



Information 2023, 14(9), 505; https://doi.org/10.3390/info14090505 - 14 Sep 2023
Cited by 10 | Viewed by 3322
Abstract
►
Show Figures
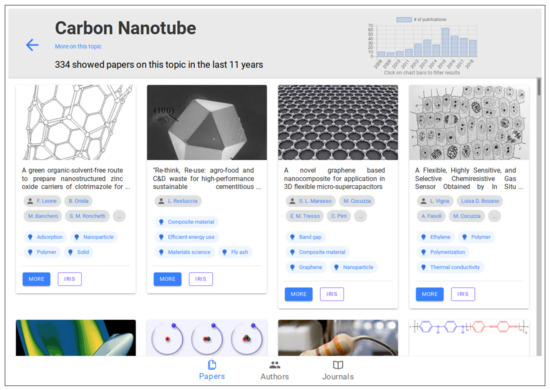
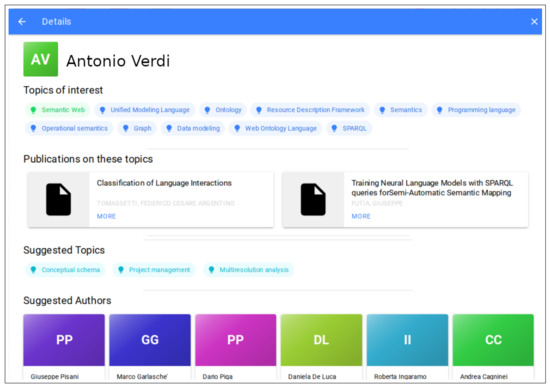
The extensive pool of content within educational software platforms can often overwhelm learners, leaving them uncertain about what materials to engage with. In this context, recommender systems offer significant support by customizing the content delivered to learners, alleviating the confusion and enhancing the
[...] Read more.
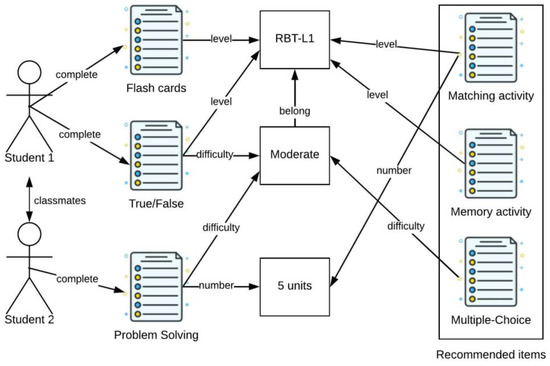
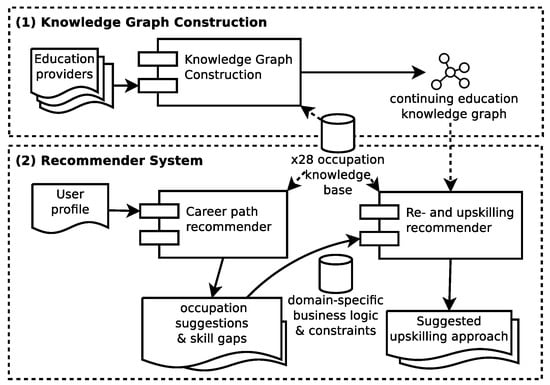
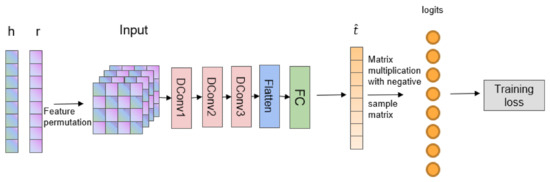
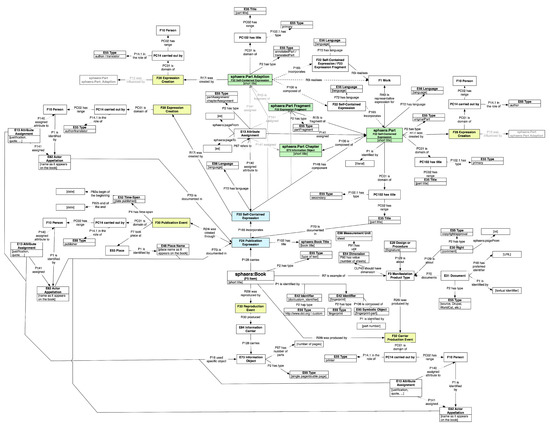
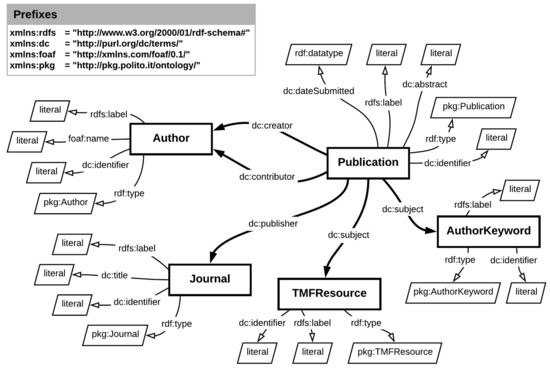
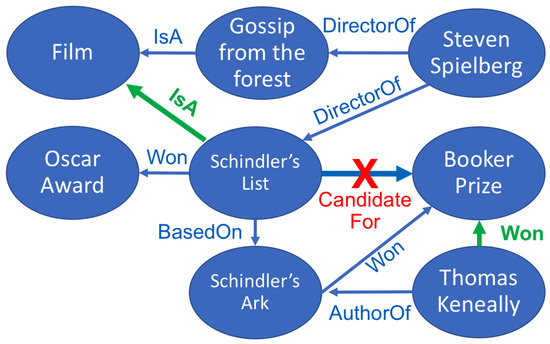
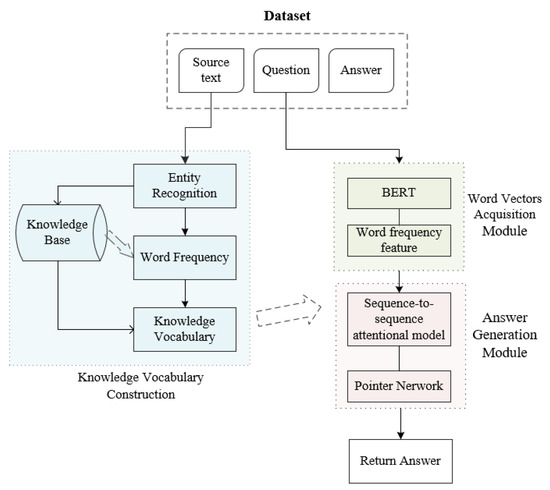
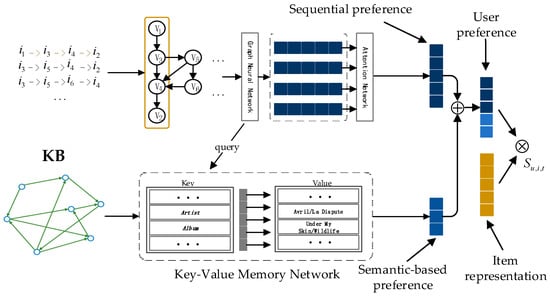
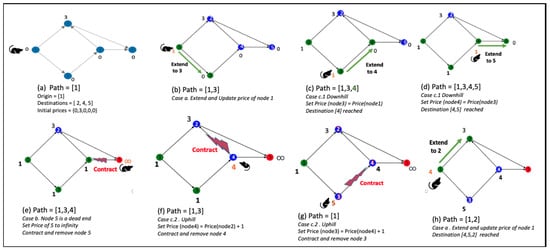
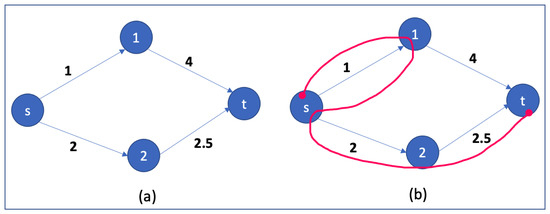
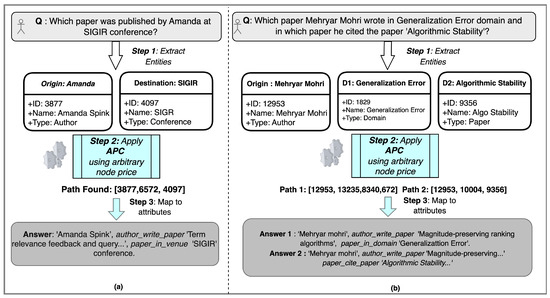
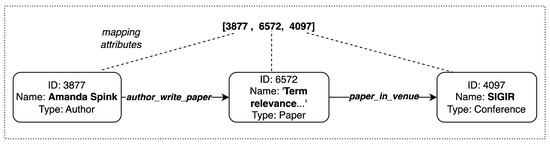
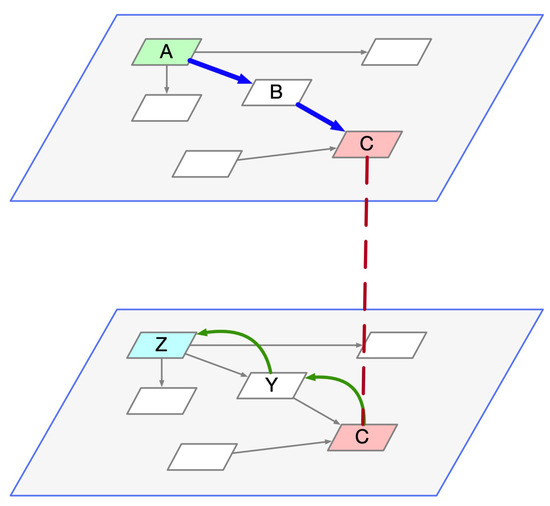
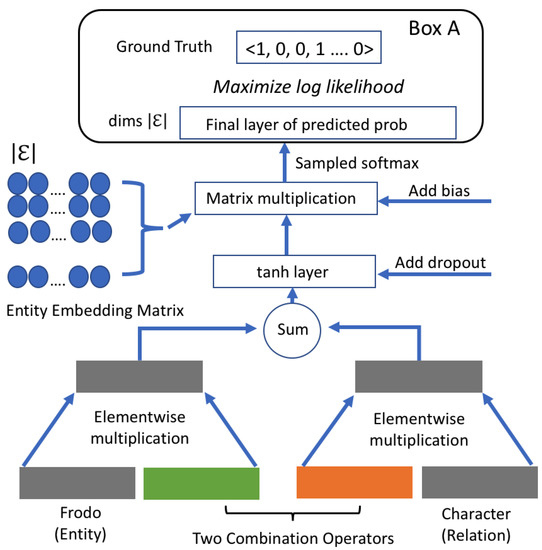
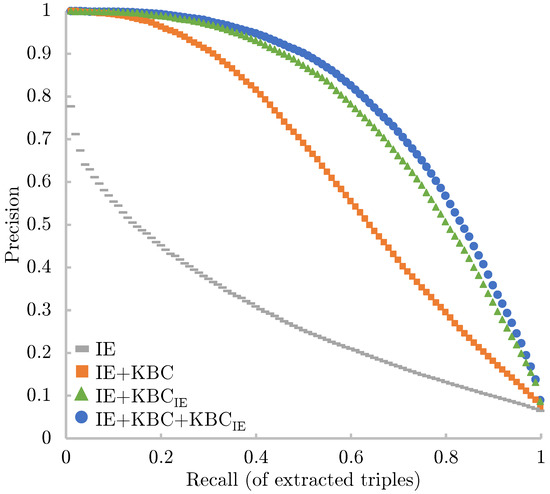
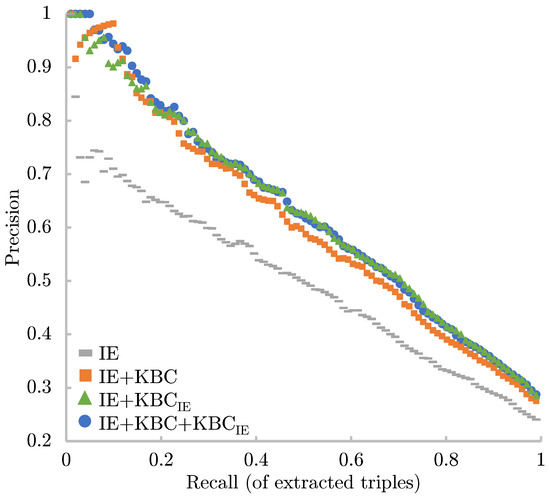
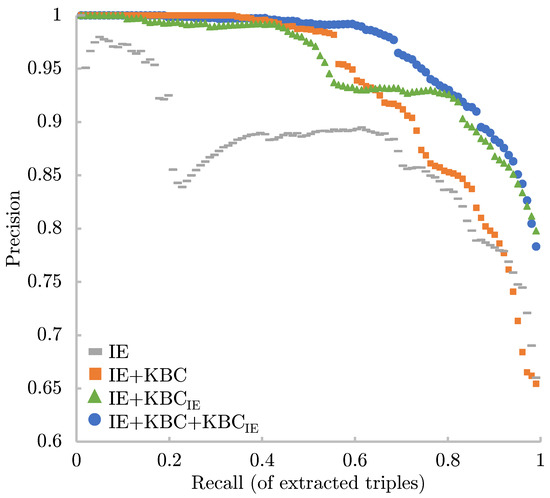
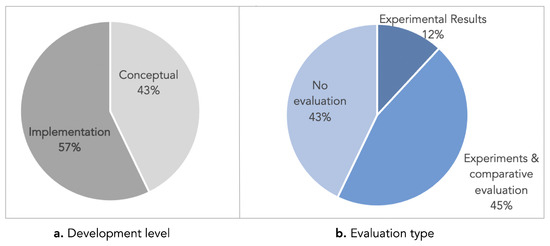
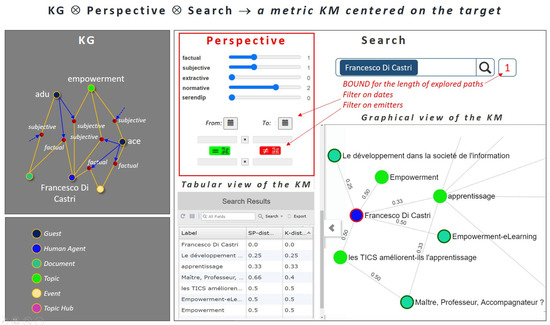
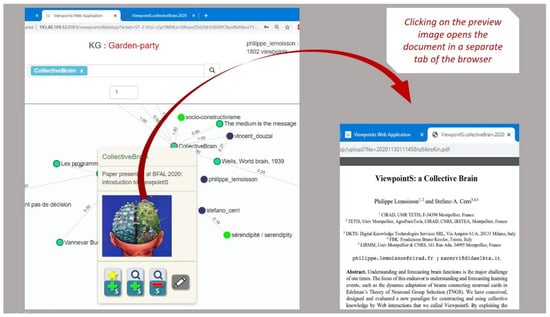
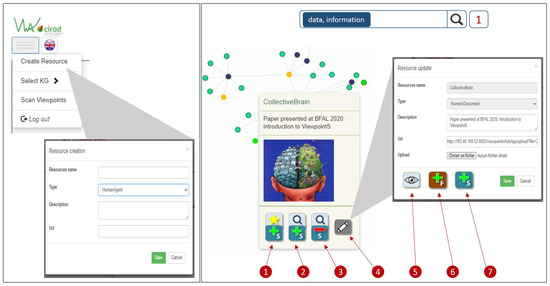
The extensive pool of content within educational software platforms can often overwhelm learners, leaving them uncertain about what materials to engage with. In this context, recommender systems offer significant support by customizing the content delivered to learners, alleviating the confusion and enhancing the learning experience. To this end, this paper presents a novel approach for recommending adequate educational content to learners via the use of knowledge graphs. In our approach, the knowledge graph encompasses learners, educational entities, and relationships among them, creating an interconnected framework that drives personalized e-learning content recommendations. Moreover, the presented knowledge graph has been enriched with contextual signals referring to various learners’ characteristics, such as prior knowledge level, learning style, and current learning goals. To refine the recommendation process, the cosine similarity technique was employed to quantify the likeness between a learner’s preferences and the attributes of educational entities within the knowledge graph. The above methodology was incorporated in an intelligent tutoring system for learning the programming language Java to recommend content to learners. The software was evaluated with highly promising results.
Full article
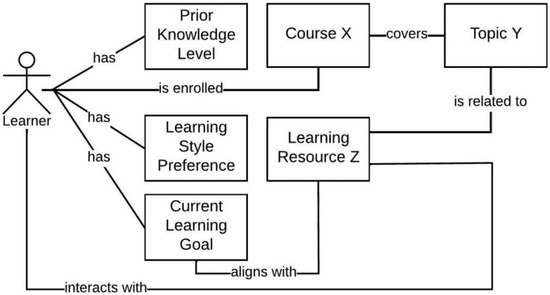
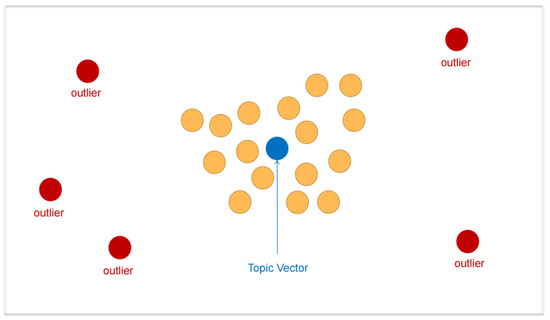
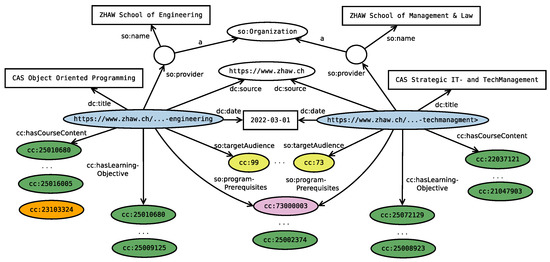
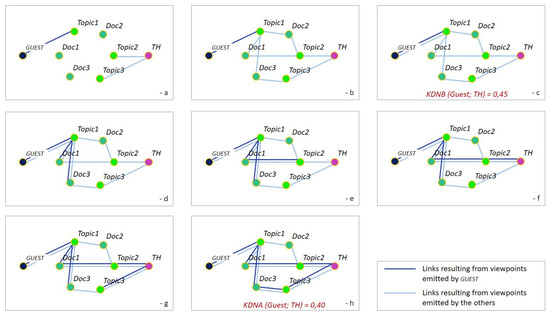
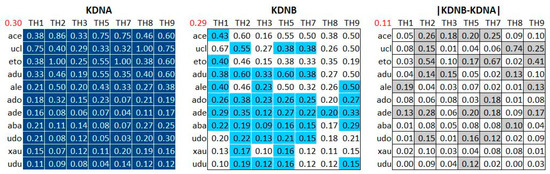
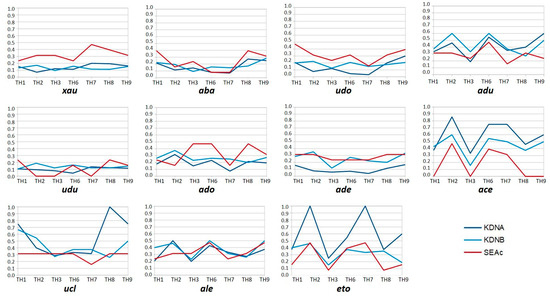
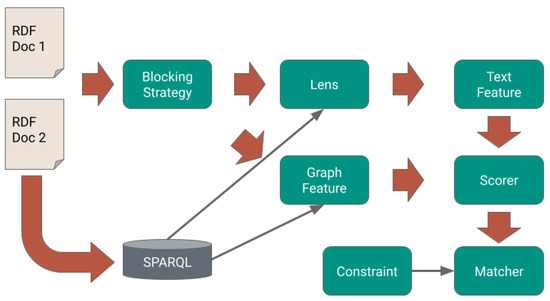
Figure 1


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}