
DIFFBAS: An Advanced Binaural Audio Synthesis Model Focusing on Binaural Differences Recovery

Abstract
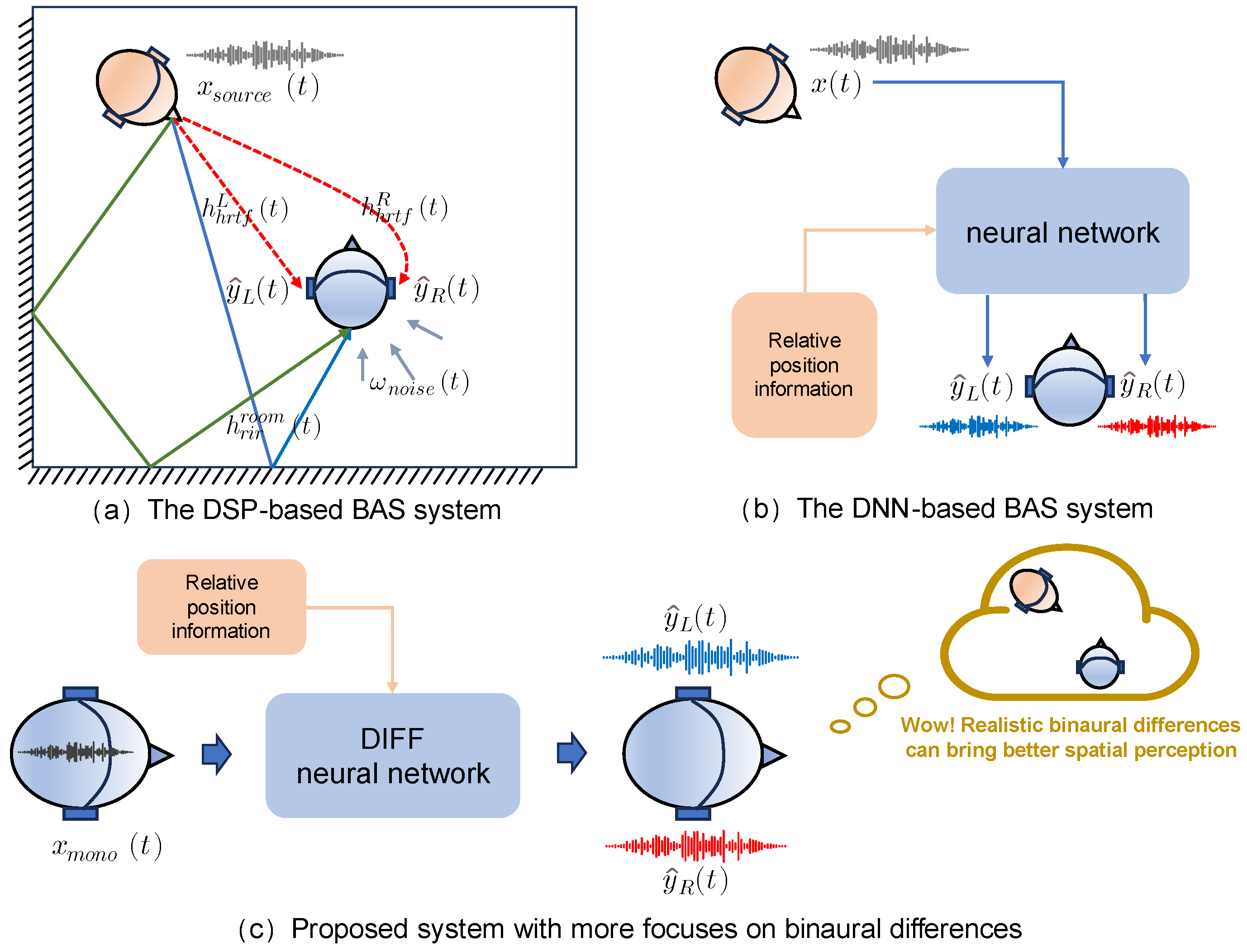
:1. Introduction
- A novel DNN-based BAS method, DIFFBAS is proposed. By focusing on modeling the specific path, DIFFBAS can avoid the overfitting problem caused by environmental and sound source diversity. The model employs new loss supervision for supplementary supervision and consequently improves the accuracy of synthesized binaural audio referring to the interaural phase difference between two ears.
- To better train the DIFFBAS model, a new loss, namely IPD loss, is proposed. This loss fits the perceptual characteristics of the human ear and ensures that the model will not lose too much spatial information during the training process. In addition, IPD is regarded as a new evaluation metric that reflects the accuracy of binaural phase difference in synthesized audio. It is the first objective metric that can quantify the spatialization degree of binaural audio.
- The performance of DIFFBAS has been validated on the only binaural dataset captured in the real world [15]. Sufficient contrast and ablation experimental results further demonstrate the effectiveness of DIFFBAS and IPD loss.
2. Methodology
2.1. Problem Definition
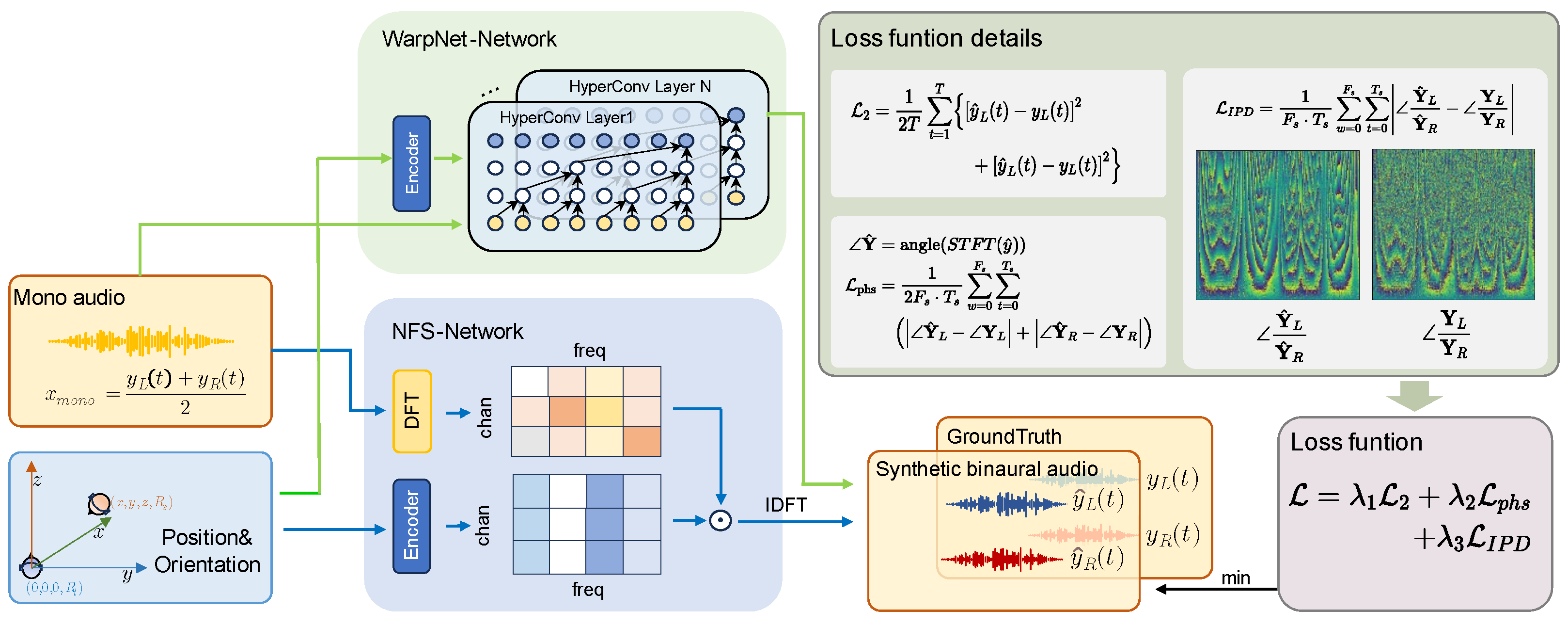
2.2. Framework of DIFFBAS
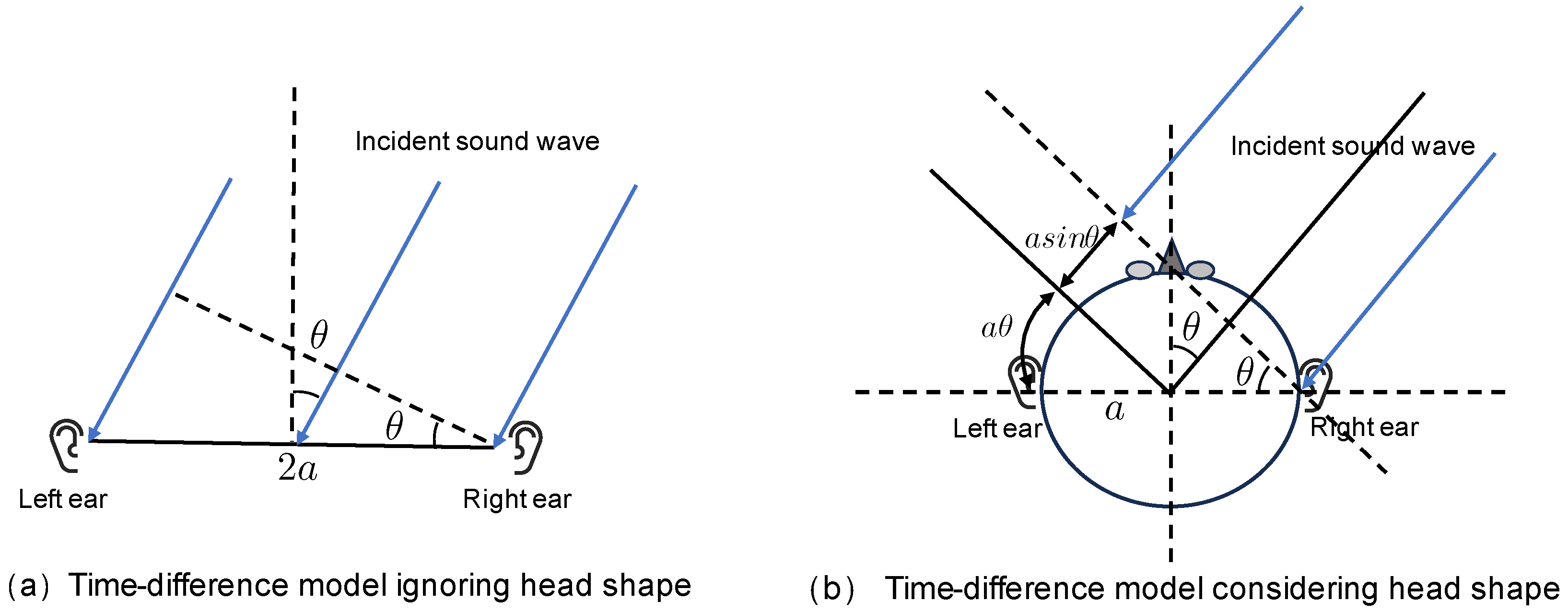
2.3. Definition of IPD
2.4. IPD Calculation of Binaural Audio
2.5. Overall Loss Function
3. Experiments and Results
3.1. Experiment Settings
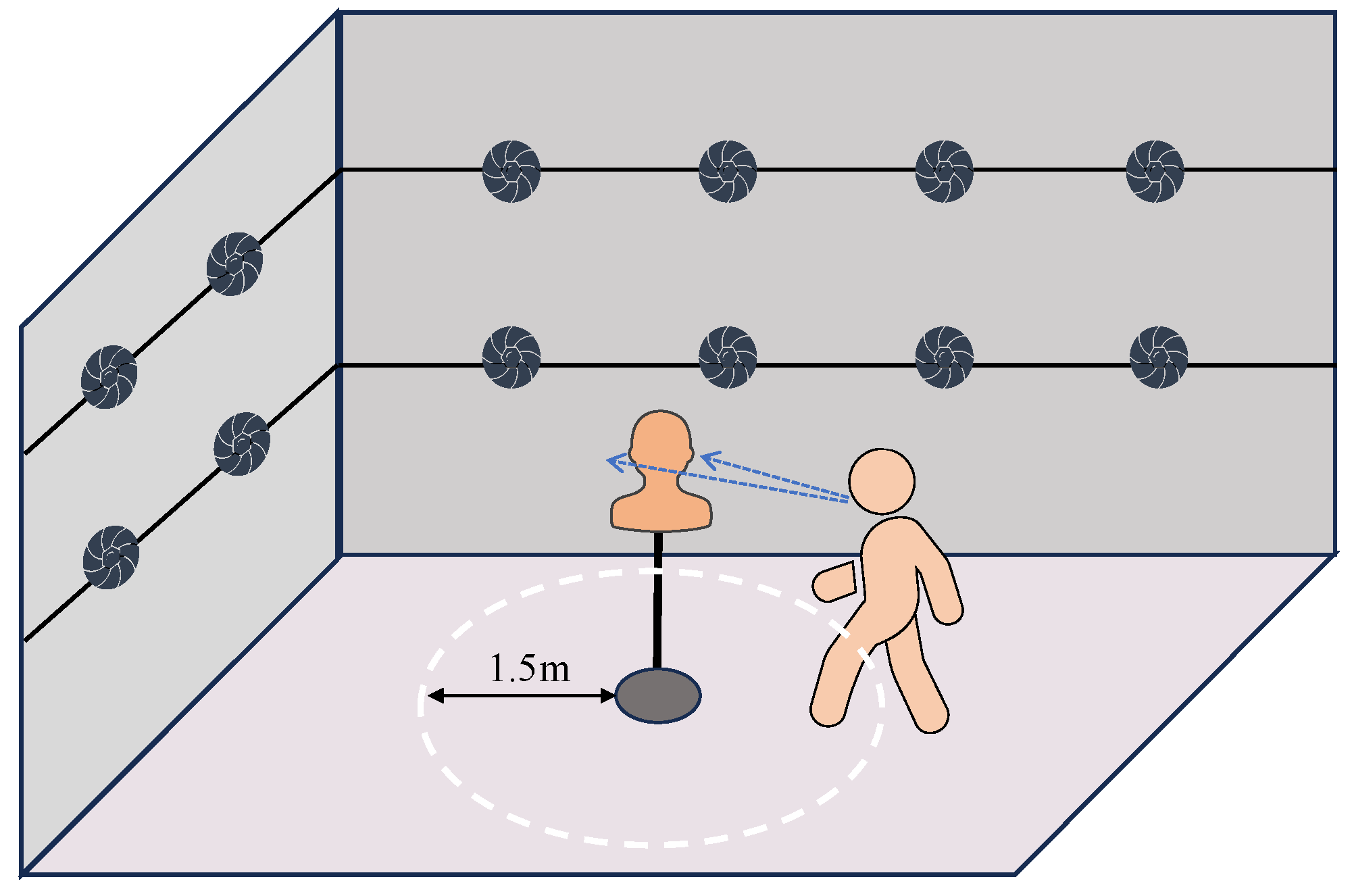
3.1.1. Dataset
3.1.2. Baselines
3.1.3. Evaluation Method
- , which represents the mean square error between the synthesized binaural audio and the golden binaural recording.
- , which measures the mean absolute error between the synthesized binaural audio and the binaural recording on the amplitude after performing STFT on the wave.
- , which captures the mean absolute error between the synthesized binaural audio and the binaural recording on the phase after performing STFT on the wave.
- , which quantifies the mean absolute error on IPD between the synthesized binaural audio and the binaural recording. The smaller the metric, the closer the spatial information carried by the synthesized binaural audio is to the binaural recording.
3.1.4. Training Details
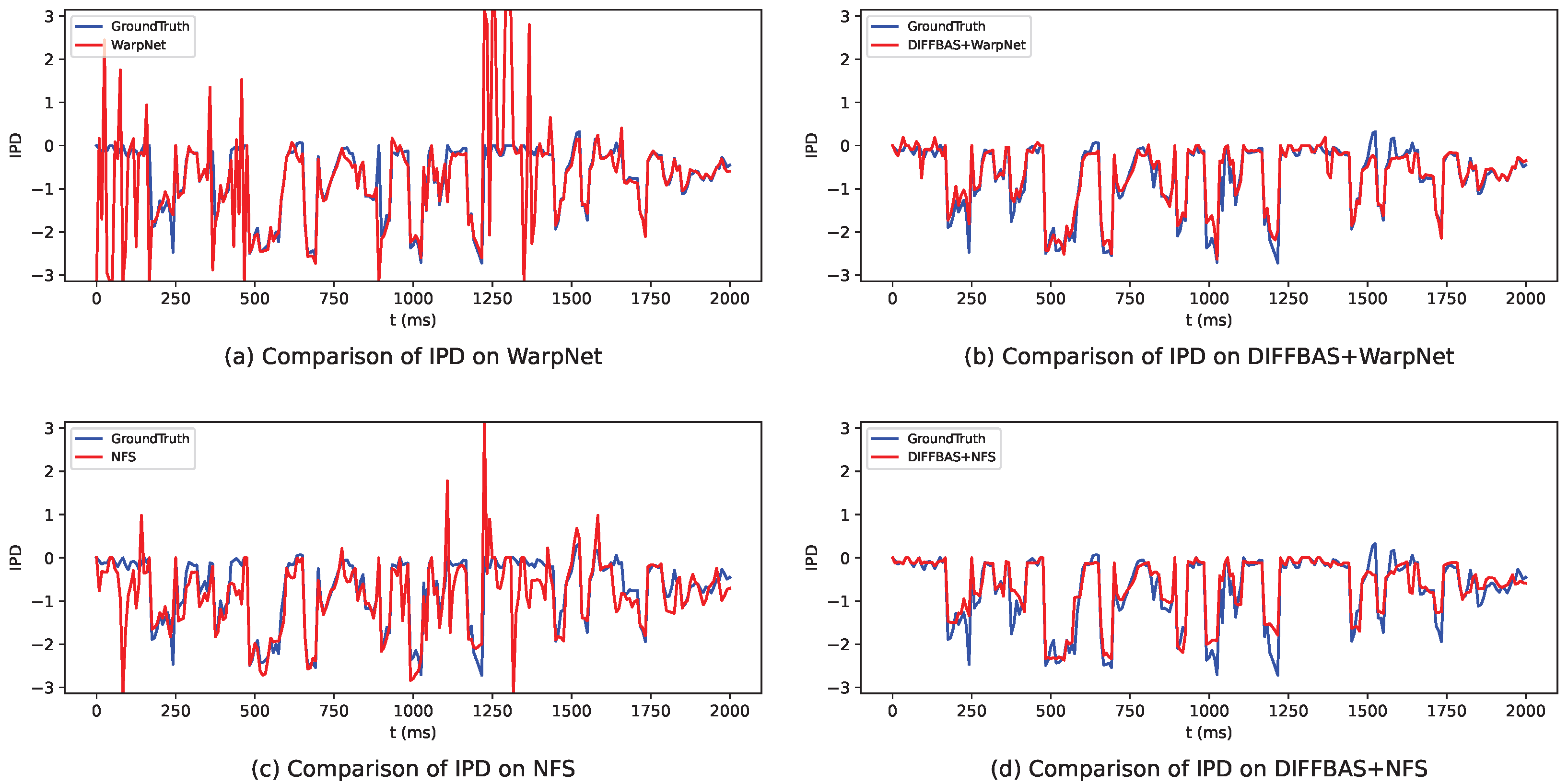
3.2. Experiment Results
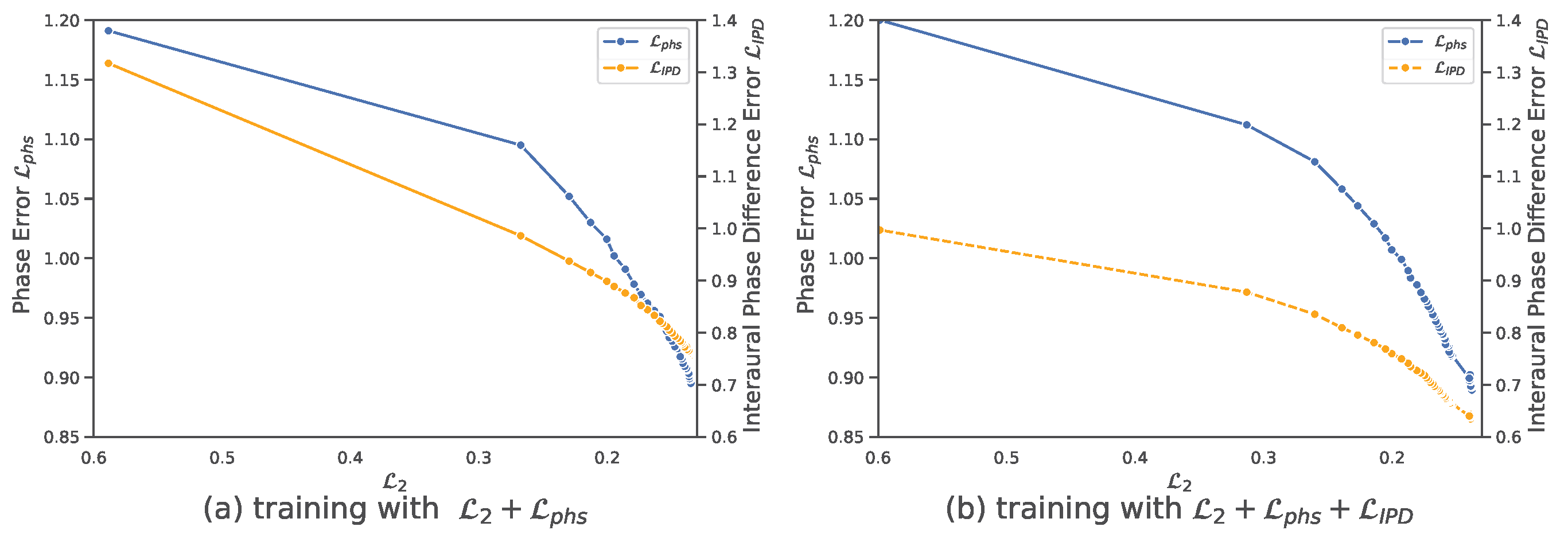
3.2.1. Loss Evaluation
3.2.2. Quantitative Evaluation
- Comparative experiment
- Geo-Warp, which performs time translation and amplitude alteration on the left and right ear signals based on the geometric information and attenuation formula of the distance from the sound source to both ears.
- WarpNet, which transforms the time-domain waveform to obtain binaural audio through geometric warp and neural warp.
- NFS, which generates frequency domain masks based on position information to obtain binaural audio.
- DIFFBAS + WarpNet, the backbone network of DIFFBAS is WarpNet.
- DIFFBAS + NFS, the backbone network of DIFFBAS is NFS.
- Mono-Mono, which produces binaural audio simply by copying the mono audio of the sound source to the left and right channels.
- Avg-Avg, which produces binaural audio by copying the average signals of left and right channels.
- Ablation experiment
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hendrix, C.; Barfield, W. The sense of presence within auditory virtual environments. Presence Teleoper. Virtual Environ. 1996, 5, 290–301. [Google Scholar] [CrossRef]
- Hammershøi, D.; Møller, H. Binaural technique—Basic methods for recording, synthesis, and reproduction. In Communication Acoustics; Springer: Berlin/Heidelberg, Germany, 2005; pp. 223–254. [Google Scholar]
- Hoeg, E.R.; Gerry, L.J.; Thomsen, L.; Nilsson, N.C.; Serafin, S. Binaural sound reduces reaction time in a virtual reality search task. In Proceedings of the 2017 IEEE 3rd VR Workshop on Sonic Interactions for Virtual Environments (SIVE), Los Angeles, CA, USA, 19 March 2017; pp. 1–4. [Google Scholar]
- Blauert, J.; Braasch, J. Binaural signal processing. In Proceedings of the 2011 17th International Conference on Digital Signal Processing (DSP), Corfu, Greece, 6–8 July 2011; pp. 1–11. [Google Scholar]
- He, J.; Tan, E.L.; Gan, W.S. Natural sound rendering for headphones: Integration of signal processing techniques. IEEE Signal Process. Mag. 2015, 32, 100–113. [Google Scholar]
- Zotkin, D.N.; Duraiswami, R.; Davis, L.S. Rendering localized spatial audio in a virtual auditory space. IEEE Trans. Multimed. 2004, 6, 553–564. [Google Scholar] [CrossRef]
- Zhang, W.; Samarasinghe, P.N.; Chen, H.; Abhayapala, T.D. Surround by Sound: A Review of Spatial Audio Recording and Reproduction. Appl. Sci. 2017, 7, 532. [Google Scholar] [CrossRef]
- Katz, B.F.G. Boundary element method calculation of individual head-related transfer function. I. Rigid model calculation. J. Acoust. Soc. Am. 2001, 110, 2440–2448. [Google Scholar] [CrossRef] [PubMed]
- Xiao, T.; Huo Liu, Q. Finite difference computation of head-related transfer function for human hearing. J. Acoust. Soc. Am. 2003, 113, 2434–2441. [Google Scholar] [CrossRef] [PubMed]
- Salvador, C.D.; Sakamoto, S.; Treviño, J.; Suzuki, Y. Dataset of near-distance head-related transfer functions calculated using the boundary element method. In Audio Engineering Society Conference: 2018 AES International Conference on Spatial Reproduction-Aesthetics and Science; Audio Engineering Society: New York, NY, USA, 2018. [Google Scholar]
- Algazi, V.R.; Duda, R.O.; Thompson, D.M.; Avendano, C. The cipic hrtf database. In Proceedings of the 2001 IEEE Workshop on the Applications of Signal Processing to Audio and Acoustics (Cat. No. 01TH8575), New Platz, NY, USA, 24 October 2001; pp. 99–102. [Google Scholar]
- Li, S.; Peissig, J. Measurement of Head-Related Transfer Functions: A Review. Appl. Sci. 2020, 10, 5014. [Google Scholar] [CrossRef]
- Brinkmann, F.; Lindau, A.; Weinzierl, S. On the Authenticity of Individual Dynamic Binaural Synthesis. J. Acoust. Soc. Am. 2017, 142, 1784–1795. [Google Scholar] [CrossRef] [PubMed]
- Lemaire, V.; Clerot, F.; Busson, S.; Nicol, R.; Choqueuse, V. Individualized HRTFs from few measurements: A statistical learning approach. In Proceedings of the Proceedings. 2005 IEEE International Joint Conference on Neural Networks, Montreal, QC, Canada, 31 July–4 August 2005; Volume 4, pp. 2041–2046. [Google Scholar]
- Richard, A.; Markovic, D.; Gebru, I.D.; Krenn, S.; Butler, G.A.; Torre, F.; Sheikh, Y. Neural synthesis of binaural speech from mono audio. In Proceedings of the ICLR, Virtual Event, Austria, 3–7 May 2021. [Google Scholar]
- Lee, J.W.; Lee, K. Neural Fourier Shift for Binaural Speech Rendering. In Proceedings of the ICASSP, Rhodes, Greece, 4–10 June 2023; pp. 1–5. [Google Scholar]
- Leng, Y.; Chen, Z.; Guo, J.; Liu, H.; Chen, J.; Tan, X.; Mandic, D.; He, L.; Li, X.; Qin, T.; et al. Binauralgrad: A Two-stage Conditional Diffusion Probabilistic Model for Binaural Audio Synthesis. Adv. Neural Inf. Process. Syst. 2022, 35, 23689–23700. [Google Scholar]
- Ho, J.; Jain, A.; Abbeel, P. Denoising Diffusion Probabilistic Models. Adv. Neural Inf. Process. Syst. 2020, 33, 6840–6851. [Google Scholar]
- Culling, J.F.; Akeroyd, M.A. Spatial hearing. In Oxford Handbook of Auditory Science: Hearing; OUP Oxford: Oxford, UK, 2010; pp. 123–144. [Google Scholar]
- Gao, R.; Grauman, K. 2.5D Visual Sound. In Proceedings of the CVPR, Long Beach, CA, USA, 16–20 June 2019; pp. 324–333. [Google Scholar]
- Blauert, J.; Jekosch, U. Sound-quality evaluation—A multi-layered problem. Acta Acust. United Acust. 1997, 83, 747–753. [Google Scholar]
- Culling, J.F.; Lavandier, M. Binaural Unmasking and Spatial Release from Masking. In Binaural Hearing: With 93 Illustrations; Springer: Berlin/Heidelberg, Germany, 2021; pp. 209–241. [Google Scholar]
- Rethage, D.; Pons, J.; Serra, X. A WaveNet for Speech Denoising. In Proceedings of the I2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 5069–5073. [Google Scholar]
- Tancik, M.; Srinivasan, P.; Mildenhall, B.; Fridovich-Keil, S.; Raghavan, N.; Singhal, U.; Ramamoorthi, R.; Barron, J.; Ng, R. Fourier Features Let Networks Learn High Frequency Functions in Low Dimensional Domains. Adv. Neural Inf. Process. Syst. 2020, 33, 7537–7547. [Google Scholar]
- Zhao, H.; Gan, C.; Rouditchenko, A.; Vondrick, C.; McDermott, J.; Torralba, A. The Sound of Pixels. In Proceedings of the ECCV, Munich, Germany, 8–14 September 2018; pp. 570–586. [Google Scholar]
- Gao, R.; Grauman, K. Co-Separating Sounds of Visual Objects. In Proceedings of the ICCV, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 3879–3888. [Google Scholar]
- Yamamoto, R.; Song, E.; Kim, J.M. Parallel WaveGAN: A Fast Waveform Generation Model Based on Generative Adversarial Networks with Multi-Resolution Spectrogram. In Proceedings of the 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 6199–6203. [Google Scholar]
- Le Roux, J.; Wisdom, S.; Erdogan, H.; Hershey, J.R. SDR–Half-Baked or Well Done? In Proceedings of the 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 626–630. [Google Scholar]
- Heitkaemper, J.; Jakobeit, D.; Boeddeker, C.; Drude, L.; Haeb-Umbach, R. Demystifying TasNet: A Dissecting Approach. In Proceedings of the 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 6359–6363. [Google Scholar]
- Luo, Y.; Mesgarani, N. Conv-TasNet: Surpassing Ideal Time–Frequency Magnitude Masking for Speech Separation. IEEE/ACM Trans. Audio Speech Lang. Process. 2019, 27, 1256–1266. [Google Scholar] [CrossRef] [PubMed]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Speaker | Listener | Gender | Room Characteristics | Time Length | |
|---|---|---|---|---|---|
| Train | Test | ||||
| subject1 | KEMAR | male | acoustically adapted room | 13:17 | 1:55 |
| subject2 | female | 14:24 | 1:59 | ||
| subject3 | female | 13:26 | 1:55 | ||
| subject4 | female | 13:12 | 1:54 | ||
| subject5 | male | 13:29 | 1:59 | ||
| subject6 | male | 13:16 | 1:58 | ||
| subject7 | male | 13:51 | 1:57 | ||
| subject8 | female | 13:14 | 1:49 | ||
| validation | male | 1:24 | |||
| DIFFBAS + WarpNet | DIFFBAS + NFS | ||
|---|---|---|---|
| loss function hyperparameters | 1 | 1 | |
| 0.01 | 0.001 | ||
| 0.01 | 0.001 | ||
| Optimizer | activation | Tanh | Relu |
| type | Adam | Adam | |
| learning_rate | 1.0 × 10−3 | 1.0 × 10−3 | |
| learning_rate_decay | 0.5 | 0.1 | |
| weight_decay | 0 | 0 |
| power spectrum+phase copy [25] | 1.276 | 0.048 | 1.563 | - |
| multiscale STFT [15] | 2.279 | 0.043 | 1.996 | - |
| Si-SDR [28] | 0.798 | 0.222 | 1.507 | - |
| 0.146 | 0.033 | 0.894 | 1.217 | |
| 0.145 | 0.036 | 0.815 | 1.064 | |
| (Equation (14)) | 0.142 | 0.036 | 0.819 | 0.967 |
| Model | ||||
|---|---|---|---|---|
| Mono-Mono | 1.340 | 0.063 | 1.564 | 1.472 |
| Avg-Avg | 0.200 | 0.031 | 0.598 | 1.472 |
| Geo-Warp | 0.408 | 0.052 | 1.156 | 1.414 |
| WarpNet [15] | 0.145 | 0.036 | 0.815 | |
| DIFFBAS + WarpNet | ||||
| NFS [16] | 0.163 | 0.040 | 0.869 | 1.250 |
| DIFFBAS + NFS | 1.083 |
| WarpNet [15] | NFS [16] | |||||||
|---|---|---|---|---|---|---|---|---|
| Condition | ||||||||
| Baseline | 0.145 | 0.036 | 0.815 | 1.064 | 0.163 | 0.040 | 0.869 | 1.250 |
| + | 0.142 | 0.036 | 0.819 | 0.967 | 0.177 | 0.047 | 0.824 | 1.194 |
| - | 0.033 | 0.018 | 0.358 | 0.865 | 0.049 | 0.019 | 0.434 | 1.087 |
| DIFFBAS | 0.033 | 0.018 | 0.358 | 0.834 | 0.049 | 0.018 | 0.431 | 1.083 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Y.; Shen, Y.; Wang, D. DIFFBAS: An Advanced Binaural Audio Synthesis Model Focusing on Binaural Differences Recovery. Appl. Sci. 2024, 14, 3385. https://doi.org/10.3390/app14083385
Li Y, Shen Y, Wang D. DIFFBAS: An Advanced Binaural Audio Synthesis Model Focusing on Binaural Differences Recovery. Applied Sciences. 2024; 14(8):3385. https://doi.org/10.3390/app14083385
Chicago/Turabian StyleLi, Yusen, Ying Shen, and Dongqing Wang. 2024. "DIFFBAS: An Advanced Binaural Audio Synthesis Model Focusing on Binaural Differences Recovery" Applied Sciences 14, no. 8: 3385. https://doi.org/10.3390/app14083385