |
![Applsci 14 03312 i002]() |
4.3. PBA: Attack with Prompt Batch
In order to improve the transferability of adversarial examples across different prompts, we promote the PA method by (1) dividing the special input prompts with dense point coordinates into small batches during the iterations of the attack, (2) using only one batch of the prompt to calculate
as Equation (
11). The overall pipeline is illustrated in Algorithm 3.
where
denotes the image with adversarial perturbation,
denotes one batch of
p, and
denotes a constant in the space of output of
, which can be generated from an arbitrary real image.
| Algorithm 3: PBA |
![Applsci 14 03312 i003]() |
4.4. Algorithms Analysis
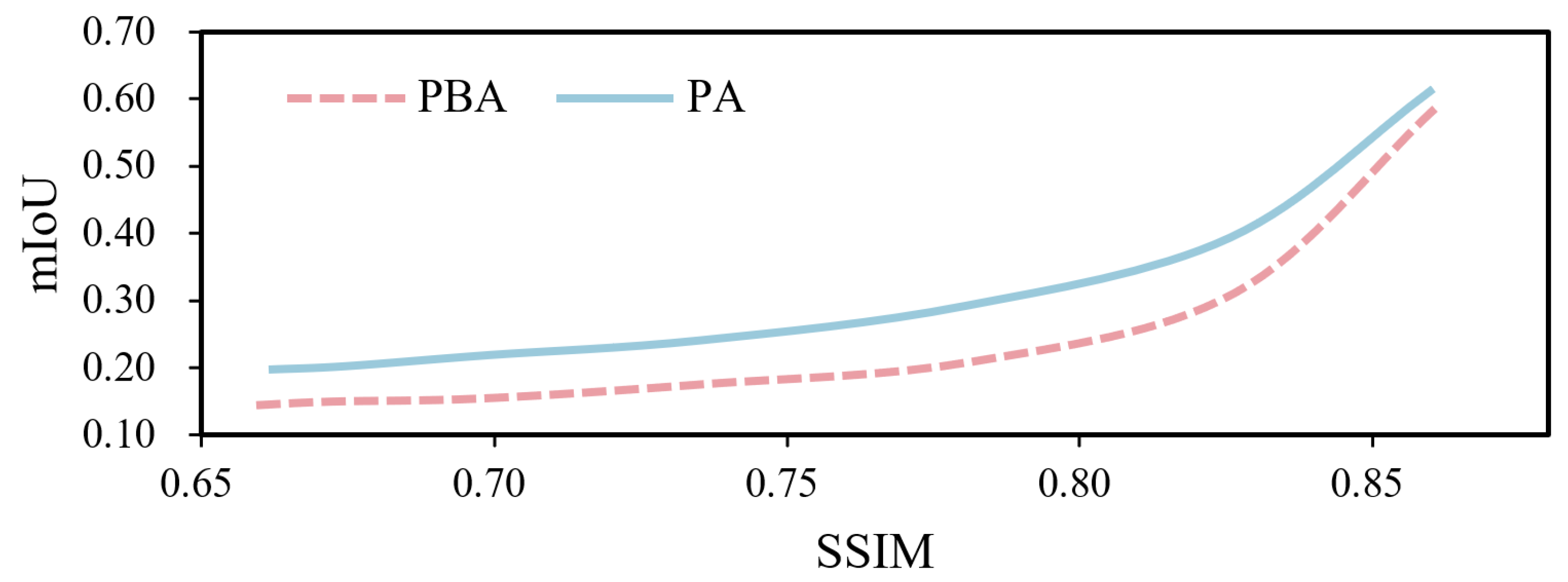
In this section, we present a comparative analysis of NPA, PA, SPA, and PBA algorithms, and, we attempt to explain the superiority of the PBA algorithm.
As shown in
Table 3, the differences between the algorithms are mainly reflected in five aspects, which are the use of the SAM structure, the use of prompt information, the loss function, the number of iterations, and the process affecting the momentum.
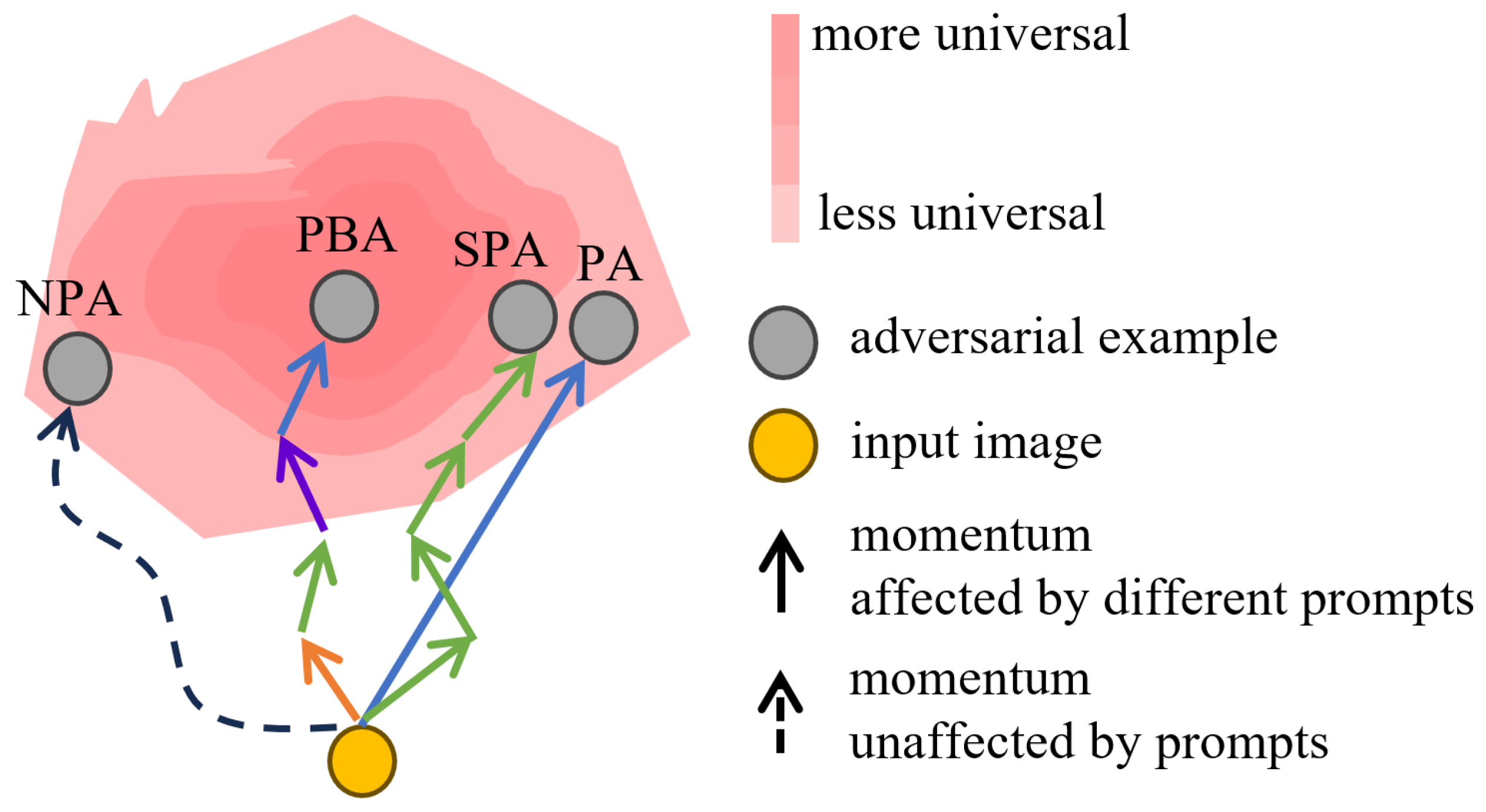
Among these aspects, the most essential is that different algorithms affect the momentum in different processes. In
Figure 3, we show the intuitive impact of the different processes affecting the momentum. In gradient-based adversarial perturbation generation processes, momentum serves as a critical factor influencing the direction of perturbation generation. It can be succinctly understood that the introduction of varying information during the iterative process affects the direction of momentum.
In the NPA algorithm, the direction of momentum is not influenced by any prompt information, thereby making it difficult for the generated adversarial examples to reach more universal prompt-dense regions (adversarial examples capable of successful attacks under a wider range of prompt conditions). In the PA algorithm, the direction of momentum is solely influenced by a single prompt, thereby significantly impacting the universality of the adversarial examples due to potential bias inherent in the specific prompt itself. In the PBA algorithm, the direction of momentum is continuously influenced by the combined effects of different prompt batch information, allowing the synthesis of multiple prompt information to correct the direction of momentum in a shorter period. Therefore, the momentum direction of PBA consistently approaches the correct direction. Conversely, in the SPA algorithm, despite having the same number of iterations and identical prompt information as PBA, it fails to promptly synthesize multiple prompt batch information to adjust the momentum direction. Consequently, the momentum direction of SPA remains unstable.
In conclusion, adversarial examples generated by the PBA method consistently converge toward the correct direction, demonstrating superior generalization across different prompt conditions. This highlights PBA cross-prompt transferability.
7. Conclusions
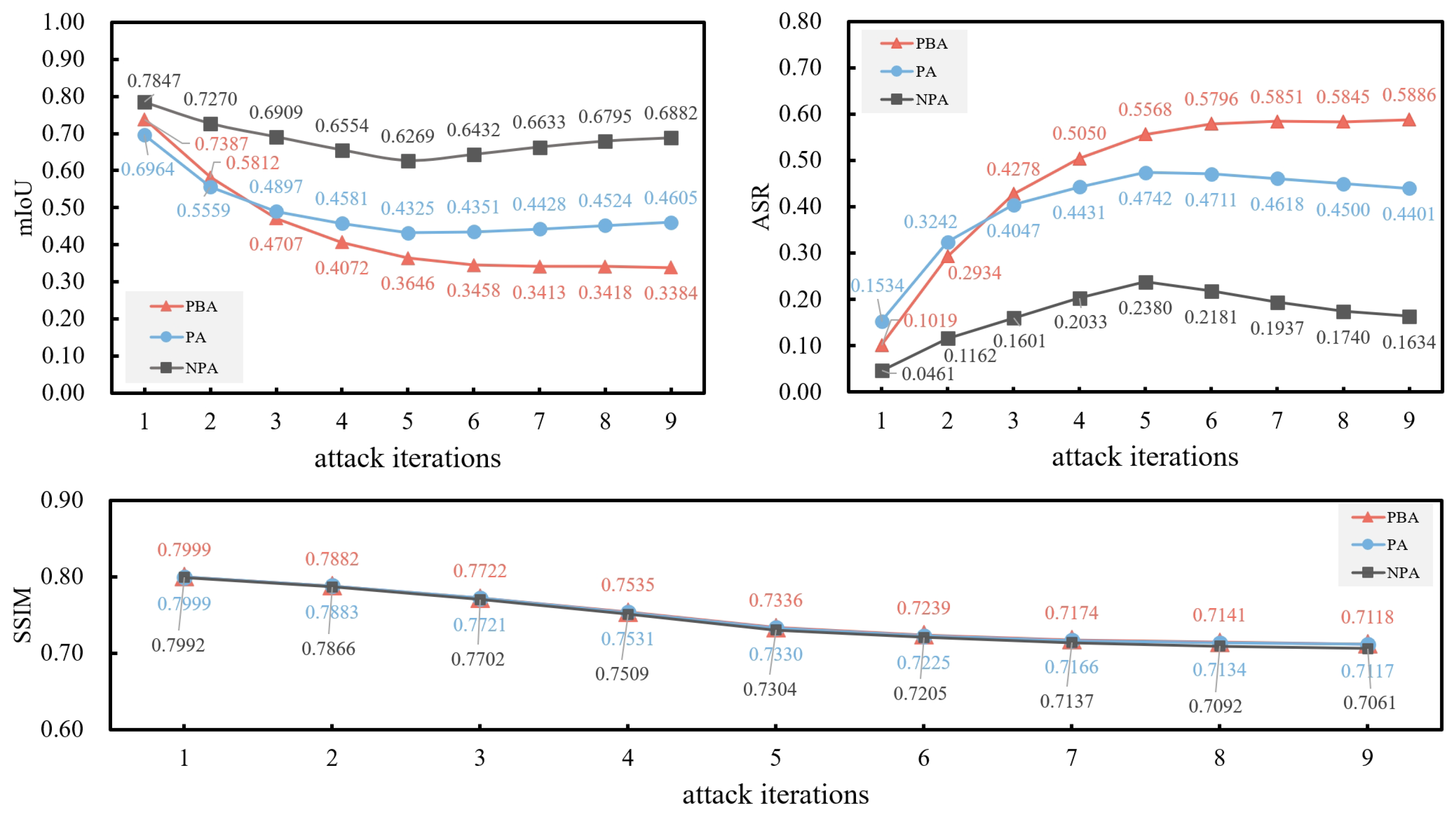
In this paper, we propose a method (the PBA method) to attack the significant visual foundation model (SAM), indicating that SAM has room for improvement in adversarial robustness. The experimental results demonstrate that the PBA method can successfully generate adversarial examples that perform well in both cross-prompt transferability and attack success rates. Numerical results on multiple datasets show that the cross-prompt attack success rate (∗) of the PBA method is 17.83% higher on average, and the attack success rate () is 20.84% higher. Generating adversarial examples with prompt batching can effectively promote the cross-prompt transferability of adversarial examples. Additionally, we find that enhancing the cross-prompt transferability of adversarial examples is crucial for attacking visual foundation models equipped with the prompt mechanism.
Additionally, we believe that using adversarial examples generated by the PBA method could be risky for real-world systems based on SAM. On the one hand, the PBA method exhibits strong cross-prompt transferability. On the other hand, SAM is a widely used visual foundation model. Therefore, we recommend adopting adversarial training when using SAM. This involves incorporating adversarial examples into SAM’s training dataset to enhance its security.
In future research, we will extensively focus on adversarial attacks and defenses targeting various types of foundation models, and explore defense methods against adversarial attacks in different application scenarios.


 ,
, 









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}