Abstract
The Kumaraswamy distribution is a common type of bounded distribution, which is widely used in agriculture, hydrology, and other fields. In this paper, we use the methods of the likelihood ratio test, modified information criterion, and Schwarz information criterion to analyze the change point of the Kumaraswamy distribution. Simulation experiments give the performance of the three methods. The application section illustrates the feasibility of the proposed method by applying it to a real dataset.
Keywords:
Kumaraswamy distribution; change point; likelihood ratio test; modified information criterion; Schwarz information criterion; maximum likelihood estimate MSC:
62C05; 62P30; 62E99; 62F03
1. Introduction
The change-point problem, introduced by Page [1,2], has become more important in many application fields, such as finance, hydrology, and genetics. In statistics, several theories and applications related to change-point analysis have been studied by scholars. Sen and Srivastava [3] deduced the exact and asymptotic distribution of the test statistics of a single change point in a normal random variable sequence. Cai et al. [4] considered the likelihood ratio test (LRT) and Schwarz information criterion (SIC) to detect the change-point problem of an exponential distribution. Chen and Ning [5] investigated the change point of an exponential-logarithmic distribution using the modified information criterion (MIC) method and applied it to biological and engineering aspects of the dataset. Said et al. [6] analyzed the change point of the skew-normal distribution by MIC, LRT, and the Bayesian information criterion (BIC). Wang et al. [7] extended the method of LRT into the skew-slash distribution. Tian and Yang [8] studied the change-point problem of weighted exponential distributions based on the LRT, MIC and SIC procedures.
In real life, we often encounter some measurements, such as the proportion of a certain feature, the scores of some ability tests, and different indicators and ratios, which are located in the interval. In such cases, bounded distributions are essential to model these phenomena. As we know, the Kumaraswamy () distribution plays an important role in bounded distributions. The distribution was introduced by Kumaraswamy [9] to study the daily rainfall in hydrology. Its probability density function (pdf) was given by
where and were shape parameters, and it was denoted by . The density function is unimodal if and and uniantimodal if and . The density function increases for and , decreases for and , and is constant for .
The distribution was considered to be a substitutive model for the beta distribution in practical terms and has drawn much academic attention and concern. In fact, the and beta distributions have the following properties in common: the shape types of their pdfs are the same, and the power function and the uniform distribution are similar in both their cases. Furthermore, the distribution has some additional advantages over the beta distribution, such as its simple explicit formulas for the distribution functions and quantile function, which did not involve any special functions. Moreover, the simplicity of the quantile function provided a simple formula for random variable generation. See Jones [10] for a detailed description. Fletcher and Ponnambalam [11] used the distribution to analyze reservoir storage capacity. Nadarajah [12] mentioned the distribution as a special case of the beta distribution, and clarified that the distribution was more effective than the beta distribution. Jones [10] systematically studied the basic statistical properties of the distribution and estimated its parameters by the maximum likelihood estimation method. Nadar et al. [13] conducted a statistical correlation analysis of the distribution for the recorded values. Meanwhile, some new families of distributions have been proposed based on the distribution, such as Saulo et al. [14], who studied the Birnbaum–Saunders distribution, which provided enormous flexibility in modeling heavy-tailed and skewed data. Lemonte et al. [15] established the exponentiated distribution and used the model to effectively fit life data. Mameli [16] pointed out that the skew-normal distribution was a valid alternative to the beta skew-normal distribution. Iqbal et al. [17] proposed the generalized inverted distribution to model a dataset of prices of wooden toys for 31 children.
Based on our knowledge, there is little research on the change point of the distribution. Therefore, it is of a certain significance to study the change-point detection of the distribution. The remaining organizational parts of the paper are as follows. The related basic theoretical knowledge and three methods of change point detection based on the distribution are introduced in detail in Section 2. Simulation studies are carried out for three different detection methods in Section 3. Real data applications are studied in Section 4. Some conclusions are given in Section 5.
2. Methodology
Let be a sequence of independent random variables with parameters and . We are interested in testing the null hypothesis,
against the alternative hypothesis
and
Under , the log-likelihood function is given by
We take the first derivatives of the Equation (1) with respect to and . The MLEs and of and can be obtained by solving the following equations:
Under , the log-likelihood function is given by
Similarly, we take the first derivatives of Equation (2) with respect to , , and . The MLEs , , and can be obtained by solving the following equations:
2.1. Likelihood Ratio Test
The LRT is one of the most commonly used change point detection methods. The main idea of this method is to use the likelihood ratio idea to test the existence of some distribution parameter change point, that is, to estimate the relevant parameters by finding the maximum value of the likelihood function, where the change point itself is a parameter. The LRT method is a problem discussed earlier in change-point theory, which has been considered by many scholars. Said et al. [18] explained that the LRT procedure has considerable ability to detect the parameter changes of the skew-normal distribution model. Wang et al. [7] used LRT procedure to study the parameter changes of the skew-slash distribution. In the following, we describe the LRT test procedure in detail.
Assuming that k is an integer between 1 and n, if the change point occurs at k, we reject the null hypothesis for a sufficiently large value of the log-likelihood ratio , which is given by the following equation:
We use and to represent MLEs under the corresponding hypothesis of change point k. Since the change position k is unknown, the maximum value of the selected log-likelihood ratio test statistic is naturally defined as
Actually, if the change occurs at the very beginning or the very end of the data, we may not have enough observations to obtain the MLEs of the parameters, or the MLEs of the parameters may not be unique; see Said et al. [18]. Thus, we consider the trimmed version of the test statistics given by Zou et al. [19], as shown in the following formula:
There are several choices for . For example, Liu and Qian [20] suggested the choice of , Said et al. [18] chose , with representing the largest integer that is not greater than x. In this paper, we also choose . Thus, we reject if
is sufficiently large and the estimated change location . This means that for any given significance level , we cannot reject if , where is the critical value with respect to for different sample size n. To obtain , we have to use the following theorem.
Theorem 1
(Csrgó and Horváth [21]). Under , as , for all , we have
where
and
Proof.
According to Theorem A1 in Csrgó and Horváth [21], which is given in Appendix A, let , . Then, we obtain
We consider the trimmed version of the test statistic and use Theorem A1 instead of Corollary A1 in the proof. □
Using Theorem 1, the approximation of is given by
Thus,
According to Equation (3), the empirical critical value at different significance levels and sample sizes n can be obtained, as shown in Table 1.

Table 1.
Approximate critical values of LRT with different values of and n.
2.2. Schwarz Information Criterion
The SIC was proposed by Schwarz [22] in order to remedy the inconsistency of estimators in the model based on the Akaike information criterion (AIC). The advantage of SIC is that it is unnecessary to derive the asymptotic distribution of complex test statistics. The SIC under is expressed as
and for a fixed change location where k is an integer, we consider
where and are the log-likelihood functions of the random sample under and , respectively. The choice to accept or depends on the principle of the minimum information criteria, i.e., we fail to reject if
and we reject if
and the location of the change point can be estimated using as follows:
To make the conclusion more statistically convincing, we consider the following test statistic:
Thus, we fail to reject if instead of , where is determined by
In fact,
where is the test statistic of the LRT. Therefore, we obtain that
Theorem 2
(Csrgó and Horváth [21]). Under , as , for all , we have
where
and
Proof.
In Csrgó and Horváth [21]’s conditions, we use Theorem A2 from Csrgó and Horváth [21] to give the above conclusion; see Appendix A for Theorem A2. □
From Theorem 2 above, the approximate expression of is derived as follows:
Thus,
According to Equation (4), the critical empirical value based on the SIC method can be obtained under different significance levels and sample sizes n, as shown in Table 2.
Table 2.
Approximate critical values of SIC with different values of and n.
2.3. Modified Information Criterion
The MIC approach was proposed by Chen et al. [23] to solve the issue of the redundancy of parameters caused by the SIC method. The MIC under the is expressed as
For a fixed change location ,
where and are the log-likelihood functions of the random sample under and , respectively. Then, we fail to reject if
and we reject if
Therefore, we can estimate the position of the change point by
In addition, we give the critical empirical value of the MIC method by the test statistic in order to detect the presence of a change point faster and more efficiently. In the case that the value is large enough, we reject the null hypothesis , and the value is given by the following formula:
For a given significance level , the critical value of the test statistic under the null hypothesis is simulated by the Bootstrap method. Namely, a certain number of Bootstrap samples are drawn from the generated random numbers by sampling with replacement, and then the values of the test statistics are obtained from the Bootstrap samples, which are sorted, and the percentage of the sorted test statistics is used as the critical value for a given significance level. Table 3 and Table 4 are the critical value of the MIC detection method obtained by the bootstrap method with some specific distributions.
Table 3.
Approximate critical values for MIC under different parameters.
Table 4.
Approximate critical values for MIC under parameters.
However, we do not know whether the real dataset satisfies or , which would be a problem. Thus, we cannot re-sample the data directly. We first assume the data satisfying , which indicates it should be fitted by a distribution, say, , where and are obtained by the MLE method. Then. we generate a random sample based on denoted by . Then, B Bootstrap samples are drawn from this generated sample with replacement, denoted by . For each Bootstrap sample, we calculate denoted by . Thus, the can be approximated as follows:
where is the indicator function and is the value of calculated from the original real data.
3. Simulation
Power refers to the probability of accepting the correct alternative hypothesis after rejecting the null hypothesis in a hypothesis test. We did not consider whether the test procedures detected the correct change point because we only evaluated whether there was a change point. Then, we gave the performance of the test procedures based on the efficacy of , , and in different simulation scenarios. In the simulation study, the assessment of the robustness of the test relative to the underlying distribution was not the goal of the study; thus, all the data generated in the simulation part came from the Kw distribution. We conducted simulations 1000 times under with different values of the shape parameters and . The test statistics , and were calculated and compared to the critical values corresponding to the significance levels of , 0.05 and 0.1. After rejecting the null hypothesis, we calculated the powers of the SIC, the LRT, and the MIC with different sample sizes , 50, and 100 and assumed the change occurs at the position of approximately , and of the sample sizes n. The detailed results are displayed in Table 5, Table 6, Table 7, Table 8, Table 9, Table 10, Table 11, Table 12 and Table 13. We choose the parameter values , (0.5, 3.5) and (5, 2) before the change, which was based on the increasing, decreasing, and unimodal types of the distribution, respectively. The selection of parameter values after the change is based on the changing of one parameter or two parameters of the distribution. In a word, the following three distributions are considered:
Table 5.
Powers of the LRT, SIC, and MIC procedures at , .
Table 6.
Powers of the LRT, SIC, and MIC procedures at , .
Table 7.
Powers of the LRT, SIC, and MIC procedures at , .
Table 8.
Powers of the LRT, SIC, and MIC procedures at , .
Table 9.
Powers of the LRT, SIC, and MIC procedures at , .
Table 10.
Powers of the LRT, SIC, and MIC procedures at , .
Table 11.
Powers of the LRT, SIC, and MIC procedures at , .
Table 12.
Powers of the LRT, SIC, and MIC procedures at , .
Table 13.
Powers of the LRT, SIC, and MIC procedures at , .
- I
- The distribution follows before the change and follows after the change, where are set to be .
- II
- The distribution follows before the change and follows after the change, where are set to be .
- III
- The distribution follows before the change and follows after the change, where are set to be .
From the simulation results in Table 5, Table 6, Table 7, Table 8, Table 9, Table 10, Table 11, Table 12 and Table 13, we observe that the power of the SIC procedure is generally the lowest for all situations, and the power of the MIC procedure is higher than the powers of the procedures based on SIC and LRT. At a small sample size of , the powers of the SIC and LRT procedures are relatively low compared to the MIC procedure; even the power of the MIC is not good enough. We also note that the generated data do not have variable points; in many cases, the rejection rate of the MIC test is greater than the nominal level, probably because the MIC-based approach takes into account the effect of variable point location on model complexity. Next, we can also observe that as the significance level and sample size n increase, the powers of the LRT, SIC and MIC procedures increase accordingly. The power values are higher when the change occurs around the middle of the data than the power values when the change occurs near the beginning or the end. Furthermore, we notice that the smaller the difference between and , the smaller the power. In other words, when the parameter value of the null hypothesis and the alternative hypothesis are closer, the smaller the power is. Moreover, when sample sizes are large enough, the power approaches 1, which indicates that the three criteria are consistent. In the simulation results shown, if the statistics of the three criteria satisfy Pr (reject when is false) ≥ Pr (reject when is true), then the statistics of the three criteria are unbiased. From the comparison, the MIC test is usually anti-conservative and does not respect the nominal , but it is the most powerful test in among the settings with good behavior under . Therefore, we conclude that the MIC method has a significant ability to detect change points compared to the LRT and SIC methods.
4. Application
The distribution is widely used in hydrology and related fields. Meanwhile, all the methods to detect the change point of the real dataset can be extended to the case where there may be a dependency between the observations, which is also common in the case of time series data, as in the literature, such as Chen and Ning [5] and Tian and Yang [8]. In this section, since the overall effect of the MIC is better, we consider applying the MIC testing procedure to detect possible change points in the following real datasets.
4.1. Shasta Reservoir
The first dataset describes the monthly water capacity from the Shasta reservoir in California, USA. The data are recorded for February from 1991 to 2010 (see for details the website http://cdec.water.ca.gov/reservoir_map.html (accessed on 15 December 2022), which can also be found in Sultana et al. [24]. The parameter estimates and the Kolmogorov–Smirnov (K-S) test correlation results are given in Table 14. The probability density fitting curves for the dataset are also shown in Figure 1, which means the dataset fits the distribution reasonably well. In fact, Nadar et al. [13] used this dataset to conduct statistical analyses on the distribution based on record data.
Table 14.
The MLEs and the goodness-of-fit statistics for the Shasta reservoir dataset.
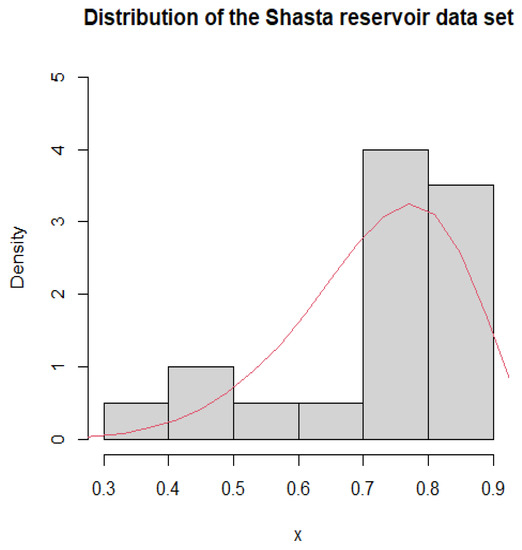
Figure 1.
Histogram and PDF fitting of Shasta reservoir dataset.
We applied the MIC test criteria of Equations (5)–(7). Under the null hypothesis , the is calculated as . Under the alternative hypothesis , is calculated as , which corresponds to . The corresponding estimated values of the parameters are , , , and with when using Equations (8) and (9). Since is less than , there is a change point occurring at position 3, which corresponds to the year 1993. According to Yates et al. [25], 1993 corresponded to a wet year in the Shasta reservoir, California. Figure 2 shows the dataset of monthly water capacity for the Shasta reservoir and the position of the change point.
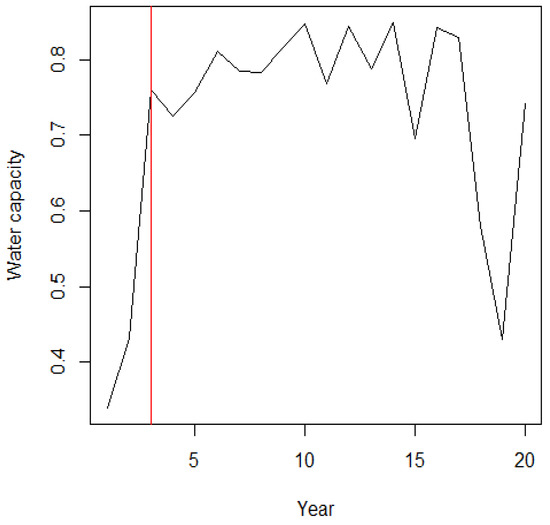
Figure 2.
The Shasta reservoir dataset and position of change point.
Figure 3 shows the MIC values associated with different values of k. The estimated change location corresponds to the smallest MIC value.
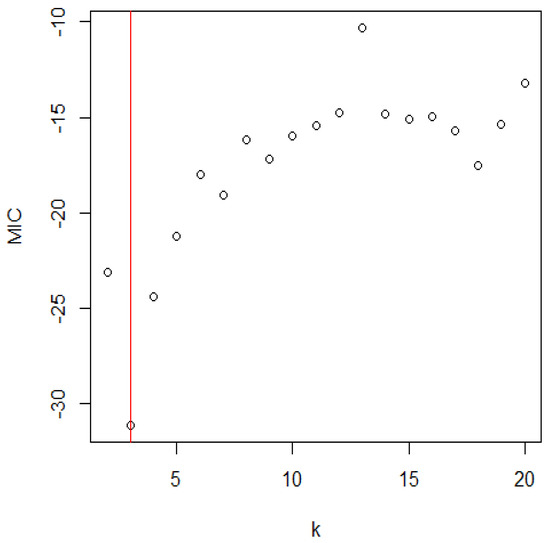
Figure 3.
The distribution of MIC for the Shasta reservoir.
4.2. Susquehanna River
The second dataset describes the maximum flood level (in millions of cubic feet per second) for the Susquehanna River at Harrisburg, Pennsylvania, from 1890 to 1969. Each number is the maximum flood level for four years. Khan et al. [26] investigated these data with the distribution and also considered fitting the flood data with the distribution. Mazucheli et al. [27] used this dataset to verify the practicability of the unit Weibull distribution. Bantan et al. [28] applied the improved model to this dataset, demonstrating the superiority of the distribution. Furthermore, the parameter estimates and the Kolmogorov–Smirnov (K-S) test correlation results are given in Table 15. The probability density fitting curves for the dataset are also shown in Figure 4.
Table 15.
The MLEs and the goodness-of-fit statistics for Susquehanna river dataset.
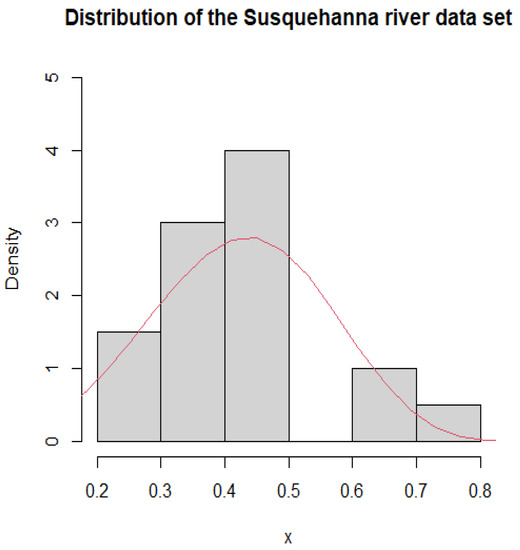
Figure 4.
Histogram and PDF fitting of Susquehanna river dataset.
In order to detect the change point in the dataset, we obtained, under the null hypothesis , the , which was calculated as . Under the alternative hypothesis , was calculated as which corresponds to . The corresponding parameters are , , , and with . Since is less than , we can say that the data have a change point, and the position of the change point is 13, which corresponds to the period 1934–1937. According to Roland et al. [29], a serious flood occurred in 1936. Figure 5 shows the dataset of the maximum flood level for the Susquehanna River and the position of the change point.
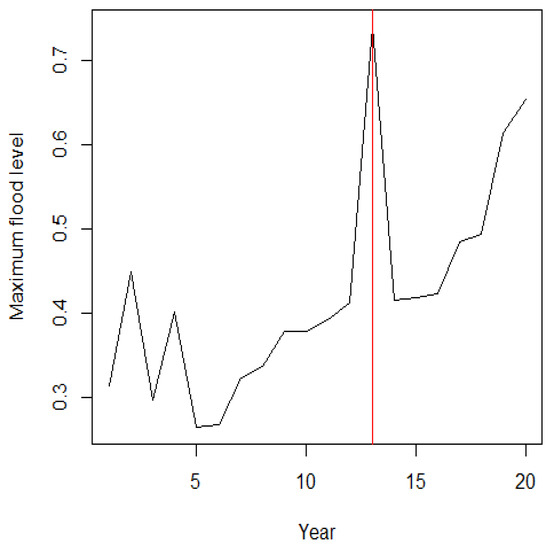
Figure 5.
The Susquehanna river dataset and position of change point.
Figure 6 shows the MIC values for all possible values of k. The smallest value of the MIC corresponds to the estimated change location.
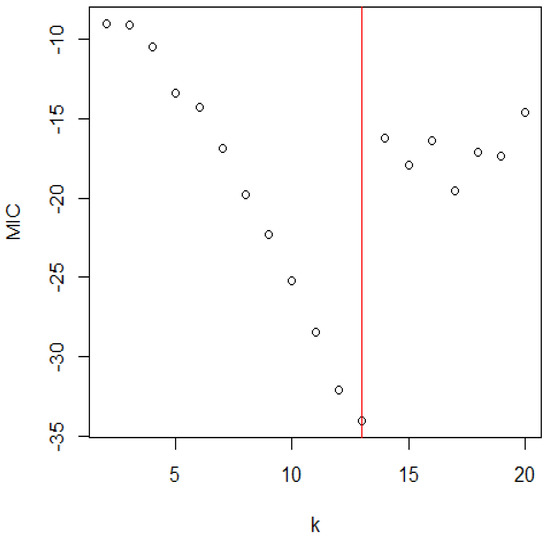
Figure 6.
The distribution of MIC for the Susquehanna river.
4.3. Strengths of 1.5 cm Glass Fibres
The third dataset represents the strengths of 1.5 cm glass fibres, initially obtained by workers at the UK National Physical Laboratory. Glass fiber is used to make a variety of products. It is a good electrical insulator; therefore, it is used in the manufacture of many electrical and electronic products and circuit boards. It is also a heat-resistant material used to make products that heat up quickly, such as batteries and motors. The observations of the dataset are found in Elgarhy [30]. The parameter estimates and the Kolmogorov–Smirnov (K–S) test correlation results are given in Table 16. The probability density fitting curves for the dataset are also shown in Figure 7. Thus, the dataset fit the distribution reasonably well.
Table 16.
The MLEs and the goodness-of-fit statistics for 1.5cm glass fibre strengths dataset.
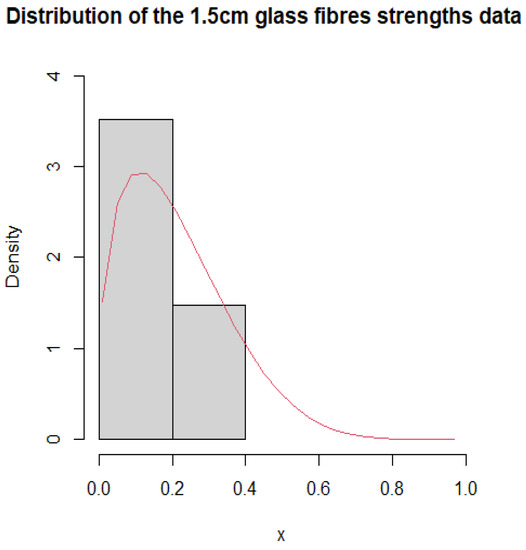
Figure 7.
Histogram and PDF fitting of 1.5 cm glass fibre strengths dataset.
Under the null hypothesis , the was calculated as . Under the alternative hypothesis , was calculated as , which corresponds to . The corresponding estimated value of the parameters are , , , , and , with . Since is less than , that is to say, there is a change point occurring at position 20, it can be seen that a change point is indicated at the strength of the twentieth, corresponding to the dataset of 0.10. This shows that for the dataset of twenty-seven strengths, the strength of the glass fibers changes at the twentieth strength, and this change remains until the twenty-seventh strength. Figure 8 shows the original data and change point position.
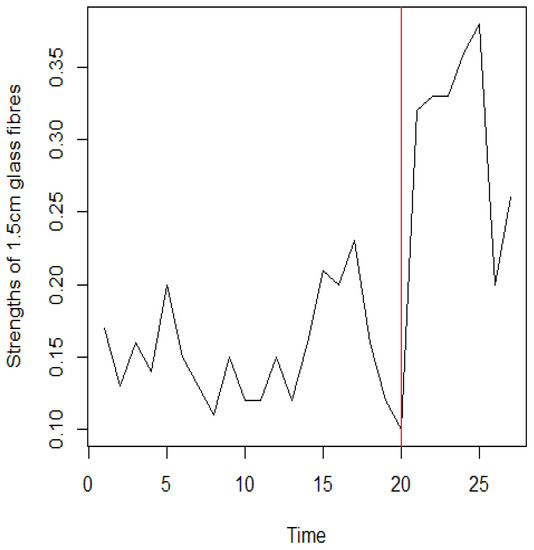
Figure 8.
The strengths of 1.5cm glass fibres dataset and position of change point.
Figure 9 shows the values of the MIC associated with different values of k. The estimated change location corresponds to the smallest MIC value.
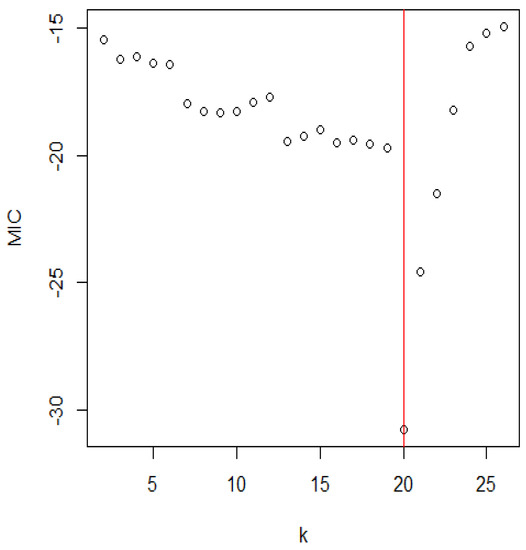
Figure 9.
The distribution of the MIC for the strengths of 1.5 cm glass fibres.
5. Conclusions
In this paper, we use the LRT, SIC and MIC methods to perform a change point analysis of the distribution, which is widely used in hydrology. Simulations are performed under different scenarios as a means to elucidate the performance of the three change point detection methods. The simulation results show that, in general, the MIC method has more advantages than the SIC and LRT methods in detecting the position of change points. Finally, the MIC method is used to detect the change point of real datasets, and significant change points can be detected. Although the MIC method can work well for the change point detection based on the distribution, the power of it is not big enough for small sizes, and we will work on an alternative method to improve it.
Author Contributions
W.T.: Conceptualization, Methodology, Validation, Investigation, Resources, Supervision, Project Administration, Visualization, Writing—review and editing; L.P.: Software, Formal analysis, Data curation, Writing—original draft preparation, Visualization; C.T., W.N.: Software, Methodology, Visualization. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
The source of the datasets are provided in the paper.
Acknowledgments
We would like to thank the reviewers for carefully and thoroughly reading this manuscript and for the thoughtful comments and constructive suggestions, which helped us improve the quality of this manuscript.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A
Theorem A1
(Csrgó and Horváth [21]). If and
then we have
for all x.
Corollary A1
(Csrgó and Horváth [21]). We have for all
Theorem A2
(Csrgó and Horváth [21]). If and hold; then we have
for all t.
References
- Page, E.S. Continuous inspection schemes. Biometrika 1954, 41, 100–115. [Google Scholar] [CrossRef]
- Page, E.S. A test for a change in a parameter occurring at an unknown point. Biometrika 1955, 42, 523–527. [Google Scholar] [CrossRef]
- Sen, A.; Srivastava, M.S. On tests for detecting change in mean. Ann. Stat. 1975, 3, 98–108. [Google Scholar] [CrossRef]
- Cai, X.; Said, K.K.; Ning, W. Change-point analysis with bathtub shape for the exponential distribution. J. Appl. Stat. 2016, 43, 2740–2750. [Google Scholar] [CrossRef]
- Chen, Y.J.; Ning, W. Information approach for a lifetime change-point model based on the exponential-logarithmic distribution. Commun. Stat.-Simul. Comput. 2019, 48, 1996–2003. [Google Scholar] [CrossRef]
- Said, K.K.; Ning, W.; Tian, Y. Modified information criterion for testing changes in skew normal model. Braz. J. Probab. Stat. 2019, 33, 280–300. [Google Scholar] [CrossRef]
- Wang, T.; Tian, W.; Ning, W. Likelihood ratio test change-point detection in the skew slash distribution. Commun. Stat.-Simul. Comput. 2020, 1–13. [Google Scholar] [CrossRef]
- Tian, W.; Yang, Y. Change point analysis for weighted exponential distribution. Commun. Stat.-Simul. Comput. 2021, 1–13. [Google Scholar] [CrossRef]
- Kumaraswamy, P. A generalized probability density function for double-bounded random processes. J. Hydrol. 1980, 46, 79–88. [Google Scholar] [CrossRef]
- Jones, M.C. Kumaraswamy’s distribution: A beta-type distribution with some tractability advantages. Stat. Methodol. 2009, 6, 70–81. [Google Scholar] [CrossRef]
- Fletcher, S.G.; Ponnambalam, K. Estimation of reservoir yield and storage distribution using moments analysis. J. Hydrol. 1996, 182, 259–275. [Google Scholar] [CrossRef]
- Nadarajah, S. On the distribution of kumaraswamy. J. Hydrol. 2008, 348, 568–569. [Google Scholar] [CrossRef]
- Nadar, M.; Papadopoulos, A.; Kızılaslan, F. Statistical analysis for Kumaraswamy’s distribution based on record data. Stat. Pap. 2013, 54, 355–369. [Google Scholar] [CrossRef]
- Saulo, H.; Leão, J.; Bourguignon, M. The kumaraswamy birnbaum-saunders distribution. J. Stat. Theory Pract. 2012, 6, 745–759. [Google Scholar] [CrossRef]
- Lemonte, A.J.; Barreto-Souza, W.; Cordeiro, G.M. The exponentiated Kumaraswamy distribution and its log-transform. Braz. J. Probab. Stat. 2013, 27, 31–53. [Google Scholar] [CrossRef]
- Mameli, V. The Kumaraswamy skew-normal distribution. Stat. Probab. Lett. 2015, 104, 75–81. [Google Scholar] [CrossRef]
- Iqbal, Z.; Tahir, M.M.; Riaz, N.; Ali, S.A.; Ahmad, M. Generalized inverted Kumaraswamy distribution: Properties and application. Open J. Stat. 2017, 7, 645. [Google Scholar] [CrossRef]
- Said, K.K.; Ning, W.; Tian, Y. Likelihood procedure for testing changes in skew normal model with applications to stock returns. Commun. Stat.-Simul. Comput. 2017, 46, 6790–6802. [Google Scholar] [CrossRef]
- Zou, C.; Liu, Y.; Qin, P.; Wang, Z. Empirical likelihood ratio test for the change-point problem. Stat. Probab. Lett. 2007, 77, 374–382. [Google Scholar] [CrossRef]
- Liu, Z.; Qian, L. Changepoint estimation in a segmented linear regression via empirical likelihood. Commun. Stat.-Simul. Comput. 2009, 39, 85–100. [Google Scholar] [CrossRef]
- Csörgó, M.; Horváth, L. Limit Theorems in Change-Point Analysis; John Wiley and Sons Inc.: Hoboken, NJ, USA, 1997; Volume 18. [Google Scholar]
- Schwarz, G. Estimating the dimension of a model. Ann. Stat. 1978, 6, 461–464. [Google Scholar] [CrossRef]
- Chen, J.; Gupta, A.K.; Pan, J. Information criterion and change point problem for regular models. Sankhya Indian J. Stat. 2006, 68, 252–282. [Google Scholar]
- Sultana, F.; Tripathi, Y.M.; Wu, S.J.; Sen, T. Inference for kumaraswamy distribution based on type I progressive hybrid censoring. Ann. Data Sci. 2022, 9, 1283–1307. [Google Scholar] [CrossRef]
- Yates, D.; Galbraith, H.; Purkey, D.; Huber-Lee, A.; Sieber, J.; West, J.; Herrod-Julius, S.; Joyce, B. Climate warming, water storage, and Chinook salmon in California’s Sacramento Valley. Clim. Chang. 2008, 91, 335–350. [Google Scholar] [CrossRef]
- Khan, M.S.; King, R.; Hudson, I.L. Transmuted kumaraswamy distribution. Stat. Transit. New Ser. 2016, 17, 183–210. [Google Scholar] [CrossRef]
- Mazucheli, J.; Menezes, A.F.B.; Ghitany, M.E. The unit-Weibull distribution and associated inference. J. Appl. Probab. Stat. 2018, 13, 1–22. [Google Scholar]
- Bantan, R.A.; Chesneau, C.; Jamal, F.; Elgarhy, M.; Almutiry, W.; Alahmadi, A.A. Study of a Modified Kumaraswamy Distribution. Mathematics 2021, 9, 2836. [Google Scholar] [CrossRef]
- Roland, M.A.; Underwood, S.M.; Thomas, C.M.; Miller, J.F.; Pratt, B.A.; Hogan, L.G.; Wnek, P.A. Flood-inundation maps for the Susquehanna River near Harrisburg, Pennsylvania, 2013. In Scientific Investigations Report 2014–5046; US Geological Survey: Reston, VA, USA, 2014; Volume 28. [Google Scholar]
- Elgarhy, M. Exponentiated generalized Kumaraswamy distribution with applications. Ann. Data Sci. 2018, 5, 273–292. [Google Scholar] [CrossRef]









Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).