Abstract
Existing diffusion models outperform generative models like Generative Adversarial Networks in image synthesis and editing. However, they struggle with high-precision image editing while preserving image details and the accuracy of editing instructions. To address these challenges, we propose a dual attention control method to achieve high-precision image editing. Our approach includes two key attention control modules: (1) cross-attention control module, which combines the cross-attention maps of the original and edited images through weighted parameters, ensures that the synthesized edited image retains the structure of the input image. (2) Self-attention control module, which varies based on the editing task, applied at “coarse” and “fine” layers, since the coarse layers help maintain input image details and the fine layers are better suited for style transformations. Experimental evaluations have demonstrated that our approach achieves excellent results in detail preservation, content consistency, visual realism, and semantic understanding, making it especially suitable for tasks requiring high-precision editing. Specifically, compared to the editing outcomes under no control conditions, the introduction of dual visual attention control has led to an increase of 6.19% in CLIP scores, a reduction of 29.3% in LPIPS, and a decrease of 24.7% in FID. These significant improvements not only validate the effectiveness of the dual attention control but also attest to the method’s substantial flexibility and adaptability across different scenarios. Notably, our approach is a zero-shot solution, requiring no user optimization or fine-tuning, facilitating real-world applications.
1. Introduction
Diffusion Models (DMs) [1,2,3] have achieved remarkable breakthroughs and widespread recognition in the generative artificial intelligence community as a cutting-edge deep learning generative technology. DMs approach the real-world data distribution through iterative denoising of random Gaussian noise, thereby enabling generative tasks. Their applications include image synthesis [4,5], image editing [6,7,8,9], image restoration [10,11], video generation [12,13], and more [14,15,16,17,18]. Notable examples are OpenAI’s DALL-E series [19,20,21], Google’s Imagen [22], and the recently famous Sora [23]. These systems built on DMs demonstrate astonishing creative capabilities.
Although the synthesis performance of DMs has surpassed many other generative models [24], such as Generative Adversarial Networks (GANs) [25], DMs still have high computational requirements. This is reflected in two aspects: on the one hand, the DMs have a huge model architecture. On the other hand, the iterative denoising method of DMs requires multi-step inference. This makes Stable Diffusion (SD) [26] stand out among numerous generative models by reducing the computational cost of DMs. The SD method converts the image into a latent space and then performs the diffusion process on this more efficient latent space. Another area for improvement with DMs is that they cannot control the generated results. Although SD supports text input to control the generated results, it still cannot provide precise control over the generated results.
The emergence of ControlNet [27] addresses the need for precise control over generated results. ControlNet is an innovative solution designed to enhance the controllability of SD’s output. By introducing additional conditional control mechanisms, ControlNet provides users with more excellent control capabilities during the generation process in a plug-and-play manner. These additional conditions include edge maps, human pose skeletons, segmentation masks, depth maps, and normals. This advancement not only enhances the practicality of SD but also indicates that DMs with precise controllability have broad application prospects in various fields, such as image processing, personalized content creation, advertising design, and filmmaking [28,29,30,31].
In image processing applications with precisely controllable DMs [32,33,34], high-precision image editing is exciting. High-precision image editing typically refers to keeping parts of the image other than the modified areas unchanged during the editing process. Specifically, details such as background, edges, and textures should remain intact, and the edited image must be consistent with the internal structure of the original image, including object positions, proportions, and lighting. At the same time, the editing results should align closely with the editing instructions [35].
Despite being praised for their boundless creativity and deep semantic capabilities, large-scale text-to-image DMs reveal limitations when directly intervening in images and achieving high-precision edits. Specifically, these models show insufficient flexibility when handling tasks that require delicate edits in specific regions of an image, primarily due to their extreme sensitivity to textual instructions. Even minor variations in input prompts can lead to significant changes in the output image, creating obstacles for implementing high-precision image editing tasks.
Some technical approaches have recently enhanced image editing quality by introducing additional control modules or fine-tuning existing models [6,27,36,37]. For instance, certain methods enhance specific control over editing results by incorporating dedicated control modules during training, improving overall image editing quality. Other methods include fine-tuning models for specific editing tasks to enhance the quality of edits. While these methods mitigate the problem of excessive sensitivity to textual instructions, a notable drawback is that they typically require independent training for each specific task, increasing implementation complexity and limiting their potential for widespread application. Moreover, in practical operations, this leads to significant changes in image details, contradicting the goal of pursuing high precision and detail integrity in editing and thus failing to meet user demands for maintaining image detail.
Although existing methods have progressed in some aspects of image editing, they still have significant limitations and cannot simultaneously balance high precision and operational convenience. Our research introduces a dual attention control method aimed at addressing the limitations of current DMs in high-precision image editing. This method ingeniously integrates cross-attention and self-attention control during the denoising phase of diffusion models to achieve high-precision image editing effects. Our method proves that the operation of attention control in the diffusion process can achieve high-precision editing tasks, as shown in Figure 1. Additionally, our method can achieve specified style transformations without optimizing or fine-tuning. More importantly, our technology is a zero-shot solution; unlike specific image editing techniques, our method can be applied to any text-to-image DMs based on attention mechanisms without requiring fine-tuning or optimization.
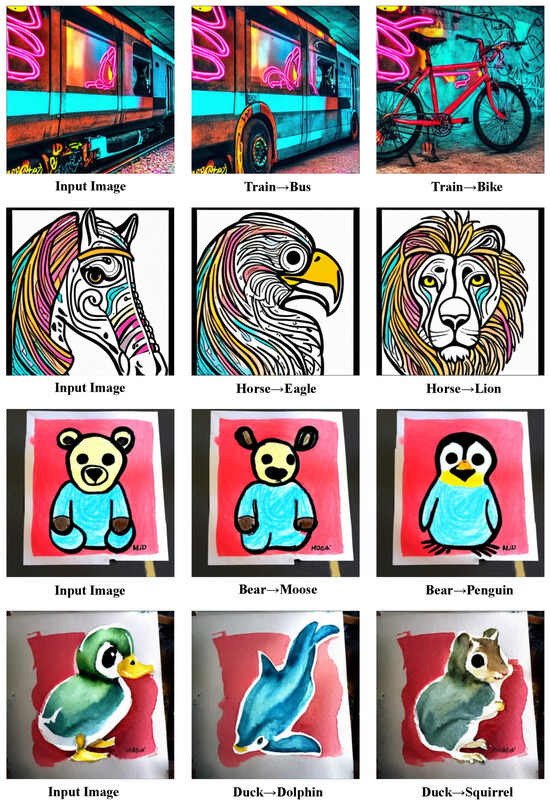
Figure 1.
Our method achieves perfect editing of large objects with good control over details and style.
Our main contributions are as follows:
(1) To address the limitations of current DMs in high-precision image editing, we propose a dual attention control method to achieve high-precision image editing, which cleverly combines cross-attention and self-attention control in the denoising stage of the diffusion model to achieve the effect of high-precision image editing.
(2) We designed a cross-attention control module, which combines the attention map of the original image and the attention of the edited image by introducing weight parameters so that the edited image can effectively preserve the structure of the input image without losing the details of the original image.
(3) We designed a self-attention control module that effectively maintains the details and style of the input image by applying self-attention control at “coarse” and “fine” layers, thus meeting high-precision editing requirements.
2. Related Work
2.1. Diffusion Models
In recent years, diffusion models have made significant progress, showcasing remarkable capabilities in image generation [1,2,3,24,26,30] and various downstream applications [5,9,10,13,14,15,16,38]. Among them, the Denoising Diffusion Probabilistic Models [1] and the Score-Based Model [2] are milestone works in the history of computer vision. Their successful practices have also inspired a lot of exploration and reference for subsequent related work. Guided Diffusion [24] further improves sampling quality with classifier guidance, enabling the model to better follow specific classes in the process of generative images from random noise, thereby generating high-quality images that better match the expected categories. This research outcome demonstrates that diffusion models outperform previous state-of-the-art generative GAN models [25].
2.2. Controllable Diffusion Models
Controllable Diffusion Models have developed rapidly in recent years [26,27,31,39]. Controllable Diffusion Models add additional conditions on top of the DMs to achieve control over the generated results. The most critical work among them is undoubtedly ControlNet [27], which is a plug-and-play model that achieves precise control over the generated output by introducing additional conditional inputs such as edge maps, human pose skeletons, segmentation masks, depth maps, and normals. During the same period as ControlNet, the T2I-Adapter [30] was a more efficient plug-and-play model. This is because ControlNet leverages the encoder structure from SD [26], which results in a large number of parameters. As a control network, it is not considered particularly efficient. In contrast, T2I-Adapter designed a lightweight control network, enabling it to achieve precise and diversified control and editing effects with greater efficiency.
2.3. Image Editing Using Controllable Diffusion Models
In the field of image editing, a technique called Prompt-to-Prompt [7] enables image content modification by changing the input text prompt. For example, it allowed transforming “A squirrel eating a burger” into “A lion eating a burger”. The core of this method lies in guiding the image transformation through changes in descriptive text prompts. Additionally, SDEdit [9] introduced a method based on the Stochastic Differential Equation for guided image generation and editing. SDEdit provided some guidance in the original image, such as adding graffiti or new patches, and the model can edit the image according to the guidance provided by the user. The introduction of the Null-Text Inversion [40] technique further enhances editing capabilities. This approach allowed users to modify specific objects in an image through textual descriptions without needing to process the entire image. It simplified the editing process and significantly extended the application of diffusion models to real-world image editing scenarios. Another noteworthy research outcome is InstructPix2Pix [6], which combined GPT-3’s [41] powerful language understanding with SD’s image generation capabilities to create datasets for training conditional diffusion models. Models trained in this way can modify images based on specific editing instructions, providing more flexible image editing functions. Similarly, DiffusionCLIP [36] and UniTune [37] achieved remarkable success in image editing using fine-tuning techniques. Meanwhile, the study titled An Edit Friendly DDPM Noise Space: Inversion and Manipulations (Edit Friendly DDPM Inv) [8] proposed an innovative idea with a new inversion algorithm that extracts an editable noise map from any image. This improvement reduces the time required for image editing in diffusion models.
3. Preliminaries
3.1. Denoising Diffusion Probabilistic Models
Denoising Diffusion Probabilistic Models (DDPMs) [1] are mainly divided into two stages: the diffusion stage and the sampling stage. Firstly, the diffusion stage is the process of gradually adding Gaussian noise to the image until it becomes purely Gaussian noise. DDPM defines the noise coefficients , which increases linearly from to . The noisy image at time step t is obtained by adding noise to the noisy image at time step . The specific formula is as follows:
with , and .
According to Equation (1), we can derive the diffusion formula from to any time step t:
with , and .
Secondly, the sampling stage is a process of gradual denoising using a trained denoising UNet [42]. For each denoising time step, the model predicts the noise in the current noisy image , and the denoising result in time step t can be described as . Directly using as the output often leads to unsatisfactory image quality, so we need to add noise with a smaller noise level to to obtain , and then continue denoising on to derive . This denoising process is iterated until a high-quality generated image is obtained. Therefore, we can obtain the following sampling formula:
with , a denoiser that predicts the noise in at time step t; , the parameter of the noise predictor; and .
The goal of training in DDPM is to make the predicted noise of the denoising model as close as possible to the actual added noise. In order to train the model parameters, DDPM generally uses L2 Loss as the loss function. This results in the following training formula for the DDPM:
with , and .
3.2. Stable Diffusion
The difference between the Stable Diffusion (SD) [26] and DDPM is that SD compresses the input image from pixel space to latent space through a Variational Autoencoder (VAE) [43]; the compressed result is represented as . SD is a text-to-image model, so there will be an additional text prompt condition during training. Consequently, the training formula for SD is Equation (6).
with being a denoiser that predicts the noise in at time step t, is the parameter of the noise predictor, , and .
At the same time, the sampling formula for SD can be obtained by:
The SD using the sampling algorithm proposed by DDPM for sampling cannot control the matching degree between the synthesized image and the given prompt. To solve this problem, Classifier-Free Diffusion Guidance (CFG) [39] is a very effective tool. CFG is a technique applied to conditional diffusion models to enhance the correlation between generated images and conditions. When the scale of CFG is set higher, the model is more inclined to generate images that closely match the given prompt. Generally speaking, the application of CFG in the sampling process of SD can be simplified as follows:
with ⌀ representing a NULL text, being a textual condition, and being the scale factor of CFG.
4. Method Overview
We first outline the model architecture (Section 4.1), with a focus on the internal structure (Section 4.2). Most importantly, we discuss the control operations on multiple attention mechanisms within the internal structure (Section 4.3), aimed at achieving the high-precision requirements of image editing.
4.1. Model Architectures
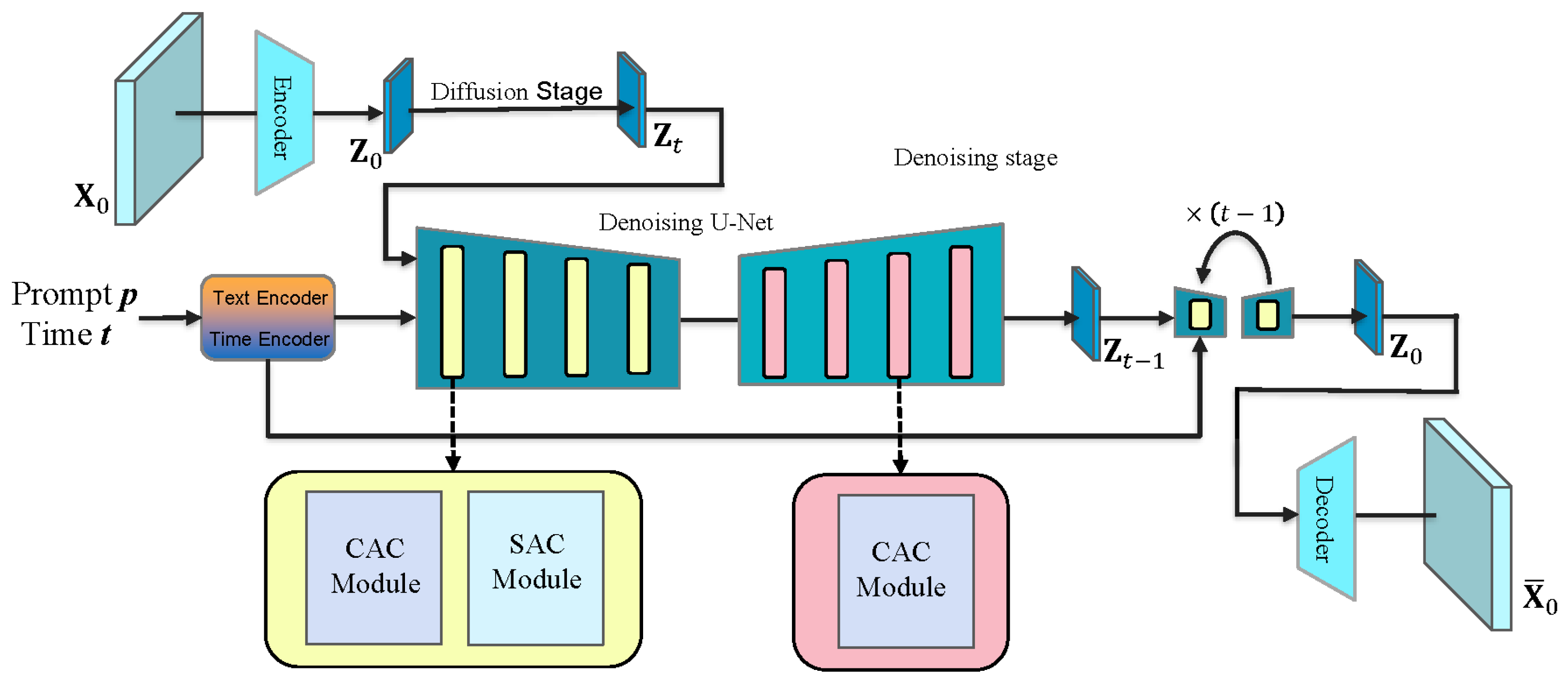
Our approach is based on the SD network structure, which consists of several sub-networks, as shown in Figure 2, including a text encoder, U-Net [42,44], and Variational Autoencoder (VAE) [43]. The cross-attention [45,46] and self-attention control modules are incorporated within the Transformer modules [47] of the U-Net architecture (explained in detail in Section 4.3). These components combine to form a model that takes text, noise level, and random Gaussian noise as inputs and outputs an image.
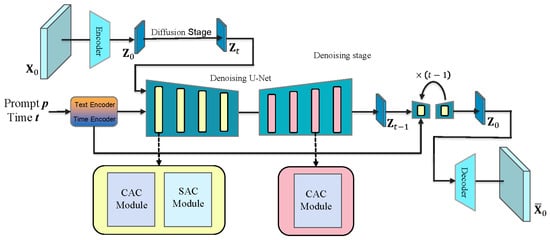
Figure 2.
The model framework diagram of this paper. CAC Module is a cross-attention control module, and SAC Module is a self-attention control module. CAC Module is used throughout the denoising process, and SAC Module is used in layers 1–4 or 5–8, depending on the editing tasks.
The training process for the model is as follows:
First, a dataset of text–image pairs is prepared, where is the original image, and is the textual description associated with image . A noise level t is set, which represents the number of steps in the diffusion process where noise is added.
Diffusion phase: The original image is passed through the encoder part of the VAE, converting it into a latent space representation . Starting from , Gaussian noise is incrementally added t times in the latent space, resulting in a highly noisy latent variable .
Denoising phase: The text prompt and the noise level t are input into the text encoder and the time encoder, which convert them into text embeddings and time embeddings, respectively. At each time step t, the text embedding, time embedding, and are fed into the U-Net. The U-Net predicts the noise component in and removes it. At this time, the generated result is not ideal, and a slight Gaussian noise will be added to the result to generate . This process is repeated, progressively reducing t until , at which point should approximate the latent representation of the original image.
In practice, image generation starts from random noise. Using a pre-trained model, noise is gradually removed through the denoising process until a high-quality image is generated. The sampling and training formulas are shown in Algorithm 1.
| Algorithm 1 Training and sampling |
|
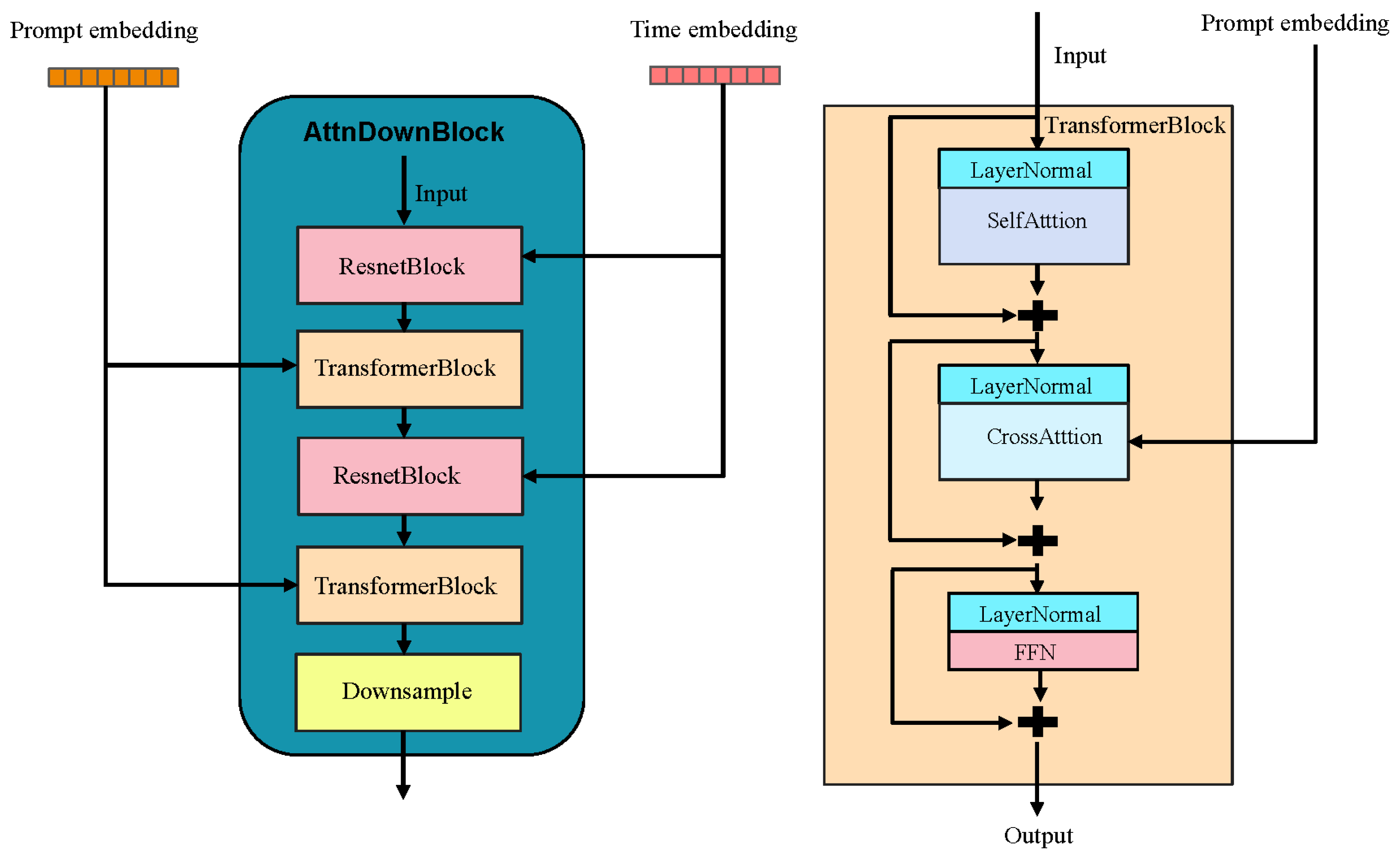
4.2. Model Internal Structure
As mentioned in Section 4.1, the model uses a U-Net architecture, which consists of four encoder blocks (three attention downsampling blocks and one downsampling block), one middle block, and four decoder blocks (one upsampling block and three attention upsampling blocks). This U-Net serves as a denoising network and is the model’s core. Taking the attention downsampling block as an example, as shown in Figure 3 left, the time embeddings are fed into the ResNet block [48], while the prompt embeddings are fed into the Transformer block [47]. The Transformer module mainly consists of two attention mechanisms (see Figure 3 right): self-attention and cross-attention. In cross-attention, the prompt words interact with the input image, while self-attention mainly processes the internal information of the input image. Through these attention mechanisms, the deep image features communicate with each other via the self-attention layer and attend to the contextual text embeddings via the cross-attention layer. Cross-attention determines the spatial layout and geometric shapes of the generated image content. Our method effectively combines and controls these two types of attention, enabling communication between the edited and original images to achieve high-precision image editing.
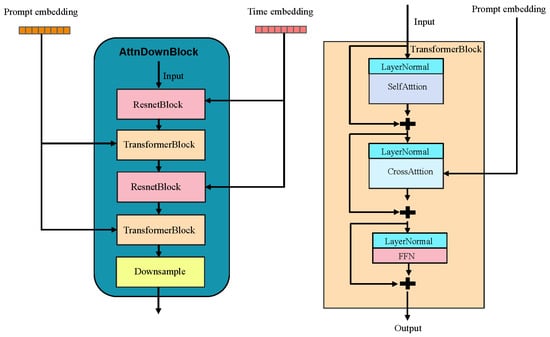
Figure 3.
The denoising U-Net’s attention downsampling block. The attention upsampling block attaches a ResNet block and a Transformer block, where downsampling is replaced by upsampling. Additionally, the final attention-based upsampling block does not perform any upsampling.
4.3. Attention Control
Section 4.2 has provided a detailed explanation of the model’s internal structure. To achieve high-precision image editing, the model not only needs to understand the information from the editing instructions but also keep the unedited regions unchanged. This requires effective combined control of the two types of attention mechanisms within the model’s internal structure.
4.3.1. Controlling the Cross-Attention
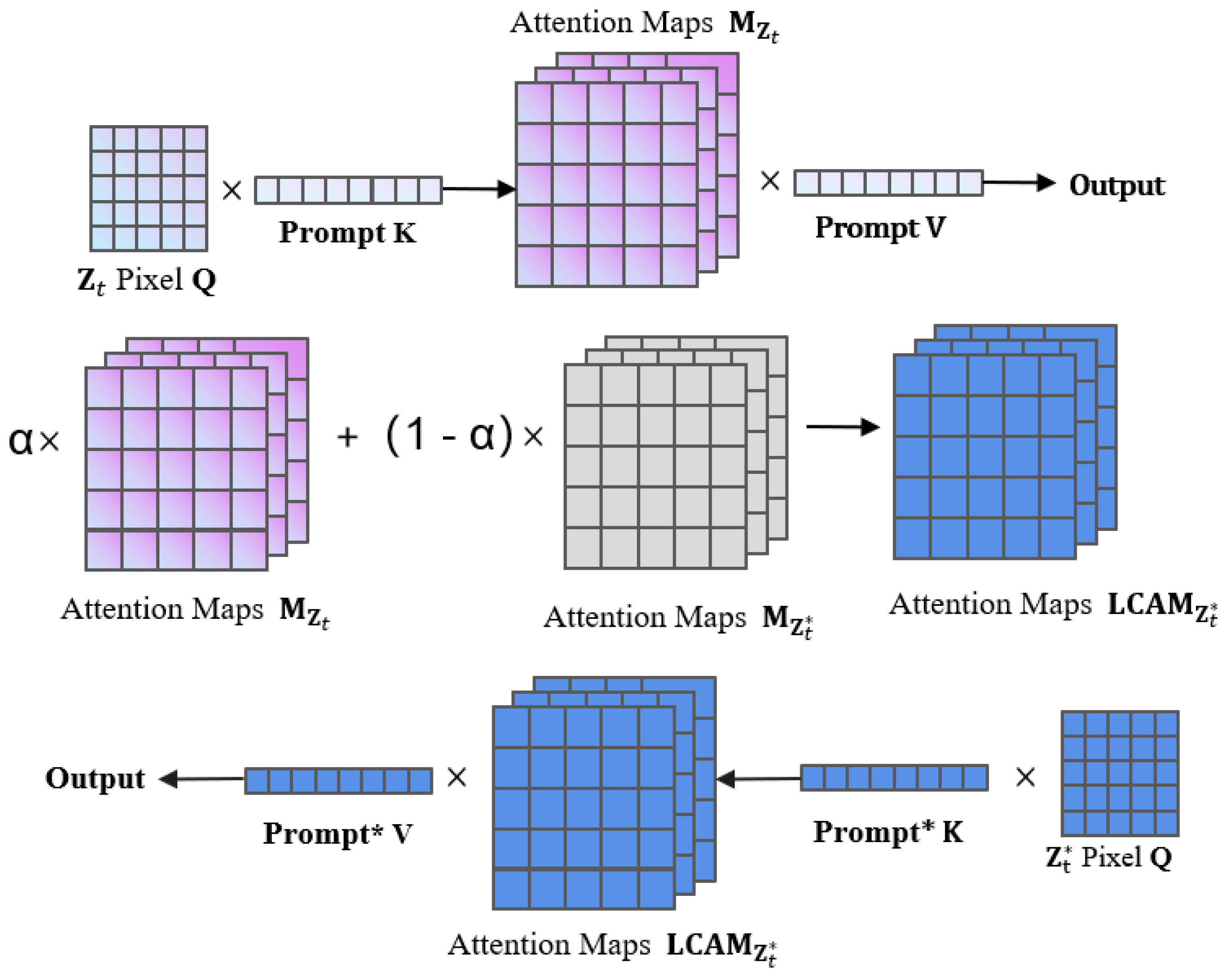
Cross-attention layers are designed to capture interactions between different sequences. In this case, we weight the attention map from the original prompt and the attention map from the modified prompt and replace the modified attention map. This modification can better control which parts of the input sequence should be attended to, generating a specific desired outcome, as shown in Figure 4. Specifically, the attention map , obtained from the generation of the initial prompt , can be injected into the generation process of the modified prompt . This allows the synthesis of an edited image while preserving the structure of the input image. In detail, suppose the following:
represents a step in the denoising process, where the output is the noisy image and the attention map . Subsequently, our diffusion step will be expressed as:
where is the original prompt, is the editing prompt for the modified image, and s is the random seed. To prevent randomness, the random seed needs to be fixed. This is due to the nature of diffusion models, where even with identical prompts, two different random seeds can lead to entirely different outputs. We do not directly substitute the attention map of the original image for that of the edited image . Instead, a linear combination of both is achieved by introducing a parameter , which controls the weight between the original and edited attention maps. This parameter provides a flexible method to adjust the extent of detail retention. Direct substitution could lead to a loss of subtle yet critical structural information present in the original image, resulting in unnatural artifacts in the generated image. The linear combination method allows for more precise control over which aspects should be emphasized or preserved, especially in local modification tasks. This method better maintains overall consistency and integrates two attention maps via smooth transitions, thereby retaining original characteristics while introducing new elements. Consequently, this leads to a more harmonious and natural editing effect.
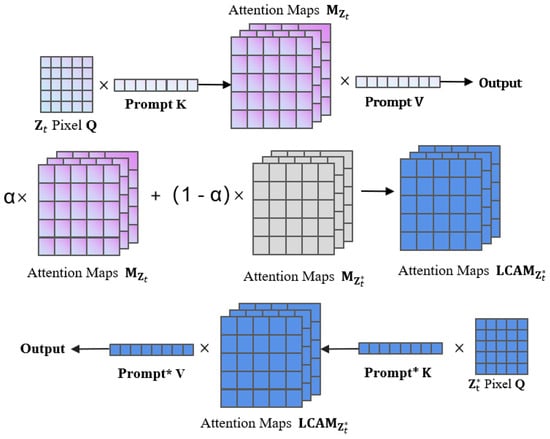
Figure 4.
CAC Module.
4.3.2. Controlling the Self-Attention
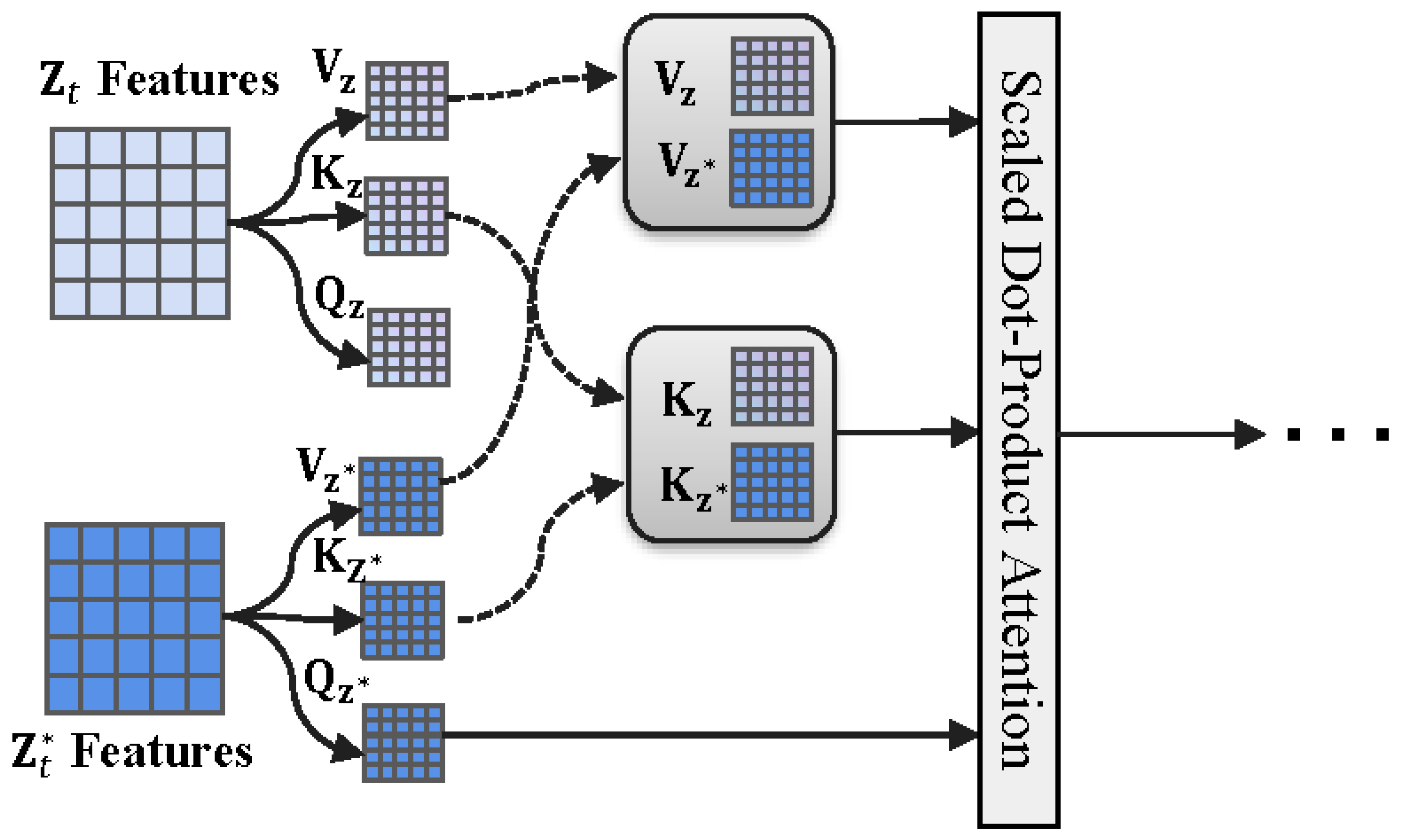
Under the control of cross-attention, while the synthesized edited image can retain the structure of the input image, many fine details of the edited image may undergo significant changes. At this point, controlling self-attention becomes necessary to preserve the image details. Typically, , , and are the query, key, and value projected from the deep features of the input image . The formula gives the attention update:
Now, if we concatenate the querie and key projected from the deep features of the target image with the querie and key projected from the deep features of the input image (see Figure 5), the attention update is as follows:
where and . This allows the target image, during synthesis, to attend to the content of the original image, ensuring that the unedited areas remain consistent with the original image. However, we found that if self-attention control is applied throughout the entire generation process, even the areas meant to be edited are strongly influenced, leading to suboptimal editing results. To address this, we adjust the strength of the self-attention control based on the specific editing task and apply it to different layers of the model. This ensures that the unedited regions retain their details while allowing sufficient flexibility for effective editing in the desired areas.
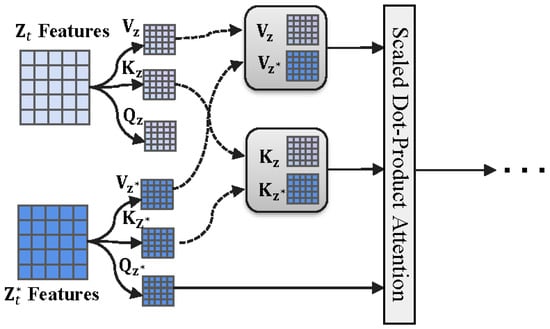
Figure 5.
SAC Module.
5. Experiment
5.1. Experiment Settings
All our experiments were conducted using the Geforce RTX 4090 GPU produced by Asus in Taiwan, China. We utilized SD as the conditional diffusion model, and our proposed method does not require additional training or fine-tuning. We demonstrate image editing results based on text prompts, successfully applying our approach to tasks that demand high precision and fine-grained edits. We compared our method qualitatively (see Figure 6) and quantitatively (see Table 1) with recent works such as Prompt-to-Prompt [7], An Edit Friendly DDPM Noise Space: Inversion and Manipulations (Edit Friendly DDPM Inv) [8], and InstructPix2Pix: Learning to Follow Image Editing Instructions (InstructPix2Pix) [6]. For the ablation experiment setup, since Stable Diffusion v1.4 includes 16 attention layers, we apply cross-attention control across all 16 layers. Self-attention control is split into two cases: for detail preservation, self-attention control is applied in layers 5–8, which we define as the self-attention control coarse layer. For style transformation, self-attention control is applied in layers 1–4, which we define as the self-attention fine control layer.

Figure 6.
Qualitative comparison of our method with the state-of-the-art methods. Our results are shown in the last column, and it is clear that our method performs well in preserving the details of the original image while accurately understanding and executing the editing instructions.

Table 1.
Quantitative comparison of our method with the state-of-the-art methods on CLIP Score, FID, LPIPS.
5.2. Comparisons
Qualitative Comparisons: Figure 6 illustrates the qualitative comparison results with Edit Friendly DDPM Inv [8], InstructPix2Pix [6], and Prompt-to-Prompt [7]. Specifically, while Edit Friendly DDPM Inv provides quick editing results, it often leads to unnatural edits and, in some cases, fails to comprehend the editing instructions fully, causing the edits to be ineffective (Figure 6 column 2). In contrast, InstructPix2Pix tends to lose detail in complex scenes, and the uncertainty in the editing instructions makes it challenging to preserve the overall style of the input image (Figure 6 column 3). Finally, Prompt-to-Prompt’s reliance on text prompts affects the fidelity of the edited images, leading to significant changes in details (Figure 6 column 4). These limitations make it difficult for these methods to achieve high precision and subtle image edits. In contrast, our method produces more natural and smooth edits while maintaining the overall structure and style of the input image. It retains the key features of the input image and adheres to the editing instructions, ensuring high precision and detailed control in the edited output.
Quantitative Comparisons: Table 1 compares our method with several existing techniques, including An Edit Friendly DDPM Inv [8], InstructPix2Pix [6], and Prompt-to-Prompt [7], based on quantitative metrics. We evaluated 1000 test images using two key metrics: LPIPS (measuring fidelity to the source image, with lower values indicating higher fidelity), CLIP score (measuring the consistency between the generated image and the target text, with higher values indicating better alignment), and FID (a measure of distance between two distributions of image sets, where a lower FID score implies that the distribution of generated images is closer to that of real images). According to the data presented in the table, our method achieves state-of-the-art FID and CLIP scores while maintaining a relatively low LPIPS score, indicating that our editing results maintain high fidelity to the source image and are highly consistent with the editing instructions. This balance highlights the effectiveness of our approach in providing precise editing with detail preservation. The CLIP score is significant in tasks requiring high precision and detail in image editing [35], as it reflects the model’s ability to understand and execute the editing instructions. A higher CLIP score indicates that the system better captures the user’s intent and applies it effectively to the image editing process.
The CLIP (Contrastive Language–Image Pretraining) score is commonly used to evaluate the quality of image generation or editing models. CLIP is a pretrained model that learns representations of both text and images simultaneously from a large number of text–image pairs through contrastive learning. The CLIP score is obtained by calculating the similarity between generated images and the text that describes them. This score measures how well the generated image matches the target description. A higher score indicates greater relevance between the image and the text. LPIPS (Learned Perceptual Image Patch Similarity) is a metric for assessing perceptual differences between two images. Unlike traditional pixel-wise difference metrics, LPIPS computes distances in the feature space derived from deep convolutional neural networks. By considering the characteristics of the human visual system, LPIPS better reflects the perceived similarity of images by humans. Lower LPIPS values indicate that two images appear more visually similar. FID (Fréchet Inception Distance) is a statistical distance measure used to compare two distributions of images, particularly suitable for evaluating the quality of image generation models. FID calculates the Fréchet distance between the distributions of feature vectors obtained by encoding real and generated image sets through the Inception V3 model. A lower FID value suggests that the distribution of generated images is closer to that of real images, which generally implies better generation quality.
5.3. Ablation Study
This study combines self-attention and cross attention control layers to improve the performance of the model for editing tasks. In order to evaluate the precise impact of these attention mechanisms on the model’s performance, we designed and performed three ablation experiments to analyze the effectiveness of our method qualitatively and quantitatively. The first ablation experiment systematically evaluated the changes in model performance under different configurations, thereby verifying the superiority of dual attention control in high-precision image editing tasks. The second ablation study aims to explore the effects of using cross attention control layers alone, using “coarse layer” self-attention control alone, and combining the two. The third ablation study mainly explores the effects of using cross attention control layers alone, using “fine layer” self-attention control alone, and combining the two.
5.3.1. Module Quantitative Analysis—Coarse Layer
To systematically evaluate changes in model performance under different configurations and to verify the superiority of dual attention mechanisms in high-precision image editing tasks, this study designed an ablation experiment, see Table 2. Specifically, a baseline model without any attention mechanisms was established as the control group to set a performance benchmark. Subsequently, the model performances were examined with only the cross-attention control integrated and then with only self-attention control integrated. Finally, in the fourth setting, both cross-attention control and self-attention control were simultaneously incorporated into the model.
Table 2.
Quantitative analysis of the dual attention control proposed by our method.
The experimental results indicate that in high-precision image editing tasks, optimal performance is achieved only when the model adopts cross-attention control alongside targeted self-attention control implemented at different levels according to specific task requirements. This finding underscores not only the importance of attention mechanisms in enhancing the quality of image editing, but also highlights the critical role of combining different types of attention mechanisms for achieving superior editing outcomes. The integration of these mechanisms ensures that the precision demands of such tasks are met, thus advancing the field of high-precision image editing.
5.3.2. Module Qualitative Analysis—Fine Layer
As shown in Figure 7, if control is not used (column 2), the diffusion model will generate another image instead of completing the image editing. Using only cross-attention control (column 3): When using only cross-attention control, while the specified region can be edited, unnecessary changes also occur in other parts of the source image. This not only alters the edited area, but also causes significant changes in unedited areas, affecting the overall fidelity of the image and failing to meet the high-precision editing requirements. Using both cross-attention control and self-attention control in layers 5–8 (column 5): We found that applying self-attention control in layers 5–8 effectively preserves the details of the source image. This approach is suitable for situations that require precise control over editing details, as these layers can be considered the “coarse layers” of self-attention control, helping to retain the fundamental structure and details of the source image.

Figure 7.
Self-attention control in coarse layers. Using only cross-attention control results in significant changes in detail and background (column 3, for example, the background of the bear changes from a house to a car), whereas using dual attention control maintains detail while enabling the desired editing.
As shown in Figure 8, using only cross-attention control (column 3): While style transformation can still be achieved using only cross-attention control, many areas of the image are re-generated in addition to the style change. This gives the impression that an entirely new image with a different style has been generated rather than an edited version of the original image. Using only self-attention control (column 4), the image retains some features of the input image, but cannot perform the desired editing or style transfer. Using both cross-attention control and self-attention control in layers 1–4 (column 5): When editing the style of an image, we recommend using self-attention control in layers 1–4. These layers can be considered the “fine layer” of self-attention control, better suited for style transformations. This approach effectively alters the overall style of the image while minimizing the impact on non-edited areas.

Figure 8.
Self-attention control in fine layers. Using only cross-attention control will cause a large change in the entire image (column 3, for example, the shape of the tree and the layout of the street), while using dual attention control can achieve the desired style transfer while keeping the content and details consistent with the original image.
6. Conclusions
Our proposed method addresses the limitations of existing image editing techniques in terms of precise control and detail preservation by applying control over the attention mechanisms in diffusion models. Our approach enables high-precision image editing and supports style transformations. By comparing existing techniques, we demonstrate superior performance in quantitative and qualitative evaluations, especially in the critical metric of CLIP scores. This shows that our method has a better understanding and execution of user editing instructions. Furthermore, by introducing dual visual attention control, our method demonstrates zero-shot characteristics and extremely high flexibility across various image editing scenarios. Compared to a scenario with no control, adopting dual control has led to improvements: the CLIP Score increased by 6.19%, LPIPS decreased by 29.3%, and FID was reduced by 24.7%. These enhancements verify the effectiveness of our proposed dual attention control. Additionally, the zero-shot nature of our method allows it to be easily applied to different image editing scenarios without additional training or fine-tuning, significantly enhancing its practicality and flexibility. Although our method performs well in various situations, it still has limitations when dealing with blurry images. Future research will focus on overcoming these limitations and further exploring the application of self-attention mechanisms in image editing and other image-processing tasks.
Author Contributions
Conceptualization, Z.P.; funding acquisition, Y.K., J.L. and L.Z.; methodology, Z.P.; resources, Y.K. and L.Z.; validation, Z.P.; writing—original draft, Z.P.; writing—review and editing, Y.K., J.L. and L.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This research is supported by the National Natural Science Foundation of China under Grant 61972147 and the Open project fund of Dongting Lake Basin Ecological Protection and Restoration Engineering Technology Innovation Center of the Ministry of Natural Resources under Grant DTB.TICECR-2024-06.
Data Availability Statement
The original contributions presented in this study are included in the article. The data in the article were generated by diffusion modeling. For further inquiries, please contact the corresponding author.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Ho, J.; Jain, A.; Abbeel, P. Denoising diffusion probabilistic models. Adv. Neural Inf. Process. Syst. 2020, 33, 6840–6851. [Google Scholar]
- Song, Y.; Ermon, S. Generative modeling by estimating gradients of the data distribution. Adv. Neural Inf. Process. Syst. 2019, 32. [Google Scholar]
- Song, Y.; Sohl-Dickstein, J.; Kingma, D.P.; Kumar, A.; Ermon, S.; Poole, B. Score-Based Generative Modeling through Stochastic Differential Equations. In Proceedings of the International Conference on Learning Representations, Virtual Event, Austria, 3–7 May 2021. [Google Scholar]
- Yang, J.; Feng, J.; Huang, H. EmoGen: Emotional Image Content Generation with Text-to-Image Diffusion Models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024. [Google Scholar]
- Zhou, Y.; Liu, B.; Zhu, Y.; Yang, X.; Chen, C.; Xu, J. Shifted diffusion for text-to-image generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023. [Google Scholar]
- Brooks, T.; Holynski, A.; Efros, A.A. InstructPix2Pix: Learning to Follow Image Editing Instructions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023. [Google Scholar]
- Hertz, A.; Mokady, R.; Tenenbaum, J.; Aberman, K.; Pritch, Y.; Cohen-or, D. Prompt-to-Prompt Image Editing with Cross-Attention Control. In Proceedings of the International Conference on Learning Representations, Virtual, 25–29 April 2022. [Google Scholar]
- Huberman-Spiegelglas, I.; Kulikov, V.; Michaeli, T. An Edit Friendly DDPM Noise Space: Inversion and Manipulations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16–22 June 2024. [Google Scholar]
- Meng, C.; He, Y.; Song, Y.; Song, J.; Wu, J.; Zhu, J.Y.; Ermon, S. SDEdit: Guided Image Synthesis and Editing with Stochastic Differential Equations. In Proceedings of the International Conference on Learning Representations, Virtual Event, Austria, 3–7 May 2021. [Google Scholar]
- Luo, Z.; Gustafsson, F.K.; Zhao, Z.; Sjölund, J.; Schön, T.B. Refusion: Enabling large-size realistic image restoration with latent-space diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshop, Vancouver, BC, Canada, 17–24 June 2023. [Google Scholar]
- Xia, B.; Zhang, Y.; Wang, S.; Wang, Y.; Wu, X.; Tian, Y.; Yang, W.; Van Gool, L. Diffir: Efficient diffusion model for image restoration. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023. [Google Scholar]
- Xu, Z.; Zhang, J.; Liew, J.H.; Yan, H.; Liu, J.W.; Zhang, C.; Feng, J.; Shou, M.Z. Magicanimate: Temporally consistent human image animation using diffusion model. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024. [Google Scholar]
- Yu, S.; Sohn, K.; Kim, S.; Shin, J. Video probabilistic diffusion models in projected latent space. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023. [Google Scholar]
- Kim, J.; Kim, T.K. Arbitrary-Scale Image Generation and Upsampling using Latent Diffusion Model and Implicit Neural Decoder. In Proceedings of the CVPR, Seattle, WA, USA, 16–22 June 2024. [Google Scholar]
- Wu, C.H.; De la Torre, F. A latent space of stochastic diffusion models for zero-shot image editing and guidance. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023. [Google Scholar]
- Qi, F.; Duan, Y.; Zhang, H.; Xu, C. SignGen: End-to-End Sign Language Video Generation with Latent Diffusion. In Proceedings of the European Conference on Computer Vision (ECCV), Milan, Italy, 29 September–4 October 2024. [Google Scholar]
- Garber, T.; Tirer, T. Image restoration by denoising diffusion models with iteratively preconditioned guidance. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024. [Google Scholar]
- Liu, H.; Wang, Y.; Qian, B.; Wang, M.; Rui, Y. Structure Matters: Tackling the Semantic Discrepancy in Diffusion Models for Image Inpainting. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024. [Google Scholar]
- Betker, J.; Goh, G.; Jing, L.; Brooks, T.; Wang, J.; Li, L.; Ouyang, L.; Zhuang, J.; Lee, J.; Guo, Y. Improving image generation with better captions. Comput. Sci. 2023, 2, 8. [Google Scholar]
- Ramesh, A.; Dhariwal, P.; Nichol, A.; Chu, C.; Chen, M. Hierarchical text-conditional image generation with clip latents. arXiv 2022, arXiv:2204.06125. [Google Scholar]
- Ramesh, A.; Pavlov, M.; Goh, G.; Gray, S.; Voss, C.; Radford, A.; Chen, M.; Sutskever, I. Zero-shot text-to-image generation. In Proceedings of the International Conference on Machine Learning, PMLR, Online, 8–24 July 2021. [Google Scholar]
- Saharia, C.; Chan, W.; Saxena, S.; Li, L.; Whang, J.; Denton, E.L.; Ghasemipour, K.; Gontijo Lopes, R.; Karagol Ayan, B.; Salimans, T. Photorealistic text-to-image diffusion models with deep language understanding. Adv. Neural Inf. Process. Syst. 2022, 35, 36479–36494. [Google Scholar]
- OpenAI. Video Generation Models as World Simulators. 2024. Available online: https://openai.com/research/video-generation-models-as-world-simulators (accessed on 9 January 2025).
- Dhariwal, P.; Nichol, A. Diffusion models beat gans on image synthesis. Adv. Neural Inf. Process. Syst. 2021, 34, 8780–8794. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Process. Syst. 2014, 27. [Google Scholar]
- Rombach, R.; Blattmann, A.; Lorenz, D.; Esser, P.; Ommer, B. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Zhang, L.; Rao, A.; Agrawala, M. Adding conditional control to text-to-image diffusion models. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023. [Google Scholar]
- Fernandez, P.; Couairon, G.; Jégou, H.; Douze, M.; Furon, T. The stable signature: Rooting watermarks in latent diffusion models. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023. [Google Scholar]
- Khachatryan, L.; Movsisyan, A.; Tadevosyan, V.; Henschel, R.; Wang, Z.; Navasardyan, S.; Shi, H. Text2video-zero: Text-to-image diffusion models are zero-shot video generators. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023. [Google Scholar]
- Mou, C.; Wang, X.; Xie, L.; Wu, Y.; Zhang, J.; Qi, Z.; Shan, Y. T2i-adapter: Learning adapters to dig out more controllable ability for text-to-image diffusion models. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 20–27 February 2024. [Google Scholar]
- Zhang, F.; You, S.; Li, Y.; Fu, Y. Atlantis: Enabling Underwater Depth Estimation with Stable Diffusion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024. [Google Scholar]
- Cao, M.; Wang, X.; Qi, Z.; Shan, Y.; Qie, X.; Zheng, Y. Masactrl: Tuning-free mutual self-attention control for consistent image synthesis and editing. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023. [Google Scholar]
- Wu, J.Z.; Ge, Y.; Wang, X.; Lei, S.W.; Gu, Y.; Shi, Y.; Hsu, W.; Shan, Y.; Qie, X.; Shou, M.Z. Tune-a-video: One-shot tuning of image diffusion models for text-to-video generation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023. [Google Scholar]
- Xiu, Y.; Yang, J.; Cao, X.; Tzionas, D.; Black, M.J. Econ: Explicit clothed humans optimized via normal integration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023. [Google Scholar]
- Huang, Y.; Huang, J.; Liu, Y.; Yan, M.; Lv, J.; Liu, J.; Xiong, W.; Zhang, H.; Chen, S.; Cao, L. Diffusion model-based image editing: A survey. arXiv 2024, arXiv:2402.17525. [Google Scholar]
- Kim, G.; Kwon, T.; Ye, J.C. Diffusionclip: Text-guided diffusion models for robust image manipulation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 2426–2435. [Google Scholar]
- Valevski, D.; Kalman, M.; Matias, Y.; Leviathan, Y. Unitune: Text-driven image editing by fine tuning an image generation model on a single image. ACM Trans. Graph. 2022, 2, 5. [Google Scholar]
- Gal, R.; Alaluf, Y.; Atzmon, Y.; Patashnik, O.; Bermano, A.H.; Chechik, G.; Cohen-Or, D. An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion. In Proceedings of the International Conference on Learning Representations, Virtual, 25–29 April 2022. [Google Scholar]
- Ho, J.; Salimans, T. Classifier-Free Diffusion Guidance. In Proceedings of the NeurIPS 2021 Workshop on Deep Generative Models and Downstream Applications, Online, 13 December 2021. [Google Scholar]
- Mokady, R.; Hertz, A.; Aberman, K.; Pritch, Y.; Cohen-Or, D. Null-text inversion for editing real images using guided diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 6038–6047. [Google Scholar]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. Adv. Neural Inf. Process. Syst. 2020, 33, 1877–1901. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; Proceedings, Part III 18. Springer: Berlin/Heidelberg, Germany, 2015. [Google Scholar]
- Kingma, D.P.; Welling, M. Auto-Encoding Variational Bayes. arXiv 2014, arXiv:1312.6114. [Google Scholar]
- Zhou, L.; Zhao, J.; He, J. A Diffusion Modeling-Based System for Teaching Dance to Digital Human. Appl. Sci. 2024, 14, 9084. [Google Scholar] [CrossRef]
- Yook, D.; Han, G.; Chang, H.P.; Yoo, I.C. CycleDiffusion: Voice Conversion Using Cycle-Consistent Diffusion Models. Appl. Sci. 2024, 14, 9595. [Google Scholar] [CrossRef]
- Xue, S.; Liu, Z.; Chen, F.; Zhang, S.; Hu, T.; Xie, E.; Li, Z. Accelerating Diffusion Sampling with Optimized Time Steps. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024. [Google Scholar]
- Vaswani, A. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]



Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).