

Revisiting Schistosoma mansoni Micro-Exon Gene (MEG) Protein Family: A Tour into Conserved Motifs and Annotation

 , ,
, ,  and
and
Abstract
:1. Introduction
2. Materials and Methods
3. Results and Discussion
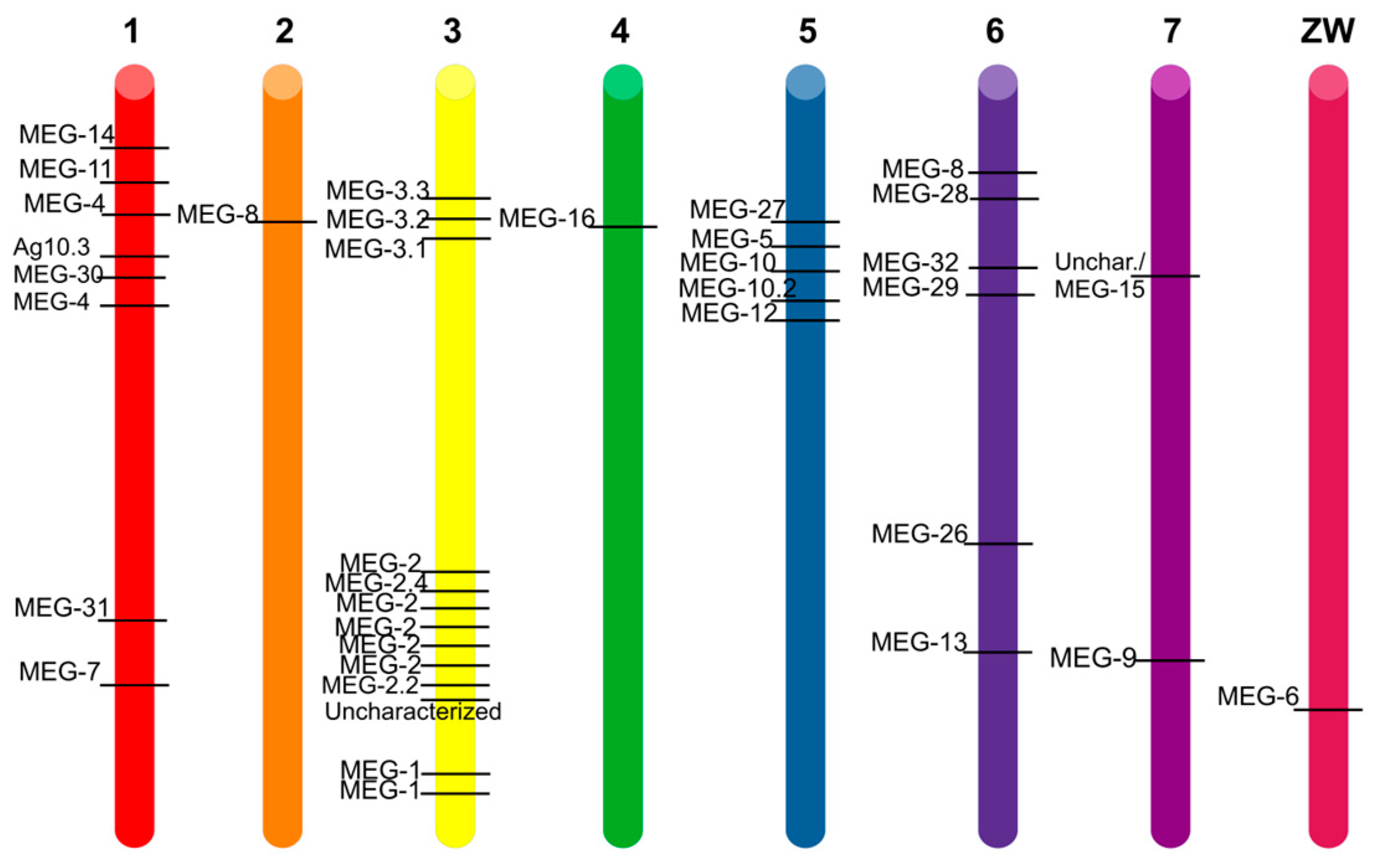
3.1. MEG Filiation
3.2. Conserved Motifs
3.3. Nomenclature
3.4. Towards a Function?
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Lander, E.S.; Linton, L.M.; Birren, B.; Nusbaum, C. Initial sequencing and analysis of the human genome. Nature 2001, 409, 860–921. [Google Scholar] [CrossRef]
- Venter, J.C.; Adams, M.D.; Myers, E.W.; Li, P.W.; Mural, R.J.; Sutton, G.G.; Smith, H.O.; Yandell, M.; Evans, C.A.; Holt, R.A.; et al. The Sequence of the Human Genome. Science 2001, 291, 1304–1351. [Google Scholar] [CrossRef] [PubMed]
- Alliance of Genome Resources Consortium; Agapite, J.; Albou, L.-P.; A Aleksander, S.; Alexander, M.; Anagnostopoulos, A.V.; Antonazzo, G.; Argasinska, J.; Arnaboldi, V.; Attrill, H.; et al. Harmonizing model organism data in the Alliance of Genome Resources. GENETICS 2022, 220, iyac022. [Google Scholar] [CrossRef]
- Zerlotini, A.; Oliveira, G. The contributions of the Genome Project to the study of schistosomiasis. Mem. Inst. Oswaldo Cruz 2010, 105, 367–369. [Google Scholar] [CrossRef]
- Berriman, M.; Haas, B.J.; LoVerde, P.T.; Wilson, R.A.; Dillon, G.P.; Cerqueira, G.C.; Mashiyama, S.T.; Al-Lazikani, B.; Andrade, L.F.; Ashton, P.D.; et al. The genome of the blood fluke Schistosoma mansoni. Nature 2009, 460, 352–358. [Google Scholar] [CrossRef]
- Silva, L.L.; Marcet-Houben, M.; Nahum, L.A.; Zerlotini, A.; Gabaldón, T.; Oliveira, G. The Schistosoma mansoni phylome: Using evolutionary genomics to gain insight into a parasite’s biology. BMC Genom. 2012, 13, 617. [Google Scholar] [CrossRef]
- Philippsen, G.S. Transposable Elements in the Genome of Human Parasite Schistosoma mansoni: A Review. Trop. Med. Infect. Dis. 2021, 6, 126. [Google Scholar] [CrossRef]
- Venancio, T.M.; Wilson, R.A.; Verjovski-Almeida, S.; DeMarco, R. Bursts of transposition from non-long terminal repeat retrotransposon families of the RTE clade in Schistosoma mansoni. Int. J. Parasitol. 2010, 40, 743–749. [Google Scholar] [CrossRef] [PubMed]
- Hull, R.; Dlamini, Z. The role played by alternative splicing in antigenic variability in human endo-parasites. Parasites Vectors 2014, 7, 53. [Google Scholar] [CrossRef]
- Davis, R.E.; Davis, A.H.; Carroll, S.M.; Rajkovic, A.; Rottman, F.M. Tandemly Repeated Exons Encode 81-Base Repeats in Multiple, Developmentally Regulated Schistosoma mansoni Transcripts. Mol. Cell. Biol. 1988, 8, 4745–4755. [Google Scholar] [CrossRef] [PubMed]
- DeMarco, R.; Mathieson, W.; Manuel, S.J.; Dillon, G.P.; Curwen, R.S.; Ashton, P.D.; Ivens, A.C.; Berriman, M.; Verjovski-Almeida, S.; Wilson, R.A. Protein variation in blood-dwelling schistosome worms generated by differential splicing of micro-exon gene transcripts. Genome Res. 2010, 20, 1112–1121. [Google Scholar] [CrossRef]
- Howe, K.L.; Bolt, B.J.; Shafie, M.; Kersey, P.; Berriman, M. WormBase ParaSite—A comprehensive resource for helminth genomics. Mol. Biochem. Parasitol. 2017, 215, 2–10. [Google Scholar] [CrossRef]
- Wilson, R.A.; Li, X.H.; MacDonald, S.; Neves, L.X.; Vitoriano-Souza, J.; Leite, L.C.C.; Farias, L.P.; James, S.; Ashton, P.D.; DeMarco, R.; et al. The Schistosome Esophagus Is a ‘Hotspot’ for Microexon and Lysosomal Hydrolase Gene Expression: Implications for Blood Processing. PLoS Neglected Trop. Dis. 2015, 9, e0004272. [Google Scholar] [CrossRef] [PubMed]
- Anderson, L.; Amaral, M.S.; Beckedorff, F.; Silva, L.F.; Dazzani, B.; Oliveira, K.C.; Almeida, G.T.; Gomes, M.R.; Pires, D.S.; Setubal, J.C.; et al. Schistosoma mansoni Egg, Adult Male and Female Comparative Gene Expression Analysis and Identification of Novel Genes by RNA-Seq. PLoS Neglected Trop. Dis. 2015, 9, e0004334. [Google Scholar] [CrossRef]
- Li, X.H.; de Castro-Borges, W.; Parker-Manuel, S.; Vance, G.M.; Demarco, R.; Neves, L.X.; Evans, G.J.; Wilson, R.A. The schistosome oesophageal gland: Initiator of blood processing. PLoS Neglected Trop. Dis. 2013, 7, e2337. [Google Scholar] [CrossRef]
- Lu, Z.; Sankaranarayanan, G.; Rawlinson, K.A.; Offord, V.; Brindley, P.J.; Berriman, M.; Rinaldi, G. The Transcriptome of Schistosoma mansoni Developing Eggs Reveals Key Mediators in Pathogenesis and Life Cycle Propagation. Front. Trop. Dis. 2021, 2, 713123. [Google Scholar] [CrossRef] [PubMed]
- The UniProt Consortium; Bateman, A.; Martin, M.-J.; Orchard, S.; Magrane, M.; Ahmad, S.; Alpi, E.; Bowler-Barnett, E.H.; Britto, R.; Bye-A-Jee, H.; et al. UniProt: The Universal Protein Knowledgebase in 2023. Nucleic Acids Res. 2023, 51, D523–D531. [Google Scholar] [CrossRef]
- Altschul, S.F.; Madden, T.L.; Schäffer, A.A.; Zhang, J.; Zhang, Z.; Miller, W.; Lipman, D.J. Gapped BLAST and PSI-BLAST: A new generation of protein database search programs. Nucleic Acids Res. 1997, 25, 3389–3402. [Google Scholar] [CrossRef]
- Notredame, C.; Higgins, D.G.; Heringa, J. T-coffee: A novel method for fast and accurate multiple sequence alignment. J. Mol. Biol. 2000, 302, 205–217. [Google Scholar] [CrossRef]
- Lassmann, T.; Sonnhammer, E.L.L. Kalign, Kalignvu and Mumsa: Web servers for multiple sequence alignment. Nucleic Acids Res. 2006, 34, W596–W599. [Google Scholar] [CrossRef]
- Edgar, R.C. MUSCLE: Multiple sequence alignment with high accuracy and high throughput. Nucleic Acids Res. 2004, 32, 1792–1797. [Google Scholar] [CrossRef]
- Madeira, F.; Pearce, M.; Tivey, A.R.N.; Basutkar, P.; Lee, J.; Edbali, O.; Madhusoodanan, N.; Kolesnikov, A.; Lopez, R. Search and sequence analysis tools services from EMBL-EBI in 2022. Nucleic Acids Res. 2022, 50, W276–W279. [Google Scholar] [CrossRef] [PubMed]
- Saitou, N.; Nei, M. The neighbor-joining method: A new method for reconstructing evolutionary trees. Mol. Biol. Evol. 1987, 4, 406–425. [Google Scholar] [CrossRef] [PubMed]
- Löytynoja, A.; Goldman, N. Phylogeny-Aware Gap Placement Prevents Errors in Sequence Alignment and Evolutionary Analysis. Science 2008, 320, 1632–1635. [Google Scholar] [CrossRef] [PubMed]
- Letunic, I.; Bork, P. Interactive Tree of Life (iTOL) v5: An online tool for phylogenetic tree display and annotation. Nucleic Acids Res. 2021, 49, W293–W296. [Google Scholar] [CrossRef]
- Crooks, G.E.; Hon, G.; Chandonia, J.-M.; Brenner, S.E. WebLogo: A Sequence Logo Generator. Genome Res. 2004, 14, 1188–1190. [Google Scholar] [CrossRef]
- Gasteiger, E.; Hoogland, C.; Gattiker, A.; Duvaud, S.; Wilkins, M.R.; Appel, R.D.; Bairoch, A. Protein Identification and Analysis Tools on the Expasy Server. In the Proteomics Protocols Handbook; Walker, J.M., Ed.; Humana Press: Totowa, NJ, USA, 2005; pp. 571–607. [Google Scholar]
- Duvaud, S.; Gabella, C.; Lisacek, F.; Stockinger, H.; Ioannidis, V.; Durinx, C. Expasy, the Swiss Bioinformatics Resource Portal, as designed by its users. Nucleic Acids Res. 2021, 49, W216–W227. [Google Scholar] [CrossRef]
- Philippsen, G.S.; Wilson, R.A.; DeMarco, R. Accelerated evolution of schistosome genes coding for proteins located at the host-parasite interface. Genome Biol. Evol. 2015, 7, 431–443. [Google Scholar] [CrossRef]
- Mathieson, W.; Wilson, R.A. A comparative proteomic study of the undeveloped and developed Schistosoma mansoni egg and its contents: The miracidium, hatch fluid and secretions. Int. J. Parasitol. 2010, 40, 617–628. [Google Scholar] [CrossRef]
- Fneich, S.; Théron, A.; Cosseau, C.; Rognon, A.; Aliaga, B.; Buard, J.; Duval, D.; Arancibia, N.; Boissier, J.; Roquis, D.; et al. Epigenetic origin of adaptive phenotypic variants in the human blood fluke Schistosoma mansoni. Epigenetics Chromatin 2016, 9, 27. [Google Scholar] [CrossRef]
- Vlaminck, J.; Lagatie, O.; Dana, D.; Mekonnen, Z.; Geldhof, P.; Levecke, B.; Stuyver, L.J. Identification of antigenic linear peptides in the soil-transmitted helminth and Schistosoma mansoni proteome. PLoS Neglected Trop. Dis. 2021, 15, e0009369. [Google Scholar] [CrossRef]
- Mambelli, F.S.; Figueiredo, B.; Morais, S.; Assis, N.; Fonseca, C.; Oliveira, S. Recombinant micro-exon gene 3 (MEG-3) antigens from Schistosoma mansoni failed to induce protection against infection but show potential for serological diagnosis. Acta Trop. 2020, 204, 105356. [Google Scholar] [CrossRef] [PubMed]
- Lopes, J.L.S.; Orcia, D.; Araujo, A.P.U.; DeMarco, R.; Wallace, B.A. Folding Factors and Partners for the Intrinsically Disordered Protein Micro-Exon Gene 14 (MEG-14). Biophys. J. 2013, 104, 2512–2520. [Google Scholar] [CrossRef] [PubMed]
- Orcia, D.; Zeraik, A.E.; Lopes, J.L.; Macedo, J.N.; dos Santos, C.R.; Oliveira, K.C.; Anderson, L.; Wallace, B.; Verjovski-Almeida, S.; Araujo, A.P.; et al. Interaction of an esophageal MEG protein from schistosomes with a human S100 protein involved in inflammatory response. Biochim. Biophys Acta. Gen. Subj. 2017, 1861, 3490–3497. [Google Scholar] [CrossRef] [PubMed]
- Martins, V.P.; Morais, S.B.; Pinheiro, C.S.; Assis, N.R.G.; Figueiredo, B.C.P.; Ricci, N.D.; Alves-Silva, J.; Caliari, M.V.; Oliveira, S.C. Sm10.3, a Member of the Micro-Exon Gene 4 (MEG-4) Family, Induces Erythrocyte Agglutination In Vitro and Partially Protects Vaccinated Mice against Schistosoma mansoni Infection. PLoS Neglected Trop. Dis. 2014, 8, e2750. [Google Scholar] [CrossRef]
- Felizatti, A.P.; Zeraik, A.E.; Basso, L.G.; Kumagai, P.S.; Lopes, J.L.; Wallace, B.; Araujo, A.P.; DeMarco, R. Interactions of amphipathic α-helical MEG proteins from Schistosoma mansoni with membranes. Biochim. Biophys Acta Biomembr. 2020, 1862, 183173. [Google Scholar] [CrossRef]
- Nedvedova, S.; Guillière, F.; Miele, A.E.; Cantrelle, F.-X.; Dvorak, J.; Walker, O.; Hologne, M. Divide, conquer and reconstruct: How to solve the 3D structure of recalcitrant Micro-Exon Gene (MEG) protein from Schistosoma mansoni. PLoS ONE 2023, 18, e0289444. [Google Scholar] [CrossRef]
- Romero, A.A.; Cobb, S.A.; Collins, J.N.R.; Kliewer, S.A.; Mangelsdorf, D.J.; Collins, J.J., 3rd. The Schistosoma mansoni nuclear receptor FTZ-F1 maintains esophageal gland function via transcriptional regulation of meg-8.3. PLoS Pathog. 2021, 17, e1010140. [Google Scholar] [CrossRef]
- Farias, L.P.; Vance, G.M.; Coulson, P.S.; Vitoriano-Souza, J.; Neto, A.P.d.S.; Wangwiwatsin, A.; Neves, L.X.; Castro-Borges, W.; McNicholas, S.; Wilson, K.S.; et al. Epitope Mapping of Exposed Tegument and Alimentary Tract Proteins Identifies Putative Antigenic Targets of the Attenuated Schistosome Vaccine. Front. Immunol. 2021, 11, 624613. [Google Scholar] [CrossRef]
- Soares, J.B.C.; Maya-Monteiro, C.M.; Bittencourt-Cunha, P.R.; Atella, G.C.; Lara, F.A.; D’avila, J.C.; Menezes, D.; Vannier-Santos, M.A.; Oliveira, P.L.; Egan, T.J.; et al. Extracellular lipid droplets promote hemozoin crystallization in the gut of the blood fluke Schistosoma mansoni. FEBS Lett. 2007, 581, 1742–1750. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| MEG-2 Coding Genes from 5′ to 3′ in the Second Half of Chromosome 3 | |||||||
|---|---|---|---|---|---|---|---|
| WBPS gene identifier | Smp_1598030.1 | Smp_159800.1 | Smp_183010.1 | Smp_183030.1 | Smp_183020.1 and Smp_183020.2 | Smp_345100.1 | Smp_336990 |
| UniProt ID | A0A3Q0KR24 | C4QG05 and D7PD69 | C4QPR6 | C4QPR9 | C4QPR8 and A0A3Q0KTV3 | A0A5K4FFX0 and D7PD77 | A0A5K4FDB9 D7DP78 D7DP76 D7DP75 |
| WBPS Gene ID | UniProt ID | Old Name | New Name |
|---|---|---|---|
| Smp_183040.1 | C4QPS0 | MEG-2/ESP15 | MEG-2 |
| Smp_1598030.1 | A0A3Q0KR24 | MEG-2/ESP15 | MEG-2.1 |
| Smp_159800.1 | C4QG05 | MEG-2/ESP15 | MEG-2.2 isoform 1 |
| D7PD69 | MEG-2.4 isoform 1 | MEG-2.2 isoform 2 | |
| Smp_183010.1 | C4QPR6 | MEG-2/ESP15 | MEG-2.3 |
| Smp_183030.1 | C4QPR9 | MEG-2/ESP15 | MEG-2.4 |
| Smp_183020.1 | C4QPR8 | MEG-2 isoform 1 | MEG-2.5 isoform 1 |
| Smp_183020.2 | A0A3Q0KTV3 | MEG-2 isoform 2 | MEG-2.5 isoform 2 |
| Smp_345100.1 | A0A5K4FFX0 | MEG-2.2 isoform 1 | MEG-2.6 isoform 1 |
| D7PD77 | MEG-2.2 isoform 2 | MEG-2.6 isoform 2 | |
| Smp_336990 | A0A5K4FDB9 | Uncharacterized | MEG-2.7 isoform 1 |
| D7DP78 | MEG-2.1 isoform 1 | MEG-2.7 isoform 2 | |
| D7DP76 | MEG-2.1 isoform 2 | MEG-2.7 isoform 3 | |
| D7DP75 | MEG-2.1 isoform 3 | MEG-2.7 isoform 4 | |
| Smp_307220.1 | A0A5K4F627 | Developmentally regulated antigen 10.3 | MEG-4.1 isoform 1 |
| Smp_307220.2 | A0A5K4F2K5 | Developmentally regulated antigen 10.3 | MEG-4.1 isoform 2 |
| Smp_307220.3 | Q86D79 | Developmentally regulated antigen 10.3 | MEG-4.1 isoform 3 |
| Smp_307240.1 | A0A5K4F4B1 | MEG-4/antigen 10.3 | MEG-4.2 |
| Smp_085840 | C4KE8 | MEG-4/antigen 10.3 | MEG-17 |
| Smp_172180.1 | G4VLP3 | MEG-8 | MEG-8 |
| Smp_171190.1 | G4VCW5 | MEG-8 | MEG-18 |
| Smp_152590.1 | A0A3Q0KQ39 | MEG-10 isoform 2 | MEG-10.1 isoform 1 |
| Smp_152590.2 | G4LYD0 | MEG-10 isoform 2 | MEG-10.1 isoform 2 |
| Smp_243730.1 | A0A0U5KJN7 | MEG-10.2 | MEG-10.2 |
| WBPS Gene ID | UniProt ID | Old Name | New Name |
|---|---|---|---|
| Smp_138060.1 | D7PD62 | MEG-3.3 isoform 1 | |
| D7PD63 | MEG-3.3 isoform 2 | ||
| D7PD64 | MEG-3.3 isoform 3 | ||
| A0A3Q0KMS0 | MEG-3 Grail family | MEG-3.3 isoform 4 | |
| Smp_138070.1 | D7PD52 | MEG-3.2 isoform 2.1 | MEG-3.2 isoform 1 |
| D7PD53 | MEG-3.2 isoform 2 | ||
| D7PD54 | MEG-3.2 isoform 3 | ||
| D7PD57 | MEG-3.2 isoform 6 | MEG-3.2 isoform 4 | |
| D7PD60 | MEG-3.2 isoform 9 | MEG-3.2 isoform 5 | |
| Smp_138080.1 | D7PD49 | MEG-3.1 isoform 1 | |
| D7PD51 | MEG-3.1 isoform 3 | MEG-3.1 isoform 2 | |
| A0A3Q0KMU6 | MEG-3 Grail family | MEG-3.1 isoform 3 | |
| WBPS Gene ID | UniProt ID | Old Name | New Name |
|---|---|---|---|
| Smp_010550.1 | A0A3Q0KC91 | Uncharacterized protein | MEG-15 isoform 1 |
| Smp_010550.2 | A0A5K4E9M7 | Uncharacterized protein | MEG-15 isoform 2 |
| Smp_010550.3 | G4VMN2 | Uncharacterized protein | MEG-15 isoform 3 |
| Smp_010550.4 | A0A5K4E9G8 | Uncharacterized protein | MEG-15 isoform 4 |
| WBPS Gene ID | UniProt ID | Old Name | New Name |
|---|---|---|---|
| Smp_326790.1 | A0A5K4F8B3 | MEG-1 | MEG-1.1 isoform 1 |
| A0A5K4F8U8 | MEG-1 | MEG-1.1 isoform 2 | |
| Smp_122630.1 | A0A3Q0KKC4 | MEG-1 isoform 1 | MEG-1.2 isoform 1 |
| D7PD83 | MEG-1 isoform 5 | MEG-1.2 isoform 2 | |
| D7PD84 | MEG-1 isoform 6 | MEG-1.2 isoform 3 | |
| D7PD86 | MEG-1 isoform 8 | MEG-1.2 isoform 4 | |
| D7PD88 | MEG-1 isoform 10 | MEG-1.2 isoform 5 | |
| D7PD89 | MEG-1 isoform 11 | MEG-1.2 isoform 6 | |
| D7PD93 | MEG-1 isoform 16 | MEG-1.2 isoform 7 | |
| Smp_122630.2 | A0A5K4EKN1 | MEG-1 isoform 2 | MEG-1.2 isoform 8 |
| D7PD79 | MEG-1 isoform 1 | MEG-1.2 isoform 9 | |
| D7PD91 | MEG-1 isoform 14 | MEG-1.2 isoform 10 | |
| D7PD94 | MEG-1 isoform 18 | MEG-1.2 isoform 11 | |
| D7PD95 | MEG-1 isoform 17 | MEG-1.2 isoform 12 | |
| D7PD99 | MEG-1 isoform 12 | MEG-1.2 isoform 13 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nedvědová, Š.; De Stefano, D.; Walker, O.; Hologne, M.; Miele, A.E. Revisiting Schistosoma mansoni Micro-Exon Gene (MEG) Protein Family: A Tour into Conserved Motifs and Annotation. Biomolecules 2023, 13, 1275. https://doi.org/10.3390/biom13091275
Nedvědová Š, De Stefano D, Walker O, Hologne M, Miele AE. Revisiting Schistosoma mansoni Micro-Exon Gene (MEG) Protein Family: A Tour into Conserved Motifs and Annotation. Biomolecules. 2023; 13(9):1275. https://doi.org/10.3390/biom13091275
Chicago/Turabian StyleNedvědová, Štěpánka, Davide De Stefano, Olivier Walker, Maggy Hologne, and Adriana Erica Miele. 2023. "Revisiting Schistosoma mansoni Micro-Exon Gene (MEG) Protein Family: A Tour into Conserved Motifs and Annotation" Biomolecules 13, no. 9: 1275. https://doi.org/10.3390/biom13091275