Abstract
With the increasing global demand for artificial intelligence solutions, their role in medicine is also expected to grow as a result of their advantage of easy access to clinical data. Machine learning models, with their ability to process large amounts of data, can help solve clinical issues. The aim of this study was to construct seven machine learning models to predict the outcomes of emergency department patients and compare their prediction performance. Data from 75,803 visits to the emergency department of a public hospital between January 2022 to December 2023 were retrospectively collected. The final dataset incorporated 34 predictors, including two sociodemographic factors, 23 laboratory variables, five initial vital signs, and four emergency department-related variables. They were used to predict the outcomes (mortality, referral, discharge, and hospitalization). During the study period, 316 (0.4%) visits ended in mortality, 5285 (7%) in referral, 13,317 (17%) in hospitalization, and 56,885 (75%) in discharge. The disposition accuracy (sensitivity and specificity) was evaluated using 34 variables for seven machine learning tools according to the area under the curve (AUC). The AUC scores were 0.768, 0.694, 0.829, 0.879, 0.892, 0.923, and 0.958 for Adaboost, logistic regression, K-nearest neighbor, LightGBM, CatBoost, XGBoost, and Random Forest (RF) models, respectively. The machine learning models, especially the discrimination ability of the RF model, were much more reliable in predicting the clinical outcomes in the emergency department. XGBoost and CatBoost ranked second and third, respectively, following RF modeling.
1. Introduction
The usage of artificial intelligence (AI) in various areas enhances the performance of proposed systems and helps end users of the systems. Personalized medicine, medication development, medical imaging analysis, and illness detection are all machine learning (ML) applications in healthcare [1,2,3]. Additionally, ML methods offer natural language processing for medical records, clinical decision support systems, epidemic prediction, wearable device monitoring, healthcare operations optimization, and predictive analytics for patient outcomes [1,2,3].
In emergency departments (EDs), early assessment, diagnosis, and referral of patients to appropriate areas (discharge from hospital, hospitalization, patient referral, etc.) are vital for ED functioning and the management of limited resources. It is an important issue for emergency departments to determine how the management of the patients will continue in the hospital, taking into account vital signs, medical tests, and demographic information of the patients. The hypothesis of this study investigates whether predictive AI-based approaches can enhance the accuracy of forecasting ED disposition and assess the potential of such systems to support medical practitioners. This study aims to utilize the information gathered from patients in the emergency department to assist specialist doctors in making decisions regarding patient hospitalization through the application of decision-support approaches developed using machine learning models.
With the increasing use of EDs in hospitals around the world, the uneven distribution of resources, delays in patient care, and subsequent increases in morbidity and mortality have become major public health issues [1,2,3]. EDs, where diagnostic and therapeutic interventions must be carried out quickly and effectively [4], are also where hospital outcomes are administered [5]. Evidence shows that the early prediction of hospital outcomes improves patient flow in the ED [6,7]. Prediction models provide opportunities to identify high-risk patients and prioritize limited medical supplies. Today, artificial intelligence (AI) is used in many medical applications, especially to reinforce the decision-making process and improve healthcare services, and the ED is one of them [8]. Due to the rapid progress in the field of machine learning, it is inevitable that the impact of AI on working life in the ED will increase. Changes will take place in the mapping, measurement, and management phases. In the first stage, clinical problems will be identified, and AI methods will be explored. In this study, we worked on ML modeling in accordance with clinical problems in the emergency department [9].
Swift improvements in the applications of AI have revealed the possibility of utilizing the data from healthcare services to generate reliable machine learning (ML) models that can timely and dynamically automatize clinical decisions [10]. ED prediction models focus on a complex clinical judgment that depends on the patient’s possible acute course, the status of medical resources, and local applications [11]. ML models have advantages such as reducing the load on EDs, preventing redundant testing, and contributing to a faster and more precise decision-making process for healthcare professionals [12]. Although the implementation of AI in the medical field is highly controversial in terms of ethical aspects, it is expected to be more widespread in the following years due to its contribution to the clinical decision-making process. The main objective of this study is to predict the outcomes (referral, discharge, hospitalization, and mortality) of ED patients with ML models and to compare the prediction performances of the models. ML-based models could help MDs in making accurate decisions regarding the outcomes of ED patients. This study aims to contribute to the literature by generating a substantial dataset, developing seven distinct models using seven different machine learning approaches, and incorporating 34 unique features for modeling. Additionally, this study explores the impact of features separately—often underemphasized in similar research—on the outcomes of ED patients.
The rest of this paper is organized as follows. The next section briefly presents the related works in the literature. Section 3 introduces the dataset, ML methods, the proposed model, and the dataset used. The experimental results are presented in Section 4. The results are discussed in Section 5. Finally, the last section concludes the paper.
2. Related Works
Several studies have examined the application of machine learning (ML) and artificial intelligence (AI) in predicting patient outcomes in emergency departments (EDs). Larburu et al. [13] reviewed models for identifying hospitalized patients in EDs, focusing on commonly used prediction methods. Feretzakis et al. [14] compared the performance of various ML algorithms in patient outcome prediction. Kishore et al. [15] explored the early prediction of hospital admissions using multiple ML approaches. Parker et al. [16] analyzed the predictive capabilities of ML models using extensive patient datasets. Hond et al. [17] evaluated the impact of different variables and time intervals on model performance. Hong et al. [18] investigated integrating prior information with triage data to enhance prediction accuracy. Grahm et al. [19] emphasized the benefits of incorporating additional data types and advanced algorithms into ML models. Van Delft and Medeiros de Carvalho [20] investigated various algorithms for predicting patient disposition, including Random Forest, AutoML, Logistic Regression, Neural Networks, and Gradient Boosting Machine (GBM). Lastly, Cusidó et al. [21] focused on predicting hospital admissions to mitigate overcrowding using a GBM approach. These studies highlight the potential of machine learning, mainly RF and GBM, for enhancing ED workflows and resource allocation. The performance results of all studies [13,14,15,16,17,18,19,20,21] were compared and discussed with the results of our study in the discussion section.
3. Materials and Methods
3.1. Study Population and Setting
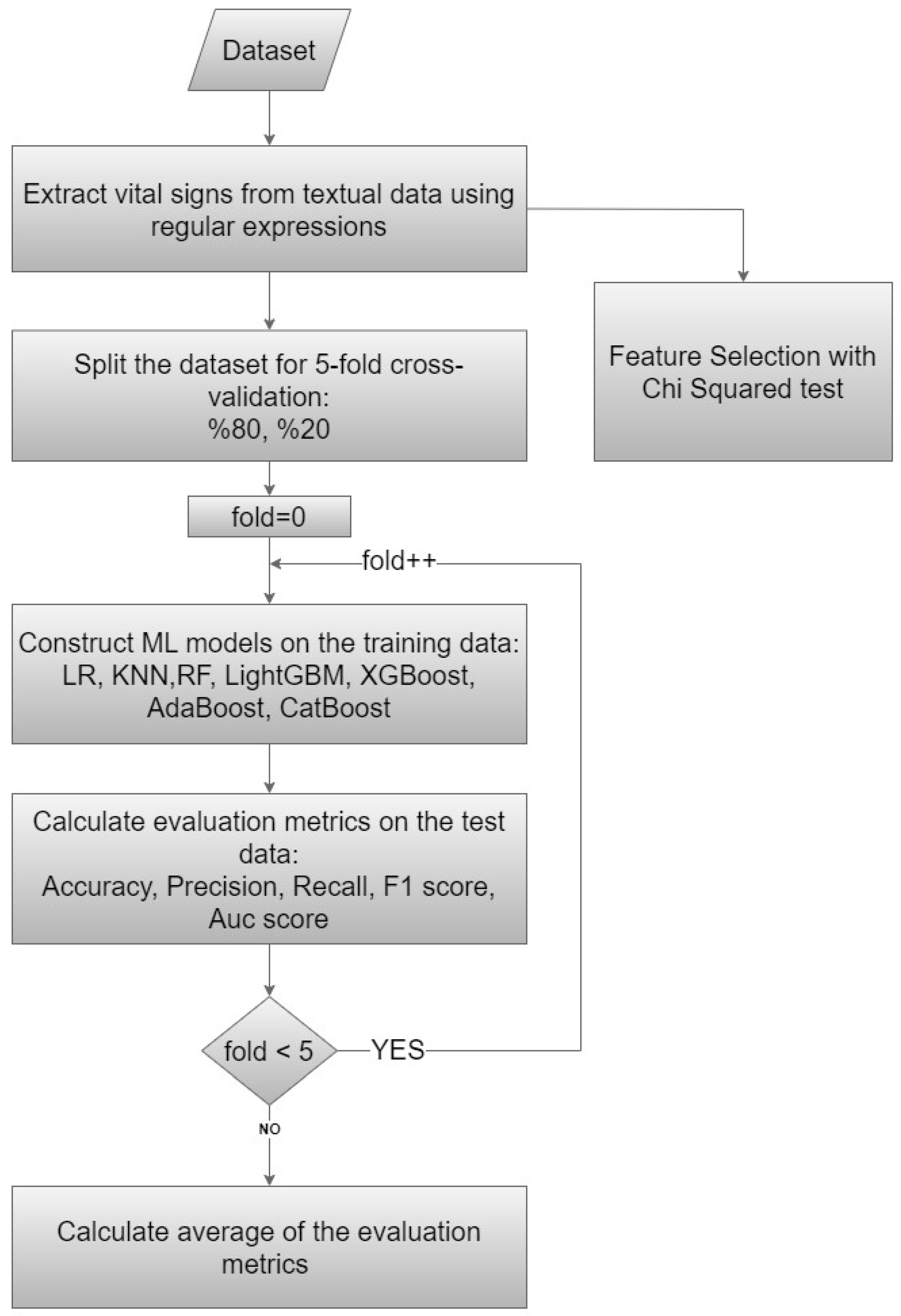
This study was based on cross-sectional data collected in the ED of a public hospital with a 400-bed capacity and serving approximately 250,000 patients a year. Odemis State Hospital is a district state hospital located approximately 120 km from the provincial center. The emergency department serves around 650–700 patients daily. The emergency department operates with 24-h shifts, and the team consists of one emergency specialist, four general practitioners, and other healthcare professionals. The study participants were adult patients (aged ≥ 18 years) who had visited the ED. A flowchart diagram of our proposed method is presented in Figure 1.
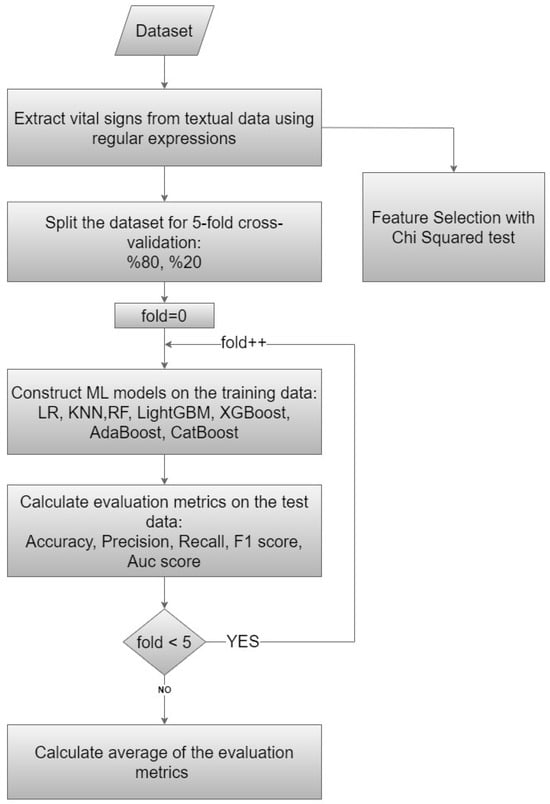
Figure 1.
Flowchart diagram of the proposed method.
3.2. Dataset Description
The dataset used in this study comprised patient records encompassing various clinical parameters and outcomes. The emergency outcomes recorded for the patients included mortality, referral, discharge.
Demographics: Gender, age. The dataset consisted of a total of 75,803 patients, of whom 36,618 were male (48.3%). The mean age was 52 (±24.94).
Laboratory results: Urea, creatine, sodium, potassium, AST, ALT, Troponin T, CK, Ck-Mb, CRP, prothrombin time, INR, WBC, RBC, HGB, HCT, PLT, MCV, MCH, MCHC, PDW, MPV, and PCT.
Emergency department parameters: The color codes determined by the Ministry of Health in our country classify patients into three levels: red (urgent emergency, life-saving intervention is required); yellow (urgent, high-risk, and unstable situation); and green (nonurgent, patient needs care) [22,23]. Duration of stay, mode, and type of arrival at the ED (Arrival Type: first examination and reapplication within 15 days; Arrival Mode: ambulance, non-ambulance). Four distinct outcome variables were considered (Table 1). Diagnosis groups, patient origin, trauma details, and consultation data were excluded from the modeling process due to insufficient information. In our initial dataset, which encompassed 29 features, we conducted the extraction of five distinct initial vital sign parameters (systolic and diastolic blood pressure, heart rate, oxygen saturation, and body temperature) from the textual data associated with the patient anamnesis file. The purpose of this augmentation was to enhance the dataset and facilitate the creation of more resilient ML models. Consequently, our dataset encompassed a total of 34 features utilized as input variables for our ML models.

Table 1.
Outcome classes, # of instances per class and the percentage of these instances.
3.3. Preprocessing
In the preprocessing section, we inputted the patient anamnesis file as textual data in our dataset. We also used the regular expression (regex) patterns to extract patterns that occur one or many times in any text. In our study, we applied regex as one of the preprocessing parts to identify specific patterns indicative of vital signs, including numerical values and associated units of measurement. Patterns were crafted to capture systolic–diastolic blood pressure, heart rate, oxygen saturation, and body temperature. By systematically applying regex patterns to the textual data, vital signs and clinical indicators were successfully extracted and transformed into structured features suitable for subsequent analysis. Regarding missing values in our dataset, we considered each feature’s normal range, averaging its lower and upper limits, and used the resulting value to impute the missing data.
3.4. Machine Learning Models
In this section, we present seven ML models employed to predict the aforementioned outcomes. The models utilized in this study included CatBoost, AdaBoost, XGBoost, LightGBM, Random Forest (RF), k-Nearest Neighbor (KNN), and Logistic Regression (LR), which are widely recognized classification methods. These techniques have been applied across various domains, including image classification [24], natural language processing [25], disease prediction [26], patient outcome modeling [27], and other fields.
We briefly explain each algorithm below. We used the scikit-learn [28] machine learning library in Python to employ seven classification methods.
3.4.1. K-Nearest Neighbor (KNN)
KNN is a simple yet effective algorithm for classification and regression tasks. It predicts based on the majority class or average value of the K nearest neighbors in the feature space. KNN can be computationally intensive, especially for large datasets and high-dimensional spaces due to the curse of dimensionality [29].
3.4.2. Adaptive Boosting (AdaBoost)
AdaBoost is an ensemble learning algorithm that combines multiple weak learners to create a strong learner. It iteratively trains weak models, adjusting misclassification weights to focus on challenging examples by assigning higher weights to misclassifications. Final predictions are made by a weighted majority vote [30].
3.4.3. Random Forest (RF)
RF is another ensemble learning algorithm based on decision trees, in which multiple trees are trained independently and their outputs are aggregated for predictions. Each tree is constructed using a random subset of features and instances, ensuring diversity. RF offers robustness against overfitting and noise in the data [31].
3.4.4. Extreme Gradient Boosting (XGBoost)
XGBoost is a fast and high-performing ensemble learning algorithm based on gradient-boosted decision trees. It integrates regularization to prevent overfitting and enhance generalization. XGBoost has become a popular choice in various ML competitions due to its exceptional predictive accuracy [32].
3.4.5. LightGBM
LightGBM is another gradient-boosting algorithm that prioritizes boosting examples with larger gradients. It uses innovative feature bundling to reduce training complexity, resulting in faster training and improved predictive performance. With support for diverse objective functions and evaluation metrics, LightGBM is versatile for various ML tasks [33].
3.4.6. Categorical Boosting (CatBoost)
CatBoost is also a gradient boosting algorithm with decision trees as base learners. It solves the problems of gradient bias and prediction shift in the standard gradient boosting algorithm by applying the ordering principle [34].
3.4.7. Logistic Regression
LR is a widely used linear classification algorithm. It estimates the probability of binary outcomes using a logistic or sigmoid function, making it efficient for binary classification tasks. LR can be extended to multiclass classification using techniques like one-vs-rest or softmax regression [35].
3.5. Feature Selection
The Chi-squared test for feature selection is particularly useful in identifying which features are most relevant or informative for determining the target class, thereby reducing dimensionality and improving the efficiency and interpretability of ML models. This test is a statistical method used to determine the association between variables. It is particularly useful for analyzing variables to see whether there is a significant relationship between them. By comparing observed and expected frequencies, it helps identify patterns within the dataset. Specifically, we examined the relationship between various clinical indicators, to uncover meaningful correlations to inform clinical decision-making and patient care strategies.
The Chi-squared feature selection method in Scikit-learn assesses the relationship between the target variable and categorical independent variables in classification tasks. It ranks features according to their relevance using the Chi-squared test. The null hypothesis in the Chi-squared test claims that the selected feature is independent of the target variable. The Chi-squared feature selection method, as implemented in Scikit-learn, utilizes a one-tailed statistical test. This is appropriate given the objective of determining whether observed values surpass expected values under the null hypothesis of independence, thereby providing evidence of a dependency.
3.6. The Proposed Model
The present study employed a comprehensive approach to analyzing patient data and predicting clinical outcomes using ML techniques and statistical methods. The proposed model encompassed data preprocessing, dataset splitting, model training, and evaluation (Figure 1). We meticulously executed these steps to ensure robustness and reliability in our analysis. We used data from 75,803 patients and 34 features for modeling with ML approaches and determining the exit pattern for each patient. For this purpose, firstly, efforts were made to increase the number of features by applying preprocessing steps of the data given as text in the raw dataset. The number of features, which was 29 in our initial dataset, was increased to 34 by extracting vital signs from the textual data. The purpose of this process was to obtain a more successful model by increasing the number of features.
In our study, we do not have an external validation dataset; thus, the dataset was divided into training and testing sets using a 5-fold cross-validation strategy. Each iteration involved splitting the dataset into training (20%) and testing (80%) sets to construct and evaluate ML models utilizing the aforementioned independent variables. Subsequently, the average of all validation results from these 5 steps was computed to obtain the final results. Cross-validation helps estimate model performance on unseen data and prevent overfitting. We utilized the default hyperparameters from the Scikit-learn library for our ML models.
The Chi-squared test, which is also accessible from the Scikit-learn library, was applied to determine which features were more important and more effective for our models. The Chi-squared approach ranked features according to their power to identify class labels on their own. We constructed our ML models using all features without eliminating any through the Chi-squared feature selection method. We used the feature selection method only to determine the importance of the features in the dataset.
4. Results
The well-known performance evaluation metrics, which are accuracy, precision, recall, F1 score, and AUC scores, were used in this study. The performance evaluation metrics assess the effectiveness of each classifier on datasets when test data is given separately for classifier-based ML-based models. Higher values of performance metrics indicate a more successful classification. Performance evaluation metrics utilized True Positive (TP), False Positive (FP), False Negative (FN), and True Negative (TN) outcomes in the classification task.
These metrics are calculated as follows:
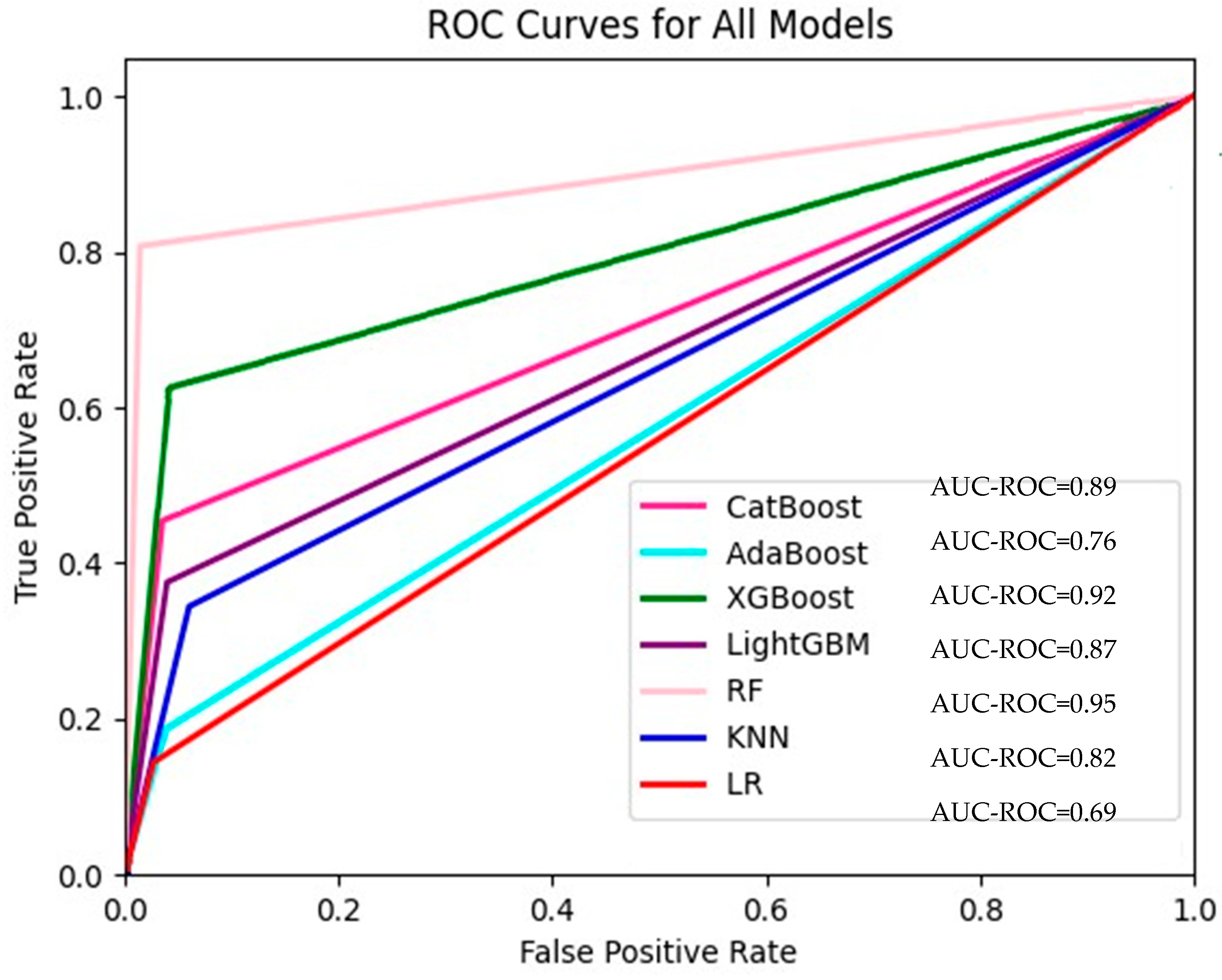
The accuracy, precision, recall, F1 score, and AUC scores of our models are shown in Table 2. The AUC values used in our study for the seven models are also presented in Figure 2. RF was the model with the best performance according to all evaluation benchmarks. Considering all these benchmarks, the XGBoost model ranked second and CatBoost ranked third. The KNN, LR, and AdaBoost models had similar results. Additionally, there were certain occasions when these models were superior to each other in different metrics. For instance, while the LR model performed better than the AdaBoost model in the evaluation made according to the accuracy (acc) benchmark, the Adaboost model performed better than LR when evaluated according to the F-score benchmark. Considering that both true positive results (cases in which patients who really need to be hospitalized are hospitalized) and false positive results (cases in which patients who do not need to be hospitalized are hospitalized) are important, the F1-score benchmark, which was evaluated following these cases, was significant. To present details about the performance of the ML models, we introduced confusion matrices for LR, CatBoost, AdaBoost, XGBoost, LightGBM, RF, and KNN models, which are also given in Supplementary Figures S1–S8, respectively, in the Supplementary File.
Table 2.
Performance metrics of the ML models.
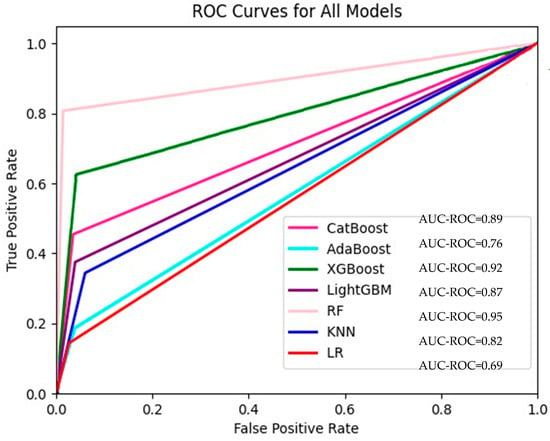
Figure 2.
ROC curves for all models.
The ranking in Table 3 presents the order in which the features determine the class label according to the Chi-squared method. The impact of class label determination, presented in Table 3, highlights the significance of each feature in contributing to the accurate determination of the class label. The variables PCT, prothrombin time, INR, and hospital arrival type in our models were not statistically significant. However, all of the other variables were statistically significant (Table 3).
Table 3.
P values of variables used in ML models.
We also included a training time graph (Supplementary Figure S1) in the Supplementary File to illustrate the computational time for each model. The results were obtained using a system with 16 GB RAM and a four-core CPU with support for 32 threads.
5. Discussion
Ongoing attempts are being made to improve and integrate clinical decision support systems that can present objective criteria for healthcare professionals. In the present study, we evaluated seven ML algorithms for predicting hospital emergency outcomes. The results revealed that RF, an ensemble-based algorithm, achieved the highest AUC score among the models tested. This suggests that RF’s ensemble learning approach might be particularly effective in capturing complex relationships within ED data. We also demonstrated that ML models could be developed to support decision-making processes in the ED. Specifically, utilizing 34 features, the RF model achieved an AUC of 0.958 in predicting four distinct outcomes in our dataset. Table 4 presents the comparison machine learning models for emergency department prediction.
Table 4.
Comparison of machine learning models for emergency department prediction.
Larburu et al. [13] found 14 out of 367 articles that met their criteria in their review of models used to identify patients hospitalized in the ED. Their paper stated that logistic regression was the most used prediction model and that it achieved an AUC value of 0.75–0.92. The AUC value we found for the LR in our study (0.694) aligns with these findings. The number of variables used in the studies included in this review varied between 6 and 21. We think that the 34 variables used in our study strengthens our findings. These papers evaluated the variables under six categories (demographic data, triage data, clinical and laboratory findings, medical history, medicine, and others). Since the medical history and medicine used could not be obtained from the records in our study, these variables were not included. Not being able to obtain medical history is a weakness of our study. AI models can contribute to increasing the quality of care in EDs and alleviate the burden on healthcare systems. In their study, conducted with 3204 ED patients, Feretzakis et al. [14] stated, considering the weighted mean values, that the RF performed slightly better than other models in terms of F-measure and ROC with values of 0.723 and 0.789, respectively. Additionally, they stated that the F-measure and ROC value intervals of all of the eight algorithms were respectively 0.663–0.723 and 0.731–0.789, and, as stated before, these can be deemed acceptable. Similarly, in our study, RF seemed to be the best modeling method. The higher values of F-measure and AUC scores in the models of our study might have been due to the number of patients included in the research and their distribution into groups. Our study justifies the current common opinion that AI can positively influence the future of emergency medicine. In their study, Kishore et al. [15] used six different ML algorithms (decision trees, support vector machines, RF, naive bias classifier, gradient boosting, and deep neural networks) for early prediction of hospital admissions of patients who were presented to the ED, and stated that the algorithms performed perfectly in predicting hospital admissions within the first 30 min. In their modeling study, conducted using ROC analysis, Parker et al. [16] analyzed 335K patients and utilized eight variables in the models. The area under the curve in the ROC curve was 0.825 (95% CI 0.824–0.827), which is deemed a good score. In our study, the area under the curve according to the ROC analyses was 0.842 after all the models were averaged, which complies with their study. Old age, increasing triage acuity, and arrival type through special patient transfer methods were the factors that best predicted the hospital admissions [16]. The hospital admission possibility of patients transferred by special patient transfer vehicles was higher than those who came in on foot, while those arriving by state ambulance was much lower. While age and increasing triage acuity were evaluated as good indicators in our study, the type of arrival was not deemed a good indicator. This might have been caused by regional differences [16]. In the study by Hond et al. [17], who used demographic characteristics, emergency, application complaints, severity of disease, and accompanying diseases as common variables, the models were evaluated at 30 min and 2 h after triage. The AUC values were RF 0.80 and XGBoost 0.84 in triage, and 0.86 and 0.86 at 30 min and 2 h, respectively. Although our study was not evaluated hourly, the highest AUC values were obtained from the RF and XGBoost models. It is stated in the study conducted by Hond et al. that time does not enhance the performance of the models. The study by Hond et al. showed that ML models had an excellent but similar predictive performance as the logistic regression model for predicting hospital admissions. On the other hand, our study showed that models can predict much better compared to LR. Using more variables might have led to that result. Hong et al. [18] reported AUC values of 0.87 for LR and XGBoost and 0.91 and 0.92 for all variables, respectively, in hospitalization modeling with triage variables. They found the XGBoost model to be better than LR in prediction performance, a finding that aligns with our study. It is seen in their study that adding previous information drastically improved the prediction performance compared to only using triage information. While variables such as ESI levels, outpatient treatment, demographic characteristics, and hospital usage statistics provided high-level information, variables such as age, gender, marital status, previous operation procedures, and hospital arrival type were deemed to provide less information. In our study, while variables such as age, gender, and triage score were statistically significant, hospital arrival type was not significant. This difference might have arisen from the generalization of the models used. Grahm et al. [19], in their study, in which they used LR, decision trees, and gradient-boosted machine models, stated that GBM had the best performance; however, decision tree and LR models only showed a slightly greater improvement; therefore, it revealed GBM as the potential candidate to apply three models. There are very important points to that study published in 2018 [18,19]. Firstly, the inclusion of additional data alongside triage data can improve accuracy; secondly, textual data can be incorporated into ML modeling; and, lastly, the use of ML algorithms can improve accuracy. All three of them were used in our study and were proved to be accurate by us [19]. Van Delft and Medeiros de Carvalho [20] explored RF, AutoML, LR, Neural Network, and GBM to support emergency department operations, focusing on predicting patient outcomes. They reported the best AUC score of 0.91 with the RF algorithm, which offers valuable support in predicting patient disposition in the ED. These findings are compatible with our study, in which RF also yielded the best performance, further supporting RF’s efficacy in predicting patient outcomes. Cusidó et al. [21] investigated using machine learning to predict hospital admissions and mitigate overcrowding in emergency departments. Employing a GBM algorithm on data from a comprehensive hospital’s emergency department, they achieved an AUC of 0.89. Similar to the findings in [19], this result suggests the potential of GBM for the effective prediction of hospital admissions, which may contribute to reducing ED overcrowding.
The theoretical contribution of this study lies in constructing an extensive dataset that incorporates 34 predictors, including two sociodemographic factors, 23 laboratory variables, five initial vital signs, and four emergency department-related variables to predict the outcomes of patients more precisely. In our study, to ensure robust and reliable predictions, a large number of features were obtained from the system, and modeling was performed using this multi-feature dataset. We aimed to enhance the uniqueness of our work by utilizing a more extensive set of features than those employed in previous research. This study also investigated the effects of 34 features for the prediction of outcomes by using the feature selection method.
Limitations
Firstly, we compared established ML models frequently applied in healthcare research that were considered suitable for our dataset dimensions. However, recent research has extended prediction models to the application of deep learning (DL) algorithms. To increase the performance of ML-based models for ED disposition, we plan to apply DL algorithms in future studies.
Secondly, this study did not include an independent dataset for external validation. Instead, five-fold cross-validation was applied for internal validation, the efficiency of which has been reported to be similar to that of independent external validation.
The utilization of diverse imputation techniques for missing data potentially resulted in improvements in the predictive performance of emergency admission. Therefore, future research could incorporate imputation strategies to further refine the predictive accuracy of the ML models.
This study also includes the limitations of retrospective file review studies, the use of triple triage classification, the discharge practice decided by the emergency physician alone, and the fact that respiratory rate parameters could not be evaluated among vital signs.
AI-based systems created to make decisions alone may cause legal and ethical problems. The aim of such AI-based systems is to help experts in the field and enable them to make more accurate decisions. In the future, it is thought that AI-based prediction models will take more responsibility in the decision-making process, particularly after the establishment of legal regulations.
6. Conclusions
Among the seven machine learning models compared for predicting the outcomes of emergency department patients, it was observed that the Random Forest (RF) model was significantly more reliable in predicting clinical outcomes, followed by the XGBoost and CatBoost models. Based on these results, it is anticipated that integrating these models into clinical decision support systems could help create applications that assist decision-making processes in emergency departments. The main limitation of this study is the necessity for medical doctors to evaluate the ML-based predictions generated by AI systems. In future work, we aim to enhance ML-based predictions by employing deep learning algorithms to develop more robust models.
Supplementary Materials
The following supporting information can be downloaded at: https://www.mdpi.com/article/10.3390/app15031628/s1, Figure S1. Training times of machine learning models; Figure S2. Confusion matrix of LR based model; Figure S3. Confusion matrix of CatBoost based model; Figure S4. Confusion matrix of AdaBoost based model; Figure S5. Confusion matrix of XGBoost based model; Figure S6. Confusion matrix of LightGBM based model; Figure S7. Confusion matrix of RF based model; Figure S8. Confusion matrix of KNN based model; Table S1. Ranking of features and Chi-Square values Chi-Square values when class label is “mortality”; Table S2. Ranking of features and Chi-Square values Chi-Square values when class label is “referral”; Table S3. Ranking of features and Chi-Square values Chi-Square values when class label is “discharge”; Table S4. Ranking of features and Chi-Square values Chi-Square values when class label is “hospitalization”.
Author Contributions
S.S.—designed the study, wrote the original draft, and analyzed the data. M.Ö.C.—designed the study, analyzed the data, reviewed, and edited. E.İ.—designed the study, analyzed the data, reviewed, and edited. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
This study was approved, and the need to acquire informed consent from individual patients was waived by the ethics committee of Izmir Katip Celebi University’s Non-Interventional Clinical Studies Institutional Review Board (#0423, 21 September 2023).
Informed Consent Statement
Not applicable.
Data Availability Statement
The original contributions presented in this study are included in the article. Further inquiries can be directed to the corresponding author.
Acknowledgments
The numerical calculations reported in this paper were fully performed at Bursa Technical University High Performance Computing Lab.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- National Center for Health Statistics (US). Health, United States, 2012: With Special Feature on Emergency Care; Report No.: 2013-1232; National Center for Health Statistics (US): Hyattsville, MD, USA, 2013. [Google Scholar]
- Morley, C.; Unwin, M.; Peterson, G.M.; Stankovich, J.; Kinsman, L. Emergency department crowding: A systematic review of causes, consequences and solutions. PLoS ONE 2018, 13, e0203316. [Google Scholar] [CrossRef]
- Sun, B.C.; Hsia, R.Y.; Weiss, R.E.; Zingmond, D.; Liang, L.J.; Han, W.; McCreath, H.; Asch, S.M. Effect of emergency department crowding on outcomes of admitted patients. Ann. Emerg. Med. 2013, 61, 605–611.e6. [Google Scholar] [CrossRef]
- Greenwald, P.W.; Estevez, R.M.; Clark, S.; Stern, M.E.; Rosen, T.; Flomenbaum, N. The ED as the primary source of hospital admission for older (but not younger) adults. Am. J. Emerg. Med. 2016, 34, 943–947. [Google Scholar] [CrossRef]
- Shafaf, N.; Malek, H. Applications of Machine Learning Approaches in Emergency Medi-cine; a Review Article. Arch. Acad. Emerg. Med. 2019, 7, 34. [Google Scholar] [PubMed]
- Kelly, A.M.; Bryant, M.; Cox, L.; Jolley, D. Improving emergency department efficiency by patient streaming to outcomes-based teams. Aust. Health Rev. 2007, 31, 16–21. [Google Scholar] [CrossRef]
- King, D.L.; Ben-Tovim, D.I.; Bassham, J. Redesigning emergency department patient flows: Application of Lean Thinking to health care. Emerg. Med. Australas. 2006, 18, 391–397. [Google Scholar] [CrossRef] [PubMed]
- Weissman, G.E.; Crane-Droesch, A.; Chivers, C.; Luong, T.; Hanish, A.; Levy, M.Z.; Lubken, J.; Becker, M.; Draugelis, M.E.; Anesi, G.L.; et al. Locally Informed Simulation to Predict Hospital Capacity Needs During the COVID-19 Pandemic. Ann. Intern. Med. 2020, 173, 21–28. [Google Scholar] [CrossRef]
- Petrella, R.J. The AI Future of Emergency Medicine. Ann. Emerg. Med. 2024, 84, 139–153. [Google Scholar] [CrossRef] [PubMed]
- Shaban-Nejad, A.; Michalowski, M.; Buckeridge, D.L. Health intelligence: How artificial intelligence transforms population and personalized health. npj Digit. Med. 2018, 1, 53. [Google Scholar] [CrossRef]
- Xie, F.; Zhou, J.; Lee, J.W.; Tan, M.; Li, S.; Rajnthern, L.S.O.; Chee, M.L.; Chakraborty, B.; Wong, A.K.I.; Dagan, A.; et al. Benchmarking emergency department prediction models with machine learning and public electronic health records. Sci. Data 2022, 9, 658. [Google Scholar] [CrossRef]
- Feretzakis, G.; Sakagianni, A.; Loupelis, E.; Karlis, G.; Kalles, D.; Tzelves, L.; Chatzikyriakou, R.; Trakas, N.; Petropoulou, S.; Tika, A.; et al. Predicting Hospital Admission for Emergency Department Patients: A Machine Learning Approach. In Informatics and Technology in Clinical Care and Public Health; Studies in Health Technology and Informatics Volume 289; IOS Press: Amsterdam, The Netherlands, 2022; pp. 297–300. [Google Scholar]
- Larburu, N.; Azkue, L.; Kerexeta, J. Predicting Hospital Ward Admission from the Emergency Department: A Systematic Review. J. Pers. Med. 2023, 13, 849. [Google Scholar] [CrossRef] [PubMed]
- Feretzakis, G.; Karlis, G.; Loupelis, E.; Kalles, D.; Chatzikyriakou, R.; Trakas, N.; Karakou, E.; Sakagianni, A.; Tzelves, L.; Petropoulou, S.; et al. Using Machine Learning Techniques to Predict Hospital Admission at the Emergency Department. J. Crit. Care Med. 2022, 8, 107–116. [Google Scholar] [CrossRef] [PubMed]
- Kishore, K.; Braitberg, G.; Holmes, N.E.; Bellomo, R. Early prediction of hospital admission of emergency department patients. Emerg. Med. Australas. 2023, 35, 572–588. [Google Scholar] [CrossRef]
- Parker, C.A.; Liu, N.; Wu, S.X.; Shen, Y.; Lam, S.S.W.; Ong, M.E.H. Predicting hospital admission at the emergency department triage: A novel prediction model. Am. J. Emerg. Med. 2019, 37, 1498–1504. [Google Scholar] [CrossRef]
- De Hond, A.; Raven, W.; Schinkelshoek, L.; Gaakeer, M.; Ter Avest, E.; Sir, O.; Lameijer, H.; Hessels, R.A.; Reijnen, R.; De Jonge, E.; et al. Machine learning for developing a prediction model of hospital admission of emergency department patients: Hype or hope? Int. J. Med. Inform. 2021, 152, 104496. [Google Scholar] [CrossRef]
- Hong, W.S.; Haimovich, A.D.; Taylor, R.A. Predicting hospital admission at emergency department triage using machine learning. PLoS ONE 2018, 13, e0201016. [Google Scholar] [CrossRef]
- Graham, B.; Bond, R.; Quinn, M.; Mulvenna, M. Using Data Mining to Predict Hospital Admissions From the Emergency Department. IEEE Access 2018, 6, 10458–10469. [Google Scholar] [CrossRef]
- van Delft, R.A.; de Carvalho, R.M. Using Machine Learning Techniques to Support the Emergency Department. Comput. Inform. 2022, 41, 154–171. [Google Scholar] [CrossRef]
- Cusidó, J.; Comalrena, J.; Alavi, H.; Llunas, L. Predicting hospital admissions to reduce crowding in the emergency departments. Appl. Sci. 2022, 12, 10764. [Google Scholar] [CrossRef]
- Ministry of Health of the Republic of Turkey. Yataklı Sağlık Tesislerinde Acil Servis Hizmetlerinin Uygulama Usul Ve Esasları Hakkında Tebliğ. Available online: https://www.saglik.gov.tr/TR,11321/yatakli-saglik-tesislerinde-acil-servis-hizmetlerinin-uygulama-usul-ve-esaslari-hakkinda-teblig.html (accessed on 13 September 2022).
- Bora, Ş.; Kantarcı, A.; Erdoğan, A.; Beynek, B.; Kheibari, B.; Evren, V.; Erdoğan, M.A.; Kavak, F.; Afyoncu, F.; Eryaz, C.; et al. Machine learning for E-triage. Int. J. Multidiscip. Stud. Innov. Technol. 2022, 6, 86–90. [Google Scholar] [CrossRef]
- Wang, P.; Fan, E.; Wang, P. Comparative analysis of image classification algorithms based on traditional machine learning and deep learning. Pattern Recognit. Lett. 2021, 141, 61–67. [Google Scholar] [CrossRef]
- Sharifani, K.; Amini, M.; Akbari, Y.; Aghajanzadeh Godarzi, J. Operating machine learning across natural language processing techniques for improvement of fabricated news model. Int. J. Sci. Inf. Syst. Res. 2022, 12, 20–44. [Google Scholar]
- Ogunpola, A.; Saeed, F.; Basurra, S.; Albarrak, A.M.; Qasem, S.N. Machine learning-based predictive models for detection of cardiovascular diseases. Diagnostics 2024, 14, 144. [Google Scholar] [CrossRef]
- Adams, R.; Henry, K.E.; Sridharan, A.; Soleimani, H.; Zhan, A.; Rawat, N.; Johnson, L.; Hager, D.N.; Cosgrove, S.E.; Markowski, A.; et al. Prospective, multi-site study of patient outcomes after implementation of the TREWS machine learning-based early warning system for sepsis. Nat. Med. 2022, 28, 1455–1460. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Zhou, X.; Wang, H.; Xu, C.; Peng, L.; Xu, F.; Lian, L.; Deng, G.; Ji, S.; Hu, M.; Zhu, H.; et al. Application of kNN and SVM to predict the prognosis of advanced sChistosomiasis. Parasitol. Res. 2022, 121, 2457–2460. [Google Scholar] [CrossRef]
- Ho, J.C.; Sotoodeh, M.; Zhang, W.; Simpson, R.L.; Hertzberg, V.S. An AdaBoost-based algorithm to detect hospital-acquired pressure injury in the presence of conflicting annotations. Comput. Biol. Med. 2024, 168, 107754. [Google Scholar] [CrossRef]
- Elhaj, H.; Achour, N.; Tania, M.H.; Aciksari, K. A comparative study of supervised machine learning approaches to predict patient triage outcomes in hospital emergency departments. Array 2023, 17, 100281. [Google Scholar] [CrossRef]
- Jiang, H.; Mao, H.; Lu, H.; Lin, P.; Garry, W.; Lu, H.; Yang, G.; Rainer, T.H.; Chen, X. Machine learning-based models to support decision-making in emergency department triage for patients with suspected cardiovascular disease. Int. J. Med. Inform. 2021, 145, 104326. [Google Scholar] [CrossRef] [PubMed]
- Li, C.; Zhang, Z.; Ren, Y.; Nie, H.; Lei, Y.; Qiu, H.; Xu, Z.; Pu, X. Machine learning based early mortality prediction in the emergency department. Int. J. Med. Inform. 2021, 155, 104570. [Google Scholar] [CrossRef]
- Chang, Y.H.; Shih, H.M.; Wu, J.E.; Huang, F.W.; Chen, W.K.; Chen, D.M.; Chung, Y.T.; Wang, C.C. Machine learning–based triage to identify low-severity patients with a short discharge length of stay in emergency department. BMC Emerg. Med. 2022, 22, 88. [Google Scholar] [CrossRef] [PubMed]
- Zabor, E.C.; Reddy, C.A.; Tendulkar, R.D.; Patil, S. Logistic regression in clinical studies. Int. J. Radiat. Oncol. *Biol.* Phys. 2022, 112, 271–277. [Google Scholar] [CrossRef] [PubMed]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).